
Why Privacy Matters?
“Knowledge is power” should be a familiar quote for most of us. But did you know that in the earliest documented occurrence of this phrase from the 7th century the original sentence finishes with “…and it can command obedience”? If we apply this idea to personal information it’s easy to understand why privacy matters. Nobody wants to be at the receiving end.
Today privacy is recognized as one of the fundamental human rights by the UN and protected through international and national level legislation. Not complying with privacy regulations can be very costly if not a business-threatening risk for organizations working with their customers’ data.
Should We Trust Blindly?
Never before has it been as difficult as now to preserve individuals’ privacy. People have lost track and control of what kind of personal data, how much of it, why and where it is being collected, stored and even sold further. From “1000 songs in our pockets” (Apple’s first iPod slogan) we moved to an endless number of apps and trackers in our pockets, recording our daily activities. In our homes as well as in public spaces, devices with sensors and meters record every step and action we take.
As an individual, it’s wise to question if the consent given to a data controller is compliant with current privacy regulations. Because sometimes data controllers turn to the Dark Side by collecting unnecessary data, sharing data with third parties, failing to protect data appropriately or using it in a discriminatory way against the data subjects.
The Industry’s Dirty Secret About Privacy
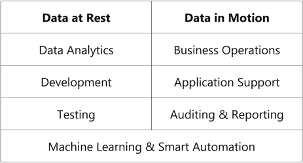
But even the data controllers who are not crossing the legal red lines are struggling more and more to protect their customer’s data at rest as well as in motion. Their life would be much easier if customer data could be locked up in a safe. But data, if not the new oil of our economy, is for sure the lubricant necessary to keep the business machine running. This means that every company needs to expose its customer’s data at least for the following purposes:
Often it’s not the bad intention but simple incapability of data controllers to comply with privacy regulations because the instruments at their hands are not capable of securely anonymizing data without destroying all of the utility in it. I remember many discussions with data security officers at different companies admitting that their current processes aren’t compliant but as long as there is no technical fix they can’t stop the machine that’s running.
What do those data security officers mean when they say that there’s no technical fix for privacy compliance? Although there are many different methods to protect data like cryptography, tokenization and anonymization, all of them have some weak points when it comes to data protection.
Sometimes the weak point is the human: If cryptographic keys are compromised the privacy is lost. Sometimes, like in the case of classic anonymization techniques, the weak point is the technology. What more and more people realize is that classic anonymization (randomization, generalization,…) is at the same time an optimization problem and an uphill battle. When original data is modified it loses some of its information value and therefore its utility. The more protection the less utility and vice versa. The data anonymization engineer is continuously balancing between the legal requirements to protect the privacy of the data subjects and the business requirements to extract value out of the data.
But in the age of big data with millions of records and thousands of attributes this optimization is getting almost impossible to achieve. The more data points are being collected about individuals, the easier it gets to re-identify individuals even in large databases. For example, 80% of all credit card owners are re-identified by 3 transactions, even when only the merchant and the date of the transaction are revealed.
The anonymization trade-off has shifted to a paradox state where only useless data is sufficiently protected data. So if you have been using anonymized, granular level data for analytics or testing, the odds are high that a significant fraction of this data is actually re-identifiable and the privacy of your customers isn’t adequately protected.
This dirty secret is causing some sleepless nights in legal and security departments across various industries. What’s even scarier is that some organizations aren’t even aware of it. And the only thing worse than not protecting your customer’s privacy is acting with the false impression that you are doing it, which leads to organizations taking their guard down to freely share poorly anonymized information internally and externally.
The trouble is on the horizon. In 2019 GDPR fine total went up to almost 500 million Euros and it wouldn’t surprise me if this amount would double in 2020. But the legal fines aren’t the biggest trouble awaiting data controllers.
What Happens When Privacy Is Breached?
Nowadays, data breaches happen more frequently even when access to sensitive data is restricted. According to IBM, the odds of experiencing a data breach went up 31% in the last 5 years to a 29% likelihood of experiencing a data breach in the next two years. Data snoopers are the bank robbers of the 21st century. The average total cost of a data breach is millions of Euros and that doesn’t only consist of regulatory fines. The biggest cost factor of a data breach is the loss of reputation that directly leads to the loss of business.
This Sunday a story was published in British media holding all the components of a perfect privacy nightmare: a data breach of a governmental database containing personal information of about 28 million children. The breach happened through the access that the UK government has granted to an educational and training provider.
Just imagine what horrible things could be done with that data. Now go through your diabolical list and strike out “selling children’s private data to betting firms” – this task has already been successfully accomplished. How successfully? According to UK media, betting companies were able to significantly increase the number of children passing their identity checks and have used the stolen data to increase the number of young people who gamble online. The house always wins.
And there’s no sign that the winning streak of data adversaries will break anytime soon. Every year we see the number of data breaches and the volume of exposed sensitive data captured rising. With a total of 550 million leaked records last year, the 28 million data records of the recent breach in the UK will hardly break the top five data breaches of 2019.
The types of breaches go from incompetency like accidental exposure, employee error, improper disposal or lost to intentional theft like hacking, insider theft, unauthorized access, and even physical data theft.
In the dark web the data is offered to other criminals or even legal entities like the betting companies in the example above, as well as social media organizations who use this data among others to check if their own passwords were indirectly exposed.
What Are The Alternatives?
The list of things that could be done to reduce privacy risk is long. When data is in motion, for example during business process operations, data controllers will continue to use cryptography and tokenization as preferred methods to protect data in operative applications. For data at rest used for data analytics, development & testing, machine learning and open innovation there are new innovative ways to truly anonymize data and fix the privacy vs. utility trade-off once for all.
AI-generated synthetic data is THE way forward to preserve the utility of data while protecting the privacy of every data subject. This innovative approach was only possible thanks to the progress in the field of artificial intelligence. Generative deep neural networks can be trained on the original structured data to then be used to generate new synthetic data points. These new synthetic datasets preserve all the correlations, structures and time dependencies present in the original data. Customer-related events like financial transactions, online-clicks, movements etc. can be synthesized and all the important insights contained in the original data can be preserved in the synthetic dataset. And at the same time there’s no way to re-identify the original customer.
With synthetic data, the way to do machine learning with anonymous “full privacy-full utility” data is wide open. The evaluation results obtained by doing machine learning on synthetic data are very similar to those generated from the original data. Application testing with synthetic data is able to cover the edge cases which are normally covered only in the original data. And the performance tests of the applications are not a problem anymore because synthetic test data, in contrast to original data, isn’t scarce anymore. Millions of synthetic records can be produced with the click of a button.
With AI-generated synthetic data being used more and more, data security and legal departments will finally be able to sleep easier. At the same time, the data scientists and development & testing teams will be able to focus on more productive tasks and won’t get distracted by legal and security requirements. Trust is good, control is better, but no dependency on trust is the best.
And what about data adversaries? What would happen if they manage to steal 28 million synthetic records of UK children like in the story above?
Nothing.
These data adversaries would be sitting on terabytes of artificially generated data: nothing more than a high-quality-look-a-like dataset. They’d be painfully disappointed to discover that re-identifying any of the 28 million UK kids would not be possible. And you can bet on that.


