
On July 3rd the first Stage of the MOSTLY AI PRIZE concluded. And what a competition it has been! In the weeks up to the finale there was a lot of movement on the leaderboards of the two Challenges (the FLAT DATA Challenge and the SEQUENTIAL DATA Challenge) as can be seen in the two illustrations below. But starting in the mid of June one leader emerged and consequently climbed to the top: Gandagorn.
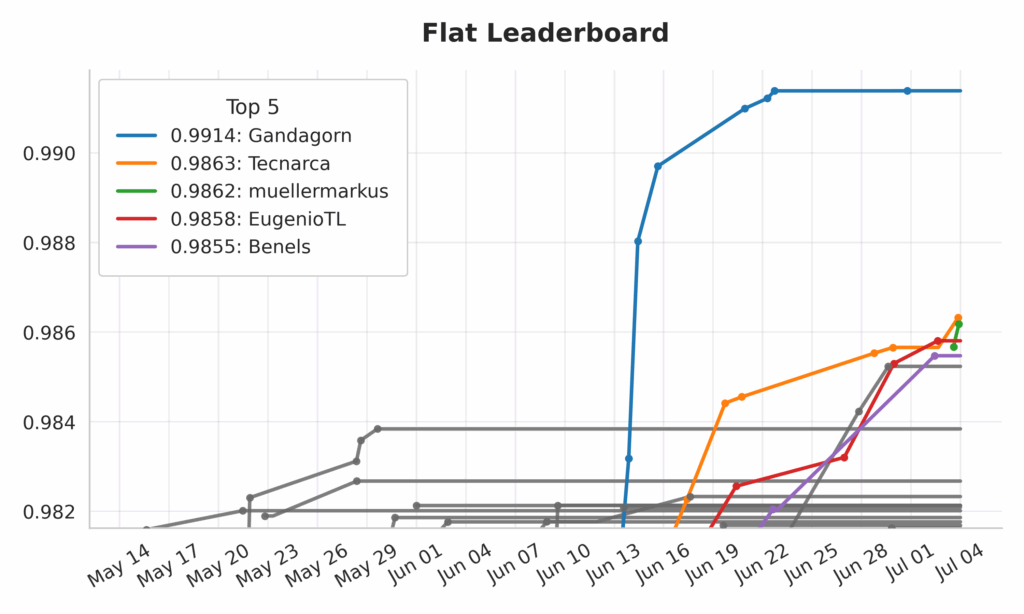
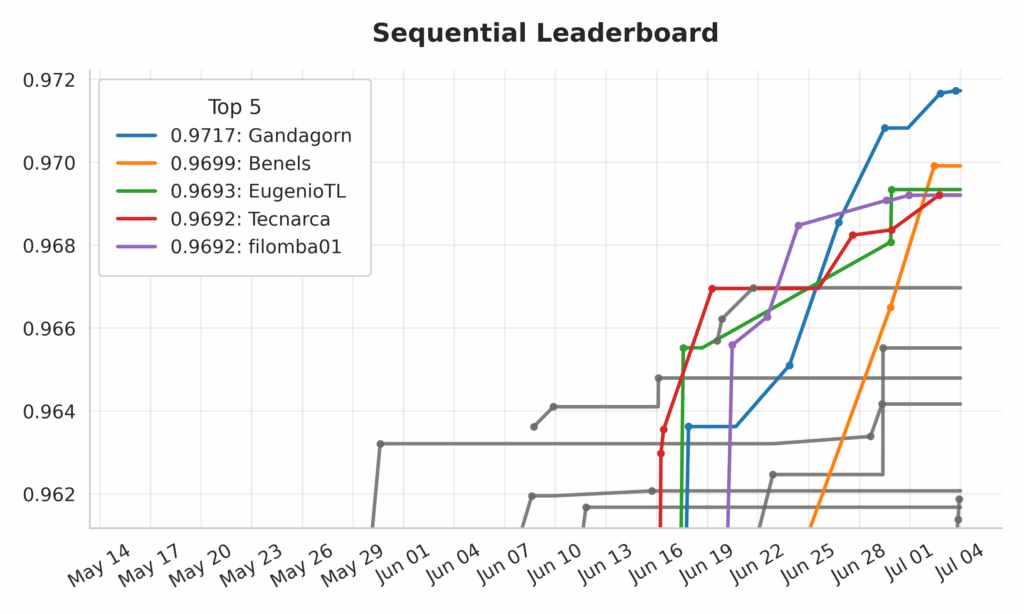
FLAT and SEQUENTIAL Challenge Leaderboards over the course of the PRIZE Duration
While that was certainly a strong indication as to who might win not only one but both challenges the competition was far from being over at that point as it entered Stage 2.
All the top leaders submitted their code and the Jury (suhaskowshik, adivekar-utexas, shree-gade, mplatzer, scriminaci, psitronic) got to work. The code submissions were then evaluated on dedicated GPU instances a total of 6 times each. The generated synthetic data was captured, and then again assessed with the same metrics as for Stage 1. And the results speak for itself:
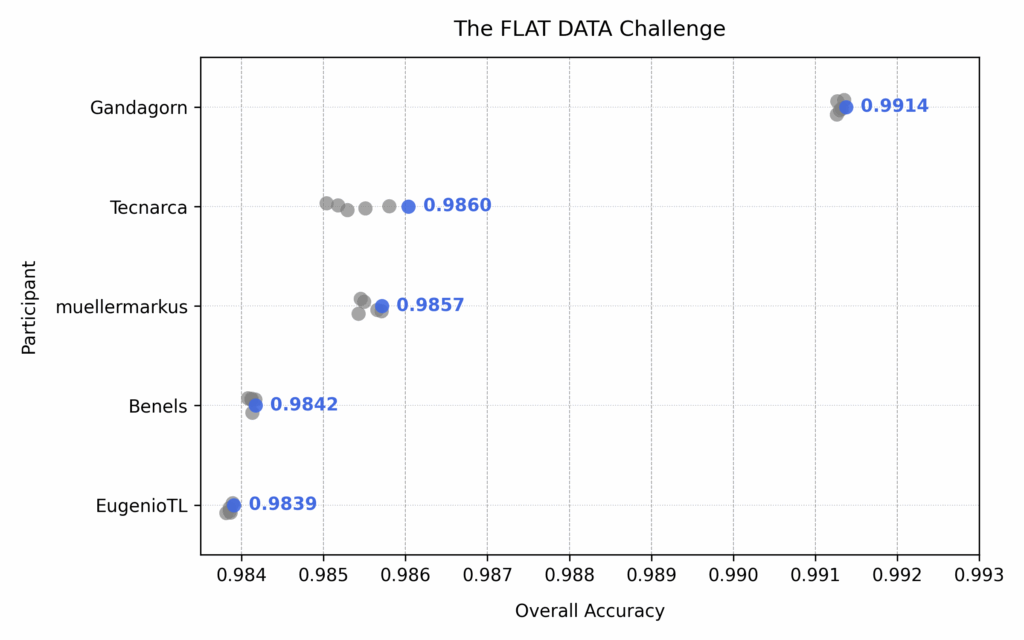
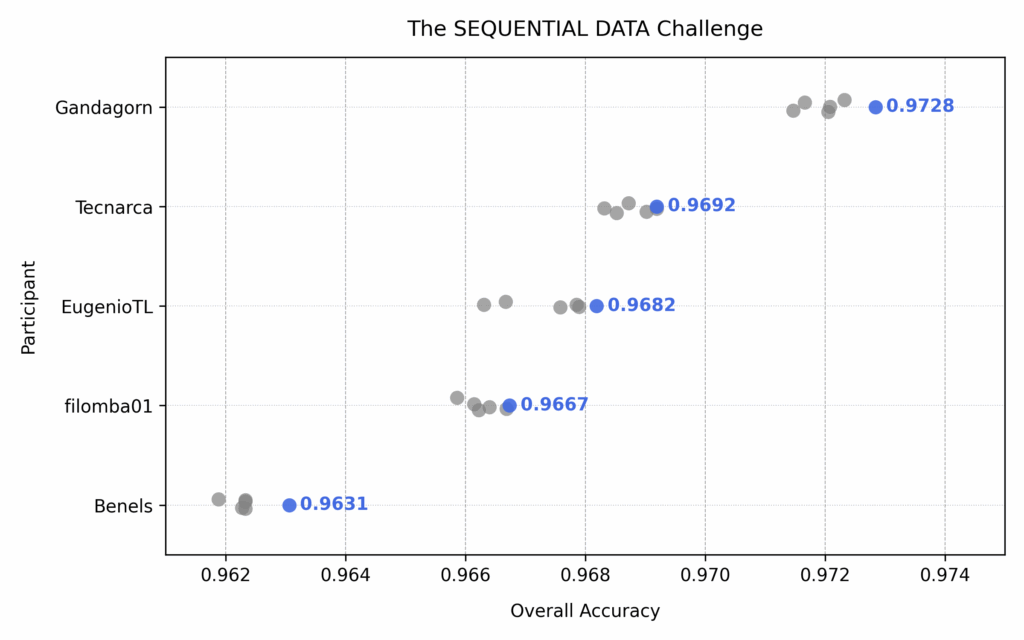
Results of the Stage 2 Evaluations for both Challenges
The interested reader can find all the datasets, all results as well as links to all open-sourced code submissions at mostly-ai/the-prize-eval!
Gandagorn is the grand winner of both Challenges!
There was no doubt anymore and Gandagorn, aka Daniel Gärber, won the FLAT Data Challenge by a very impressive margin and also the SEQUENTIAL Data Challenge with a lead over the 2nd place. And with that Daniel was able to take home the Grand PRIZE for both Challenges - $100,000!
Congratulations Daniel on this great job!

John (VP Go-To-Market MOSTLY AI) handing over the $100,000 PRIZE to Daniel
Our CEO Tobias had a chance to catch-up with Daniel on a short call to learn more about his journey with the PRIZE. Check out the full conversion here or read the transcript below.
Interview with Daniel
Tobias:
Hi, Daniel. Thanks for joining us today, and congratulations on winning the MOST AI Prize.
Really great performance—very impressed by what you achieved there.
Daniel:
Thank you. Thank you very much.
Tobias:
Just wanted to cover a couple of questions.
Maybe you can briefly introduce yourself?
Daniel:
Thank you. It's great to be here.
It was a really great competition to be part of, and it’s really, really nice to meet you now.
So, my name’s Daniel. I'm 27 years old and currently living in Vienna.
Originally, I’m from Styria. I studied computer science at the Technical University of Graz, moved to Vienna three years ago, and I’m now working at a startup.
We’re building AI-native asset management solutions—software for asset managers.
It’s quite machine learning-heavy, data science-heavy work. That’s always been my main goal: to work in this area.
I did a lot of Kaggle competitions back in the day, so that’s why this competition was especially interesting.
Usually, I focus on NLP—text, generative AI, ChatGPT—but I also like to broaden my perspective with tabular data, time series, graphs, and a bit of computer vision.
So it was a very nice competition for me to work with synthetic data.
Tobias:
Cool. Very cool. How did you hear about the prize?
Daniel:
I initially saw it on LinkedIn. I think I noticed a post quite a while before I actually joined the competition.
It was only the second time I came across it that I really thought about participating.
I remember lying in bed one weekend, scrolling LinkedIn, and seeing the post—it just clicked.
It looked like an interesting topic, especially now that synthetic data is becoming more important with the progress in machine learning and the growing need for privacy.
It was a great opportunity to learn more.
Tobias:
Were you already familiar with synthetic data, or was it new to you?
Daniel:
I knew what it was and roughly how to use it, but I hadn’t worked with it in a real project before.
I had done some synthetic data generation for graphs back at university—that was a bit of a different use case.
This competition was a nice way to dive deeper.
I also have a friend doing a PhD in privacy-preserving machine learning, and I’ve always struggled to understand exactly what she was doing.
So this was a good opportunity to learn more.
Tobias:
Eventually, you worked with the synthetic data SDK we at MOSTLY AI released earlier this year.
Did you consider any alternatives, or did you stick with our library?
Daniel:
Yeah, for me it was interesting to approach this with a blank mind.
I didn’t know which tools were best, so I explored. I checked papers, benchmarks, and tried out various tools.
There are many models out there. I played around with Synthecity and some other models that performed well in benchmarks.
But honestly, I stuck with the MOSTLY AI library.
I had a hard time setting up environments for other libraries, so I soon stopped and just focused on your SDK.
Tobias:
Nice to hear our library was easier to use!
How did you go about optimizing the synthetic data generation?
Any tricks or specific methods?
Daniel:
I tried a lot of different approaches—there’s always some trick involved.
My Kaggle experience helped me understand what might work.
I focused on feature engineering, fine-tuning, and post-processing.
I did a bit of model tuning and hyperparameter optimization.
I also read the papers you published for the SDK, which were very helpful.
But my main trick was post-processing.
I generated a much larger sample of synthetic data than needed, then refined and handpicked samples that gave high scores compared to the training set.
That approach worked much better than everything else I tried.
Tobias:
It definitely worked well! Was there a moment when you thought, “I might win this”?
Daniel:
Yes—when I first tried the oversampling approach.
I had uploaded a few solutions before, but when I tried this technique, I jumped up about 10 places into the top 5.
I thought, “Okay, this is working surprisingly well. If I optimize it further, I might actually have a winning solution.”
That’s when I really committed.
Before that, I was more casual—just trying to learn something—but then I got competitive.
Tobias:
And how much time did you spend on the challenge in total?
Daniel:
It’s hard to say exactly, but for the final month before the leaderboard closed, it was like having two full-time jobs.
I had my regular job, and then all my free time went into this.
The last two weeks were filled with long nights—at least until midnight or 1 AM.
It was mentally tough at times, but it paid off.
I’m glad I had support from my girlfriend and family during those intense moments.
Tobias:
What would you say was the biggest challenge?
Daniel:
From a technical perspective, it was working within the compute and memory constraints of the competition.
There wasn’t unlimited time or RAM, so I had to do a lot of low-level optimizations.
I used NumPy, SciPy, Numba—things that are really efficient.
Otherwise, the post-processing would have been too slow or memory-hungry.
I’m happy I got it down to something efficient and performant.
Tobias:
What’s the coolest or most insightful thing you learned during the competition?
Daniel:
Definitely how to work with and generate synthetic data.
That’s a skill I’ll always carry forward, and it will help me professionally.
I honestly don’t know why I didn’t look into it more deeply earlier.
In today’s machine learning world, data is often sensitive and tricky to use.
We need to be careful—and synthetic data is a powerful tool for that.
I also learned a lot about optimizing for performance, which is always useful as a developer.
Tobias:
Excellent.
Thank you so much for sharing those insights and taking us along on your journey.
You’re now the big winner—and this week is the prize ceremony.
You’ll also receive the prize money.
Any plans for how you’ll spend it?
Daniel:
Yes, I’ve made a few plans.
I’ve never had this amount of money in my account before, so it’s definitely new.
I’ll save and invest some for the future, but I’ll also spend a bit on myself.
My girlfriend and I are planning a trip to Japan next year, so I think the money will be well spent there.
Tobias:
For sure!
Again, thank you so much for participating—and congratulations on winning the prize.
Really outstanding work.
You’ve also given us great food for thought on how to improve or extend our SDK.
Daniel:
Thank you.
Also, thanks for organizing the competition—you really did a great job managing everything. That’s no easy feat!
Tobias:
Thank you.


