TL;DR: To date, synthetic data is not a clearly defined term. Part of the reason why we lack a widely-used synthetic data definition might be that a broad variety of synthetic data categories exists – and that different types of synthetic data are used for different purposes. Yet, if it’s privacy protection what you are after, there is only one synthetic data category that is worth the hype. Only one that offers bulletproof privacy protection and near-perfect data utility: privacy-preserving, AI-generated synthetic data. This article aims to bring forward a definition for privacy-preserving, AI-generated synthetic data and, hopefully, clears up some of the confusions about what AI-generated synthetic data actually is.
Read on for a deeper dive into all the elements that make up the following definition of truly privacy-preserving, AI-generated synthetic data. You might also find this article worthwhile to learn how you can successfully sift through the constantly growing sea of synthetic data tools and solutions out there, to find those that truly offer privacy protection. But knowing that this post is rather extensive and that most of you probably wouldn’t get to the end, let me start with the definition of synthetic data right here on top ⬇️
The definition of privacy-preserving, AI-generated synthetic data
Synthetic data as a rapidly evolving technology is not yet a clearly defined term. While it was first mentioned decades ago, older types of synthetic data do not bear any resemblance to the powerful AI-generated synthetic data we have today. Although there are various application areas where AI-generated synthetic data is of value, only one category is relevant for privacy protection: privacy-preserving, AI-generated synthetic data.
Privacy-preserving, AI-generated synthetic data is defined as an anonymization technology that preserves data utility. It is artificial data created by a machine learning model trained on real-world data that accurately and granularly retains the statistical properties of the real data it was trained upon. Yet, it is generated with a holistic set of privacy mechanisms that ensure absolute, irreversible anonymization.
Privacy-preserving, AI-generated synthetic data is synthesized at the user-level, not only at the event-level. It is fully synthetic as opposed to partially synthetic. It does not contain any 1:1 relationships between real and synthetic data subjects – and it is impossible to re-identify.
To better understand the different elements of this AI-generated synthetic data definition, feel free to jump to the specific sections in the blog post:
- What’s wrong with most definitions of synthetic data?
- Legacy vs. AI-generated synthetic data
- Fake “synthetic data” vs. real synthetic data
- Different categories of AI-generated synthetic data
- Why privacy mechanisms are essential for privacy-preserving synthetic data
- Fully vs. partly AI-generated synthetic data
- User-level vs. event-level synthetic data
Disclaimer: This post will focus on AI-generated structured synthetic data – think financial transactions, mobility data, or healthcare records – for the purpose of privacy protection. AI-generated unstructured synthetic data (like videos, images, voice, or long sequences of free text) is not included.
What’s wrong with most definitions of synthetic data? (Or: Why am I writing this blog post?)
Thinking back, it’s quite funny. For years I’ve been telling people why and how AI-generated synthetic data is replacing legacy anonymization techniques. Meanwhile, synthetic data’s potential is very well understood – and so are the risks of relying on outdated anonymization techniques.
Over time, this led to significantly more media coverage of synthetic data – which is exciting to see. Even though I sometimes stumble upon bad press for this emerging technology. Don’t get me wrong. I’m not against critical thinkers sharing their take on this or any other new technology. But in 90% of those articles I can’t help but notice that the authors mixed up different synthetic data types: AI-generated synthetic data and legacy approaches of synthetic data generation (or even worse: legacy anonymization techniques). And understandably so. Even though synthetic data is widely talked about, it is still not a clearly defined term. But what is the result of this lack of terminology? Confusion about what synthetic data actually is paired with various critical points that simply don’t apply to state-of-the-art synthetic data.
Another common theme of synthetic data articles is that different categories of AI-generated synthetic data get mixed up to then put the technology's privacy-preservation capabilities into question – which doesn’t make sense when a category of AI-generated synthetic data is evaluated that has a purpose different from protecting privacy. So, it might be time for a proper definition of privacy-preserving, AI-generated synthetic data with a focus on how you can differentiate it not only from legacy anonymization but also legacy data synthesis techniques. Let me give it a shot (to hopefully help to clear up some of this confusion)!
What is the difference between legacy and AI-generated synthetic data?
Legacy synthetic data
Although the hype for synthetic data and its adoption in Fortune 500 companies started only in recent years, the term itself is not a new one. “Synthetic data” has been around for more than three decades. Back then, it referred to overly simplistic mock data (or dummy data). This type of synthetic data was rule-based – meaning a human or a machine followed simple rules to create artificial data points.
To give you a feel for that, you can try rule-based synthetic data generation yourself. Just write down a table with 10 individuals - 50% female and 50% male - and please come up with suitable given names, surnames, home addresses (let’s say in NYC), and birthdates. If you want to go wild, you could even add a shiny credit card transaction for each of your artificial customers. To do that, just write down the date/time, merchant, and amount of money that was spent.
Congrats, you’ve just generated rule-based synthetic data! (Assuming that you didn’t get too creative and came up with birthdates like 17th of April 1622 or ZIP codes that ignore the “5-digits”-rule of NYC ZIP codes.) Do that times 1,000 or 10,000 and you’ve built yourself a rule-based synthetic dataset to perform some basic software tests.
The problem with this type of synthetic data is that it’s of limited use. It follows some rules that are already known to you or the machine creating it (like the distribution of 50% males and females, typical female first names and how ZIP codes in NYC are structured). While this might be sufficient for very basic tests, there won’t be any previously unknown insights hidden in rule-based synthetic data. So what does this mean for AI or analytics? That rule-based synthetic data is completely useless!
| Privacy | Utility | |
| Legacy synthetic data (rule-based) | Private, although accidental matches are still possible | Limited, frequently used for testing new features in software development |
| AI-generated synthetic data | Private when supported by additional privacy mechanisms | Almost 100%, retaining correlations and, distributions on a granular level |
AI-generated synthetic data
But how is AI-generated synthetic data different from legacy rule-based synthetic data? It is trained on high-dimensional, complex real-world data and - thanks to powerful deep learning algorithms - capable of automatically extracting its patterns, correlations, time dependencies and structures. Once the synthetic data generator is trained, it can be used to create one (or even multiple, if you would like) new synthetic data sets from scratch. These AI-generated synthetic datasets are fully anonymous and don’t include privacy-sensitive information anymore. But what they do include are all the same patterns, correlations, and structures of the original training data, which are then readily available for you to uncover valuable insights - without infringing on your real customers’ privacy.
To sum up, when AI entered the synthetic data game, it brought an unprecedented level of data utility. In contrast to rule-based synthetic data, this new breed of synthetic data is suitable for a broad variety of use cases – ranging from AI training and advanced analytics to complex software testing, digital product development, and external data sharing.
Watch out, fake “synthetic data” is jumping on the wagon
With the ever-growing hype around synthetic data, it comes as no surprise that some vendors decided to call synthetic data what – if you look a little closer – turns out to be nothing more than perturbation, obfuscation, or any of the other legacy anonymization techniques. Sure, now that synthetic data is frequently covered in the media, adopted by major players in finance as well as other industries, and picked up by analyst firms like Gartner – who are strongly advising their enterprise customers to incorporate this emerging technology into their AI and data strategies – it is tempting to do a little re-branding and try to get yourself a slice of the pie.
But watch out! Only putting a fancy “synthetic data” sign on top, doesn’t get you the benefits, data quality, and protection levels of having truly privacy-preserving, AI-powered synthetic data generation under the hood. Just adding some noise to a dataset or using another perturbation technique comes with the full range of privacy risks – which we’ve extensively covered in previous blog posts, so I’ll refrain from reiterating at this point. Instead, I’ll stick to urging you to look more closely when confronted with shiny “synthetic data” marketing materials.
AI-generation is just one piece of the synthetic data puzzle. Purpose is another.
As mentioned in the intro, even if we only look into AI-generated synthetic data technology, there are different categories of it. A good way to distinguish between them is the purposes they are used for. The two most common ones are privacy protection and artificially creating more data where there is a lack of it.
Synthetic data for privacy protection of real-world data
The former needs plenty of real-world data to learn from. Subsequently, it uses this knowledge to create highly realistic and statistically representative, yet fully anonymous synthetic data. Think of this privacy-preserving category of AI-generated synthetic data as an enabling technology. It is used to anonymize existing datasets without destroying the original dataset’s value and utility. This helps organizations to safely unlock and innovate on top of their data assets in compliance with even the strictest privacy regulations like GDPR.
Synthetic data when not enough real-world data exists
The other most prominent category of AI-generated synthetic data focuses on creating more data where there’s a lack of it. Think of autonomous vehicles. During development and training, businesses and researchers want to make sure that they are safe to use and that they ALWAYS stop when there is an obstacle approaching the car. It must not make a difference from which of the 360 possible angles a rabbit is running on the street. Whether there is blinding light, twilight, bright light, or nearly no light during nighttime. Even if there is rain, hail or storm shouldn’t make a difference in the car’s ability to spot the obstacle and slam on the brakes.

But how to get all that training data without spending hundreds of thousands of dollars on a video crew tasked with catching rabbits running on streets on their cameras? Here, the second category of AI-generated synthetic data can help to get high-quality training data at significantly lower costs. Oftentimes, it just gets a little seed training data (for example, a few different videos of rabbits running on the street) to get the synthetic data generation algorithm started. In our example, these seed video sequences plus the laws of physics (e.g. how shadows change depending on the source of light or time of day) help the algorithm to create a myriad of highly useful synthetic “rabbit running on the street” videos. In turn, these AI-generated videos are again used to train AI and help the self-driving car’s algorithm to become 100% rabbit-safe.
Without privacy mechanisms, synthetic data is NOT a privacy-enhancing technology
Plain AI-generated synthetic data might do a stellar job in preserving the utility part of the original data it was trained on, but it does not automatically help you with privacy protection. No matter whether you are building an AI-powered synthetic data generator yourself, use open source tools to generate your synthetic data, or rely on a trusted and tried vendor solution – it is essential that all the necessary privacy mechanisms and privacy checks are implemented in the synthetic data generation process. Without them, you risk leaking privacy-sensitive information in the newly created artificial data.
Which privacy mechanisms are essential, you might wonder? Some of them intuitively appear logical. For example, the prevention of overfitting. One must ensure that the AI model is not memorizing the real-world data it is trained on. Otherwise, you would pretty much get a copy of your privacy-sensitive source data.
The science of privacy-preserving synthetic data generation lies in extracting the generalizable patterns, structures, and insights hidden in a dataset, while leaving the personal secrets and privacy-sensitive parts behind. To pull that off, the prevention of overfitting is just one piece of the puzzle.
But bulletproof privacy protection goes beyond protecting the sensitive information of individuals. You also want to account for group privacy and prevent membership attacks. This means, a truly privacy-preserving synthetic dataset not only protects the privacy of extreme individual outliers but also the sensitive information of small groups (think, the 5 individuals in country X suffering from a super rare disease). Here, privacy mechanisms like rare category protection (RCP) help to exclude extremely rare occurrences within the source data already before the AI-powered synthetic data model is trained upon it.
Often forgotten is that not only the specific data points but also the metadata and data structure need to be protected to prevent privacy leakage. How entities relate to and interact with each other is highly unique and oftentimes specific to individuals. This is easiest understood with graph data. Imagine a table that includes a list of all the calls and messages you – and 20 million other customers of a fictitious telco company – received and made or sent over the last month.
While it is intuitively clear that the caller IDs of the sender and receiver or the date, time, and duration of a call are highly privacy-sensitive, it is oftentimes overlooked that also that which is not in plain sight – the metadata or the structure of how different entities relate to each other – is in urgent need of protection. Just recently, there was an excellent paper published in Nature that once again underlined what should be well understood: also metadata is data - and if it is about real-world individuals, then metadata is personal data that needs to be adequately protected.
The paper showed that only by looking at the patterns in the metadata it is easy to re-identify individuals. How frequently you call your respective contacts, at which time of the day, the duration of your calls, or the number of messages you exchange with your best friend Stacy are highly unique behavioral patterns that tend to stay constant over time. What the paper showed was, that even if an adversary can’t link you to the call that you made to President Biden on the 16th of May 2022 at 3:17 am to complain about the constant air traffic flying over your house and waking you up in the middle of the night, the simple fact that you try to reach the US president 3 times over the course of a month to lodge your complaint is a behavioral pattern of yours (although presumably one that is not leading to much success). Pair that with your weekly overseas calls to Auntie Ann living in London and a few other calling habits of yours, and you’ve successfully created yourself a digital behavioral fingerprint that makes it easy to single you out: From the supposedly anonymous call records of May 2022, as well as from those of January the same year and probably even August the year before.

What I’m getting at is that we have entered a time where direct linkage attacks are just one of your many privacy concerns. Yes, you still need to prevent that (supposedly) anonymous data can be linked with auxiliary information that directly matches parts of the (not so anonymous) dataset. But nowadays, adversaries can even re-identify your (not so) anonymous data by matching behavioral patterns or profiles of two datasets from different periods of time – and easily so if they throw AI-powered profiling attackers in the mix. To read more about this equally mind-blowing as well as scary new breed of privacy attacks (and how our synthetic data protects against them), I highly recommend you check out our blog post on AI-based re-identification attacks.
As you can see, privacy protection is complex and needs to be approached holistically. While this is by no means an exhaustive list of all the privacy mechanisms that should go into a truly privacy-preserving synthetic data generator (that’s something for a future blogpost ;-)), what I want you to remember is: you must implement a whole set of privacy mechanisms into an AI-powered synthetic data generator to successfully protect privacy – but if you do that, you will be able to achieve absolute, irreversible anonymization.
To truly protect privacy, make sure you’re getting fully and not partly AI-generated synthetic data
Admittedly, we are now entering the weeds of selecting a truly privacy-preserving synthetic data solution. But for the sake of completeness: if you want bulletproof privacy protection, make sure that you are getting fully and not partly AI-generated synthetic data. To not be mistaken, there are some highly interesting use cases for partly synthetic data and it can be an invaluable tool to augment real-world data. But it’s not the right approach if privacy protection is what you are after.
How to distinguish between partly and fully synthetic data?
The former pairs either...
a) real-world data, or
b) traditionally anonymized data (which, as you know, is simply not anonymous in the era of big data anymore .Thus it is basically real-world data 😉)
...with synthetic data.
So what you get out of this is a mix of partly real data and partly artificially created data – and as you could have guessed, that’s not privacy safe at all! Sure, the synthetic part won’t be your privacy problem. But if there are bits and pieces of real, highly sensitive data in there, then the whole thing becomes personal data and must be protected accordingly. Your takeaway here? Merely applying data synthesis (or differential privacy, for that matter) column-based as opposed to a dataset in its entirety is more wishful thinking than actual privacy protection.
To be inclusive, there is another category of partly synthetic data that might not be that easy to spot. Remember the metadata/data structure problem I pointed out earlier? If you want to synthesize not only one dataset but a whole bunch of tables within your database, it is not a good idea to set up your synthetic data generator in a way that it just mindlessly fills out one table after the other with fresh batches of representative synthetic data.
At first glance, this might look innocent and perfectly privacy safe. And why shouldn’t it be? After all, each table on its own contains fully synthetic data and not a single real-world data point. But there is a catch! If you’re not synthesizing multiple tables in a way that all the fine-grained relations between the different tables are learned, then your synthetic data generator will fail to detect and remove potentially privacy-sensitive patterns in that relational metadata – and thereby introduce a privacy risk via the backdoor.
The cardinal rule of data synthesis: anonymize at the user-level and not just at the event-level
A similar problem can be encountered when data that should be synthesized (or anonymized) is not set up in a way that user-level anonymization can be achieved. What do I mean by that? Whenever we want to anonymize data, it is real-world individuals we want to protect. Thus, it is not sufficient to apply any anonymization technology only on the event- or trip-level.
Just recently this was nicely illustrated in the Nature paper “On the difficulty of achieving Differential Privacy in practice: user-level guarantees in aggregate location data”. The researchers analyzed a differentially private location dataset with the trips of 300 million Google Maps users over the course of one year.
As most of you know, differential privacy offers mathematical privacy guarantees that are quantified with the so-called epsilon value. The lower the value, the stronger the protection (below 1 is oftentimes recommended in academia). The higher the epsilon parameter, the closer you get to privacy-washing and guarantees of complete meaninglessness – which is why Apple and other big brands already earned harsh criticism for their differential privacy practices in the past. But back to our study – what was the problem here? The epsilon value that was reported was 0.66. “Awesome, completely anonymous!” one might think…but the researchers uncovered that the differential privacy guarantees were calculated for the trip-level only, based on the assumption that any one of the 300 million users did not contribute more than one of her/his trips to the dataset.
Unfortunately, this wasn’t the case. Individual users contributed more than one trip to the dataset. To get a more accurate picture of how well the actual users (and not only their individual trips) were protected, the researchers then went on and conservatively estimated the real, user-level epsilon value of this dataset to be closer to 46. Imagine that, 46! For just one week worth of trip data. Remember, the full data set contained the trips of a whole year. Thus, the actual epsilon value for the entire dataset could be 52-times as high and as large as 2392 – which due to the exponential nature of this parameter is more a guarantee for non-privacy than anything else.
I think, there are few examples out there that more powerfully illustrate how important it is to apply data synthesis, differential privacy, or any other anonymization technology to the user-level (e.g. ALL your trips or all your “events” like financial transaction” contained in the dataset) and not merely to the individual trips or events.
What does this mean for data synthesis in practice? Set up your tables in a way that ALL events belonging to a single data subject are connected to said user via a unique ID. Thereby you ensure that privacy protection is applied on the right level and that you achieve what all the emerging privacy regulations want you to achieve: that the privacy of individuals, of real-world humans is kept safe and secure.
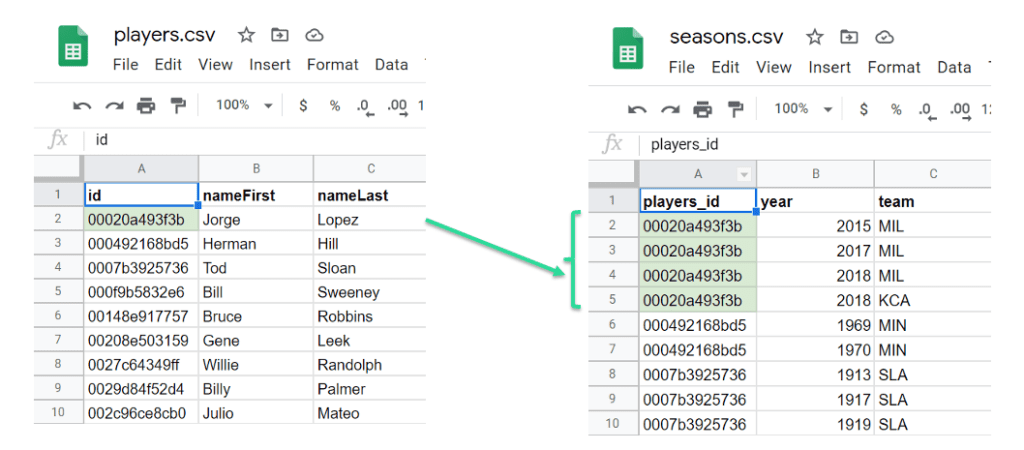
In the example dataset above you see baseball players on the left and the seasons they played on the right. The first four seasons all belong to a single player and are connected to this person with a unique ID. This ID is referred to as the primary and foreign keys, which link tables together. Generating synthetic data with this set up guarantees the privacy of individuals when using MOSTLY AI's synthetic data generator.
Closing thoughts on this AI-generated synthetic data definition
Now that you’ve come this far, you are equipped with the knowledge to sift through the myriad of synthetic data tools and solutions and capable of identifying the ones that truly offer impeccable privacy protection. Even more importantly, I hope you gained a deeper understanding why I consider all these different elements important to be included in any definition for privacy-preserving, AI-generated synthetic data.
Rest assured, that we at MOSTLY AI take privacy very seriously – and that all the privacy risks highlighted above (and even those I didn’t have space for in this post) are covered with our synthetic data generation software. If you use MOSTLY AI’s synthetic data generator, you enjoy the benefits of truly privacy-preserving, AI-generated synthetic data: unparalleled data utility paired with bulletproof anonymization.
As for the definition, I’m curious to hear your comments and thoughts. Personally, I can’t wait to continue working on and refining this AI-generated synthetic data definition as part of the IEEE Synthetic Data IC Expert Group we recently established. If you, too, want to get involved and collaborate with an international group of synthetic data vendors and experts from corporates, academia, and the regulatory side – join us!