
Table of Contents
- Data simulation: what is it?
- How do data simulations work with synthetic data?
- Why organizations can't afford to miss out on data simulation
- Decoding of model development & testing with synthetic data simulation
- The data simulation toolbox: exploring techniques & tools
- How to ensure simulated data mirrors the real world
- Data simulation risks & limitations
- Data simulation in finance
- Empowering data simulation with MOSTLY AI's synthetic data generator
- Conclusion
Data simulation: what is it?
The process of creating synthetic data that resembles (potential) real-world or data is referred to as data simulation. It is widely used in a variety of domains, including statistics, machine learning, and computer science, for a variety of reasons, including testing algorithms, assessing models, and performing experiments.
Data simulation is the process of producing a dataset with specified traits and qualities that imitate the patterns, distributions, and correlations seen in real data or how one would expect to see it in real data (e.g. in the future). This generated data may be used to conduct studies, evaluate the efficacy of statistical methods or machine learning algorithms, and investigate various situations without the limits or limitations associated with real data collecting.
How do data simulations work with synthetic data?
Synthetic data and data simulation are closely related concepts, as synthetic data is often generated through data simulation techniques. In the past few years the approach of ML generated synthetic data has becoming more and more popular. Artificial Intelligence and machine learning models are leveraged to create synthetic data of very high quality.
Why organizations can't afford to miss out on data simulation
Data simulation is an invaluable tool for businesses of all sizes. It has several advantages that help with decision-making, risk assessment, performance evaluation, and model creation.
One of the key benefits of data simulation is its capacity to assist in making informed decisions. Organizations can explore numerous alternatives and analyze potential results by simulating different situations that closely reflect real-world settings. This enables individuals to make data-driven decisions, reducing uncertainty and increasing the possibility of obtaining desired outcomes.
Risk assessment and management are also greatly enhanced through data simulation. Organizations may simulate various risk scenarios, assess their likelihood and impact, and design risk-mitigation strategies. They may implement proper risk management strategies and defend themselves against possible threats by proactively identifying vulnerabilities and analyzing the potential repercussions of various risk variables.
When it comes to model development and testing, synthetic data generated through simulation is highly valuable. Organizations can train and test statistical or machine learning models in controlled environments by developing synthetic datasets that closely imitate the properties of real data. This allows them to uncover flaws, enhance model accuracy, and reduce error risk before deploying the models in real-world settings.
Decoding of model development & testing with synthetic data simulation
- Data for AI/ML Training: Organizations can use data simulation to create synthetic datasets with known properties and trends. Machine learning models may be trained using these datasets. Organizations may develop different training datasets that span a wide range of scenarios by modelling data that replicates the distribution and relationships inherent in real-world data. This improves the model's capacity to generalize and perform well on previously unknown data.
- Model Evaluation/Validation: Before deploying models in real-world circumstances, simulated data may be utilized to test their performance. Organizations may analyze the model's accuracy, precision, recall, and other performance measures by comparing the model's predictions on simulated data to known ground truth. This review aids in detecting possible faults or weaknesses in the model and allows for development.
- Error and edge case testing: Organizations can use simulated data to test models against specific error situations or edge cases that are difficult to encounter in real-world data. They may examine how effectively the model handles purposeful mistakes, outliers, or severe situations by simulating data with such scenarios. This testing aids in finding any flaws or vulnerabilities in the model as well as improving its performance.
The data simulation toolbox: exploring techniques & tools
Data simulation comprises a wide range of methodologies and technologies that businesses may use to produce simulated data. These techniques and tools cater to different data characteristics and requirements, providing flexibility and versatility in data simulation. Let's take a closer look at some regularly used strategies and tools!
Random sampling is a key tool for data simulation. This method entails picking data points at random from an existing dataset or creating new data points based on random distributions. When the data has a known distribution or a representative sample is required, random sampling is valuable.
Another extensively used approach in data simulation is Monte Carlo simulation. It makes use of random sampling to describe and simulate complex systems that include inherent uncertainty. Monte Carlo simulation models a variety of possible outcomes by producing many random samples based on probability distributions. This approach is used in a variety of industries, including finance, physics, and engineering.
For data simulation, statistical modeling techniques such as regression analysis, time series analysis, and Bayesian modeling can be employed. Fitting statistical models to existing data and then utilizing these models to produce simulated data that closely mimics the original dataset are examples of these approaches.
To facilitate data simulation, various software packages and tools are available. AnyLogic is a sophisticated simulation program that allows for the modeling of agent-based, discrete events, and system dynamics. Simul8 is a well-known program for discrete event simulation and process modeling. Arena is a popular modeling and simulation tool for complex systems, processes, and supply chains. R and Python programming languages, along with packages like NumPy and SciPy, provide substantial capabilities for data simulation and modeling.
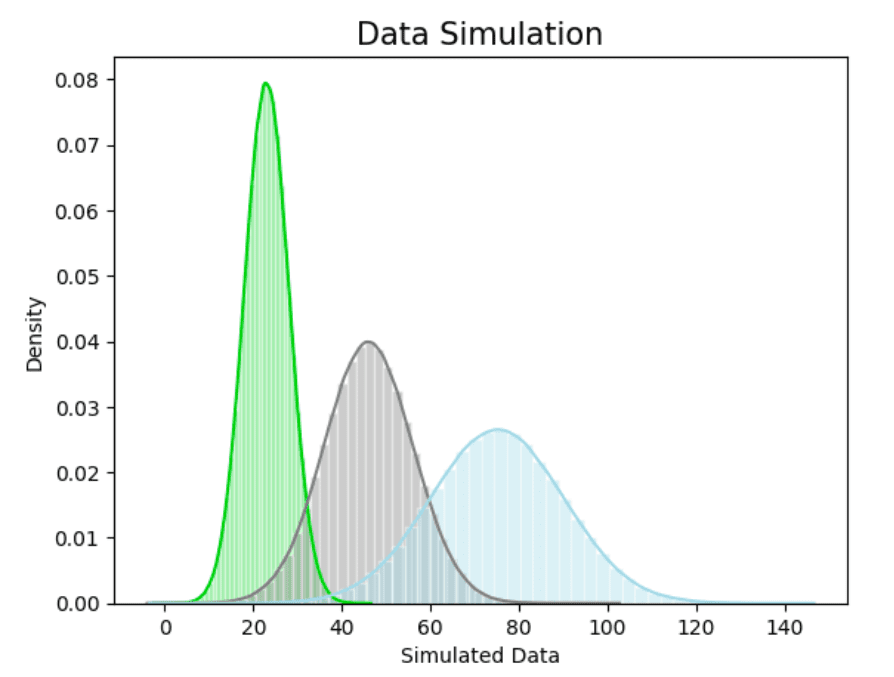
How to ensure simulated data mirrors the real world
For enterprises seeking reliable insights and informed decision-making, ensuring the accuracy of simulated data in contrast to real-world data is critical. Several factors and practices can aid in achieving this precision, allowing for more relevant analysis.
Obtaining a thorough grasp of the data generation process is a critical first step towards realistic data modeling. Collaboration with subject matter experts and domain specialists gives important insights into essential aspects, connections, and distributions that must be included in the simulation. Organizations may build the framework for correct representation by understanding the complexities of the data generation process.
Validation and calibration play a vital role in ensuring the fidelity of simulated data. Comparing statistical properties, such as means, variances, and distributions, between the real and simulated datasets allows for an assessment of accuracy. Calibration involves adjusting simulation parameters and models to achieve a closer match between the simulated and real data, enhancing the quality of the simulation.
A feedback loop involving stakeholders and subject experts is essential. Gathering input and thoughts from folks who are familiar with the real data on a regular basis improves the simulation's accuracy. By incorporating their experience into the simulation process, tweaks and enhancements may be made, better matching the simulated data with the real-world environment. Validation against real data on a regular basis maintains the simulation's continuous fidelity.
Data simulation risks & limitations
While simulated data can closely resemble real-world data and offer numerous benefits, it is essential to acknowledge the inherent limitations and assumptions involved in the simulation process. Organizations should recognize the uncertainties and limitations associated with simulated data, using it as a complementary tool alongside real data for analysis and decision-making.
The assumptions and simplifications necessary to mimic real-world settings are one of the fundamental limits of data simulation. Simulated data may not fully reflect the complexities and nuances of the actual data generation process, resulting in possible disparities between simulated and real data. Organizations should be cautious of the assumptions they make as well as the amount of authenticity attained in the simulation.
The accuracy of simulated data is strongly dependent on the quality of the underlying simulation models. Models that are inaccurate or inadequate may fail to convey the complexities and interdependencies seen in real data, resulting in erroneous simulated data. It is vital to ensure the validity and accuracy of simulation models in order to provide relevant insights and dependable forecasts.
The quality and representativeness of the training data used to develop the simulation models are intrinsically dependent on simulated data. If the training data is biased or does not represent the target population successfully, the simulated data may inherit those biases. To reduce the possibility of biased simulations, organizations must carefully curate and choose representative training data.
Another danger in data simulation is overfitting, which occurs when models become highly fitted to the training data, resulting in poor generalization to unknown data. Organizations should take caution and not depend too much on simulated data that has not been thoroughly validated against real-world data. Real-world data should continue to be the gold standard for evaluating the performance and dependability of simulation models.
Data simulation in finance
Data simulation is used in various use cases by banks and financial institutions. Here are the most important examples:
- Fraud Detection and Prevention: Simulated data is useful for training and testing fraud detection algorithms. Organizations can develop simulated environments to evaluate the performance of fraud detection systems by producing synthetic data that closely mimics real-world transactions. Simulations enable the discovery and fine-tuning of detection thresholds, hence improving fraud protection measures and lowering false positives.
- Custom Behavior Analysis: Simulated data may be used to better understand consumer behavior and forecast their reactions to various products and services. Organizations may test and enhance marketing tactics, examine consumer segmentation, and customize offers by creating synthetic customer profiles and modeling their interactions with financial products. Simulations improve customer experience management and enable proactive consumer involvement.
- Portfolio optimization: Simulated data helps in portfolio optimization by simulating asset price movements and correlations. Organizations can use simulation to evaluate risk-return profiles and improve portfolio allocations. This allows for the development of ideal asset combinations based on historical data and anticipated future situations, hence boosting investment decision-making and performance.
- Stress Testing and Scenario Analysis: Stress tests and scenario studies are frequently used by financial institutions to examine the resilience of their balance sheets and the effect of severe economic conditions. Simulated data allows for the production of realistic stress scenarios that include elements such as interest rate increases, loan defaults, and market shocks. Organizations may examine probable outcomes, identify weaknesses, and enhance capital allocation and risk management methods by running simulations.
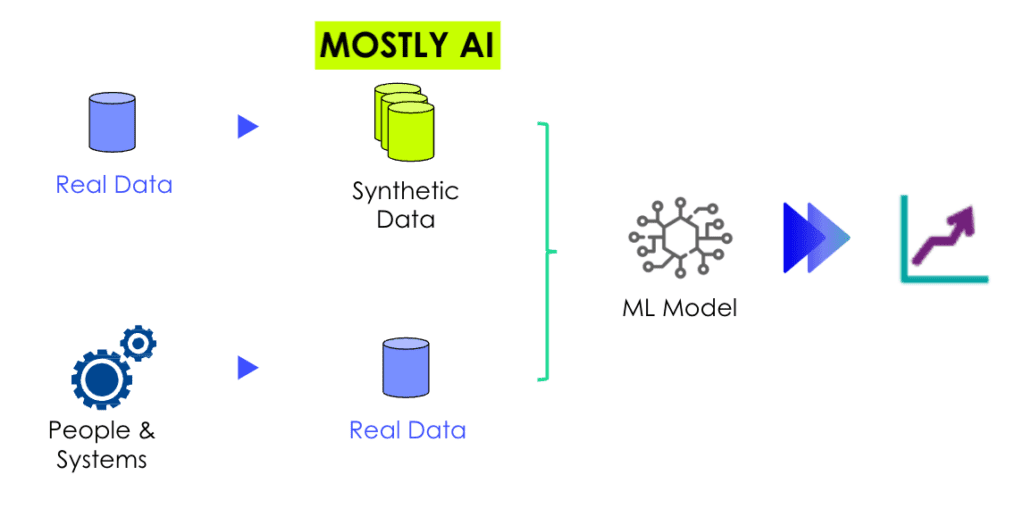
Empowering data simulation with MOSTLY AI's synthetic data generator
Simulated data for machine learning
Training machine learning models on synthetic data rather than actual data can potentially increase their performance. This is achievable because synthetic data assists these models in learning and understanding patterns. In the realm of data simulation, there are two essential ways in which it can significantly enhance the representation of data: by supplying a greater number of samples than what may be available in the original dataset and, more notably, by providing additional examples of minority classes that would otherwise be under-represented. These two aspects of data simulation play a crucial role in addressing the challenges associated with imbalanced datasets and expanding the diversity of data for more robust analysis.
Firstly, the MOSTLY AI synthetic data generator allows organizations to generate a larger volume of synthetic data points beyond the existing dataset. This serves as a valuable advantage, particularly in situations where the original data is limited in size or scope. By artificially expanding the dataset through simulation, organizations gain access to a richer and more comprehensive pool of samples, enabling more accurate and reliable analysis. The additional samples offer increased coverage of the data space, capturing a wider range of patterns, trends, and potential outcomes.
Secondly, and perhaps more significantly, data simulation offers the opportunity to address the issue of under-representation of minority classes. In many real-world datasets, certain classes or categories may be significantly under-represented, leading to imbalanced distributions. This can pose challenges in accurately modeling and analyzing the data, as the minority classes may not receive adequate attention or consideration. MOSTLY AI provides a solution by generating synthetic examples specifically targeted towards these under-represented classes. By creating additional instances of the minority classes, the simulated data helps to balance the distribution and ensure a more equitable representation of all classes. This is particularly important in various domains, such as fraud detection, where the minority class (e.g., fraudulent cases) is often of particular interest.
As discussed above, it is important to note that data simulation is not without its own challenges. The process of generating synthetic data requires careful consideration and validation to ensure that the simulated samples accurately capture the characteristics and patterns of the real-world data. The quality of the simulation techniques and the fidelity of the generated data are critical factors that need to be addressed to maintain the integrity of the simulation process.
Rebalancing as a data simulation tool
Recently, MOSTLY AI introduced data augmentation features. Rebalancing is one of them and it can be used as a data simulation tool. Many businesses, particularly financial institutions, suffer because the data they have accumulated over time is significantly skewed and biased towards a specific behavior. There are several examples of skewed/biased data sets investigating gender, age, ethnicity, or even occupation. As a result, decision-makers are sometimes unable to make the optimal decision that will help their firm flourish.
MOSTLY AI's rebalancing capability may be used as a simulation tool. The goal is to offer decision-makers an effective tool for better understanding and exploitation of newly acquired information that may influence their contradictory decision to make. Rebalancing may be a key and useful technique for testing multiple hypotheses and 'what-if' situations that may impact the entire organization's strategy change.
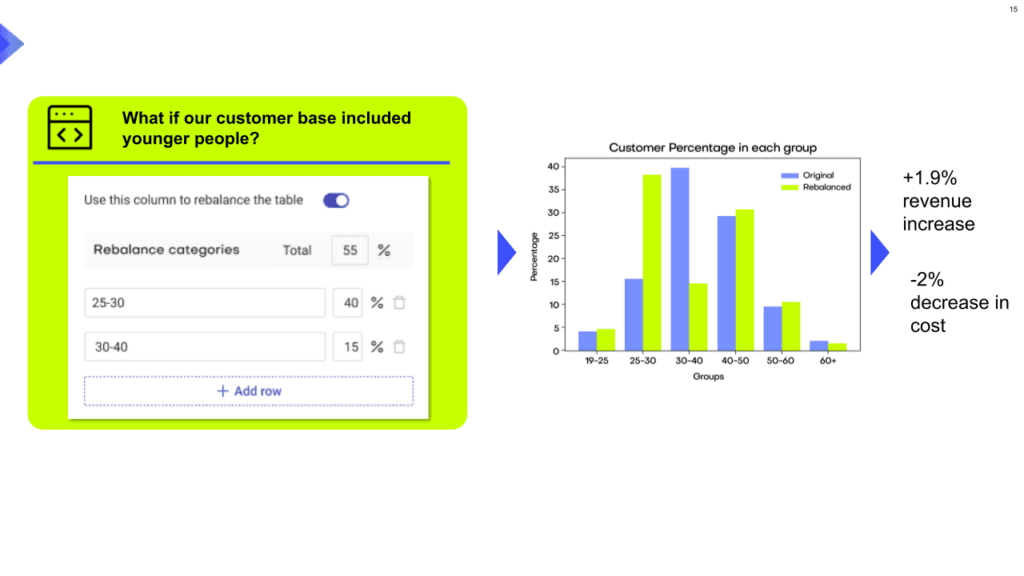
Take the insurance business as an example. Total yearly premiums and total claims amount are two of the most important KPIs for all insurers worldwide. One might use rebalancing as a simulation tool to answer questions like:
- What impact on our revenues would altering our client business mix have?
- What shifts in our client base would reduce our claim costs?
Using MOSTLY AI's rebalancing feature, we changed the insurance customer mix distribution toward younger audiences. MOSTLY AI's synthetic data generator then created the rest of the dataset's characteristics based on the new information. The two previously mentioned KPIs have been adjusted, and a decision-maker may notice that income has increased while costs have fallen.
Stakeholders can utilize the above comprehensive research to guide their judgments and perhaps adjust their organizational strategy.
Conclusion
In the dynamic and data-intensive landscape, data simulation has emerged as a powerful tool for organizations seeking to enhance decision-making, manage risks, and optimize operations. We've seen how data simulation helps organizations get useful insights and create informed strategies through a variety of effective use cases.
Data simulation has become an indispensable tool for organizations, providing them with the means to make evidence-based decisions, optimize strategies, and navigate complex landscapes. As organizations embrace the power of simulated data, they can unlock new insights, enhance their competitive advantage, and deliver superior services in an ever-changing world.


