
The General Data Protection Regulation (GDPR) puts strict policies in place for dealing with personal data, or Personally Identifiable Information (PII). It can be intimidating to make sure you follow the right rules that apply to your dataset so you don’t run into expensive fines. Fortunately, the GDPR also provides exceptions to these demanding rules when the personal data in question has been processed using an approved privacy-enhancing technique, such as anonymization or pseudonymization.
There are important differences between anonymization and pseudonymization techniques. The two techniques function differently and result in varying levels of privacy protection. For this reason, the GDPR puts separate policies in place for data that has been pseudonymized vs. data that has been anonymized. You will need to be able to recognize and understand the differences between these two forms of privacy protection when navigating the regulatory complexities of GDPR compliance. Because of the privacy-utility trade-off, you will also need to understand how the two techniques differ in the data utility they can guarantee.
This article will explain the difference between the two approaches in detail. You will learn about the practical implications of pseudonymization and anonymization, the tradeoffs between privacy and data utility, and how synthetic data can help. The information in this article will support you to implement the best privacy protection strategies for your data projects.
Note that the information in this article does not constitute legal advice. Always consult with a legal expert who knows the specific details of your use case and application.
Pseudonymization vs Anonymization: Quick Definition
The main difference between pseudonymization and anonymization is how easily personal data can be re-identified after the technique has been applied. Pseudonymization involves reversible transformations to the data that makes the personal data less identifiable. Anonymization, on the other hand, takes a stricter approach and ensures irreversibility and absolute detachment from individual identities. Pseudonymized data still needs to comply with the GDPR; fully anonymized data does not.
Let’s take a closer look at what this means for your data projects. We’ll start with some definitions to make sure we understand all the relevant concepts.
What is personal data or personally identifiable information (PII)?
First, let’s start by defining the type of data the GDPR applies to: personal data, also known as personally identifiable information (PII):
“Personal data” refers to any information concerning an identifiable individual. An identifiable person is someone who can be directly or indirectly distinguished, through identifiers like a name, identification number, location data, online identifier, or specific factors related to the physical, genetic, mental, economic, cultural, or social identity of the individual.
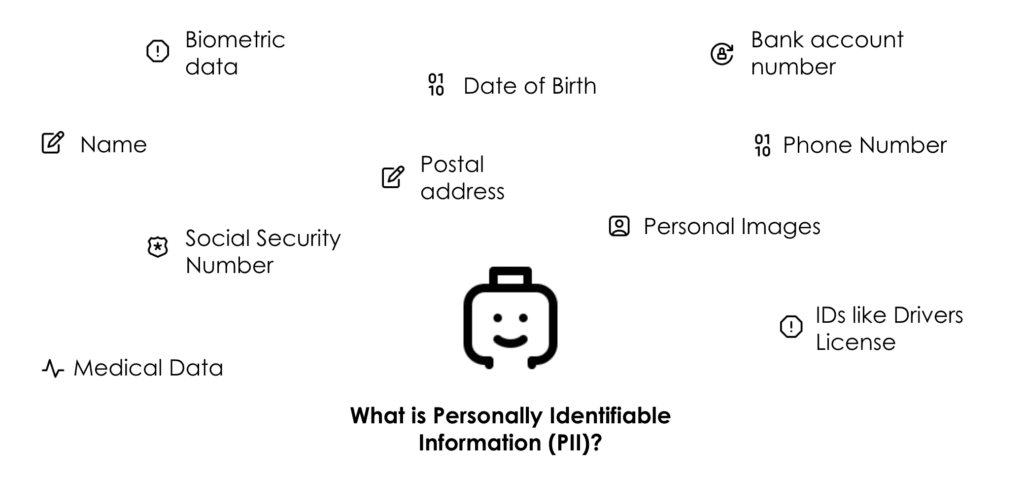
The GDPR only applies if your data project involves personal data. This means that if you can guarantee that your data cannot be used to identify any of the individuals it originated from then the GDPR simply does not apply and you are free to process the data in any way you like.
What is pseudonymization?
‘Pseudonymization’ is the handling of personal data in a way that prevents direct association with a particular data subject unless additional information is used. Pseudonymization is also often referred to as de-identification by regulators in other countries, including in the US.
Pseudonymization is performed by separating the source data into identifiable and non-identifiable fields. The non-identifiable data can be kept intact while the identifiable data should be stored separately and securely. Sometimes actual pseudonyms are used to mask the sensitive data fields.
For example, let’s say we have a data record for Barry Lee containing information about their:
- name
- age
- occupation
- address
- favorite food
To pseudonymize this data, we would separate the sensitive data (name and address) from the non-sensitive data (age, occupation and favorite food). The two tables would be linked using a unique reference identifier and the sensitive data would be stored separately from the non-sensitive data. Sometimes the sensitive data is also deleted altogether. The non-sensitive data can then be used for data applications such as analysis or training machine learning models.

While this approach offers basic privacy measures, the process is not rigorous enough to guarantee protection. Firstly, because the non-sensitive data stays the same, it still contains parts of identifiable information hidden in the non-PII attributes. In some cases, it may be possible to identify an individual from these supposedly “non-PII” features (also known as “quasi-identifiers”), such as age and occupation or combinations thereof. Secondly, the pseudonymization process is easily reversible if the sensitive data is compromised since the two tables are clearly linked. (Note: This is not an issue if the sensitive data parts have been deleted.)
For this reason, data that has been pseudonymized is still considered personal data. This means that pseudonymized data falls under the GDPR and you need to ensure compliance.
“Personal data which have undergone pseudonymisation, which could be attributed to a natural person by the use of additional information should be considered to be information on an identifiable natural person.”
https://www.privacy-regulation.eu/en/recital-26-GDPR.htm
What is anonymization?
Anonymization is the process of removing all personal identifiers from personal data and making sure that the individual can also not be identified from any of the remaining non-sensitive data fields. Anonymized data, then, is data which does not relate or cannot be related to an identifiable person. This means that even the person or program who performed the anonymization will not be able to reverse the operation.
In the case of our example record for Barry Lee, this would mean irreversibly removing all PII attributes such as name and address. It may also mean abstracting the favorite food into a broader category to further decrease the risk of re-identification. However, there is no “one standard” as to how to anonymize data nor when data is considered to be anonymous. The GDPR defines anonymous data when there are no “means [that] are reasonably likely to be used to identify the natural person”. And it further specifies that “To ascertain whether means are reasonably likely to be used to identify the natural person, account should be taken of all objective factors, such as the costs of and the amount of time required for identification, taking into consideration the available technology at the time of the processing and technological developments.”

But once it has been established that data is anonymous, the GDPR does not apply to the processing of such anonymous information.
“The principles of data protection should therefore not apply to anonymous information, namely information which does not relate to an identified or identifiable natural person or to personal data rendered anonymous in such a manner that the data subject is not or no longer identifiable. (…) This Regulation does not therefore concern the processing of such anonymous information, including for statistical or research purposes.”
https://www.privacy-regulation.eu/en/recital-26-GDPR.htm
Pseudonymization vs Anonymization: how it affects your Data Utility
The privacy protection of your personal dataset is important, but it is only one half of the story. You also need to make sure that your data retains a sufficient level of utility. This is also known as the privacy-utility trade-off: traditionally, the more privacy you ensure, the lower the utility of the data you end up with.
Let’s take our anonymized data record for Barry Lee as an example. We have successfully removed all attributes that could be used to identify Barry from this record. But you will notice that this also means we have lost valuable data that is now no longer available to our downstream analysis or machine learning models. We do not know where Barry lives, nor do we know his exact profession. We have sacrificed data utility to ensure data privacy.
Traditional anonymization techniques struggle to find the ideal point at which you can ensure sufficient privacy and maintain enough data utility for your downstream analysis or machine learning applications. Because they maintain a 1:1 relationship between each record and a specific person, there will (almost) always be a possibility of re-identification, unless the data is anonymized to the point of no longer being useful for downstream applications.
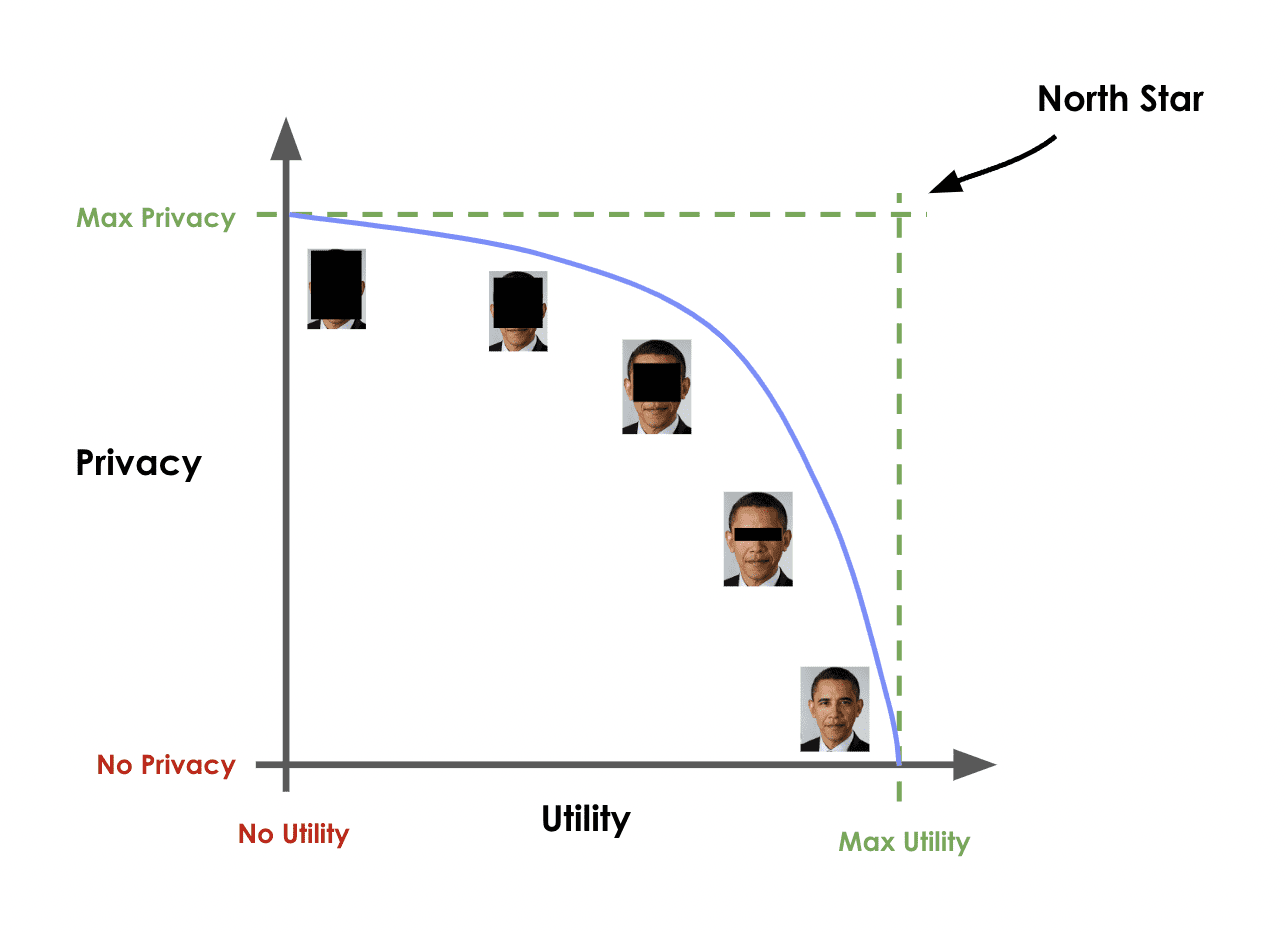
Many studies have shown that data that has been traditionally anonymized is actually not safe at all. E.g. see here, here, and here
Synthetic Data Anonymization
Synthetic data offers you a way out. Synthetic data is newly made up data and therefore contains no direct links to the real individuals whose privacy we are working so hard to protect. Instead of masking the sensitive parts of real records, synthetic data takes a fundamentally different approach. ML powered data synthesis is performed by training an AI algorithm on the original, sensitive data. The algorithm learns the data’s overall patterns and structures and then uses this generalized statistical information to generate entirely made up but statistically representative new records.
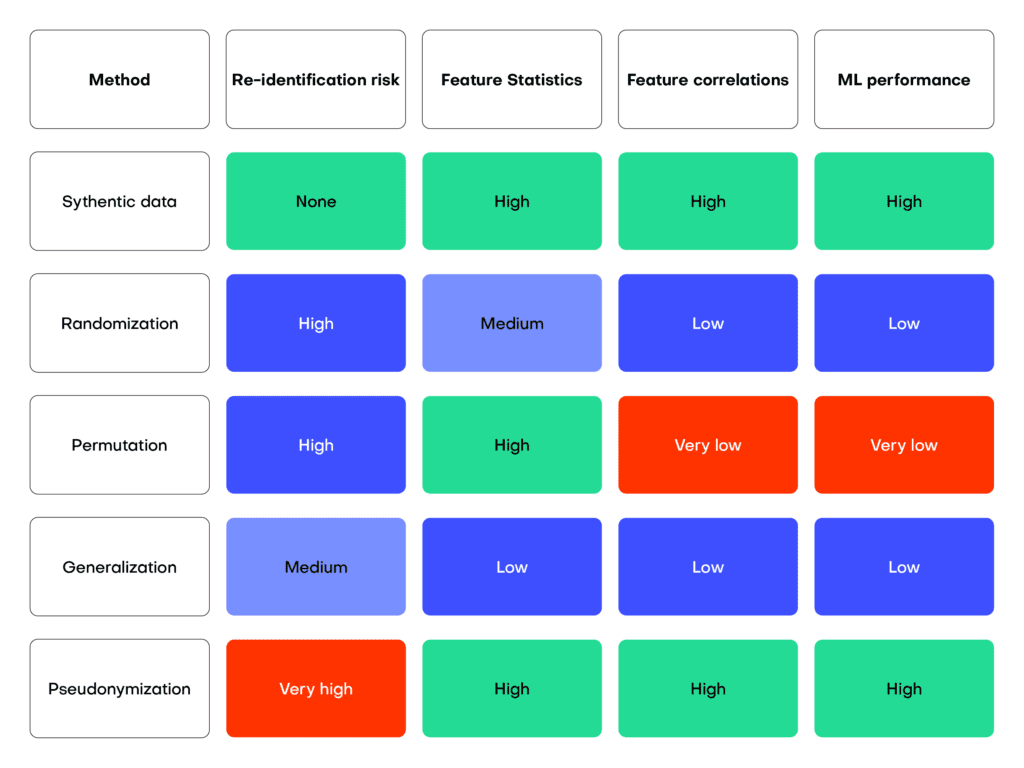
The table below gives an overview of different anonymization techniques and their relative privacy risks vs utility scores. While pseudonymization maintains much of the downstream data utility, it offers only minimum privacy protection. Generalization, on the other hand, which we applied to Barry Lee’s occupation, considerably lowers the re-identification risk but also decreases the utility of the remaining data.
Pseudonymization vs Anonymization: Conclusion
This article has explained the difference between pseudonymization and anonymization. Pseudonymization offers some privacy protection by separating out the sensitive data fields. However, the GDPR still considers this to be personal data and it will need to be handled in accordance with its regulations. Anonymization, on the other hand, offers much stronger privacy guarantees by irreversibly removing any attributes that pose any risk of re-identification. For this reason, the GDPR regulations for personal data do not apply to fully anonymized data.
You have also seen that anonymization techniques can severely degrade your data utility and that there is no “standard” on how to anonymize data or when data is considered to be anonymous. Traditional techniques struggle with the privacy-utility trade-off and overcompensating for privacy often causes negative impacts on your downstream applications. Synthetic data can help you ensure both maximum privacy and data utility by learning the overall population statistics from the source data and using these to generate representative but entirely new synthetic records.
If you’re looking for a synthetic data generator that is able to consistently deliver optimal privacy and utility performance, give MOSTLY AI a try today and let us know what you think!


