
Here at MOSTLY AI, we are big fans of open-source software. We are leveraging more than 90 open-source software packages for our synthetic data generator. It is safe to say that without open-source software libraries, it would have been impossible to get where we are today so quickly. We sometimes get asked by prospects why they should choose MOSTLY AI’s Synthetic Data Platform over freely available open-source solutions, like MIT’s Synthetic Data Vault, to synthesize data. This blog post provides an answer.
Update: SDV changed their license model in 2023, and is NOT open-source anymore.
SDV vs MOSTLY AI: Synthetic data quality
The answer is multifaceted, but the main point is the quality of the synthetic data you can generate. We pride ourselves on delivering synthetic data that is so close to the real data that it can be used as a drop-in replacement without sacrificing any meaningful quality. And, of course, all while guaranteeing full privacy.
Already two years ago, we looked at the quality of synthetic data generated with two popular open-source models: CTGAN and TVAE. Back then, we showed how MOSTLY AI’s synthetic data had higher accuracy on multiple dimensions. This time we look more broadly at the open-source software library developed by MIT, the Synthetic Data Vault (SDV). It was initially released in 2018 based on research work led by Kalyan Veeramachaneni. SDV is a Python library that supports three types of data: single table data, relational data, and time series data. In addition, SDV provides an evaluation and benchmarking framework, SDGym, and comes with 100+ datasets that can be used to explore the functionality.
For this benchmarking exercise, we picked five of the 19 provided single table datasets to get a good variety of data in terms of size and structure:
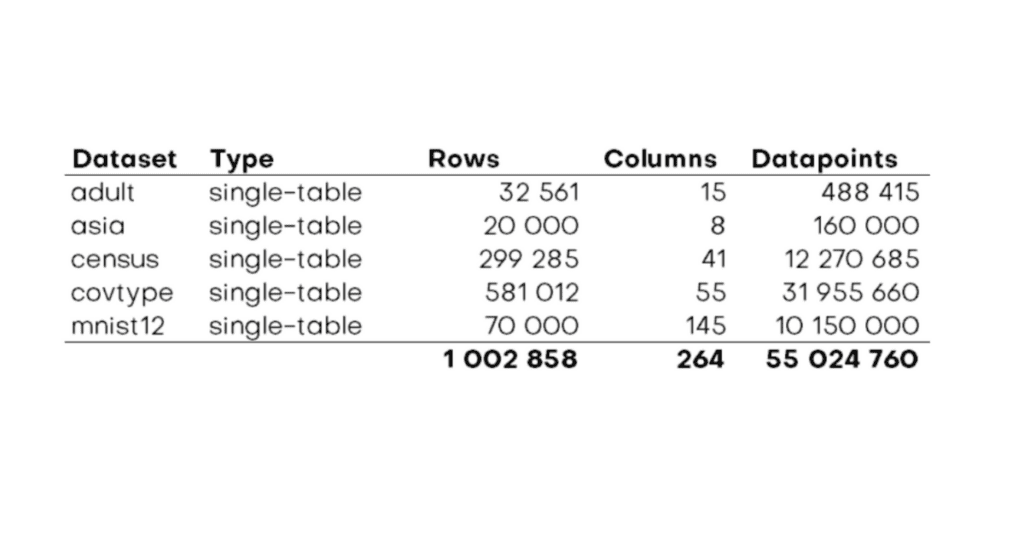
Currently, SDV offers five different models for synthesizing single table data: Tabular Preset (FAST_ML), GaussianCopula, CTGAN, CopulaGAN, and TVAE. To get a proper overview of the state of the art of open-source data synthesis, we spun up some virtual machines and synthesized all five datasets with all available models. And of course, we used the latest release of the MOSTLY AI Synthetic Data Platform to synthesize these datasets to compare. For the record – we used the standard configurations of all models and of our platform. We did not specifically try to tune any dataset. In total, we created more than 5 million rows of synthetic data or 300 million synthetic data points.
The big picture of quality includes the functionality of the synthetic data
Since we wanted to check out SDV more broadly, we also had a look at the functionality to evaluate the quality of generated synthetic data. SDV’s Evaluation Framework takes a real and a synthetic dataset as input and then calculates up to 29 different metrics comparing these two. It returns the average of the scores of the individual metrics, which results in an overall score from 0 to 1, with 0 being the worst and 1 being the best (= the synthetic data is really close to the real data).
For our benchmark, we picked three metrics that worked without any further configuration (LogisticDetection, CSTest, and KSTest) and had SDV report the aggregate score. CSTest (Chi-Squared test) and KSTest (two-sample Kolmogorov–Smirnov test) are statistical metrics that compare the tables by running different statistical tests. LogisticDetection is part of the detection metrics, which evaluate how hard it is to distinguish the synthetic data from the real data by using an ML model (in this case a LogisticRegression classifier).
The results are summarized in the chart below:
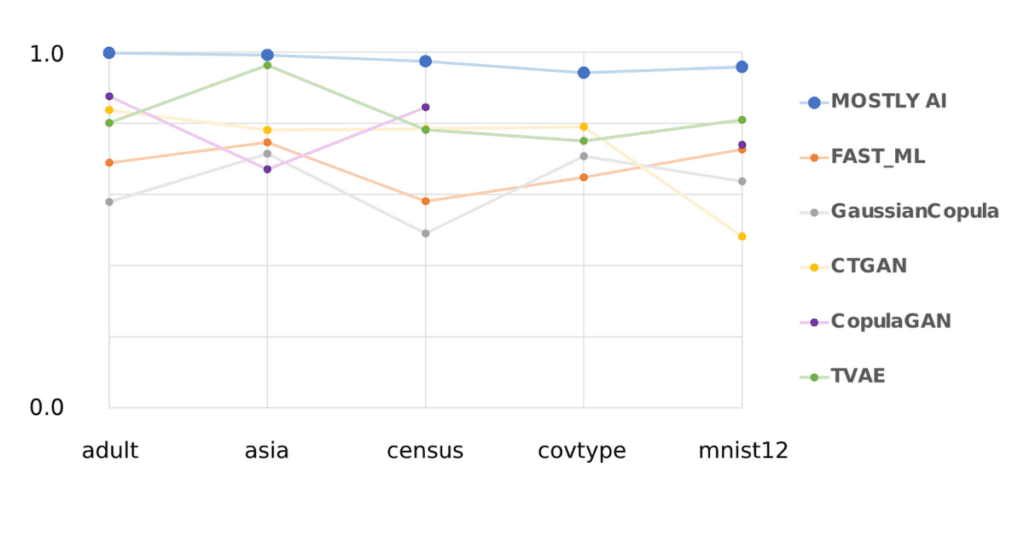
* Please note that no synthetic data for covtype could be created with CopulaGAN due to time-out issues, even on a VM with 224 vCPUs
In short: MOSTLY AI beat every single open-source model for every single dataset. Unsurprisingly the less compute intense FAST_ML, and GaussianCopula models cannot create highly realistic synthetic data with average scores of 0.68 and 0.63, respectively. From the more sophisticated models, TVAE performs best with an average score of 0.82, followed by CopulaGAN (0.78) and CTGAN (0.74). MOSTLY AI’s average score is 0.97.
SDV vs MOSTLY AI: Beyond the hard metrics & further evaluations on synthetic data generation
In practice, you will want to evaluate synthetic data on more dimensions than statistical and detection metrics. High-level metrics give you a first assessment of the quality of the created synthetic data, but the real deal is when synthetic data is actually evaluated by performing the exact same downstream tasks you would have performed using the real data.
Again and again, these analyses confirm what we already know: MOSTLY AI’s Synthetic Data Platform delivers the most accurate synthetic data consistently. But don’t take my word for it: you can find all the created synthetic datasets as a download here to perform whatever kind of analysis you wish.
The heart of our synthetic data platform is where we do not rely on open source but instead have developed our own proprietary IP. The approach and the deep learning architecture used to train a generative model. We have done so because this is what really matters when it comes to achievable synthetic data quality.
There are other reasons to consider when choosing a synthetic data generator. In addition to unmatched synthetic data quality, some of the reasons for choosing MOSTLY AI’s Synthetic Data Platform include:
- Ease of use: Our platform is so simple to use, practically anyone can synthesize data. You do not have to write a single line of code. You do not have to worry about choosing the generative model or about hyperparameter tuning. Just provide the data you want to synthesize, and the platform takes care of the rest – making sure to deliver the highest quality synthetic data.
- Speed: Training sophisticated generative models is compute-intense, and takes time and money. We waited several hours for some CTAN and TVAE models to train on strong VMs. With our platform on a lightweight VM, the synthesizations never took longer than an hour. In production, this can lead to significant cost savings.
- Flexible data ingestion: Instead of being limited to ingesting CSV files, you can connect directly to various data sources, including cloud buckets (e.g., AWS S3) or relational databases like Oracle, MySQL, and PostgreSQL. This saves time and pre- and post-processing steps that are otherwise necessary.
- Privacy guarantees: Synthetic data is not, per default, fully anonymous. For example, you need to make sure to handle outliers and extreme values properly. MOSTLY AI’s synthetic data generator takes care of all that automatically.
- Dedicated support: We have been working in this space for more than five years and know synthetic data inside out. If you encounter any issues, we are there to provide support – for our enterprise clients with guaranteed SLAs.
SDV vs MOSTLY AI: In conclusion
In conclusion, at MOSTLY AI, we are enthusiastic supporters of open-source software and recognize its significant contribution to our synthetic data generator. Our rapid progress and success can be attributed to leveraging over 90 open-source software packages. However, when prospects inquire about why they should choose our Synthetic Data Platform over freely available open-source solutions like Synthetic Data Vault (SDV), we have compelling reasons to offer.
The key factor that sets us apart is the exceptional quality of the synthetic data we generate. We take great pride in delivering synthetic data that closely resembles real data, allowing for seamless integration without compromising privacy or sacrificing quality. In a previous analysis, we compared the accuracy of synthetic data generated using two popular open-source models, CTGAN and TVAE, and demonstrated that MOSTLY AI's synthetic data exhibited superior accuracy across multiple dimensions. This time, we conducted a broader evaluation by examining SDV, an open-source software library developed by MIT.
To assess the quality of the generated synthetic data, we utilized SDV's evaluation framework, which employs various metrics to compare real and synthetic datasets. The results were consistently in our favor, highlighting the superiority of MOSTLY AI's Synthetic Data Platform.
Beyond statistical and detection metrics, we firmly believe in evaluating synthetic data through practical applications. Repeated analyses have validated that our platform consistently delivers the most accurate synthetic data. However, we don't expect you to take our word for it. We invite you to explore and analyze the synthetic datasets we have created, which are available for download.
While open-source software plays a crucial role in our work, we have developed our proprietary intellectual property to ensure the highest possible synthetic data quality. The heart of our Synthetic Data Platform lies in our unique approach and deep learning architecture for training generative models.
In addition to exceptional data quality, there are other reasons to consider our Synthetic Data Platform. We prioritize user experience, offering a straightforward and code-free platform that eliminates the need for choosing generative models or fine-tuning hyperparameters. Moreover, our platform ensures speed and efficiency, leading to significant cost savings compared to training sophisticated generative models using open-source solutions. We also provide flexible data ingestion capabilities, enabling direct connections to various data sources, saving time and effort on pre- and post-processing steps.
Privacy is of utmost importance, and our synthetic data generator automatically handles outliers and extreme values, ensuring privacy. Lastly, we offer dedicated support, leveraging our extensive experience in the synthetic data domain to provide assistance to our enterprise clients with guaranteed service level agreements (SLAs).
If you would like to experience the power of the MOSTLY AI Synthetic Data Platform, we encourage you to sign up and generate synthetic data for free. We are confident that our platform's capabilities and the quality of synthetic data it produces will exceed your expectations.
Experience the power of the MOSTLY AI Synthetic Data Platform for yourself and sign up to generate synthetic data for free.


