
The protection of personally identifiable information (PII) has become an important concern in the data industry. As part of regular data-processing pipelines, datasets often need to be shared to be processed, for example with external clients or with cloud services for high-performance processing. During this process, it’s vital to ensure that sensitive information is not exposed. Data privacy compliance breaches can do serious harm to a company’s reputation and can result in high fines.
Data anonymization is a technique that can be used to protect personally identifiable information by removing or obfuscating sensitive data. Python is a popular programming language that can be used to perform data anonymization. In this article, we will explore four different techniques for data anonymization in Python: randomization, aggregation, masking, and perturbation.
Performing data anonymization in Python with open-source solutions can be a low-effort method for providing a basic level of privacy protection. However, there are important security tradeoffs to consider. While performing data anonymization in Python may be helpful in quick prototyping scenarios, these techniques are generally considered legacy data anonymization techniques that do not offer sufficient protection for data pipelines running in production. Fully synthetic data is the new industry-standard for production-grade data analysis.
What is data anonymization?
Data anonymization is the process of removing or obfuscating personally identifiable information from datasets. The goal of data anonymization is to protect the privacy of individuals whose data is included in the dataset. Anonymized data can be shared more freely than non-anonymized data, as the risk of exposing sensitive information is greatly reduced.
Data anonymization in Python techniques
There are several techniques that can be used for performing data anonymization in Python. These techniques include randomization, aggregation, masking, and perturbation.
1. Randomization
Randomization involves replacing sensitive data with random values. For example, a person's name might be replaced with a randomly generated string of characters.
Let’s look at how to perform data anonymization in Python using the randomization technique. We’ll start with something simple. We’ll use Python’s built-in random library together with pandas to scramble the characters in the Name column in an attempt to obscure the identities of the people in our dataset:
import pandas as pd
import random
# Load the dataset
df = pd.read_csv('sensitive_data.csv')
df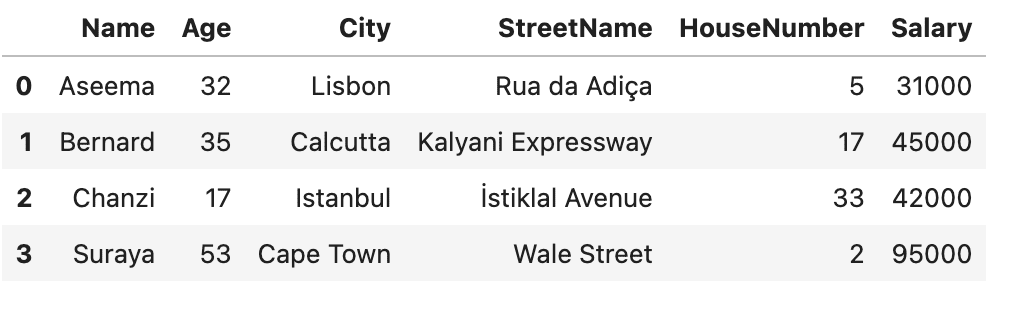
# define a function to randomize column values
def randomize_values(col_values):
col_values_list = list(col_values) # convert string to list
random.shuffle(col_values_list)
return ''.join(col_values_list) # convert list back to string
# apply the function to the desired column(s)
column_to_randomize = 'Name'
df[column_to_randomize].apply(randomize_values)
df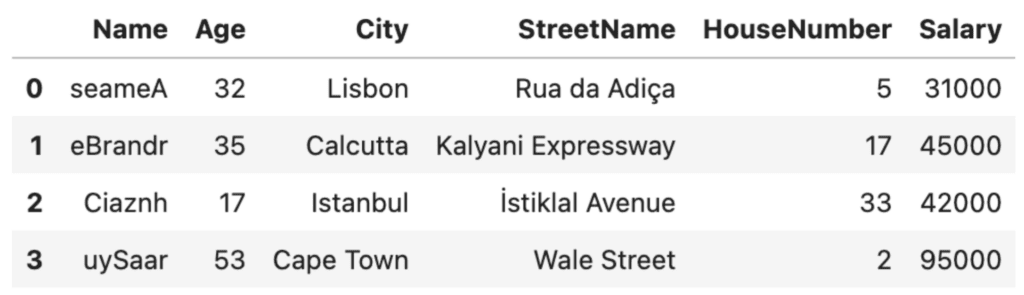
This is clearly a very rudimentary anonymization technique. The good thing about this technique: it’s quick. The bad thing: it may fool a third-grader…but not much more. The first letters of the names are still capitalized and from there, it’s not very hard to imagine what the real names might be, especially if someone has prior knowledge of the people in the dataset. Of even more concern is the fact that the addresses and ages are still clearly visible. We need to do better.
Let’s expand our randomize_values function to scramble all of the columns containing strings in our dataframe. We’ll use random.choices() instead of random.shuffle() to improve our anonymization:
import string
# define function that operates on entire dataframe
def randomize_values(df):
for column in df.columns:
if df[column].dtype == 'O': # check if column has object dtype
df[column] = [''.join(random.choices(string.ascii_letters + string.digits, k=10)) for _ in range(len(df))] # generate a list of random strings
return df
# apply function to dataframe
df_rand = randomize_values(df)
df_rand
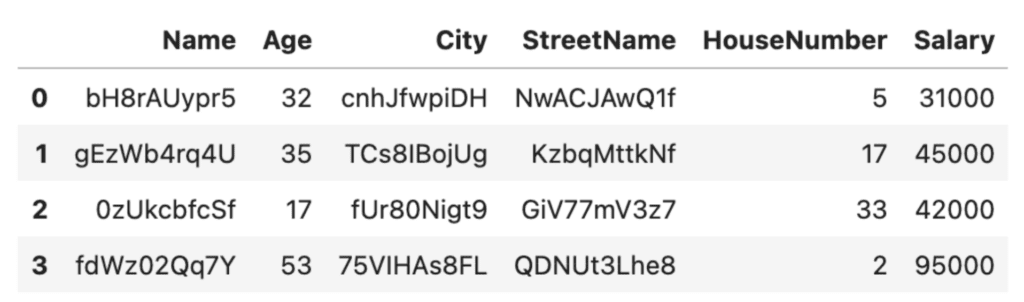
This is looking much better! The downside here is that it'll be easy to lose track of who's who this way. To help with this, it’s recommended practice to create a lookup table. We will give each row a unique identifier so that we can use that as a key to look up how the anonymized rows correspond to their original entries.
Let’s add a new row UniqueID to the original, non-scrambled DataFrame:
# add a new column with unique integer-only IDs
df['UniqueID'] = list(range(1001, 1005))
df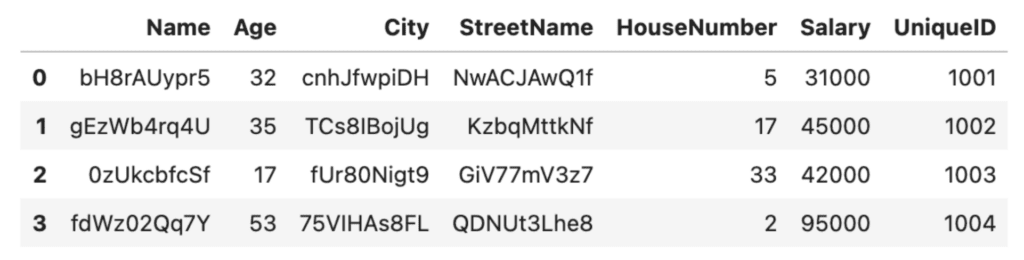
In this case, we chose to create a unique ID column of int data type so that our randomize_values function will not scramble it. For production purposes, you will probably want to build something a little more scalable and robust, for example using the Python uuid library.
We can now apply randomize_values again to get the anonymized rows with the unique IDs.
# apply function to dataframe
df_rand = randomize_values(df)
df_rand
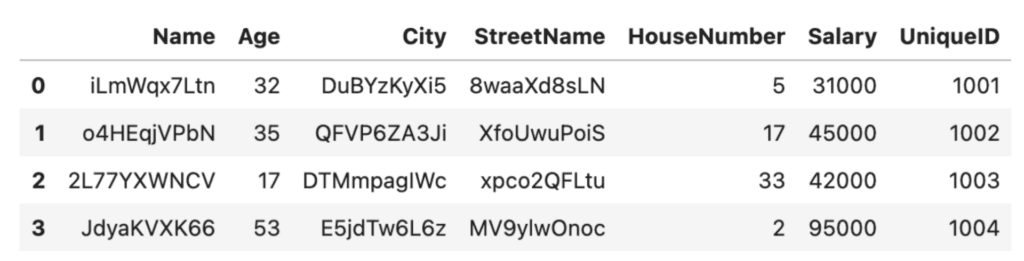
Randomization is a relatively low-effort method to perform data anonymization in Python. It’s important to note, however, that this low-effort benefit comes with some serious tradeoffs. First of all, the data utility has decreased significantly: it’s hard to imagine running any meaningful analysis on top of the scrambled City names, for example. Secondly, there are tradeoffs to consider in terms of robustness and security. For example, if a dataset contains a small number of unique values, it may be possible to use statistical analysis to identify individuals based on the random values.
Let’s now look at a second technique for performing data anonymization in Python: aggregation.
2. Aggregation
Aggregation involves combining data from multiple individuals to create a group-level view of the data. For example, instead of storing data for each individual separately, data might be aggregated into ranges or groups.
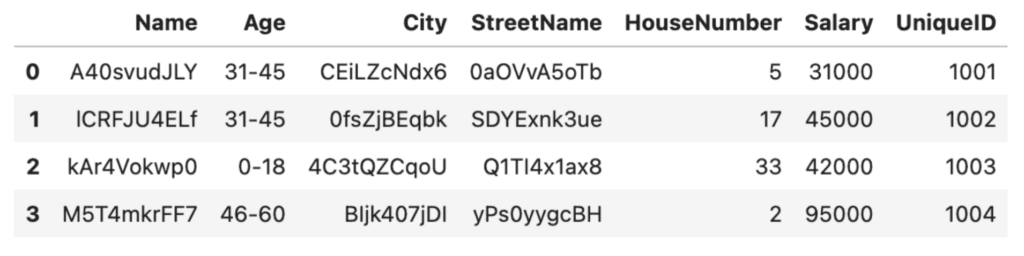
Let’s say we're happy with the randomization technique used above for hiding the names and addresses of the people in our dataset. However, we want to take our data anonymization one step further and also hide the numerical values. We can use Python to aggregate the numerical values, for example anonymizing the ages by grouping the individuals in our dataset into age brackets using the pandas .cut() method and specifying the bins and labels:
# Anonymize the ages by grouping them into age ranges
bins = [0, 18, 30, 45, 60, 100]
labels = ['0-18', '19-30', '31-45', '46-60', '60+']
df['Age'] = pd.cut(df['Age'], bins=bins, labels=labels)
df
We can do something similar with the salaries:
# Anonymize the salaries by grouping them into ranges
bins = [0, 30_000, 50_000, 80_000, 100_000, 200_000]
labels = ['0-30K', '31-50K', '51-80K', '81-100K', '100K+']
df['Salary'] = pd.cut(df['Salary'], bins=bins, labels=labels)
df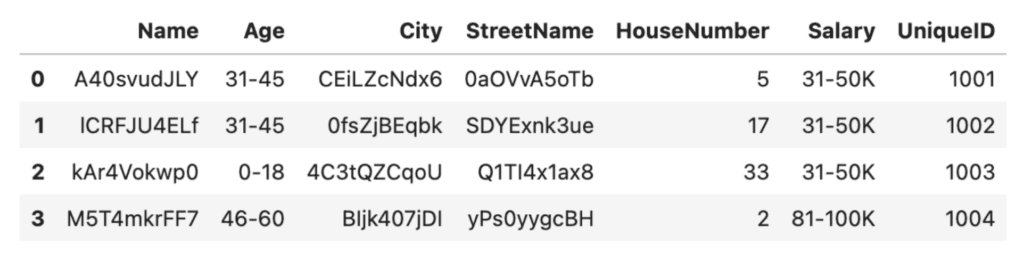
Excellent, it's now no longer possible to get any personally identifiable age or salary characteristics from our anonymized dataset. This was a relatively simple technique to achieve data anonymization. However, we've traded it for a significant amount of granularity. In the Salary column, we now have only 2 unique values (31-50K and 81-100K) instead of the original four. This reduces the types of analysis we can run on this dataset, decreasing its data utility.
There are many other ways to achieve anonymization by aggregation in Python, for example using groupby(). The important thing to remember is that while aggregation is technically an effective technique for data anonymization, it may often not be a feasible solution for your use case, especially if your analysis requires specific levels of data granularity.
3. Masking
The third technique for performing data anonymization in Python is masking. Masking involves replacing sensitive data with a similar but non-sensitive value. For example, a person's name might be replaced with their initials or a pseudonym.
In the randomization example above, we replaced people's names, cities, and street names with random characters. This is an effective anonymization technique (provided you have created a correct and securely-stored lookup table) but can make the dataset less intuitive to work with. If humans are going to be part of the data analysis process, you may want to use an anonymization technique where the anonymized contents still indicate something about the type of information they contain. Pseudonyms can be helpful for this.
Let's take a look at some Python code that uses masking to anonymize the names, cities, and street names in our dataset:
# take a look at the original dataset
df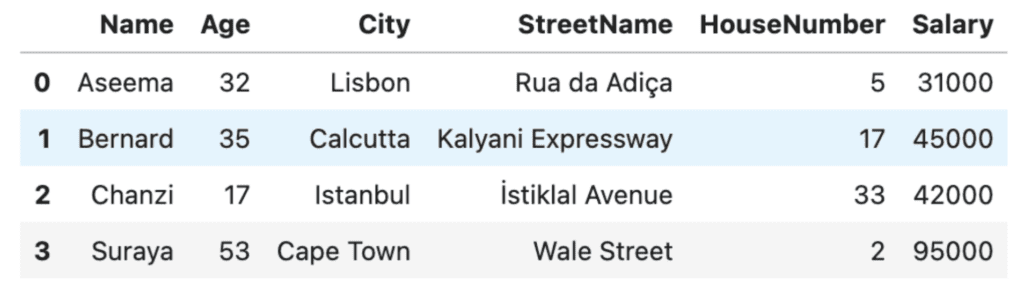
# mask the sensitive values by using pseudonyms for the names, cities and street names
masked = df.copy()
masked['Name'] = ['Stephanie', 'Marcus', 'Yasmin', 'Oprah']
masked['City'] = ['Amsterdam', 'Zagreb', 'Houston', 'London']
masked['StreetName'] = ['Central Road', 'Independence Avenue', 'Home Path', 'Long Walk']
masked
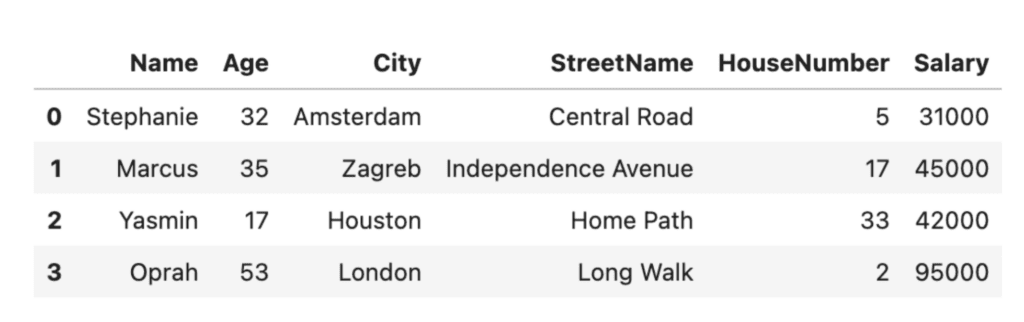
Masking can be an effective technique for data anonymization, but it may not always provide sufficient protection. If the masked value is still unique to an individual, it may be possible to use statistical analysis to identify them. It’s also important to note that pseudonymization alone is not GDPR-compliant.
Masking can also be difficult to perform programmatically. In the code above, we manually entered the alternative values. This is feasible for a small toy dataset with 4 rows, but imagine having to come up with and type out pseudonyms for a dataset containing millions of rows (!) Unless you can find a programmatic way to mask the data, masking may mean trading in efficiency for human legibility.
There are open-source Python libraries available that help you to perform this type of masking programmatically. One example is anonymizedf, which builds on pandas and faker to easily substitute original columns with masked substitutes. We’ll walk through a quick example below:
from anonymizedf.anonymizedf import anonymize
# prepare data for anonymization
an = anonymize(df)
# add masked columns
fake_df = (
an
.fake_names("Name", chaining=True)
.fake_whole_numbers("Salary", chaining=True)
.fake_whole_numbers("Age", chaining=True)
.fake_categories("City", chaining=True)
.fake_whole_numbers("HouseNumber", chaining=True)
.show_data_frame()
)
# subset only anonymized columns
fake_df = fake_df[['Fake_Name', 'Fake_Salary', 'Fake_Age', 'Fake_City', 'Fake_HouseNumber', 'StreetName']]
fake_df
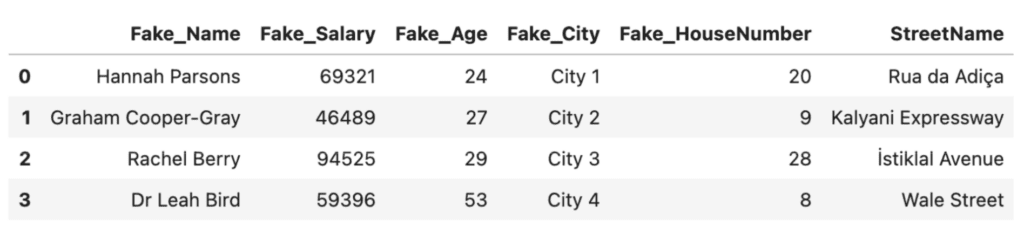
Anonymizedf and Faker are helpful open-source solutions that can help you perform data anonymization in Python. However, they also have their drawbacks. Being open-source, there are security risks associated with using these solutions on production data. The solutions are also limited in their flexibility: the an.fake_whole_numbers method, for example, simply outputs random integers between the lowest and highest value found in the original column. There is no way to control the distribution of the values in that column which is important for downstream machine-learning and other analysis projects, as we’ll see in the next section.
4. Perturbation
The fourth and final technique for performing data anonymization in Python is perturbation. Perturbation involves adding random noise to sensitive data to make it harder to recognize. For example, a person's salary might be increased or decreased by a small amount to protect their privacy. The amount of noise added can be adjusted to balance privacy with data utility. Data utility is generally a function of how well we can preserve the overall distribution in the dataset.
Perturbation is generally only used for numerical and categorical columns. Let's take a look at an example of performing perturbation on a numerical column in Python. We'll write a function called add_noise that will use the numpy library to add noise to the Salary column. The amount of noise can be controlled using the std (standard deviation) keyword argument.
import numpy as np
def add_noise(df, column, std = None):
if std == None:
std = df[column].std()
withNoise = df[column].add(np.random.normal(0, std, df.shape[0]))
copy = df.copy()
copy[column] = withNoise
return copy
perturbation = add_noise(df, 'Salary', std=100)
perturbation
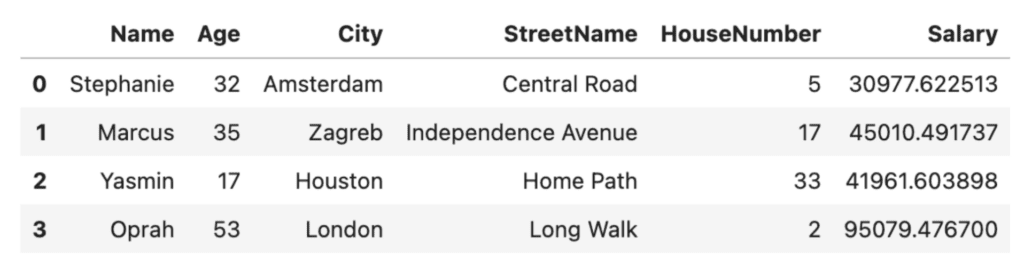
If we compare this to our original Salary values, we’ll see a minor deviation. This will likely preserve the original distribution of the dataset, but is it enough to guarantee the privacy of the individuals in our dataset? Probably not.
A toy dataset with 4 rows is not enough data to observe the effect of perturbation on the dataset’s distribution. Let’s work with a slightly larger fictional dataset that has 60 rows of data. This will allow us to clearly see the tradeoff of privacy (perturbation) and accuracy (data utility). For reproducibility of the code in this tutorial, we’ll create a larger DataFrame by simply copying the original df 15 times.
# create a large dataset
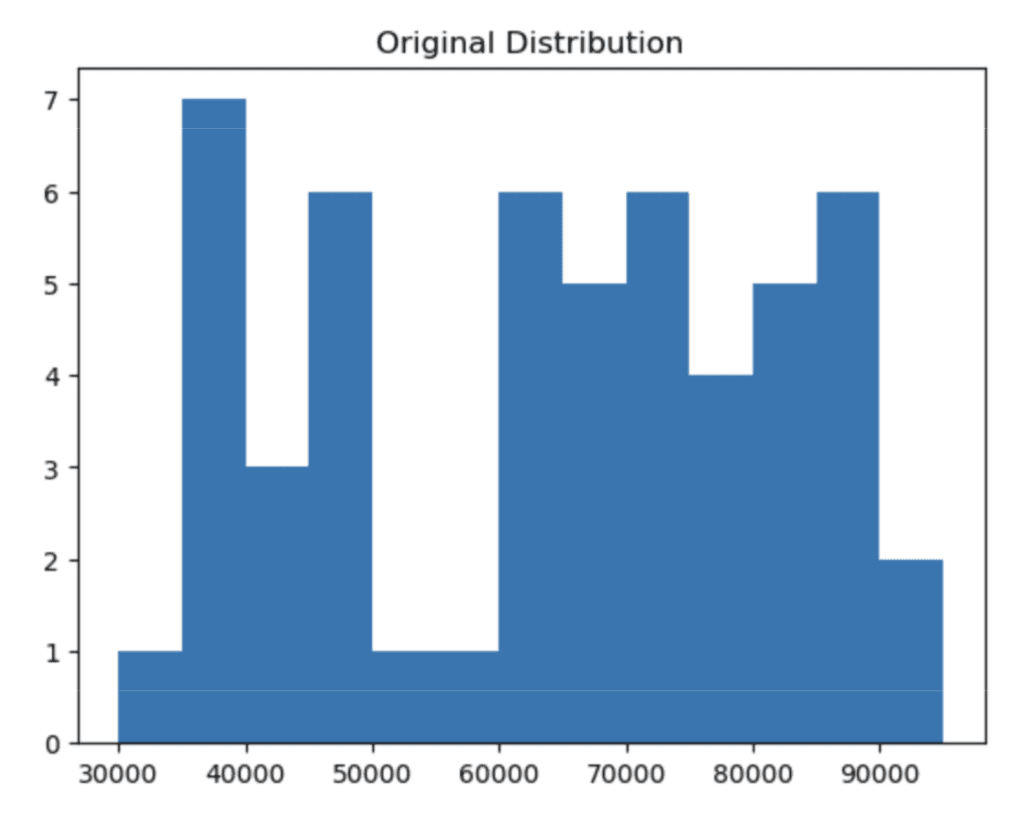
df_large = pd.concat([df, df, df, df, df, df, df, df, df, df, df, df, df, df, df])Let’s plot a histogram of the original Salary column:
# plot the distribution of the salary column using 5K bins
plt.hist(
'Salary',
data=df_large,
bins = np.arange(start=30_000, stop=100_000, step=5_000),
)
plt.title(“Original Distribution”);
Now apply our add_noise function with varying degrees of noise:
df_large_pert_10 = add_noise(df_large, 'Salary', std=10)
df_large_pert_100 = add_noise(df_large, 'Salary', std=100)
df_large_pert_2000 = add_noise(df_large, 'Salary', std=2000)And then visualize the distributions with noise:
fig, (ax1,ax2,ax3,ax4) = plt.subplots(nrows=1, ncols=4, sharey=True, figsize=(20,10))
ax1.hist(
'Salary',
data=df_large,
bins = np.arange(start=30_000, stop=100_000, step=5_000),
)
ax1.title.set_text('Original Distribution')
ax2.hist(
'Salary',
data=df_large_pert_10,
bins = np.arange(start=30_000, stop=100_000, step=5_000),
)
ax2.title.set_text('With Noise - std=10')
ax3.hist(
'Salary',
data=df_large_pert_100,
bins = np.arange(start=30_000, stop=100_000, step=5_000),
)
ax3.title.set_text('With Noise - std=100')
ax4.hist(
'Salary',
data=df_large_pert_2000,
bins = np.arange(start=30_000, stop=100_000, step=5_000),
)
ax4.title.set_text('With Noise - std=2000')
;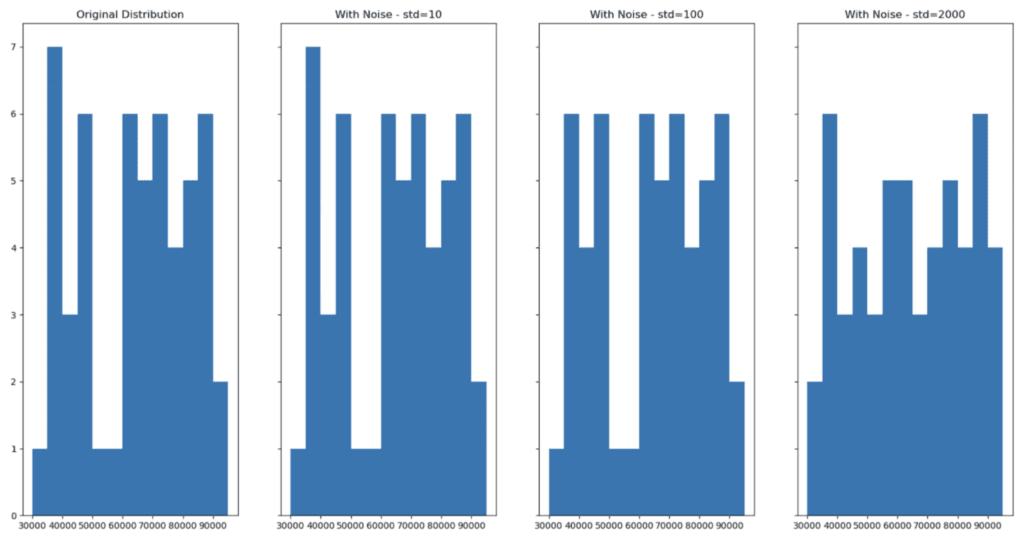
As we can see, adding noise (increasing privacy) can lead to a change in the distribution of the dataset (decreasing accuracy). Finding the perfect balance where privacy is ensured and accuracy is maintained is a difficult task to execute manually.
Automate data anonymization with MOSTLY AI
MOSTLY AI offers a fully-managed, no-code service for performing data anonymization. You can generate fully anonymized, synthetic datasets that maintain the distributions of your original dataset, striking that sweet spot between guaranteed privacy and maximum data utility. It offers built-in AI recognition of all data types and provides you with detailed reports to inspect both the utility (accuracy) and security (privacy) of your synthetic data. It takes into account any correlations between columns (both within and between related tables) and can automatically perform data augmentation techniques like imputation and rebalancing. Give it a try by signing up for a free account, we give you 100K rows of synthetic data for free, every day.
Data anonymization in Python: conclusion
Data anonymization is a critical step in protecting sensitive data and ensuring compliance with data privacy regulations. While Python provides libraries that can be leveraged to perform data anonymization. As we have seen in this blog, each of the four techniques presented also has serious drawbacks. They all require manual coding (and are thus sensitive to human error) and in many cases don’t actually provide the necessary level of privacy protection. That’s why performing data anonymization yourself, for example in Python, is generally considered to be a legacy technique that is not suitable for production environments.
Synthetic data anonymization is one of the core generative AI use cases for tabular data. Synthetic data provides solid guarantees about security and privacy protection. This type of data is completely made up and therefore contains virtually no risks of exposing any sensitive information from the original dataset. Powerful deep learning algorithms extract characteristic patterns, correlations and structures from the original dataset and use that to generate data that is entirely synthetic. As data privacy regulations continue to evolve, it is essential to stay up-to-date with the latest techniques and best practices for data anonymization. By doing so, you can ensure that your data is protected, and your business remains compliant. If you don’t want to worry about the risks of performing your data anonymization manually, consider giving MOSTLY AI a try and let us know how you get on!


