
What is a data catalog?
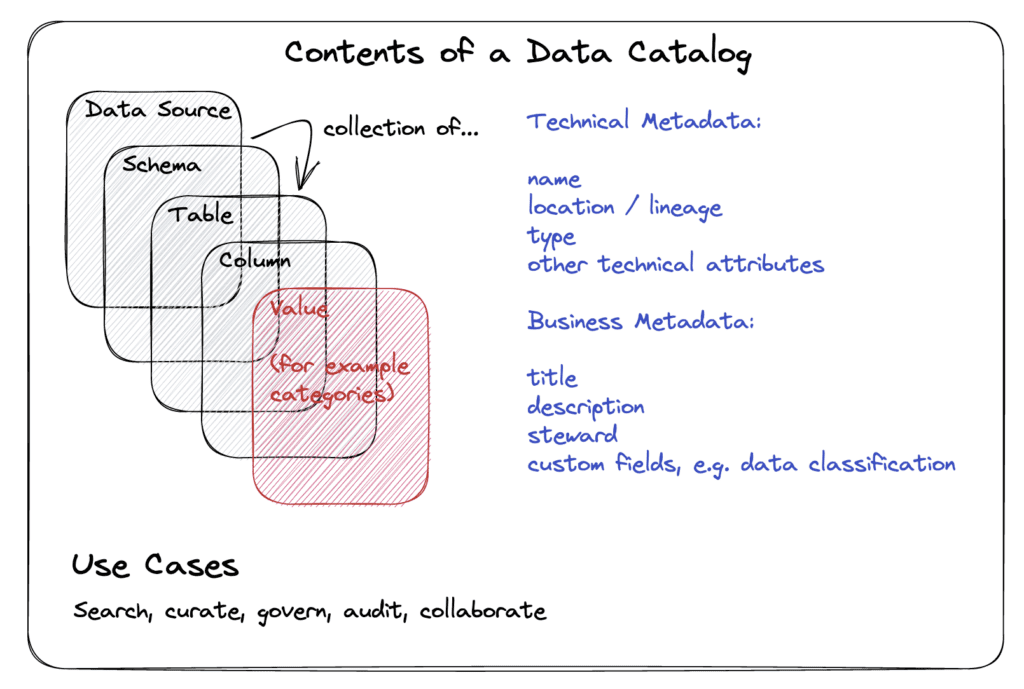
Data catalog tools enable centralized metadata management, providing a comprehensive inventory of all the data assets within an organization. A data catalog is a searchable, curated, and organized inventory of all the data sources, datasets, and data flows, along with information about their lineage, quality, and other attributes.
Data catalogs are the single source of truth for all data assets. Data catalogs make it easier for data users and stakeholders to discover, understand, and trust the data that is available to them. They provide detailed information about the structure, content, and context of data assets, including their data definitions, data types, and relationships to other data assets.
By providing a centralized view of data assets, data catalogs can help organizations to better manage and govern their data. Data catalog tools also facilitate compliance by providing visibility into the data lineage and usage, as well as access controls and permissions.
Why do we need data catalog tools?
Data catalog tools are software applications that allow you to create and manage the collection of your data assets described above. These data catalog tools typically store, and share metadata about data assets, including data definitions, data types, data lineage, and data quality.
Developing and maintaining these extensive data assets without a dedicated tool is near-impossible once tables number in the thousands, which is often the case in larger organizations.
Data catalog tools have been around as long as computing, but with the evolution of large scale data and distributed data architectures, they became mission critical. The data catalog tools of today often incorporate machine learning and artificial intelligence capabilities, enabling them sometimes to even automatically classify, tag, and analyze data assets.
What are the challenges of using data catalog tools?
While data catalogs can make it easier to manage data assets, there are also several challenges associated with using data catalog tools.
Data quality
Data catalogs rely on accurate and up-to-date metadata to be effective, and poor data quality can undermine the usefulness of the catalog. If the metadata is incomplete, inconsistent, or inaccurate, it can lead to confusion and misinterpretation of the data.
Data governance
Data catalogs can be an important tool for enforcing data governance policies and managing data assets, but this requires careful planning and implementation to ensure that the right policies and procedures are in place. You can’t govern what you can’t see. An effective data catalog tool allows governance people to track governance initiatives and co-operate with other stakeholders across organizations. Confining governance to IT departments is a mistake that should be avoided. However, sharing data assets downstream comes with its own privacy issues. AI-generated, realistic, yet privacy-protective synthetic data can serve as a drop-in placement for production data samples.
Integration
Data catalogs need to integrate with other data management tools, such as data warehouses, data lakes, and ETL tools, in order to provide a comprehensive view of an organization's data assets. This can be challenging, particularly when dealing with legacy systems or complex data architectures.
Maintenance
Data catalogs require ongoing maintenance and updates to ensure that the metadata is accurate and up-to-date. This can be time-consuming and resource-intensive, particularly for larger organizations or those with complex data architectures.
Data catalogs can provide significant benefits, however, they require careful planning, implementation, and ongoing curation to be effective. In our experience, it pays to have a dedicated team of data stewards who truly care about data democratization.
How to use data catalog tools
A data consumer uses a data catalog to find data. They may use full text search across the entire data catalog content, or navigate in a more structured manner and use filters to search for very specific tables, for example. In most cases, the user ends up on the catalog page of a table. A table is the most relevant entity for a data consumer. On the table page, they can inspect the title, description, and any other custom fields at the table level, and go into the details of each column, as well.
Chief Data Officers can effectively improve the analytical capabilities, scale governance and increase data literacy using a reliable data catalog tool. Enabling people across the organization to self-serve data on the fly should be the ultimate goal, while keeping data privacy and governance policies top of mind too. An essential tool in the journey towards full data democratization is to develop, curate and catalog synthetic data products. These readily available, statistically near-identical datasets can accelerate all data-intensive processes from third party POCs to the development of accurate machine learning models.
Why do data catalog tools need synthetic data?
Since data catalog tools typically display sample data on the table page, visible to every catalog user, there is a danger of accidentally revealing sensitive information, such as names, ages, salaries, health status and other privacy violations. The usual answer to the problem: just mask the sensitive columns. However, data masking renders the sample less useful by destroying readability and still failing to protect privacy in meaningful ways.
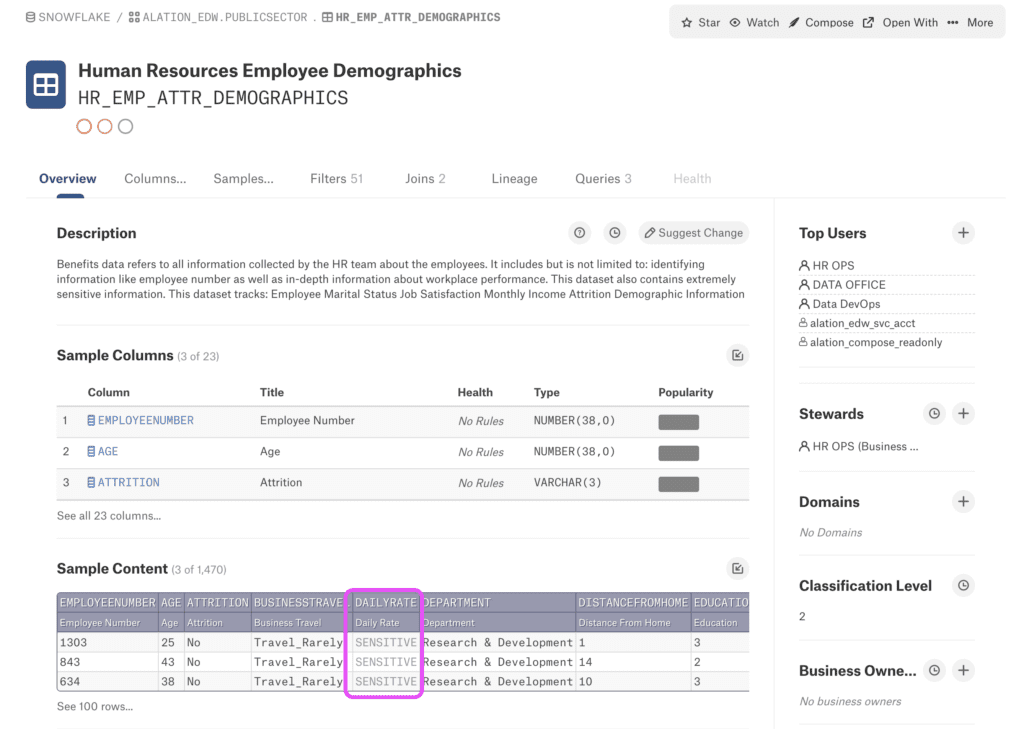
Synthetic data alternatives are needed to provide high readability and privacy protection to sample data displayed within data catalog tools. Furthermore, AI-powered synthetic data generation can also improve data quality by filling in gaps in the existing dataset or providing additional examples of rare or hard-to-find data points.
Some data catalog tools also include built-in SQL editors. If a user has a username and password or other credentials for the database in question, they can start querying the database from within the data catalog tool. They can reuse queries other users have published, and publish their own queries. Here, as well, it may be useful to direct the user (by default) to synthetic data rather than production data.
Synthetic data generation itself can be managed through data catalog tools. Datasets in need of full synthesization or data augmentation can be marked by data consumers directly in the data catalog tool, allowing seamless access to high quality, curated or even augmented synthetic datasets. In short, combining data catalogs with synthetic data can be an excellent way of accelerating time-to-value for any data project.
How to replace real data with synthetic data in a data catalog?
In this tutorial, we'll show you how to add synthetic data to Alation, a data catalog tool.


