
We proudly present the free version of MOSTLY AI's synthetic data platform and warmly welcome you to try it out.
What does MOSTLY AI's synthetic data platform do?
MOSTLY AI enables you to automatically transform your privacy-sensitive big data assets into highly realistic and accurate synthetic datasets. The benefit is, that synthetic data is fully anonymous and thus exempt from data protection regulations. This results in as-good-as-real data, that is free to use, share or monetize. So with MOSTLY AI's synthetic data platform, you are finally able to freely innovate with one of your most valuable resources – all while avoiding the financial, regulatory or reputational risks of a privacy violation!
How does our synthetic data platform work?
MOSTLY AI's synthetic data platform leverages state-of-the-art generative deep neural networks with in-built privacy mechanisms to automatically learn the patterns, structure and variation from an existing dataset. Once the training is completed, it allows you to simulate an unlimited number of highly realistic and representative – but completely anonymous – synthetic customers. Thereby, you are able to retain all the valuable information in your data assets, while at the same time rendering the re-identification of any individual impossible.
How does the free version compare?
The free version of MOSTLY AI's synthetic data platform comes with the same powerful core technology as the enterprise version: our fully automated Synthetic Data Engine. This will enable you to generate synthetic data based on a provided actual dataset and to experience the magic of generative AI in action. Try it out today and persuade yourself of its quality, its flexibility and its ease-of-use.
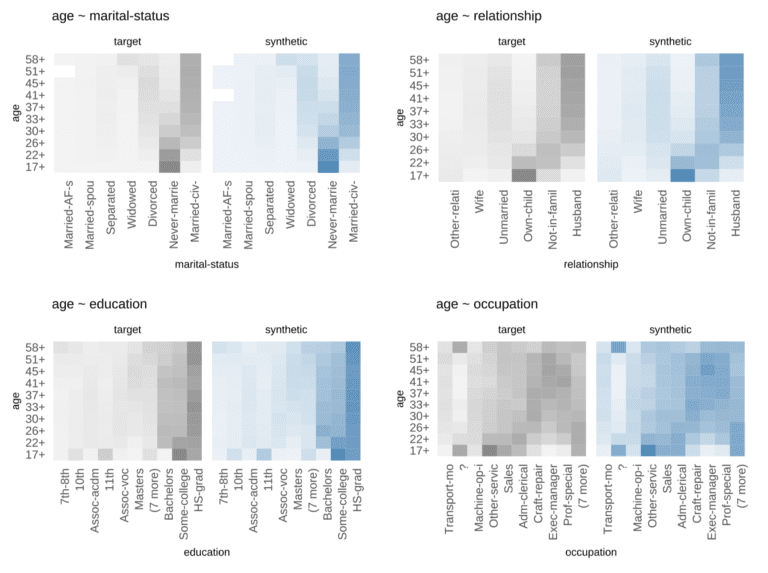
the quality of your synthetic data (blue) with the original (grey).
But keep in mind, that it is a free version and that some usage restrictions apply. While the enterprise version of MOSTLY AI's synthetic data platform supports multiple tables and extremely large datasets with millions of rows and hundreds of columns, we limit the input for the free version to a single table with 50.000 rows and 50 columns. Furthermore, you won’t have the same flexibility as with our enterprise version to configure the training or the generation process. And as we operate this demo on a low-cost cloud infrastructure, the compute time will be significantly longer than for production setups.
Lastly, since it is a demo version, you must not use it to upload any personal or sensitive data. But no worries – if you don’t have a suitable dataset at hand, just go to Kaggle and choose a publicly available dataset you like. Or, if you are looking for even more convenience, simply select one of the datasets already provided on the demo site to start your first synthesis run in a matter of seconds!
With that being said, we warmly welcome you to generate synthetic data and to start your own personal journey with this groundbreaking technology. We are very much looking forward to your valued feedback and are here to answer your questions, should any arise.


