Synthetic diamonds are near indistinguishable from actual diamonds to the human eye, they have the same structure, and they bear they same valuable characteristics, like hardness, purity and thermal conductivity. Yet, they take 3 billion years less to form, come at a fraction of cost and are considered more ethical in terms of sourcing.
Along the same lines, synthetic data can as well be near indistinguishable from actual data, can have the same structure, and can retain all the same valuable properties (=statistical information) of actual data. Yet, machines can generate synthetic data in unlimited quantities, and more importantly, synthetic data allows big data to be utilized and shared without putting anyone’s privacy at risk. Synthetic data has the potential to become the new risk-free & ethical norm to leverage customer data at scale. Finally, there is a solution for big data privacy!
However, just like with diamonds, the process of generating high quality synthetic data is anything but trivial. At MOSTLY AI we’ve mastered the automated generation of synthetic structured data over the past 2 years by leveraging state-of-the-art generative AI, and are confident to claim that we offer the world’s most advanced synthetic data engine. As a simple demonstration, as part of this first post, let’s apply our solution to a publicly available diamonds dataset with 53’940 records, and 10 attributes. As can be seen, the attributes are a mix of categorical as well as numerical variables.
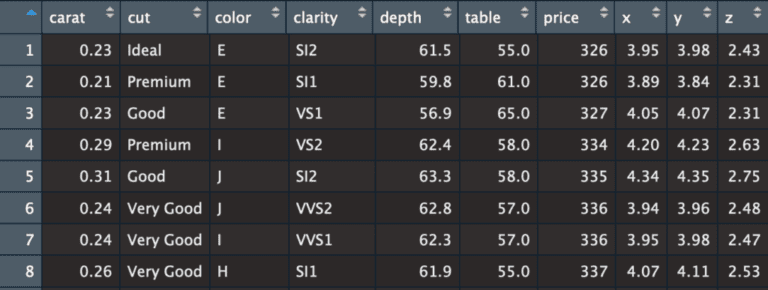
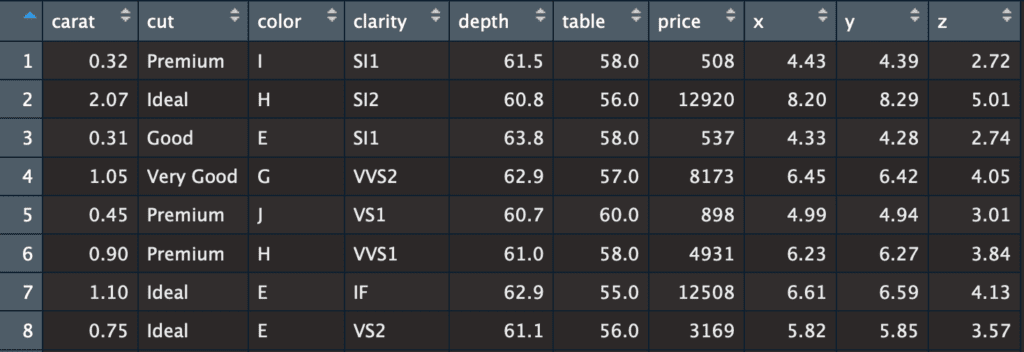
Generating an equally sized, structural identical, yet synthetic version of this dataset is, thanks to the flexibility of our engine, as simple as:
> mostly train diamonds.csv
> mostly generate -n 53940
This will create a new data file with 53’940 records, where none of the generated records have any direct relationship anymore to the records in the original dataset. Hence, the information and thus privacy of any individual diamond is being protected (in case they care :)), while the structure of the population is retained.
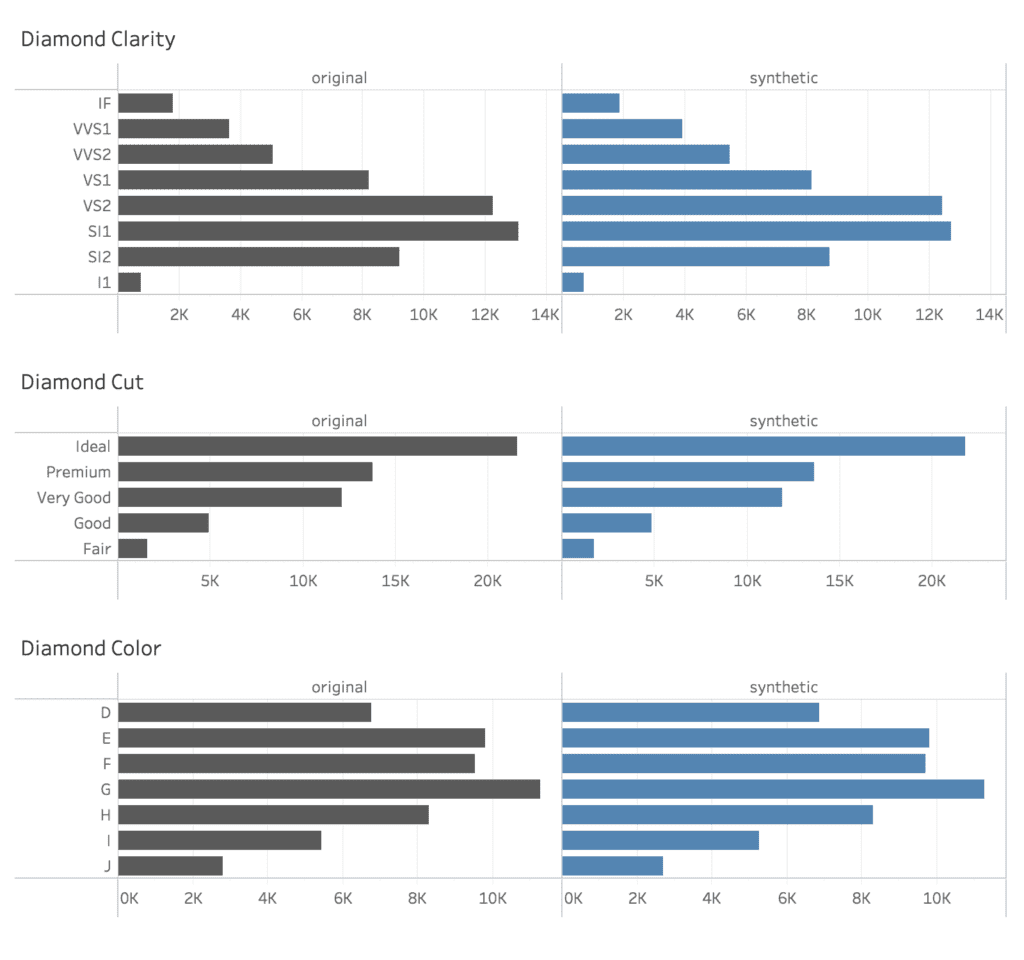
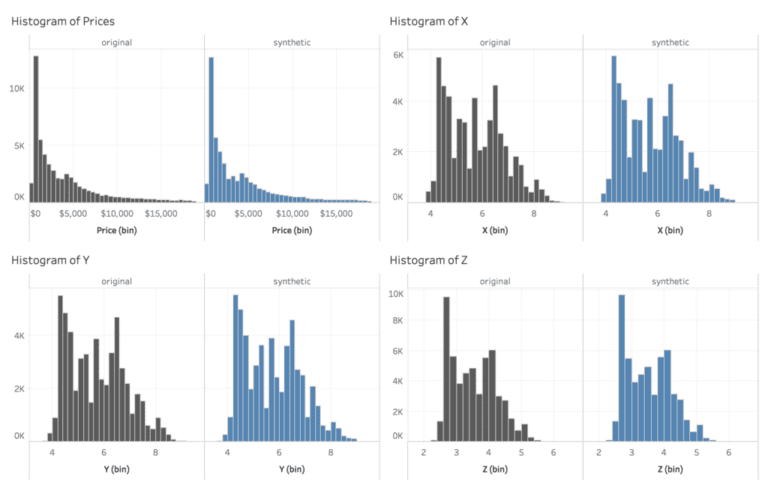
Further the statistical properties of the various attributes are successfully retained. Here are side-by-side comparison of the frequency of the three categorical variables clarity, cut and color. All these univariate distributions are matched to near perfection.
Similarly, the engine is also able to retain the distributions of the numerical variables, and nicely captures location, skew, the tails as well as the multiple modes.

More importantly, the (non-linear) interdependencies between the various variables is being properly captured. These statistical multivariate relationships are the key value of any dataset, as they help to gain a deeper understanding of the underlying domain.
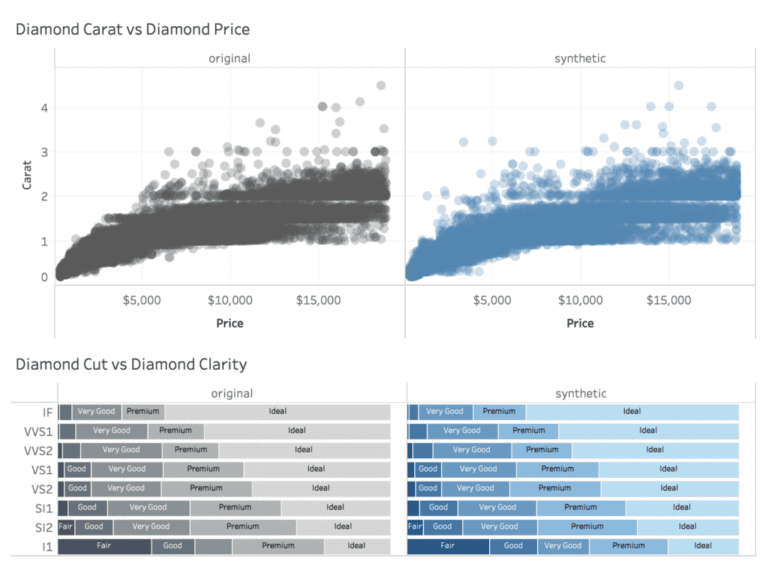
As can be seen, the patterns of the synthetic dataset mimic the patterns found in the original dataset to a very high degree. By analyzing the synthetic data we can gain various insights in terms of the diamond market. Whether that’s the relationship between market prices and carats, or the dominance of “Ideal” cut for diamonds with clarity “IF”. Even unexpected patterns, like the lack of “just-little-less-than-2-carat” diamonds is perfectly captured as well, if you take a close look at the upper chart.
Apart from descriptive statistics the synthetic data also turns out to be of immense value for training machine learning algorithms and predictive tasks. This opens up a whole range of opportunities to power next-generation AI, as more data can be gathered across different sources, across borders and industries, without infringing individual’s privacy.
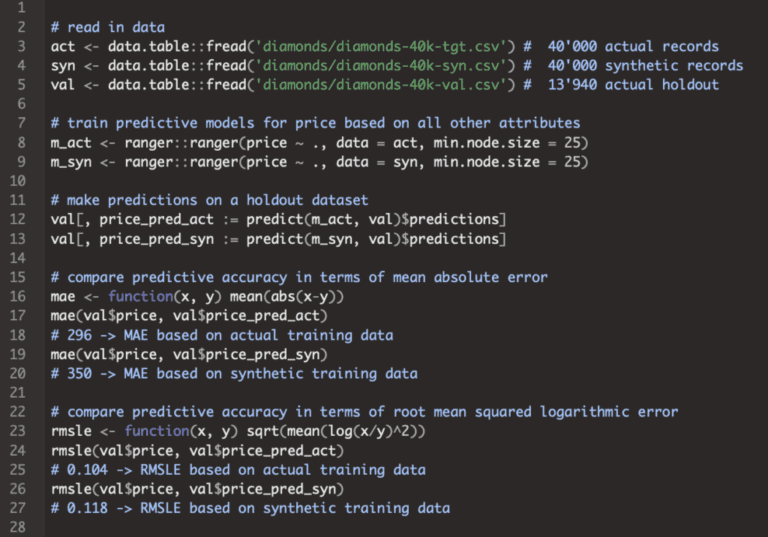
Let’s now take a subset of 40k actual records, and generate 40k synthetic records based on that. We will need the remaining 13’940 actual records to have a fair holdout set available to benchmark our two models for diamond prices: one model trained on actual data, and another one on synthetic data. As expected, there is a loss in accuracy, as the data synthesis results in an information loss (to protect privacy), but the loss is within a rather small margin. In terms of mean absolute error we acchieve an error of 350$ vs 296$. Still, the 350$ is a far cry from a naive model, that would in this case result in an error of $3036 when having no data available at all.
In an upcoming post we will dive deeper into an example of synthetic sequential data, which actually turns out to be the prevalent form when it comes to privacy-sensitive user data. But this is a story for another day. For now, let’s simply generate us a million more synthetic data diamonds and wallow in these for the time being.
> mostly generate -n 1000000
> mostly wallow 🙂