
Whenever companies spend money and make investments, they are looking for one thing: a positive return on investment (ROI). At the end of the day, this can be achieved through lowering costs or increasing revenues. If you look at a profit and loss statement, there aren’t any other levers to pull. In practice, investment decisions are more complicated though. But with this blog post I won't dive into the complexities of corporate purchasing processes. Instead I will highlight some of the very clear economic values that synthetic data brings to organizations and discuss how to quantify them.
Because although it sounds great in principle to “unlock data silos” and “enable data-driven innovation”, it won’t necessarily get you approval for your business case by itself. There are arguably many different angles one could take to look at this topic. I decided to structure the discussion around two very simple questions:
How large will the likely ROI be?
How easy is it to quantify the likely ROI?
This gives the following nice matrix:
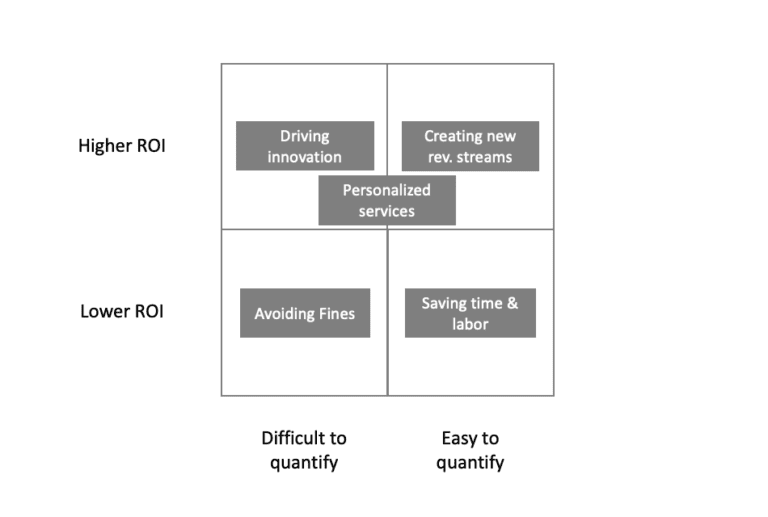
With that matrix in mind let’s look at two very quantifiable value creators of synthetic data and three lesser so:
Synthetic data to create new revenue streams
Let’s start on a strong note. This use-case sits in the desirable top right corner of our matrix and that is for a good reason. At one point or another, it becomes the goal of most companies to create additional revenue streams that lie outside of its current core business. History has shown that companies that innovate in such a way are more likely to survive over a long time period and are more resistant to external shocks. We’ve all read it so many times that I won’t repeat here that data is the … Instead, let’s think about the following scenario. You operate a large hospital chain. Every day thousands of patients are treated with certain medications. You do not only collect this data, but also important information about the results of these treatments. That data is not only gold for any pharmaceutical company, it’s also gold for health insurance companies, researchers and the entire health system in general. The only problem is: you can’t share that individual data on a granular level due to privacy concerns and HIPAA.
Enter the world of synthetic data. You have implemented a solution to synthesize this treatment data and are able to share these datasets in a privacy preserving way. However, you are not giving this data away for free, as you are well aware of the value you are creating for the recipients of this data. In fact, with a quick back of the envelope calculation you are able to assess the impact of your data for different recipients: reduced health insurance costs by x%, improved medication performance by y%, etc.
Depending on the data assets that you own and the potential recipients, the rewards can be huge and the ROI of this business case easy to quantify. But while we have seen synthetic data creating new waves of revenue streams for some companies, overall progress in this space has been relatively slow as organizations tend to focus on internal data monetization opportunities first.
Saving time (and manual labor) with synthetic data
Time is money and that is especially true when time involves manual labor. If you look at the booming robotic process automation (RPA) industry, that becomes obvious. It’s straightforward to calculate the ROI for any of these solutions. Estimate the time a manual process takes, look at the labor costs associated with it, subtract the cost of implementing and maintaining the RPA solution, and there you have your ROI.
While it’s not as straightforward with synthetic data projects, the concept is the same. Creating test data or anonymizing datasets is often a manual and time-consuming process. Depending on who is involved, these tasks are often completed by data engineers or data scientists who are expensive and in high demand. Imagine a scenario where it currently takes you about three months before you have a specific dataset anonymized for sharing with a third party. This involves manual work to anonymize the data, coordination with legal on the approach, as well as final clearance. While three months may sound like a long time, there are companies where such a process can take up to six months or longer!
Now imagine a process that takes one week instead, which becomes possible when you are using synthetic data with automated privacy safeguards that have already been pre-checked by legal. There is no extensive manual work involved. The process is simple: you provide the input data, the data is synthesized by the platform, and you are good to go with the output data. The one week delay basically results from a certain backlog where your data request needs to wait until other work has been completed.
The ROI calculation for the manual labor saved is straight forward, but probably will only result in overall lower ROI values. But on top of that, you get an extra benefit that is more difficult to quantify: reduced time to data! This time saving could result in an important partnership won or competitive edge that otherwise might have been a lost opportunity instead.
Synthetic data to avoid privacy fines
Regulations can sometimes be a burden and painful. While most of us do not like to deal with bureaucracy and excessive rules, we are certainly happy that particular regulations exist and welcome some with open arms. I prefer to fly a plane that is well maintained, with a pilot who has gone through proper training, for example. At MOSTLY AI, we are big fans of privacy regulations. Yes, they can have a negative impact on business, but they also promote what should be in our all interest: the protection of our privacy. We see a vast number of companies in the market that have started to embrace that mindset as well. For some that have not, legislators have taken precautionary measures in the form of fines for privacy violations. Like it or not, ensuring compliance by meeting privacy standards, and thus avoiding fines, is a legitimate reason for companies to invest in technology. Synthetic data comes in handy here as well.
Imagine you are working with an outsourced software testing company. Because you really need to be sure that these tests are performed as realistically as possible, you are using real customer data for these tests. Your service provider has ensured many safeguards for your data but becomes the victim of an internal hack and some of your sensitive customer data finds its way to the darknet. Suddenly, you’re faced not only with negative press but also with a hefty fine, because you did not have consent from all of your users to hand their personal data to this outsourced service provider.
When calculating the ROI for this case you have to take three things into consideration: what is the likelihood of such an event happening, what is the possible fine you could be confronted with, and what is the potential reputational damage you might suffer. While the number of fines and the amounts associated with related GDPR violations have increased dramatically in 2019 (reaching up to hundreds of million EUR per fine, see for example here), the actual risk your company might be facing could still be relatively small. As such, it’s not only difficult to quantify possible fines, but the business case will also likely show a rather low ROI. In general, we do not like to base business cases purely on this scenario – protecting your customer’s privacy is something that should be done, because it is the right thing to do, not in order to avoid possible fines!
Creating personalized services with synthetic data
You don’t have to necessarily create entirely new revenue streams - synthetic data allows you to significantly improve existing revenue streams as well. If you are a large organization that handles sensitive customer data (for example a bank or insurance company) it is likely that your product team has very limited access to actual granular customer data. This leads to certain challenges when it comes to data-driven innovation. For example how would you design a new mobile banking app, if you had no access to the actual transaction data of your customers? Quite likely, you would need to rely on assumptions and secondary research, which both come with a whole bunch of limitations.
Synthetic data, on the other hand, enables product teams to work with -as-good-as-real data of their customers in a privacy-compliant manner. It allows them to design and bring to market highly personalized services and products. The ROI drivers for this use case most often come in the form of lower customer churn and number of new customers won (and indirectly via higher customer satisfaction). All of these are KPIs that can be easily measured, however, the possible impact is not always trivial to quantify upfront. As such this scenario sits somewhere in between “easy” and “difficult” to quantify in our matrix.
Driving innovation on top of synthetic datasets
Let’s end this blog post with the generic “driving innovation” use-case of synthetic data. Why? Because the ROI can be massive. Imagine you are a large bank. One thing you have been struggling with in the past is working with innovative start-ups, due to lengthy legal processes and constraints in sharing data. Let’s assume you were using a synthetic data platform that would allow you to quickly and easily share certain data assets with several promising start-ups while ensuring that the privacy of your customers stays protected. Now imagine that one of those start-ups develops a game-changing micro-lending app based on the insights it gathers from your synthetic, yet highly representative customer data. You decide to enter a strategic partnership with that start-up. Fast forward five years: that start-up has grown to become a unicorn and through your partnership, you create tens of millions in additional revenue every year. Possible? Certainly! Easy to quantify the ROI today? Definitely not!
But that’s exactly the challenge companies are currently facing, not only when it comes to investments in synthetic data solutions, but investments in innovation in general. At MOSTLY AI we strongly believe in the power of data and the value that comes from using data for customer-centric product development. These investments might not return a positive ROI this year, but they certainly can in the long run.
This blog post sheds some light on the complexity of evaluating the concrete value of synthetic data. Of course, every company and every purchase decision is unique. If you are currently in the process of exploring solutions to create synthetic data, I’d be happy to help you quantify the value that you might be able to get out of such a solution - just reach out to me via LinkedIn.
About the author
Tobias Hann, holds a PhD in business from the Vienna University of Business and Economics as well as an MBA from the Haas School of Business, UC Berkeley. After having worked several years in management consulting and at various start-ups, he currently serves as the CEO of MOSTLY AI.


