
Creating realistic, relational healthcare datasets doesn’t need to be complicated. In this blog, I walk through how to use the Assistant from MOSTLY AI to simulate a multi-table Healthcare and Life Sciences (HLS) use case from scratch. The entire process flows through natural language, making it intuitive even for non-technical users.
This workflow includes two key steps:
- Generating mock data across multiple tables with realistic relationships
- Scaling that data with a synthetic generator and writing it directly to a production-ready database
Step 1: Generating a Multi-Table HLS Dataset with Natural Language
Using the Assistant, I start by asking for mock data across four common HLS tables: patients, visits, diagnoses, and medications. I specify that I want a sample of 150 patients, and the Assistant takes care of the rest. It defines the schema, sets the primary and foreign key relationships, and generates mock data with full referential integrity.

Each patient links to multiple visits, and each visit includes one or more diagnoses and medications. The mock dataset is ready in just a few minutes and reflects realistic HLS patterns.
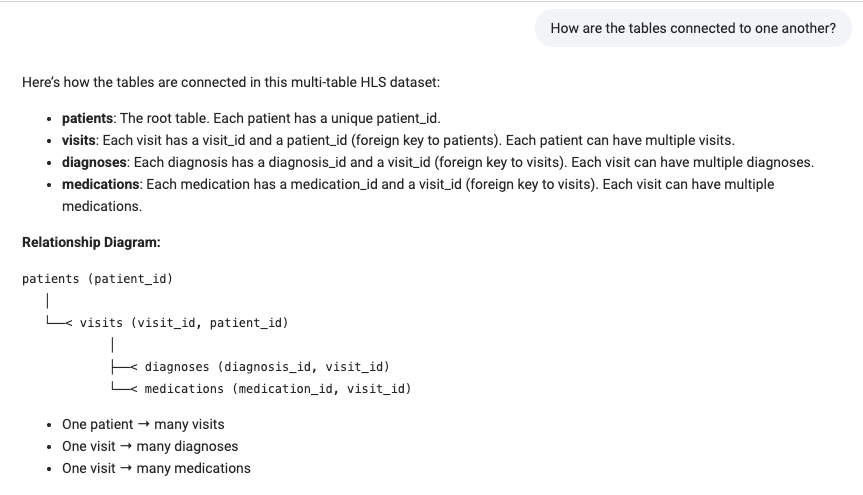
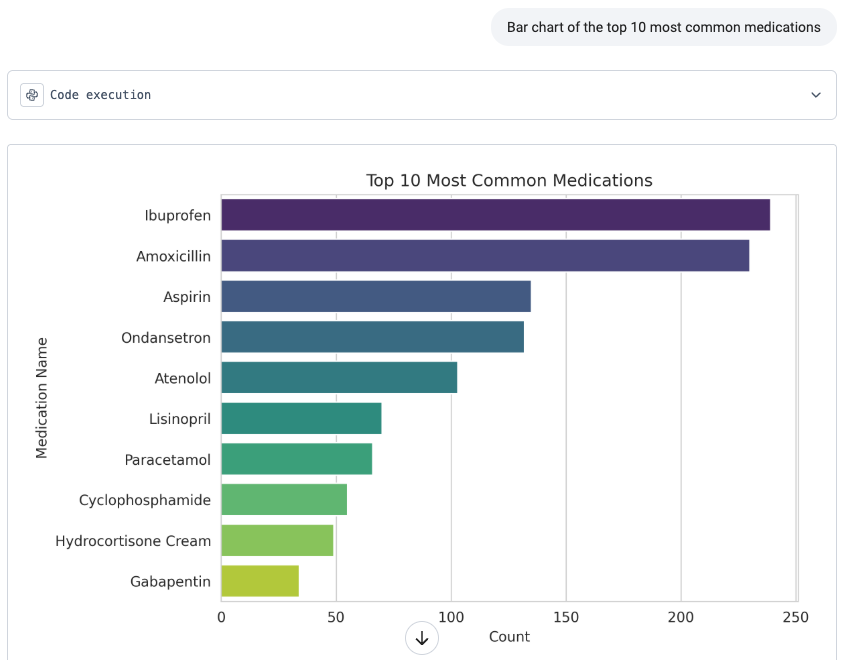
To validate the setup, I ask the Assistant how the tables are connected. It confirms the relationships and renders a diagram showing the structure. I also ask it to create a quick bar chart of the top 10 most common medications in the dataset. The output looks solid with Ibuprofen, Amoxicillin, Aspirin, and others appearing just as expected.
At this point, I have a complete and realistic mock dataset. I can download each table as a CSV file and import them into any database of my choice for testing, development, or early prototyping.
If the goal is simply to explore a schema or test functionality without involving sensitive data, this workflow is already complete.
Step 2: Scaling the Data and Pushing to a Production Database
Now that I have mock data in place, I move to the next step: scaling it into a much larger, enterprise-ready synthetic dataset.
I ask the Assistant to configure a generator using the mock data from Step 1. It sets up a multi-table generator that preserves all relationships and metadata. Once configured, I kick off the training process, which prepares the model to generate synthetic data at scale.
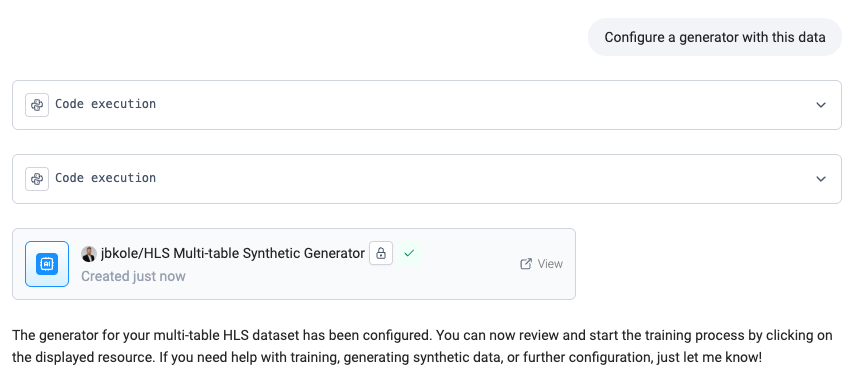
With the trained generator ready, I launch a generation job and increase the sample size from 150 to 100,000 patients. The linked tables like visits, diagnoses, and medications scale automatically based on these relationships.

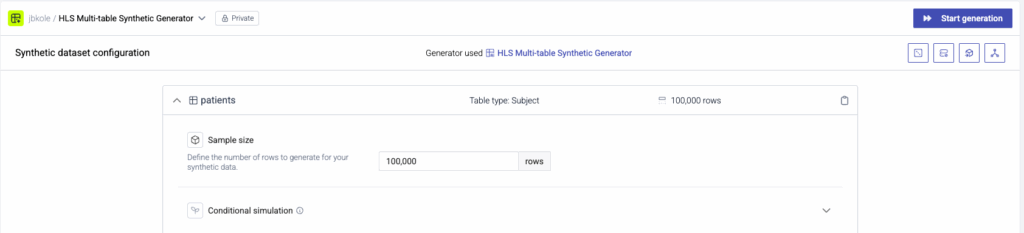
This time, instead of downloading the output as CSV files, I send the synthetic data directly into a database. I select a pre-configured destination connector pointing to a Databricks instance, where I’ve already created a catalog and schema named jbcatalog.hls.
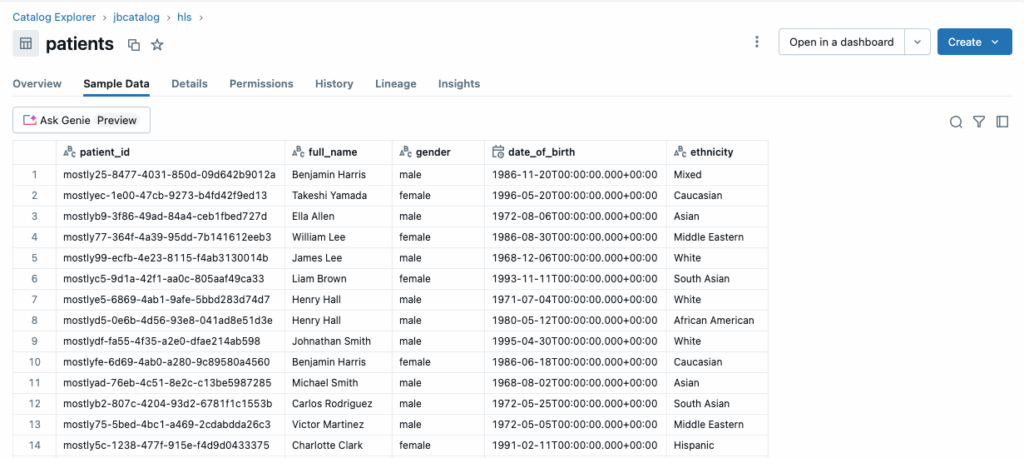
After starting the job, I switch over to my Databricks workspace and refresh the schema. Within seconds, I see all four tables—patients, visits, diagnoses, and medications—fully populated. I query the patients table and confirm it contains exactly 100,000 rows, just as expected.
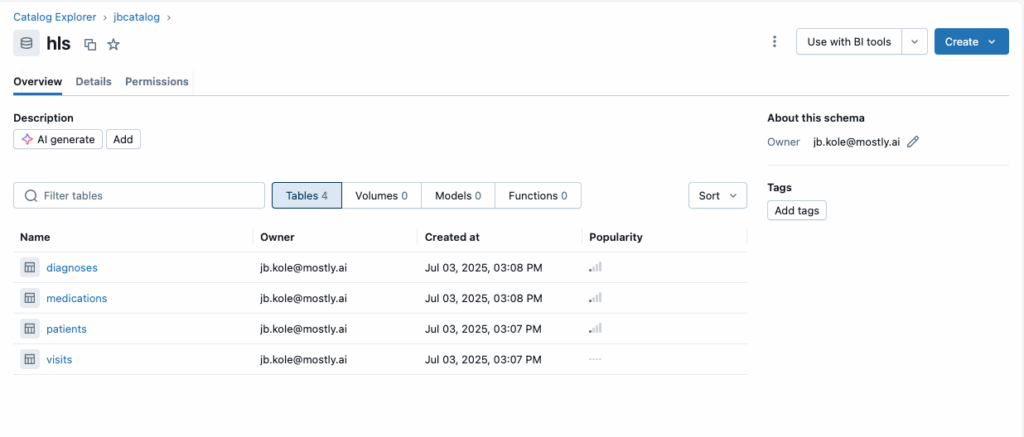
The synthetic data mirrors the structure of the original mock data and is now accessible within a production-grade analytics environment without any of the privacy concerns or legal delays tied to real data.
While I’m using Databricks here, this process works just as easily with Snowflake, PostgreSQL, MySQL, and other supported systems. The Assistant, combined with destination connectors, enables seamless delivery of high-quality data to wherever it is needed.
Final Thoughts
This end-to-end workflow moves from schema definition and mock data creation to large-scale synthetic data generation and delivery. It is driven primarily through natural language, with only light use of the UI when needed.
For teams working in healthcare and life sciences, but also any other industry, this provides a fast, privacy-safe way to enable testing, model development, and analytics at scale. Whether you're a data engineer, analyst, or product owner, this approach helps to get data quickly, even if you don’t have any data to begin with.
If you're exploring synthetic data for real-world use cases, the Assistant makes it easy to get started. Just describe what you need and let the platform guide the rest.


