
We’re incredibly proud to share the highlights of our latest Synthetic Data Platform release - v200 - in this blog post!
Over the past couple of months the team has been working extremely hard to incorporate a ton of feedback from our Enterprise Clients and FREE Version users. We’ve also made a significant effort in making sure that we come one (huge) step closer in realizing our vision for the product and how we believe machine learning generated synthetic data can have the most impact in organizations.
There are so many improvements and new features across various different aspects of the platform that it’s impossible to cover everything and impossible to rank them in order of importance. But together all these improvements and changes will lead to an entirely new user experience. One that we are very excited about and we think you will be too. So without further ado, let’s dive into the magic of v200!
Empowering you to train your Generative AI Model on Tabular Data
Generative AI has been all over the news for more than a year now. And there’s no question about it - it’s a magical technology! The truth is, we’ve been fans of Generative AI not only since the launch of ChatGPT in November 2022, but for more than 7 years when we started MOSTLY. Maybe it wasn’t clear to everyone but our platform is (and always was) leveraging Generative AI to create synthetic data. We’re extremely excited to make this more obvious by introducing the "Generator" concept.
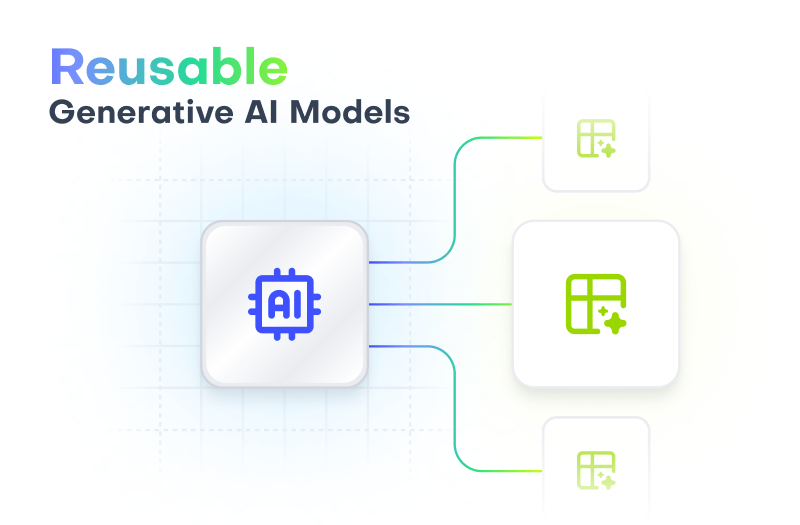
This is a major update of the workflow that better reflects how the platform is used in practice. There are two groups of users for our platform
- Individuals that have access to production data. They can train a Generative AI model with that data and by doing so create "Generators". A Generator bundles the trained Generative AI model and the definition of metadata about tabular data (table schemas, table relationships, and data types).
- Individuals that don't have access to production data (we like to call them “Data Consumers”). They can access these "Generators" to easily create "Synthetic Datasets". And they can now do so with great flexibility in how to generate synthetic data for their specific needs!
Improved UI/UX
We love to use products that have a slick user interface and user experience ourselves. And while we were pretty happy with our platform already, we knew that some aspects of it were a bit confusing and well… not as slick as they could have been. And so we changed that!
If you’ve been a user of our previous versions you will immediately notice the difference when logging into v200 for the first time. There are many small improvements across the board, but these are the most important ones:
- Overall improved look & feel of the platform for more intuitive workflows
- Faster and simpler configuration of multi table setups
- Faster and simpler configuration of advanced features like value protection and flexible generation
- More flexible way of configuring and working with data connectors
- More flexible way to controlling temperature of synthetic data generation

Defining a maximum Training Time
There is one major change that I’m personally extremely excited about: it’s now possible to conveniently define a max. time for the training phase of a Generator! No more guessing how long the AI training might take. If you’re in a rush choose the predefined “Speed” configuration which will limit the training time to 10 min. If the quality of the Generator is not what you expect then increase the max. training time. But trust me - you’ll be probably surprised how good the results are even with short training times.

API & Python Client
One of the guiding principles has always been for us to make it as simple as possible for users to create synthetic data. That’s why we’re very proud that with only a couple of clicks virtually anyone can create the industry's most accurate synthetic data. At the same time we knew that our more sophisticated users were asking for more: more flexibility to work with the platform and the opportunity to seamlessly integrate synthetic data generation in existing workflows. That’s why we’re introducing an entirely redesigned API and an entirely new Python Client.

Our previous API offered the opportunity to control basic elements of the synthetic data generation process. But nothing beyond that. On the contrary: our new API allows users to control every single aspect of the platform. Everything that can be done via the UI, is now possible to do in a programmatic way via the API!
You will find a comprehensive documentation for the API here: https://api-docs.mostly.ai/
But we didn’t stop there. A lot of users of our platform are data scientists and their main environment for working are Jupyter Notebooks and Python. And we wanted to make your life a whole lot easier. And we’re doing so by now offering a simple to use Python client to directly work with our platform. Getting started is as simple as
pip install mostlyaiand then using the code example directly from the platform
from mostlyai import MostlyAI
# initialize client
mostly = MostlyAI(
api_key='YOUR-API-KEY',
base_url=''
)
# train a generator
g = mostly.train('https://github.com/mostly-ai/public-demo-data/raw/dev/census/census.csv.gz')
# share a generator with your colleagues
mostly.share(g, 'analytical.amanda@your-company.com')
mostly.share(g, 'creative.clara@your-company.com')
mostly.share(g, 'strategic.sarah@your-company.com')
# generate a synthetic dataset
sd = mostly.generate(g)
# start using it
sd.data()
As you explore our updated documentation, you will find code snippets that show how to accomplish a task with the Python client. Use the Python and UI tabs to switch between the code snippets and the UI steps.
Seed Generation

I would dare to say that Seed Generation is one of the most neglected, yet most powerful features of our platform. Already in the past it was possible to provide a Seed to “conditionally” create a synthetic linked table. Now it’s possible to do exactly that for a single table too. What this means is that you can specifically control what kind of synthetic data you will get.
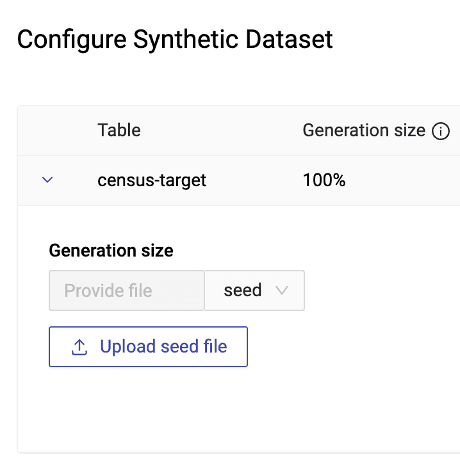
Let’s say for example that you have a Generator that was trained on the US Census dataset. But you’re only interested in a certain subgroup of that large representation of the US population. You only care about 27 year old university graduates and you would like to get a better understanding about them. With Seed Generation you can define a Seed for that synthetic data generation. It basically consists of the age variable and the education variable.

And then your generated synthetic dataset will be just that: 27 year olds with some sort of college degree.
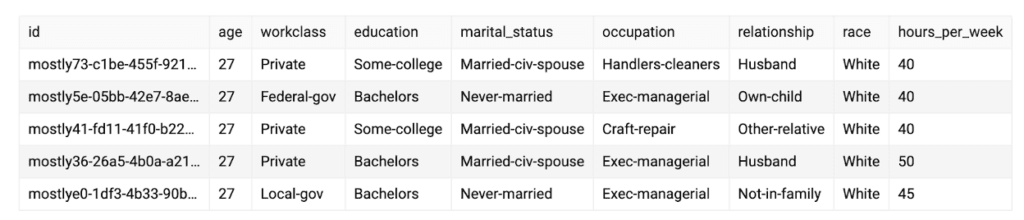
When privacy is not the main concern this feature can also be used to create mixed real- and synthetic datasets. You can basically “fix” certain columns to represent the original data (by providing them as a Seed) and then have the rest of the variables synthetically generated.
And the best part: all of this happens during the creation of a Synthetic Dataset. That means whoever configured the Generator in the first place does not have to worry about it. It’s just important that the Generator was created with “Flexible generation” turned on. Don’t worry though, it’s “On” by default.
Highly-scalable low-latency engine and improved data quality
Ok, granted - some of these improvements were already quietly introduced in some of our latest releases but together with additional optimizations it’s now time to bring all of this before the curtain.
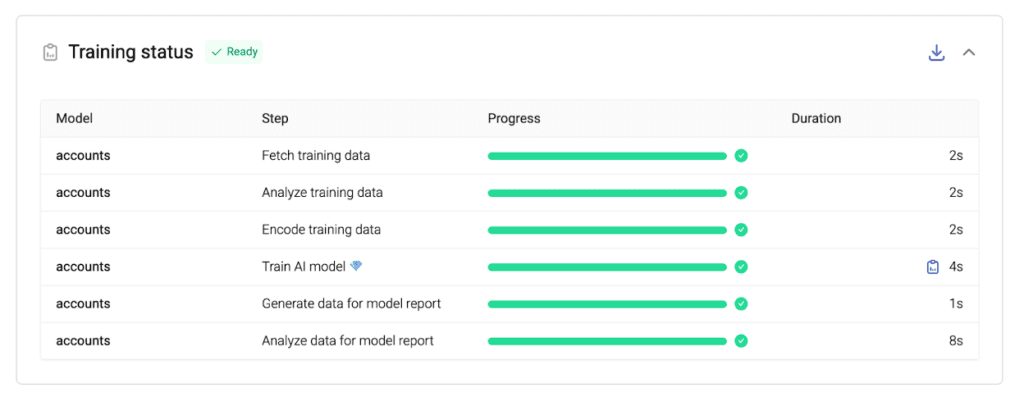
We are all impatient. That’s also true when working with IT tools and of course it’s also true when working with our synthetic data platform. We are thus very happy to share that we were able to achieve improved performance and speed across the entire synthesis process. Noticeably, there is no more lag between the different steps of creating a Generator and each step itself is also performed more quickly. With smaller datasets you will have a hard time catching up what’s happening - a couple of seconds and your Generator is ready to be shared!
Not only for small datasets, but also for very large datasets we are bringing a lot of improvements to the platform. If your data is spread over multiple partitioned Parquet files for example, you will notice a much better performance when loading and working with that data.
Speed is one thing we care about, but there is one other thing we care about even more: data quality. We have already provided the industry’s leading synthetic data quality in the past and we are now taking it even further. With v200 we are introducing excellent sequence length capabilities, catered specifically for large transaction data, i.e. multi-sequence multi-variate time-series data. If you have data with thousands of events per customer you will love the improved data quality!
Improved & easier deployment

Most of our customers prefer to run their own installation of our platform in their secure IT environments. And we get why - your production data is highly sensitive and you rather not have it leave your controlled systems. And synthetic data helps to alleviate exactly this concern after all by giving you a privacy-safe alternative to your production data that can be worked with much more flexibility.
Our platform gets deployed either via Kubernetes or OpenShift. And while these are standard infrastructure tools in most organizations today there are some specific and individual configurations that sometimes could cause issues in the past. And that’s why we made it faster and simpler than ever before to install our platform by providing:
- Simplified Helm Charts
- More flexible options when it comes to required storage classes
- An improved memory management for more robust platform operation
- A new, centralized logging for easier maintenance and issue remediation
Bonus
If you’re still reading - thank you, I know this was a lot! But you can probably tell how excited we are about all these changes and improvements. And this blog post didn’t even cover everything. The interested reader will find the complete list of changes in our User Documentation here.
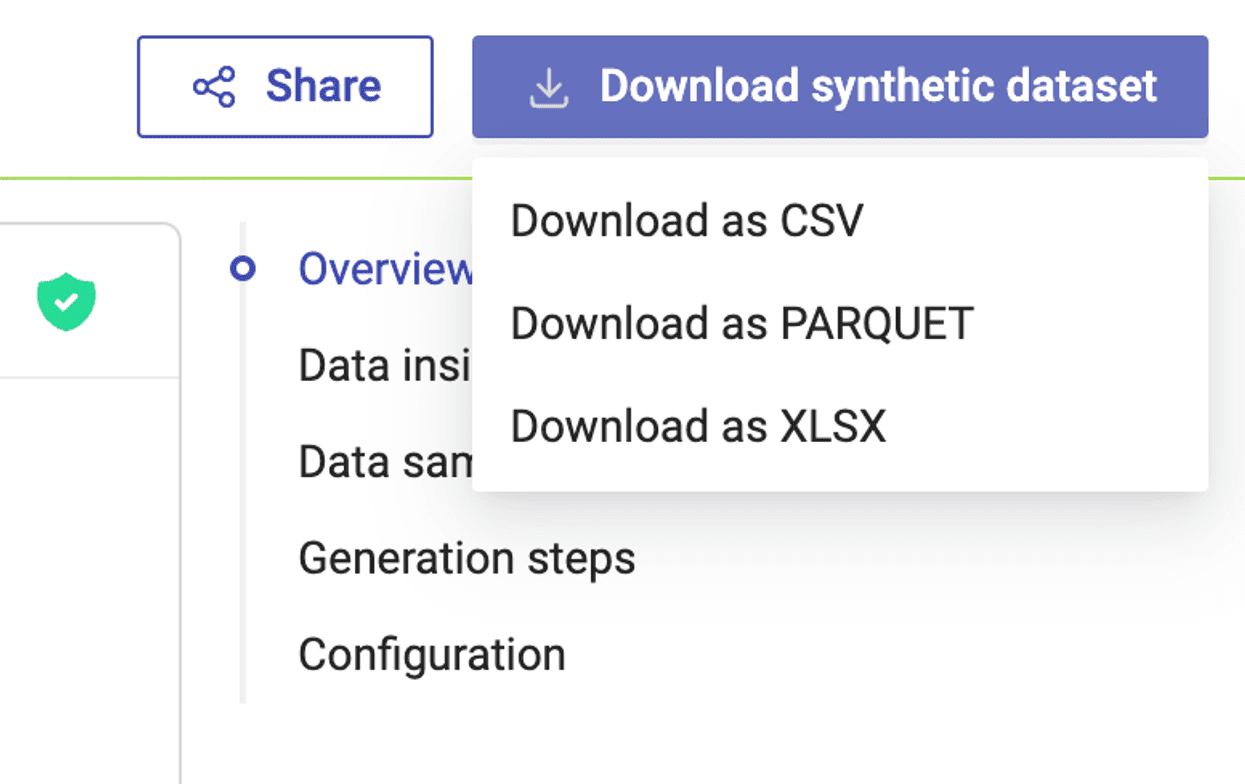
However, there is one cool feature that I still want to mention: Excel. Who doesn’t love Excel? Or Pivot Tables? Of course it was always possible to inspect and work with our synthetic data in Excel, but you had to take the extra step of importing a CSV file. With v200 that step won’t be necessary anymore. You can now download synthetic datasets not only as CSV and PARQUET files but also straight as an XLSX file. The Excel file will contain up to 10,000 samples of your synthetic data and is already neatly pre-formatted so that you can sort and filter your data right away, or create a Pivot Table with just a few clicks.
We’d love to hear from you
As always we would love to hear from you! Tell us what you love about v200, but also tell us what you don’t like as much. And certainly please let us know of any additional improvements and changes you would like to see in the future. You can contact us here.
Although this is a major upgrade to our platform this is really only the beginning. There are many more cool things we’re working on already. Expect to see many more exciting news in the next coming months!


