Netflix has been working on a recommender systems for years by then, were recognized for their business innovation as well as technical excellence, managed to hire the smartest data engineers and machine learning experts alike, and certainly knew all the ins and outs on movies, genres and popular actors. Still, they were eager to learn more.
The competition began on October 2nd, 2006. Within a mere six days a first contestant succeeded in beating their existing solution. Six days! From getting access to the data and taking a first look, to building a movie recommender algorithm from scratch, all the way to making more accurate predictions for over a million ratings than anyone before. Six days, from zero to world class.
It didn’t stop there. Within a year, over 40,000 teams from 186 countries entered the competition, all trying to improve on Netflix’ algorithms. And contestants increasingly started collaborating, sharing their learnings and taking lesson from others, formed bigger teams and ensembled ever more powerful models. Hardly ever before was there such a rich & big dataset on consumer behavior openly available. Together with a clearly stated and measurable objective, it provided a challenging, yet safe and fair sandbox for a worldwide community of intellectually driven engineers. All working together on advancing science, while, as a more than welcome side effect, also helping Netflix improve its core algorithm.
The Case for #OpenBigData
Being open enables to pick the brain of a wider group, to bring in fresh perspectives to existing challenges, to build upon the creative minds of the many. And with data being the lingua franca of today’s business world, being the common denominator across departments, across corporations, across industries, being open is really about sharing data, about sharing granular level data at scale!
Openly sharing customer data at scale in 2006 was a bold move. But it was no coincidence that it’s been done by Netflix. Already in their early years they successfully established a culture of excellence, curiosity as well as courage, well documented in “one of Silicon’s valley’s most important PowerPoint decks” [1]. Sharing data broadly takes courage, but is even more so a sign of curiosity and a thrive for excellence. No holding back, no hiding out, no making excuses. Netflix was never afraid of their competitors. They were afraid of stopping to strive for the best.
Openly sharing customer data at scale in 2019 is an (unl)awful move. Over the past years, the explosion in data volumes met a poorly regulated market, with little sanctions being imposed, and thus allowing excessive misuse of personal data. The tide though has turned, both the regulators as well as corporates are acknowledging privacy as a fundamental human right, one that is to be defended [2]. This is indeed a new era of privacy.
Unfortunately, this plays into the hands of modern-day corporate gatekeepers. Those decision makers, who’ve never really been fond of being transparent and being challenged, and thus reluctant to share “their” data in the first place. It turns out they found a new ally in defending their corporate data silos: privacy.
The Case for #SyntheticData
This is the point where one needs to tell the lesser known part of the Netflix Prize story: As successful the competition was for the company overall, they also had to pay their prize at court. In fact, they were forced to cancel their second machine learning challenge, that was planned for 2011 [3]. Netflix had misjudged their anonymization measures they’ve had put in place. Even though they limited data to movie ratings and their dates, merely linked to a scrambled user ID, it proved inefficient to prevent re-identification. It had taken only 16 days, after the data was released for an outsider (with no superhuman hacking skills) to link these user IDs with freely available public data – with enough time left at hand to write up a whole paper on de-anonymization [4]. Netflix had unintentionally exposed the full movie history for parts of their customer base, with no chance of making that privacy infringement undone. A decade later Facebook had to learn that same painful lesson. Once the data is out and you failed to properly anonymize, no matter how good your intentions might have been, you will have a hard time to undo your actions.
This risk of re-identification in large-scale data is by now well understood by privacy and security experts [5], and yet still widely under-estimated by the corporate world. That’s why these experts face a challenging role within organizations, as they need to educate their colleagues, that most anonymization attempts for big data in fact fail to provide safety for their customers. And these experts are forced to give a NO more often than a YES to a new initiative, to a new innovation project, in order to keep privacy safe and secure.
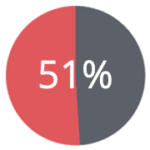
of mobile phone owners are re-identified simply by 2 antenna signals, even when coarsened to the hour of the day
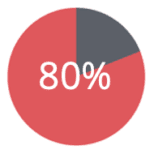
of credit card owners are re-identified by 3 transactions, even when only merchant and the date of transaction is revealed
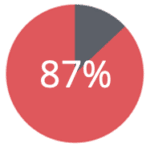
of all people are re-identified, merely by their date-of-birth, their gender and their ZIP code of residence
So, this is the big quest of our time: How to be open, while being private at the same time? How to put big data to good use, while still protecting each and everyone’s right for privacy? How to foster data-driven, people-centric and innovative societies and organizations, all at the same time, while not giving up an inch on safeguarding privacy?
We, at Mostly AI, set out to solve this challenge, and developed a one-of-its-kind technical solution to this long-standing problem: an AI-based synthetic data generator. One that learns based on actual behavioral data, to generate statistical representative synthetic personas and their data. Synthetic data, that can be broadly shared, internally as well as externally, without exposing any individuals. It’s all the value of the original data, but without the privacy risk.
This is 2019. It’s time to protect privacy, as well as to embrace the power of open again. It’s time to #GoSynthetic!


