
Data intelligence is locked up. Machine learning and AI in insurance is hard to scale and legal obligations make the job of data scientists and actuaries extremely difficult. How can you still innovate under these circumstances? The insurance industry is being disrupted as we speak by agile, fast moving insurtech start-ups and new, AI-enabled services by forward-thinking insurance companies.
According to McKinsey, AI will “increase productivity in insurance processes and reduce operational expenses by up to 40% by 2030”. At the same time, old-school insurance companies struggle to make use of the vast troves of data they are sitting on and sooner or later, ambitious insurtechs will turn their B2B products into business to consumer offerings, ready to take sizeable market shares. Although traditional insurance companies’ drive to become data-driven and AI-enabled is strong, organizational challenges are hindering efforts.
Laggers have a lot to lose. If they are to stay competitive, insurance companies need to redesign their data and analytics processes and treat the development of data-centric AI in insurance with urgency.
The bird's-eye view on data in the insurance industry
Data has always been the bread and butter of insurers and data-driven decisions in the industry predate even the appearance of computers. Business-critical metrics have been the guiding force in everything insurance companies do from pricing to risk assessment.
But even today, most of these metrics are hand-crafted with traditional, rule-based tools that lack dynamism, speed and contextual intelligence. The scene is ripe for an AI revolution.
The insurance industry relies heavily on push sales techniques. Next best products and personalized offers need to be data-driven. For cross selling and upselling activities to succeed, an uninterrupted data flow across the organization is paramount, even though often Life and Non-Life business lines are completely separated. Missed data opportunities are everywhere and require a commitment to change the status quo.
Interestingly, data sharing is both forbidden and required by law, depending on the line of business and properties of data assets in question. Regulations are plenty and vary across the globe, making it difficult to follow ambitious global strategies and turning compliance into a costly and tedious business. Privacy enhancing technologies or PETs for short can be of help and a modern data stack cannot do without them. Again, insurance companies should carefully consider how they build PETs into their data pipelines for maximum effect.
The fragmented, siloed nature of insurance companies' data architecture can benefit hugely from using PETs, like synthetic data generators, enabling cloud adoption, data democratization and the creation of a consolidated data intelligence across the organization.
Insurtech companies willing to change traditional ways and adopting AI in insurance with earnestness have been stealing the show left, right and center. As far back as 2017, a US insurtech company, Lemonade announced to have paid out the fastest claim in the history of the insurance industry - in three seconds.
If insurance companies are to stay competitive, they need to turn their thinking around and start redesigning their business with sophisticated algorithms and data in mind. Instead of programming the data, the data should program AI and machine learning algorithms. That is the only way for truly data-driven decisions, everything else is smoke and mirrors. Some are wary of artificial intelligence and would prefer to stick to the old ways. That is simply no longer possible.
The shift in how things get done in the insurance industry is well underway already. Knowing how AI in insurance systems works and what its potential is with best practices, standards and use cases is what will make this transition safe and painless, promising larger profits, better services and frictionless products throughout the insurance market.
What drives you? The three ways AI can have an impact
AI and machine learning typically can help achieving impact in three ways.
1. Increase profits
Examples include campaign optimization, targeting, next best offer/action, and best rider based on contract and payment history. According to the AI in insurance 2031 report by Allied Market Research, “the global AI in the insurance industry generated $2.74 billion in 2021, and is anticipated to generate $45.74 billion by 2031.”
2. Decrease costs
Examples of cost reduction includes reduced claims cost which is made up of two elements - claim amount and claim survey cost. According to KPMG, “investment in AI in insurance is expected to save auto, property, life and health insurers almost US$1.3 billion while also reducing the time to settle claims and improving customer loyalty.”
3. Increase customer satisfaction
AI-supported customer service and quality assurance AI systems can optimize claim processing and customer experience. Even small tweaks, optimized by AI algorithms can have massive effects. According to an IBM report, “claimants are more satisfied if they receive 80% of the requested compensation after 3 days, than receiving 100% after 3 weeks.”
What stops you? Five data challenges when building AI/ML models in traditional insurance companies
We spoke to insurance data practitioners about their day-to-day challenges regarding data consumption. There is plenty of room for improvement and for new tools making data more accessible, safer and compliant throughout the data product life-cycle. AI in insurance suffers from a host of problems, not entirely unrelated to each other. Here is a list of their five most pressing concerns.
1. Not enough data
Contrary to popular belief, insurance companies aren’t drowning in a sea of customer data. Since insurance companies have far fewer interactions with customers in comparison with banks or telcos, there is less data available for making important decisions, health insurance being the notable exception. Typically the only time customers interact with insurance providers is when the contract is signed and if everything goes well, the company never hears from them again.
External datasources, like credit scoring data won’t give you a competitive edge either - after all it’s what all your competitors are looking at too. Also, the less data there is, the more important architecture, data quality and the ability to augment existing data assets becomes. Hence, investment into data engineering tools and capabilities should be at the top of the agenda for insurance companies. AI in insurance cannot be made a reality without meaningful, high-touch data assets.
2. Data assets are fragmented
To make things even more complicated, data sits in different systems. In some countries, insurance companies are prevented by law from merging different datasets or even managing them within the same system. For example property-related and life-related insurances often have to be separated. Data integration is therefore extremely challenging.
Cloud solutions could solve some of these issues. However, due to the sensitive nature of customer data, moving to the cloud is often impossible, and a lot of traditional insurers still keep all their data assets on premise. As a result, a well-designed data architecture is mission-critical for ensuring data consumption. Today there often are no data integrations in place and a consolidated view across all the different systems is hard to create.
Access authorizations are also in place as well as curated datasets, but if you want to access any data, that is not part of usual business intelligence activities, the process is very slow and cumbersome, keeping data scientists away from what they do best: come up with new insights.
3. Cybersecurity is a growing problem
Very often cybersecurity is thought of as the task of protecting perimeters from outside attacks. But did you know, that 59% of privacy incidents originate with an organization’s own employees? No amount of security training can guarantee that mistakes won’t be made and so, the next frontier for cybersecurity efforts should tackle the data itself.
How can data assets themselves be turned into less hazardous pieces of themselves? Can old school data masking techniques withstand a privacy attack? New types of attacks are popping up attacking data with AI-powered tools, trying to reidentify individuals based on their behavioral patterns.
These AI-based re-identification attacks are yet another reason to ditch data masking and opt for new-age privacy enhancing technologies instead. Minimizing the amount of production data in use should be another goal added to the already long list of cybersec professionals.
4. Insurance data is regulated to the extreme
Since insurance is a strategically important business for governments, they are subjected to extremely high levels of regulation. While in some instances insurance companies are required by law to share their data with competitors, in others, they are prevented from using certain parts of datasets, such as gender, by law.
It’s a complicated picture with tons of hidden challenges data scientists and actuaries need to be aware of if they want to be compliant. Data stewardship is becoming an increasingly important role in managing data assets and data consumption within and outside the walls of organizations.
5. Data is imbalanced
Class distribution of the data is often imbalanced: rare events such as fraud or churn are represented in only a fraction of the data. This makes it hard for AI and machine learning models to pick up on patterns and learn to detect them effectively. This issue can be solved on more ways than one and data rebalancing is something data scientists often do.
Data augmentation is especially important for fraud and churn prediction models, where only a limited number of examples are available. Upsampling minority classes with AI-generated synthetic data examples can be a great solution, because the synthesization process results in a more sophisticated, realistic data structure, than more rudimentary upsampling methods.
The low-hanging AI/ML fruit all insurance companies should implement and how synthetic data can make models perform better
Underwriting automation
Automating underwriting processes is one of the first low hanging fruits insurance companies reach for when looking for AI and machine learning use cases in insurance. Typically, AI and machine learning systems assist underwriters by providing actionable insights derived from risk predictions performed on various data assets from third party data to publicly available datasets. The goal is to increase Straight Through Process (STP) rates as much as possible.
Automated underwriting processes are replacing manual underwriting in ever increasing numbers across the insurance industry and whoever wins the race to maximum automation, takes the cake. There are plenty of out of the box underwriting solutions promising frictionless Robotic Process Automation, ready to be deployed.
However, no model is ever finished and historical data used to train these models can go out of date, leading underwriters astray in their decision making. The data is the soul of the algorithm and continuous monitoring, updates and validation are needed to prevent model drift and optimal functioning.
Pricing predictions
Actuaries have long been the single and mysterious source of pricing decisions. Prices were the results of massively complicated calculations only a handful of people really understood. Almost like a black box with walls made out of the most extreme performances of human intellect.
The dusty and mysterious world of actuaries is not going away any time soon due to the legal obligations insurance companies need to satisfy. However, AI and machine learning are capable of significantly improving the process with their ability to process much more data than any single team of actuaries ever could. Machine learning models make especially potent pricing models. The more data they have, the better they do.
Fraud, anomaly and account take over prediction
Rule based fraud detection systems get very complicated very quickly. As a result, fraud detection is heavily expert-driven, costly to do and hard to maintain. Investigating a single potential fraud case can cost thousands of dollars. AI and machine learning systems can increase the accuracy of fraud detection and reduce the number of false positives, thereby reducing cost and allowing experts to investigate cases more closely.
With constantly evolving fraud methods, it’s especially important to be able to spot unusual patterns and anomalies quickly. Since AI needs plenty of examples to learn from, rare patterns, like fraud need to be upsampled in the training data.
This is how synthetic data generators can improve the performance of fraud and anomaly detection algorithms and increase their accuracy. Upsampled synthetic data records are better than real data for training fraud detection algorithms and they are able improve their performance by as much as 10%, depending on the type of machine learning algorithm used.
Next best offer prediction
Using CRM data, next best offer models support insurance agents in their upselling and cross selling activities. These product recommendations can make or break a customer journey. The accuracy and timing of these personalized recommendations can be significantly increased by predictive machine learning models. Again, data quality is a mission-critical ingredient - the more detailed the data, the richer the intelligence prediction models can derive from it.
To make next best action AI/ML models work, customer profiles and attributes are needed in abundance, with granularity and in compliance with data privacy laws. These recommendation systems are powerful profit generating tools, that are fairly easy to implement, given that the quality of the training data is sufficient.
Churn reduction
Even a few percentage points reduction in churn could be worth hundreds of thousands of dollars in revenue. It’s not surprising that prediction models, similar to those used for predicting next best offers or actions, are frequently thrown at the churn problem. However, identifying customers about to lapse on their bills or churn altogether is more challenging then making personalized product recommendations due to the lack of data.
Low churn rates lead to imbalanced data where the number of churning customers is too low for machine learning algorithms to effectively pick up on. Churn event censorship is another issue machine learning models find problematic, hence survival regression models are better suited to predict churn than binary classifiers. In this case, the algorithm predicts how long a customer is likely to remain a customer.
A series of churn prevention activities can be introduced for groups nearing their predicted time to event. Again, data is the bottleneck here. Loyalty programs can be great tools not only for improving customer retention in traditional ways, but also for mining useful data points for churn prediction models.
Process mining
Insurance is riddled with massive, complicated and costly processes. Organizations no longer know why things get done the way they get done and the inertia is hard to resist. The goal of process mining is to streamline processes, reduce cost and time, while increasing customer satisfaction and compliance.
From risk assessments, underwriting automation, claims processing to back office operations, all processes can be improved with the help of machine learning. Due to the multi-faceted nature of process mining, it’s important to align efforts with business goals.
Get hands-on with synthetic training data
The world's most powerful, accurate and privacy-safe synthetic data generator is at your fingertips. Generate your first synthetic dataset now for free straight from your browser. No credit card or coding required.
The four most inspiring AI use cases in insurance with examples
Startups are full of ideas and are not afraid to turn them into reality. Of course, it’s much easier to do something revolutionary from the ground up, then to tweak an old structure into something shiny and new. Still, there are tips and tricks ready to be picked up from young, ambitious insurtech companies. Go fast and break things should not be one of them though, at least not in the insurance industry.
1. Risk assessment with synthetic geospatial imagery
How about going virtual with remote risk assessments? Today’s computer vision technology certainly makes it possible, where visual object detection does the trick. These models can assess the risks associated with a property just by looking at them - they recognize a pool, a rooftop, or a courtyard. They have a good idea of the size of a property and its location.
In order to train these computer vision programs and to increase their speed and accuracy, synthetic images are used for training them. AI-powered, touchless damage inspections are on offer too for car insurers, ready to buy third party AI solutions.
2. Detect fraud and offer personalized care to members
Anthem Inc teamed up with Google Cloud to create a synthetic data platform that will allow them to detect fraud and offer personalized care to members. This way, medical histories and healthcare claims can be accessed without privacy issues and used for validating and training AI designed to spot financial or health-related anomalies that could be signs of fraud or undetected health issues, that could benefit from early interventions.
Open data platforms are becoming more and more common driven by synthetic data technology. Humana, a large North American health insurance provider published synthetic medical records for research and development while keeping the privacy of their customers intact.
3. AI-supported customer service
Natural Language Processing is one of the areas in artificial intelligence which experienced a massive boom in recent years. The transcripts of calls are a treasure trove of intelligence, allowing insurance companies to detect unhappy customers with sentiment analyses, preventing churn with pre-emptive actions and reducing costs on the long run.
By monitoring calls for long pauses, companies can identify customer service reps who might be in need of further training to improve customer experience. Customer service reps can also receive AI-generated help in the form of automatically created summaries of customer histories with the most important, likely issues flagged for attention.
Using transcripts containing sensitive information for training AI systems could be an issue and to prevent privacy issues, AI-generated synthetic text can replace the original transcripts for training purposes. Conversational AI also needs plenty of meaningful training data, otherwise you’ll end up with chatbots destroying your reputation faster than you can build it back up.
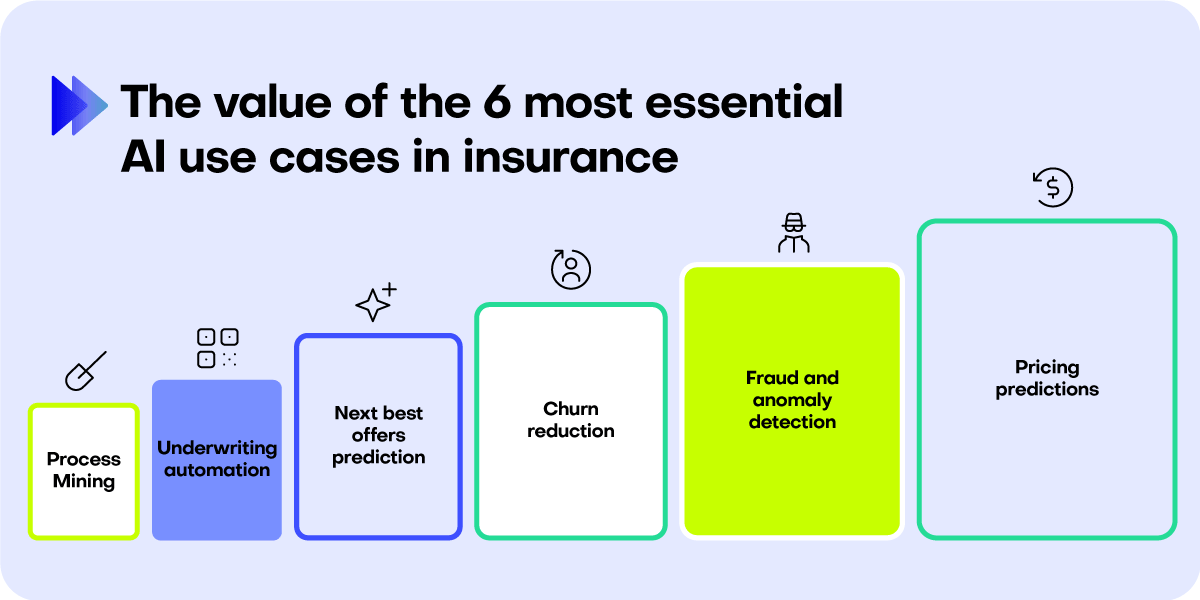
The six most important synthetic data use cases in insurance
When we talk to insurance companies about AI, the question of synthetic data value comes up quickly. Making sure that companies take the highest value out of synthetic data is crucial. However, not all use cases come with the same value. For example, when it comes to analytics, the highest value use cases come with the highest need for synthetic data assets.
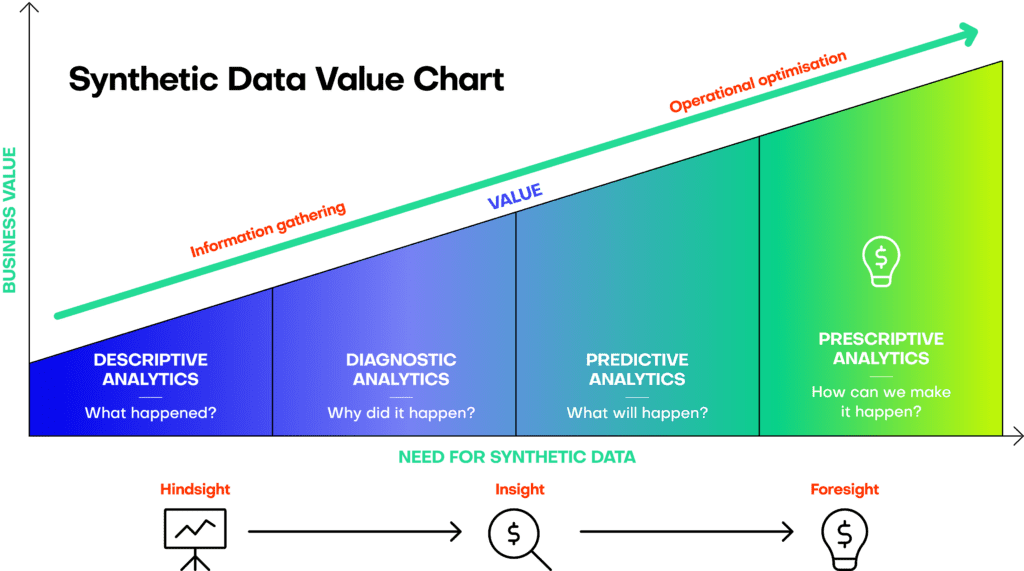
AI-generated synthetic data is not only an essential part of the analytics landscape. Here are the most important synthetic data use cases in insurance, ready to be leveraged.
Data augmentation for AI and machine learning development
The power of generative AI is evident when we see AI-generated art and synthetic images. The same capabilities are available for tabular data, adding creativity and flexibility to data generation. Unlike other data transformation tools, AI-powered ones are capable of handling datasets as a whole, with relationships between the data points and the intelligence of the data kept intact.
Examples of these generative data augmentation capabilities for tabular data include rebalancing, imputation and the use of different generation moods from conservative to creative. To put it simply, MOSTLY AI's synthetic data generator can be used for designing data, not only to generate it. Your machine learning models trained on synthetic data can benefit from entire new realities, synthesized in accordance with predefined goals, such as fairness or diversity.
Data privacy
Synthetic data generators were first built to overcome regulatory limitations imposed on data sharing. By now, synthetic data generators are a full-fledged privacy-enhancing technology with robust, commercially available solutions and somewhat less reliable open source alternatives. Synthetic data is a powerful tool to automate privacy and increase data access across organizations, however, not all synthetic data is created equal. Choose the most robust solution offering automated privacy checks and a support team experienced with insurance data.
Explainable AI
AI is not something you build and can forget about. Constant performance evaluations and retraining are needed to prevent model drift and validate decisions. Insurance companies are already creating synthetic datasets for retraining models and to improve their performance. With AI-regulations soon coming into effect, providing explainability to AI models in production will become a necessary exercise too.
Modern AI and machine learning models work with millions of model parameters, that are impossible to understand unless observed in action. Transparent algorithmic decisions need shareable, open data assets, allowing the systematic exploration of model behavior.
Synthetic data is a vital tool for AI explainability and local interpretability. Providing a window into the souls of algorithms, data-based explanations and experiments will become standard parts of the AI lifecycle. AI in insurance is likely to get frequent regulatory oversight, which makes synthetic training data a mission-critical asset.
Data sharing
Since insurance companies tend to operate in a larger ecosystem made up of an intricate sales network, individual agents, travel agencies, service providers and reinsurers, effective, easy and compliant data sharing is a mission-critical tool to have at hand.
At MOSTLY AI, we have seen large insurance companies flying data scientists over to other countries in order to access data in a compliant way. Life and non-life business lines are strictly separated, making cross-selling and intelligence sharing impossible to do. Cloud adoption is the way to go, however, it’s still a distant future for a lot of traditional insurance companies, whose hands are tied by regulatory compliance. Insurance companies should consider using synthetic data for data sharing.
Since AI-generated synthetic data retains the intelligence contained within the original data it was modelled on, it provides a perfect proxy for data-driven collaboration and other datasharing activities. Synthetic data can safely and compliantly be uploaded to cloud servers, giving a much needed boost to teams looking to access high-quality fuel for their AI and machine learning projects.
Humana, one of the largest North American health insurance providers created a Synthetic Data Exchange to facilitate the development of new products and solutions by independent developers.
IoT driven AI
Smart home devices are the most obvious example of how sensor data can be leveraged for predictive analytics to predict, detect and even prevent insurance events. Home insurance products paired with smart home electronics can offer a powerful combination with competitive pricing and tons of possibilities for cost reduction.
Telematics can and most likely will revolutionize the way cars are insured, alerting drivers and companies of possibly dangerous driving behaviors and situations. Health data from smart watches can pave the way for early interventions and prevent health issues on time. Win-win situations for providers and policy holders as long as data privacy can be guaranteed.
Software testing
Insurance companies develop and maintain dozens if not hundreds of apps serving customers, offering loyalty programs, onboarding agents and keeping complex marketing funnels flowing with contracts. Bad test data can lead to serious flaws, however, production data is off-limits to test engineers both in-house and off-shore. Realistic, production-like synthetic test data can fill the gap and provide a quick and high-quality alternative to manually generated mock data and to unsafe production data.
How to make AI happen in insurance companies in five steps
1. Build lighthouse projects
In order to convince decision makers and get buy-in from multiple stakeholders, it’s a good idea to build lighthouse projects, designed to showcase what machine learning and AI in insurance is capable of.
2. Synthesize data proactively
Take data democratization seriously. Instead of siloing data projects and data pools and thinking by departments, synthesize core data assets proactively and let data scientists and machine learning engineers pull synthetic datasets on-demand from a pre-prepared platform. For example, synthetic customer data is a treasure trove of business intelligence, full of insights, which could be relevant to all teams and use cases.
3. Create a dedicated interdepartmental data science role
In large organizations, it’s especially difficult to fight against the inertia of massively complicated systems and departmental information silos. Creating a role for AI enablement is a crucial step in the process. Assigning the responsibility of collecting, creating and serving data assets and coordinating, facilitating and driving machine learning projects across teams from zero to production is a mission-critical piece of the organizational puzzle.
4. Create the data you need
Market disruptors are not afraid to think creatively about their data needs and traditional insurance companies need to step up their game to keep the pace. Creating loyalty programs for learning more about your customers is a logical first step, but alternative data sources could come in many forms.
Think telematics for increasing drivers’ safety or using health data from smart devices for prevention and for designing early intervention processes could all come into play. Improving the quality of your existing data assets and enriching them with public data are also possible by using synthetic data generation to upsample minority groups or to synthesize sensitive data assets without losing data utility. Think of data as a malleable, flexible modelling clay that is the material for building AI and machine learning systems across and even outside the organization.
5. Hire the right people for the right job
The hype around AI development is very real, resulting in a job market saturated with all levels of expertise. Nowadays, anyone who has seen a linear regression model up close might claim to be an experienced AI and machine learning engineer. To hire the best, most capable talent, ready to venture into advanced territories, you need to have robust processes in place with tech interviews designed with future tasks in mind. Check out this excellent AI engineer hiring guide for hands-on tips and guidance on hiring best practices. AI in insurance needs not only great engineers, but a high-level of domain knowledge.


