
Machine learning and AI applications are becoming more and more common across industries and organizations. This makes it essential for more and more developers to understand not only how machine learning models work, but how they are developed, deployed, and maintained. In other words, it becomes crucial to understand the machine learning process in its entirety. This process is often referred to as “the machine learning life cycle”. Maintaining and improving the quality of a machine learning life cycle enables you to develop models that consistently perform well, operate efficiently and mitigate risks.
This article will walk you through the main challenges involved in ensuring your machine learning life cycle is performing at its best. The most important factor is the data that is used for training. Machine learning models are only as good as the data that goes into them; a classic example of “garbage in, garbage out”.
Synthetic data can play a crucial role here. Injecting synthetic data into your machine learning life cycle at key stages will improve the performance, reliability, and security of your models.
What is a machine learning life cycle?
A machine learning life cycle is the process of developing, implementing and maintaining a machine learning project. It includes both the collection of data as well as the making of predictions based on that data. A machine learning life cycle typically consists of the following steps:
- Data Collection
- Data Preparation
- Model Selection
- Model Training and Evaluation
- Model Tuning
- Model Deployment and Monitoring
- Model Explanation
- Model Retraining

In reality, the process of a machine learning life cycle is almost never linear. The order of steps may shift and some steps may be repeated as changes to the data, the context, or the business goal occur.
There are plenty of resources out there that describe the traditional machine learning life cycle. Each resource may have a slightly different way of defining the process but the basic building blocks of a machine learning life cycle are commonly agreed upon. There’s not much new to add there.
This article will focus on how you can improve your machine learning life cycle using synthetic data. The article will discuss common challenges that any machine learning life cycle faces and show you how synthetic data can help you overcome these common problems. By the end of this article, you will have a clear understanding of how you can leverage synthetic data to boost the performance of your machine learning models.
The short version: synthetic data can boost your machine learning life cycle because it is:
- high-quality,
- high-availability, and
- privacy-proof.
Read on to learn more 🧐
The role of synthetic data in your ML life cycle
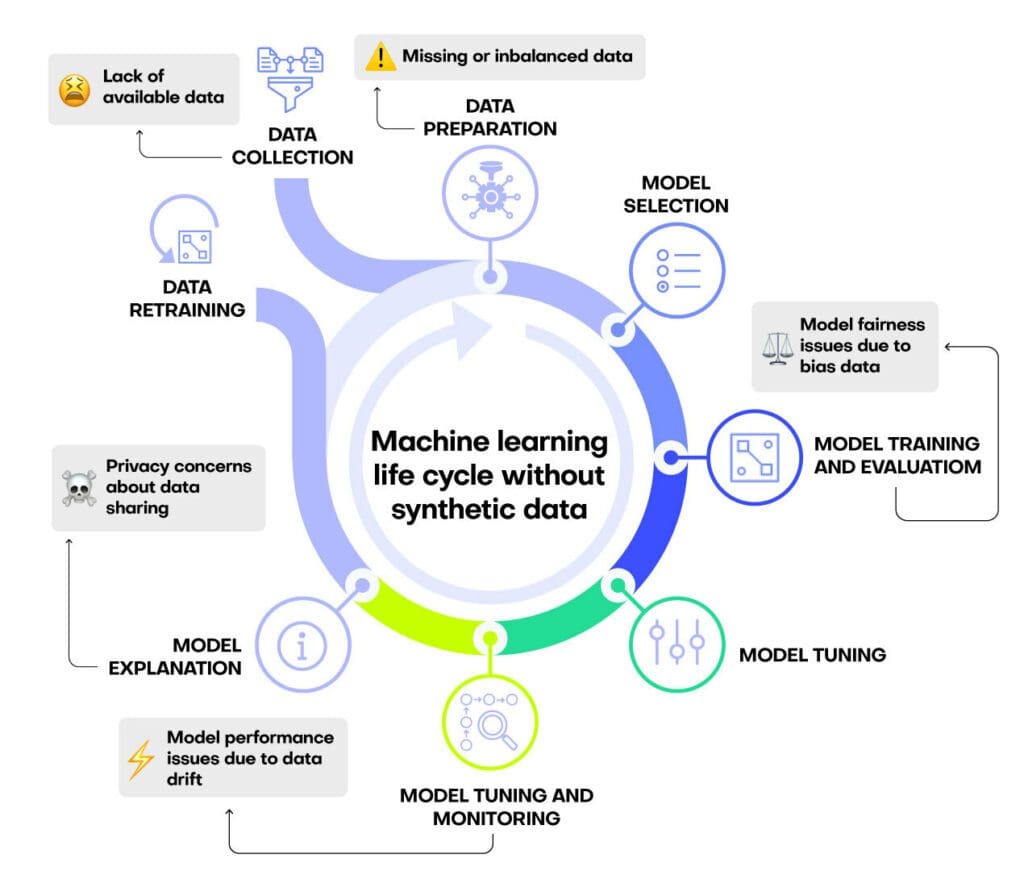
Every machine learning life cycle encounters some, if not all, of the problems listed here:
- A lack of available training data, often due to privacy regulations
- Missing or imbalanced data, which will impact the quality of the downstream machine learning model
- Biased data, which will impact the fairness of the downstream machine learning model
- Data drift, which will impact model performance over time
- Inability to share models or results due to privacy concerns
Let’s take a look at each one of these problems and see how synthetic data can support the quality of your machine learning life cycle in each case.
Data collection
The problem starts right at the first step of any machine learning project: data collection. Any machine learning model is only as good as the data that goes into it and collecting high-quality, usable data is becoming more and more difficult. While the overall volume of data available to analysts may well be exploding, only a small fraction of this can actually be used for machine learning applications. Privacy regulations and concerns obstruct many organizations from using available data as part of their machine learning project. It is estimated that only 15-20% of customers consent to their data being used for analytics, which includes training machine learning models.
Synthetic data is infinitely available. Use synthetic data to generate enough data to train your models without running into privacy concerns.
Once your generator has been trained on the original dataset it is able to generate as many rows of high-quality, synthetic data as you need for your machine learning application. This is a game-changer as you no longer have to scrape together enough high-quality rows to make your machine learning project work. Make sure to use a synthetic data generator that performs well on privacy-preservation benchmarks.
Data preparation
Real-world data is messy. Whether it’s due to human error, sensor failure or another kind of anomaly, real-world datasets almost always contain incorrect or missing values. These values need to be identified and either corrected or removed from the dataset. The first option (correction) is time-intensive and painstaking work. The second option (removal) is less demanding, but can lead to a decrease in the performance of the downstream machine learning model as it means removing valuable training data.
Even if the data sourcing is somehow perfect – what a world that would be! – your machine learning lifecycle may still be negatively impacted by an imbalanced dataset. This is especially relevant for classification problems with a majority and a minority class in which the minority class needs to be identified.
Fraud detection in credit card transactions is a good example of this: the vast majority of credit card transactions are perfectly acceptable and only a very small portion of transactions are fraudulent. It is crucial to credit card companies that this very small portion of transactions is properly identified and dealt with. The problem is that a machine learning model trained on the original dataset will not have enough examples of fraudulent behavior to properly learn how to identify them because the dataset is imbalanced.
Synthetic data can be better than real. Use synthetic data to improve the quality of your original dataset through smart imputation and synthetic rebalancing.
Model training and evaluation
Many machine learning models suffer from embedded biases in the training data which negatively impact the model’s fairness. This can have negative effects on both societal issues as well as on companies’ reputation and profit. In one infamous case investigated by ProPublica, a machine learning model used by the U.S. Judicial system was shown to make biased decisions according to defendants’ ethnicity. This led to incorrect predictions on the likelihood of defendants to re-offend which in turn affected their access to early probation or treatment programs.
While there is no single cause for biased training data, one of the major problems is a lack of sufficient training data, leading to certain demographic groups being underrepresented. As we have seen, synthetic data can overcome this problem both because it is infinitely available and because imbalances in the data can be fixed using synthetic upsampling.
But biases in AI machine learning models are not always due to insufficient training data. Many of the biases are simply present in the data because we as humans are all biased to some degree and these human biases find their way into training data.
This is precisely where Fair Synthetic Data comes in. Fair Synthetic Data is data whose biases have been corrected through statistical tools such as demographic parity. By adding fairness constraints to their models, synthetic data generators are able to ensure these statistical measures of fairness.
Synthetic data can increase data fairness. Use synthetic data to deal with embedded biases in your dataset by increasing the size and diversity of the training data and ensuring demographic parity.
Model tuning and maintenance
Once a machine learning model has been trained, it needs to be tuned in order to boost its performance. This is generally done through hyperparameter optimization in order to find the model parameter values that yield the best results. While this is a useful tool to enhance model performance, the improvements made tend to be marginal. The improvements are ultimately limited by the quality and quantity of your training data.
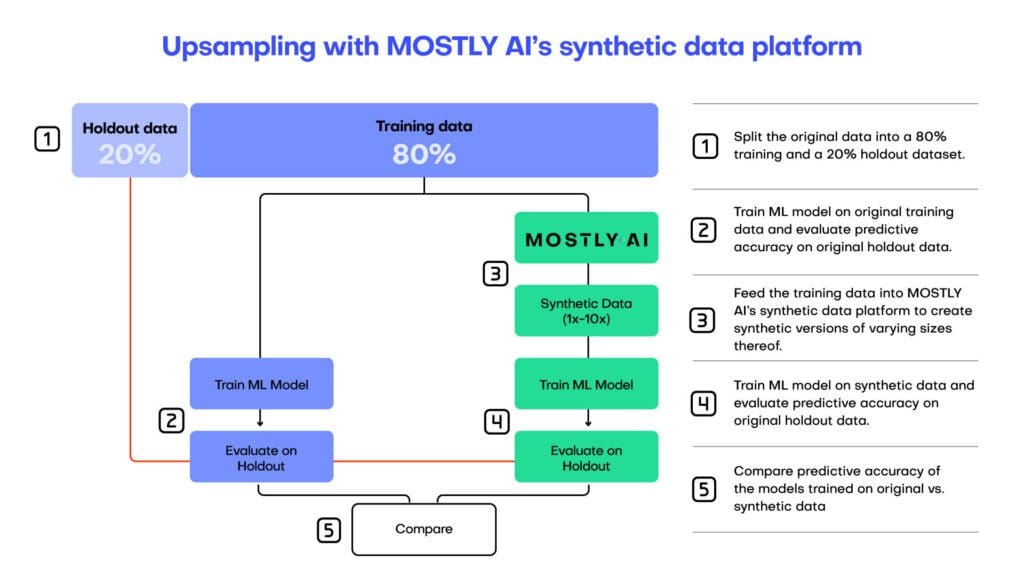
If you are working with a flexible capacity machine learning model (like XGBoost, LightGBM, or Random Forest), you may be able to use synthetic data to boost your machine learning model’s performance. While traditional machine learning models like logistic regression and decision trees have a low and fixed model capacity (meaning they can’t get any smarter by feeding them more training data), modern ensemble methods saturate at a much later point and can benefit from more training data samples.
In some cases, machine learning model accuracy can improve up to 15% by supplementing the original training data with additional synthetic samples.
Once your model performance has been fine-tuned, it will need to be maintained. Data drift is a common issue affecting machine learning models. As time passes, the distributions in the dataset change and the model is no longer operating at maximum performance. This generally requires a re-training of the model on updated data so that it can learn to recognize the new patterns.
Synthetic data can increase model accuracy. Use synthetic data to boost flexible-capacity model performance by providing additional training samples and to combat data drift by generating fresh data samples on demand.
Model explanation and sharing
The final step of any machine learning life cycle is the explanation and sharing of the model and its results.
Firstly, the project stakeholders are naturally interested in seeing and understanding the results of the machine learning project. This means presenting the results as well as explaining how the machine learning model arrived at these results. While this may seem straightforward at first, this may become complicated due to privacy concerns.
Secondly, many countries have AI governance regulations in place that require access to both the training data and the model itself. This may pose a problem if the training data is sensitive and cannot be shared further. In this case, high-quality, representative synthetic data can serve as a drop-in replacement. This synthetic data can then be used to perform model documentation, model validation and model certification. These are key components of establishing trust in AI.
Synthetic data safeguards privacy protection. Use synthetic data to support Explainable AI efforts by providing highly-representative versions of sensitive training datasets.
The role of synthetic data in your ML life cycle
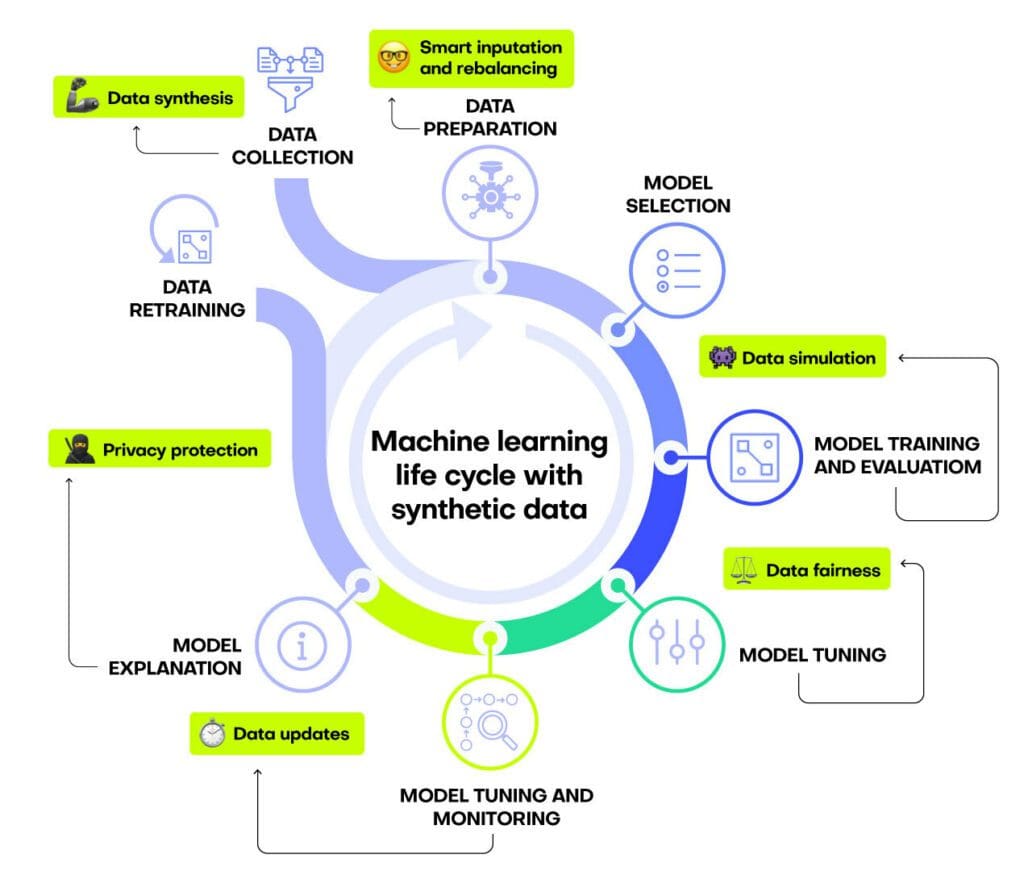
Synthetic data can address key pain points in any machine learning life cycle. This is because synthetic data can overcome limitations of the original, raw data collected from ‘the real world’. Specifically, synthetic data can be highly available, balanced, and unbiased.
You can improve the quality of your machine learning life cycle by using synthetic data to:
- Generate sufficient training data without privacy concerns
- Improve data quality through smart imputation and synthetic rebalancing
- Improve data fairness by removing embedded biases
- Boost model accuracy through training sample generation and data updates
- Share and explain AI models without infringing on privacy regulations
If you’re looking for a synthetic data generator that is able to consistently deliver optimal privacy and utility performance, give synthetic data generation a try today and let us know what you think – the first 100K rows of synthetic data are on us!


