
TL;DR: Databricks research shows that 90% of businesses are holding back on GenAI due to concerns over accuracy, safety, and governance. MOSTLY AI helps you overcome these challenges by using privacy-preserving synthetic text to safely fine-tune your custom LLMs.
Introduction
Fine-tuning a model is the process of adapting a pre-trained LLM to instill specific knowledge or domain expertise. By training the model on additional, domain-specific data, it can perform targeted tasks and better understand the nuances of a particular field. However, such data is often sensitive and proprietary, containing private information about customers. Synthetic text offers a safe solution, enabling LLMs to be fine-tuned on your proprietary data insights while preserving customer privacy.
In part 1 of our mini-series on fine-tuning LLMs with synthetic text, we’ll demonstrate how easy it is to create privacy-preserving synthetic text in Databricks to fine-tune an LLM.
Step 1: Data preparation
We used the default databricks/databricks-dolly-15k and followed the required data preparation by organizing the dataset into 'prompt' and 'response' columns to ensure compatibility with Mosaic AI's fine-tuning service. This dataset was chosen to show synthetic data's ability to retain the original data's statistical patterns, not to highlight improvements from domain-specific fine-tuning.
# read source data
catalog_path = "mostly_pt.finetuning_data.dolly_databricks"
# load from the unity catalog into spark df
df = spark.table(catalog_path)
# remove unnecessary columns
df = df.drop('context', 'category')
# rename relevant columns
df = df.withColumnRenamed('instruction', 'prompt')
# filter df to less than 1k char
df_1k = df.filter((F.length(F.col('prompt')) <= 1000) &
(F.length(F.col('response')) <= 1000))
# split into train and holdout
df_1k_train, df_1k_holdout = df_1k.randomSplit([1 - holdout_fraction, holdout_fraction], seed=42)
# save dolly_databricks_trn
df_1k_train.write.mode("overwrite").saveAsTable("mostly_js.mosaic_sourcedata.dolly_databricks_trn")
# save dolly_databricks_holdout
df_1k_holdout.write.mode("overwrite").saveAsTable("mostly_js.mosaic_sourcedata.dolly_databricks_test")Step 2: Generate synthetic text using MOSTLY AI in a Databricks notebook
The experiment starts with our dataset in a 'restricted' Databricks catalog, simulating enterprise data access controls. Using MOSTLY AI's python client, we read the data, train a generator, create a synthetic dataset, and write it to a new 'unrestricted' catalog.
# install MOSTLY AI in Databricks notebook
%pip install -U mostlyai
dbutils.library.restartPython()
# initialize the MOSTLY AI client
from mostlyai import MostlyAI
mostly = MostlyAI(api_key='your_api_key')
# create configuration for generator
config = {"name": "dolly_databricks_trn_sd",
"description": None,
"tables": [
{
"name": "dolly_databricks_trn",
"sourceConnectorId": "816babbb-31a4-46be-ba57-13c096efaf7a",
"location": "mosaic_sourcedata.dolly_databricks_trn",
"data": None,
"modelConfiguration": None,
"languageModelConfiguration": {
"model": "mistralai/Mistral-7B-v0.3",
"maxSampleSize": 11912,
"batchSize": 4,
"maxTrainingTime": 300,
"maxEpochs": 100,
"maxSequenceWindow": 4,
"enableFlexibleGeneration": True,
"valueProtection": True,
"rareCategoryReplacementMethod": "CONSTANT",
"compute": "d2dc8ce3-2861-4bea-95c2-99c01a2ed084"
},
"primaryKey": None,
"foreignKeys": None,
"columns": [
{
"name": "prompt",
"modelEncodingType": "LANGUAGE_TEXT"
},
{
"name": "response",
"modelEncodingType": "LANGUAGE_TEXT"
}
]
}
]
}
# train a generator on your data
g = mostly.train(data)
# create configuration for synthetic dataset
config_sd = { "generatorId": "8b357208-0b59-4ebf-82f5-abbb7bbe65f4", # This ID refers to the already created generator
"name": "dolly_databricks_trn_sd",
"description": None,
"tables": [
{
"name": "dolly_databricks_trn",
"configuration": {
"sampleSize": 11912,
"sampleSeedConnectorId": None,
"sampleSeedDict": None,
"sampleSeedData": None,
"samplingTemperature": 1,
"samplingTopP": 1,
"rebalancing": None,
"imputation": None,
"fairness": None,
"tabularCompute": None,
"languageCompute": "d2dc8ce3-2861-4bea-95c2-99c01a2ed084"
}
}
],
"delivery": {
"overwriteTables": True,
"destinationConnectorId": "19c7d057-7f45-436f-ae41-2e8ba19747b9",
"location": "mosaic_syntheticdata"
}
}
# generate a synthetic dataset
sd = mostly.generate(g)Step 3: Fine tune two LLMs using Mosaic AI in Databricks
Using Mosaic AI Model Training we finetune two LLMs, one with original data, one with synthetic data. We use the same training parameters for pre-trained model, sample size, compute, and number of epochs.
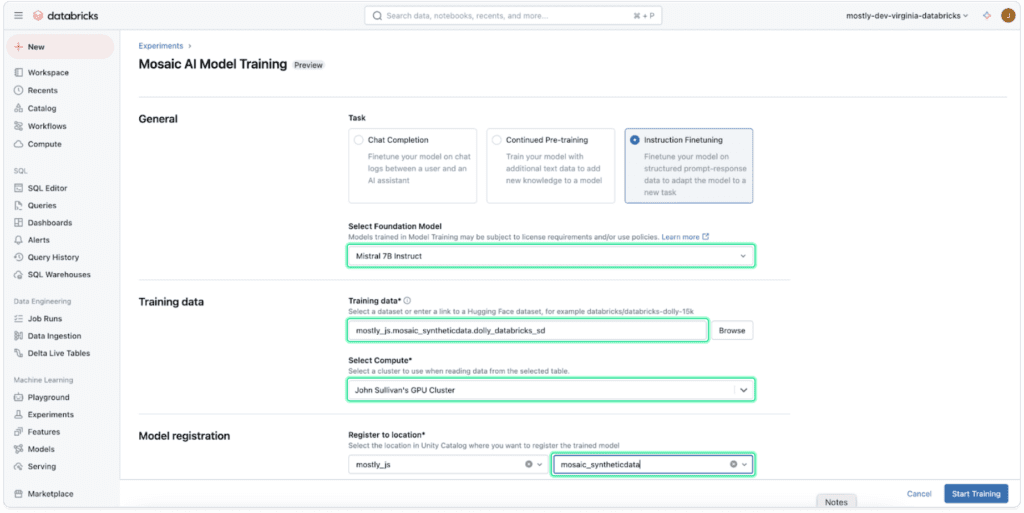
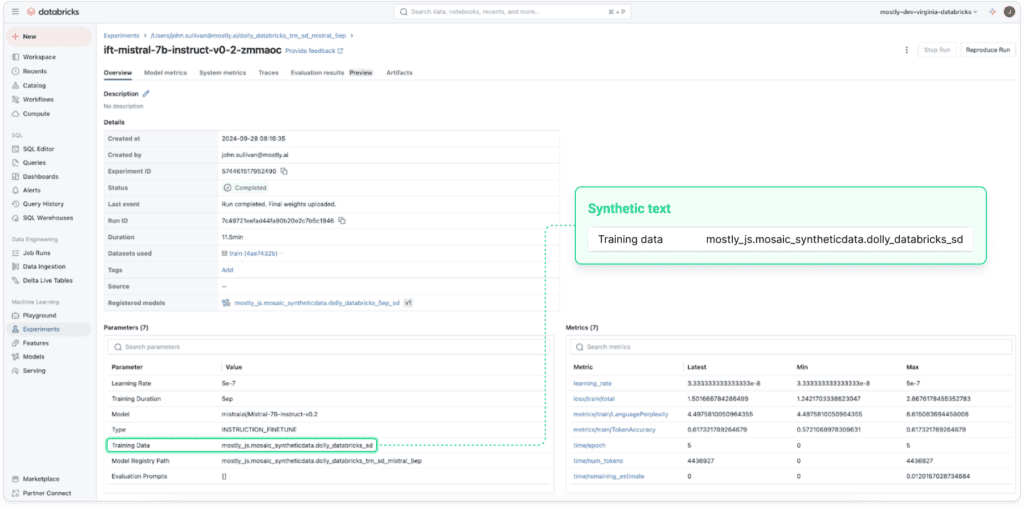
The resulting Mosaic AI training metrics demonstrate the synthetic text achieved lower loss (1.50 vs. 2.39), improved language perplexity (4.50 vs. 5.34), and slightly higher token accuracy (0.617 vs. 0.609) when compared with the original text.
In part 2 of our mini-series on fine-tuning LLMs with synthetic text, we’ll demonstrate how to use LLM-as-a-judge to evaluate the performance of synthetic text Vs the original text using a domain-specific dataset!


