
TL;DR
- Synthetic data generation methods changed significantly with the advance of AI
- AI-generated, sample-based synthetic data is an entirely different beast than random or mock data
- Stochastic processes are still useful if you care about data structure but not content or meaning
- Rule-based synthetic data generation methods can be used for simple use cases with low, fixed requirements toward complexity
- Use deep generative models to automatically retain structure as well as information of data at scale to unlock private data and reduce model-to-market time
An overview of synthetic data generation methods
Not all synthetic data is created equal and in particular, synthetic data generation methods today are very different from what they were 5 years ago. Let’s take a look at different methods of synthetic data generation from the most rudimental forms to the state-of-the-art methods to see how far the technology has advanced! In this post we will distinguish between three major methods:
- The stochastic process: random data is generated, only mimicking the structure of real data.
- Rule-based data generation: mock data is generated following specific rules defined by humans.
- Deep generative models: rich and realistic synthetic data is generated by a machine learning model trained on real data, replicating its structure and the information it contains.

Which synthetic data generation method should you choose? Evaluation metrics 101
The choice of method depends on the use case and should be evaluated - if possible - both by an expert on the data synthesis and by a domain expert, who is familiar with the data and its downstream usage.
In addition to use-case-specific criteria, several general aspects can be used to evaluate and compare the different synthetic data generation methods available.
- Computation: how much compute is needed to generate data or to build a model.
- Human labor: how much human expertise and labor goes into the generation process.
- System complexity: how difficult it is to build such a data generation system.
- Information content: how much information is present in the synthetic data.
The stochastic process: when form matters more than content
If the structure of the desired synthetic data is known, and the data distribution is irrelevant - when random noise is all you need - the stochastic process is a perfect synthetic data generation method.
An example would be where the synthetic dataset should take the form of a CSV file with a specific number of columns and rows. A random number generator can be used to fill the fields following a defined distribution.
The applicability of such a process is limited to cases where the content of the synthetic data is irrelevant and random noise is good enough in place of real data. Examples of such applications would be stress testing systems, where a huge amount of random data is generated on the fly to evaluate how systems behave under heavy use.
- Computation: generating random data has very small computational needs and can be performed on the fly whenever random data is needed.
- Human labor: the data structure of the synthetic data can be defined easily, or inferred from an existing dataset, reducing the human expertise and labor to a minimum.
- System complexity: these systems are the easiest to build and challenges during implementation often concern computational efficiency to maximize the amount of data that can be generated with given resources.
- Information content: the generated synthetic data contains no relevant information.
Rule-based synthetic data generation: the human-powered machine
The obvious downside to synthetic data generation methods using stochastic processes is their limited use-cases since the resulting data is random and contains no real information.
Rule-based synthetic data generation methods improve on that by using hand-generated data following specific rules defined by humans.
The complexity of those rules can vary from very simple, taking only the desired data type of a column into account (i.e. if a column contains numeric, categorical, or text data), to more sophisticated rules, that define relationships between various columns and events. The amount of human labor and expertise needed, as well as the information contained in the generated data, are therefore completely dependent on the defined rules.
Thus, rule-based synthetic data generation methods come with three additional challenges:
- Scalability: datasets containing many different interdependent columns in a multi-table configuration easily need hundreds of complex and intertwined rules. Adding additional rules gets more and more difficult, practically limiting the maximum complexity of the data that can be modelled.
- Bias: since the rules are defined by human experts, the bias of those experts is reflected in the rules and is therefore present in the generated data. Some table columns might reflect a clearly defined business logic, where bias is part of the agreed policy, but others (e.g. customer behavior, or patient history) might be more susceptible to unconscious human bias.
- Drift: real world data is continuously changing, so rules need to be altered to reflect that change. Complex rule-based systems need effective change management governing the conditions and deciding which rules have to be adapted to reflect changes in the context of their application.
Coping with these challenges can be very difficult, and in many cases, they prove to be deal-breakers. Specifically, Scalability and Drift prevent rule-based systems to be used in applications that require flexibility and support for changing data requirements, effectively limiting its applicability to use cases where the scope and the data requirements are exactly known and will not change. But if these challenges are successfully met, a rule-based system can be a good enough choice for testing in applications, ranging from the generation of tabular data to multimedia content.
However, in any case, no additional information can be extracted from the rule-based synthetic data, than what was already known beforehand and manually encoded into the rules. Thus, these datasets offer no value for analytics, nor for decision support, nor for training machine learning models.
Several web-based tools exist where one can manually define the structure and simple rules to generate tabular data. These kinds of synthetic data generation methods can then be used for testing purposes in software development, or integration tests, ranging from the most typical to the testing of specific edge cases.
- Computation: the computational resources needed to run such a system are completely governed by the number and the complexity of the rules, but in general, the method’s computation needs can be classified as minor to moderate.
- Human labor: the amount of human labor and expertise needed to use such a system is extensive and much higher than any of the other methods described.
- System complexity: the system grows with the number and complexity of the rules supported. In addition, the format/language and interface used to describe rules can be a major contributor to system complexity. In general, the method’s system complexity is high.
- Information content: the information contained in the generated data is limited only by the applied rules.
AI-generated synthetic data: learning by example
Generative AI has revolutionized many things, synthetic data generation methods being one of the prime examples. Synthetic data generation methods using generative algorithms replace code with data. The rules of rule-based synthetic data generation are inherently contained in data samples, upon which AI-powered synthetic data generators are trained. Generative AI models are a class of statistical models that learn the distribution of training data and can be used to generate new data following that distribution.
Applying generative models from machine learning, it is possible to train a machine learning model (e.g. an artificial neural network) with real data so that it learns the structure and the information contained and is able to generate new synthetic data.
Synthetic data generators can be open source, like MIT's synthetic data vault or proprietary, like MOSTLY AI's synthetic data platform. When comparing synthetic data quality, MOSTLY AI's robust commercial solution outperformed SDV in a research conducted by the Joint Reserach Centre of the European Commission.
The human guidance needed by such a system can be minimal. In the best case, no human interaction is needed and the machine learning model is trained automatically.
The complexity of the data that can be learned by such a model is, primarily, limited by the data available and the model capacity (i.e. model architecture and hyperparameters). If the data requirements change, no significant adjustments are needed, simply a new model needs to be trained on the actual data.
Due to the power of machine learning models mimicking the training data, three new challenges unique to this synthetic data generation method have to be addressed:
- Data similarity: The success of replicating the information contained within the original data depends on data complexity and the capacity of the model one chooses to use. For best results, special attention must be paid to testing and documenting the similarity of the synthetic data compared to the original data used to train the model. The metric of similarity is application-specific, but methods from descriptive statistics can be used to analyze the univariate and multivariate distribution, as well as the correlation between features for the synthetic and training data.
- Privacy: with great power comes great responsibility. With many machine learning models being prone to overfitting, one needs to take particular caution to prevent the memorization of training examples. This is particularly important, if the training data is privacy-sensitive, and must be protected.
- Business rules: generative models learn the distribution of features in the training data, and don't yet have a human-like understanding of what a feature means, or what relational qualities exist between features. However, a well-trained generative model will be able to learn most of the rules and retains relationships contained within the training data. Those rules, which are not yet adhered to, can be enforced by simply filtering out the few invalid records as part of the post-processing.
Once these challenges have been met, the applications of AI-powered synthetic data generation methods are almost limitless, and even go beyond what is possible with real data.
Two unique opportunities arise with the use of generative models. One is the use of synthetic data in place of the original data that cannot be accessed because of legal and privacy reasons, and the second is the use of synthetic data within a company to reduce the development time of machine learning models.
One such example, where synthetic data is playing a key role in unlocking original data protected for privacy reasons, is in finance. Here, synthetic data is used for example to improve fraud detection, since it contains the statistical properties necessary for improving fraud detection systems, without exposing the privacy of individuals.
Sharing data across departments and even country borders becomes a seamless process when using a high quality, accurate and privacy compliant deep generative tool, like our very own MOSTLY AI synthetic data platform. As shown in our benchmarking study, MOSTLY AI is the world’s most accurate deep generative tool, which makes the most of all deep generative model advantages, such as the highest levels of statistical utility.
Another example is the use of synthetic data by data science, machine learning and business intelligence units. In most working environments, data access is strictly regulated resulting in time-consuming processes. Working with synthetic data instead of the original makes it possible to build models much faster and to reduce model-to-market time.
We have shown in a recent study that models trained on synthetic data achieve comparable results, and in some cases even outperform models trained on original data. AI model development is increasingly relying on synthetic training data due to the possibilities of data augmentation during the synthesization process, turning data into modelling clay for data scientists and machine learning engineers.
Test data generation can also massively benefit from the power of AI. Synthetic test data generators can pick up on business rules encoded in the production data and automatically recreate them. The resulting synthetic test data is highly realistic and covers many more business cases than manual data generation ever could.
- Computation: the training of machine learning models is in general very compute-intensive, but the problem can be mitigated by the use of special hardware (e.g. GPU, TPU, ASIC as well as others) and by the use of cloud computing.
- Human labor: an optimal machine learning system can be application-agnostic, limiting user interaction to the selection of the training data used to create the models and to some post-processing - depending on the qualities of the dataset and its application.
- System complexity: Machine learning-enabled data synthesis is by far the most complex of the described systems, as it contains multiple complex sub-components (e.g. machine learning model, training infrastructure, and user applications to interact with the system). The architecture of generative models for tabular data and its power to solve previously untouched problems, such as human bias and imbalances is an open research topic full of future potentials.
- Information content: a model capable of generating synthetic data with high similarity to the training data maximizes information content, surpassing rule-based systems by a huge margin and in some cases is even better than raw data.
For a more in-depth introduction to generative models, take a look at this blog post by OpenAI or Stanford’s free course on the subject.
Rundown
Here is a summary of the synthetic data generation methods compared and their performance on the metrics used to evaluate them.
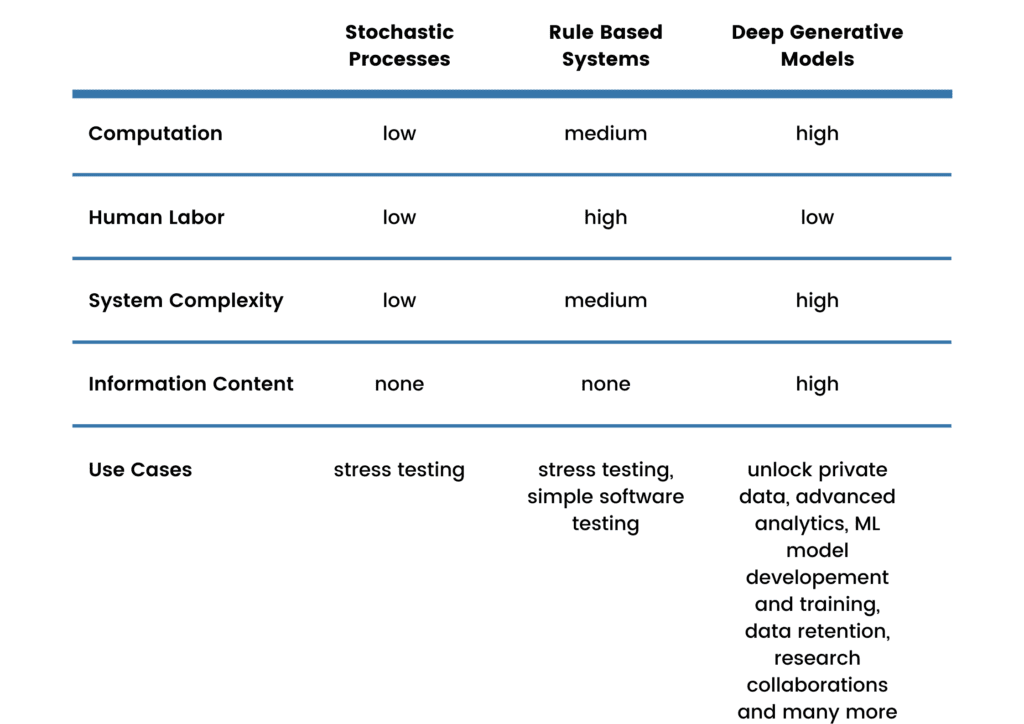
How to choose the right synthetic data generation method?
After having discussed the capabilities and challenges of the various synthetic data generation methods, how do you decide which one matches best the requirements and use cases at hand? Two simple questions shall guide your decision:
- Do you have resources/expertise available to build your own system, and
- Does the synthetic data need to be realistic as well as representative?
Solutions making use of stochastic processes and rule-based systems are highly dependent on their use case, and almost always require the development of new property software. Libraries like cayenne or PyRATA can support such efforts, but require expertise, resources, and will to be maintained.
If the synthesized data has to be realistic, stochastic processes are out of the question and rule-based systems only make sense if it is clear what the data should look like and that description can be written in code.
If in-house development is not an option and the synthetic data has to be as realistic and representative as possible, the use of ML-enabled systems as a service is the best course of action.
How is MOSTLY AI making the most out of generative models?
With MOSTLY AI's synthetic data platform we are addressing the unique challenges coming with generative models. Our synthetic data generation platform comes with built-in privacy safeguards, preventing overfitting, and eliminating the risk of re-identification. Synthetic data is exempt from data privacy regulations, freeing up your previously untouched data assets for sharing and utilization. What’s more, generated synthetic datasets come with automated quality assurance reports which make the assessment of the quality quick and painless.
We at MOSTLY AI are proud to serve customers worldwide. Our clients use synthetic data for finance, insurance and telecommunications use cases. Curious? Head over to the browser version of our product and generate synthetic data yourself for free forever, up to 100K rows a day! Hopefully, this post has been useful to you and provided you with a better understanding of how synthetic data generation has evolved from simple stochastic processes to sophisticated deep generative models. Feel free to reach out and contact us, either with feedback, questions, or any other concerns.


