
Policies are designed for far-reaching, societal-level impact. We expect them to be solidly evidence-based and data-driven. The pandemic highlighted how much we rely on (and that we oftentimes still lack) good quality data that is comprehensive and easy to access across nation, states, research groups and different institutions.
However, the status quo of data anonymization and data sharing, especially in healthcare and policy applications, severely limit the amount of information that can be retained. Finding better ways to collaborate on data without compromising privacy is key for policy makers, researchers and businesses across Europe. As part of this mission, the European Commission’s Joint Research Centre thoroughly looked into the opportunity AI-generated synthetic data presents for privacy-safe data use. They concluded with a very strong endorsement for synthetic data in their final report:
Synthetic data will be the key enabler for AI
- "[Synthetic data] can become the unifying bridge between policy support and computational models, by unlocking the potential of data hidden in silos; thus becoming the key enabler of AI in business and policy applications in Europe."
- "Resulting data not only can be shared freely, but also can help rebalance under-represented classes in research studies via oversampling, making it the perfect input into machine learning and AI models"
It is very cost efficient to use synthetic data for privacy protection
- "Synthetic data change[s] everything from privacy to governance"
- “Synthetic data eliminates the bureaucratic burden associated with gaining access to sensitive data"
- "among the privacy-preservation technique studies analysed, data synthesis gave the best price/effort ratio."
Synthetic data is a mature privacy enhancing technology (PET) that is ready to be deployed
- "Synthetic data have proven great potential and are the go-to methods ready to be deployed in real-life scenarios. Policy applications can now be researched and developed with little risk involved."
- "Commercial solutions still beat the available research and open source solutions by a huge margin at the time of writing."
- "A robust commercial solution for hierarchical data synthesis was offered by the company MOSTLY.AI to test the synthesis quality. The results, available in the accompanying archive both as a PDF report and CSV files with the data correlations, are impressive."
Synthetic data improves fairness, diversity and inclusion
- “...policy makers will have the opportunity to create radically new policy instruments based on more detailed less biased population data.”
- "policy support can embrace diversity by stopping averaging out, and thus marginalisation of under-represented minorities by shifting away from aggregate-level statistics; capture the full diversity within the population, and start coping with its complexity, rather than continue ignoring it."
Synthetic data facilitates open data, data democratization, and data literacy
- "Data democratization – a new type of Open Data would emerge from the shift towards the synthetic data"
- "synthetic data in policy making process will enable involvement of much broader communities [..] same goes for algorithmic governance"
- "Data literacy is today as what was computer literacy in 1990s. Synthetic data have potential to accelerate their learning path towards data-driven decision & policy making by making available data closer to the people’s perspective."
Why is not everyone in the EU using synthetic data (yet)?
With such strong proof for the maturity, quality and cost-efficiency of AI-generated synthetic data, it begs the question why not every European institution or private sector organization rich in sensitive data is using synthetic data yet? Particularly, as the European Commissions’s JRC report pointed out, that synthetic data not only helps with privacy protection, but also with accelerating AI adoption, democratizing data access, improving AI fairness and facilitating much-needed data literacy across Europe.
Looking at the EU Commission’s strategy for AI and their Digital Decade, this indeed seems to be an interesting question. According to their AI strategy, it’s the EU’s ambition to “become a global leader in developing cutting-edge, trustworthy AI” and to “ensur[e] that AI is human-centric”. But to ensure widespread adoption of AI amongst European institutions and businesses, it’s self-evident that broad access to high-quality, yet privacy-safe data is a necessity. The same holds true for two of the four main goals that the EU Commission set for itself as part of their Digital Decade. One is the digital transformation of businesses, the other a “digitally skilled population and highly skilled digital professionals”. But: a business that cannot quickly access and innovate with its data (while ensuring compliance with European data protection law) cannot digitally transform. And a European workforce, that cannot openly access granular data simply cannot become data literate, let alone highly digitally skilled.
Thus we at MOSTLY AI strongly support the call to action of the European Commission’s JRC on what shall be done next. "More important than focusing on how to synthesize data is:
- what can we achieve with the new data available at scale,
- how to convince data owners to unleash their coveted data to the broadest audience,
- and how to accommodate this massive new ability into the policy formulation and assessment." [formatting and bulletpoints by the author]
With synthetic data, the technology is already there. It’s mature, cost-efficient, accurate and ready to be deployed. What is left to do by policy makers, if they really want the EU to excel on its path towards digital transformation and widespread development and adoption of human-centric, trustworthy AI, is to open up the access to data - and AI-generated synthetic data will be the single-most valuable tool to help the regulators to do that.
What if the EU would use open synthetic data to fight cancer?
Synthetic images are already playing a crucial role in the training of computer vision models designed to detect tumors and cancer cells. Just like synthetic tabular data, synthetic images can improve the accuracy of AI-powered decision support tools dramatically. For example, Michigan Medicine's neurosurgery team increased the accuracy of their AI models from 68% to 96% with synthetic training data. How? Simply put, the more images the model can look at, the better it gets at detecting pathologies. Synthetic data generation allowed them to upsample the number of images available for model training.
What has been done using synthetic images can be extrapolated to other data types, such as structured tabular data. Rebalancing imbalanced datasets or using synthetic data to augment datasets can help improve model accuracy not just for cancer detection but also for other rare diseases or events, such as lockdowns, unusual energy consumption patterns or recessions.
Data sharing is also key here. Medical research is often plagued with the difficulty of sharing or obtaining large enough datasets where the correlations weren’t destroyed by old data anonymization techniques, like aggregation or data masking. Researchers in different countries should be able to work on the same data in order to arrive at the same conclusions, without endangering the privacy of patients.
To date, there is no open synthetic cancer dataset available in the EU that can be freely accessed by researchers and policymakers. But what if? What if the valuable raw data that was already collected about millions of European cancer patients would be synthesized and - for the very first time - made available to a broad group of researchers? Just imagine the advances in healthcare our society could achieve. With MOSTLY AI's synthetic data platform this can become a reality.
The EU Commission’s JRC used MOSTLY AI's synthetic data generator for synthetic cancer data - with impressive results
For their study on synthetic data, the Joint Research Center leveraged MOSTLY AI's synthetic data platform to train on half a million of real-world cancer records. They then generated 2 million highly accurate, yet truly anonymous synthetic cancer patient records. Chapter 6 of the report includes the details of their analysis. But to summarize in their own words, “the results [...] are impressive.”
“The resulting dataset has shown astonishing level of realism (are we looking at the original or the synthetic data?) while maintaining all the privacy test. Resulting data not only can be shared freely, but also can help rebalance under- represented classes in research studies via oversampling, making it the perfect input into machine learning and AI models.”
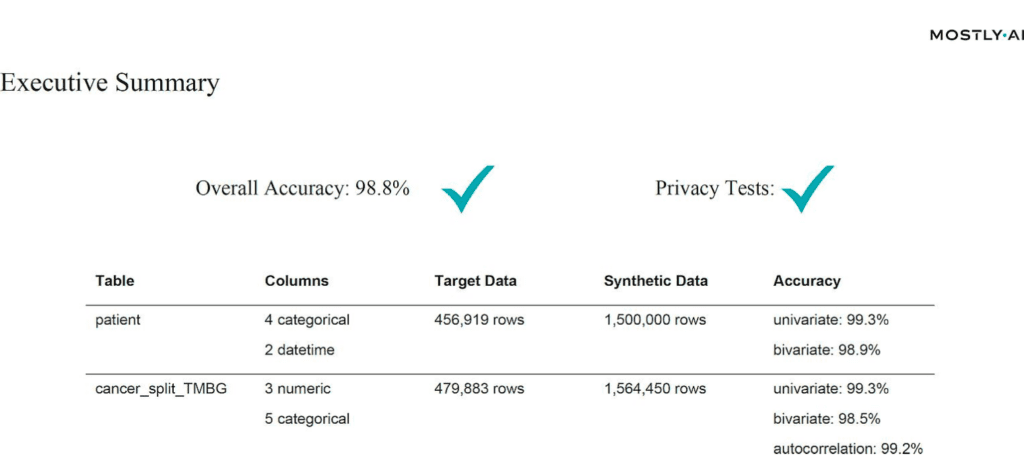
In particular, compared to an open-source alternative, MOSTLY AI could show its strength with its high level of automation. While the open-source solution required several person-months in an attempt to clean up the sample data, MOSTLY AI’s solution delivered out-of-the-box with top-in-class accuracy and rule adherence:
“Commercial solutions still beat the available research and open source solutions by a huge margin at the time of writing”
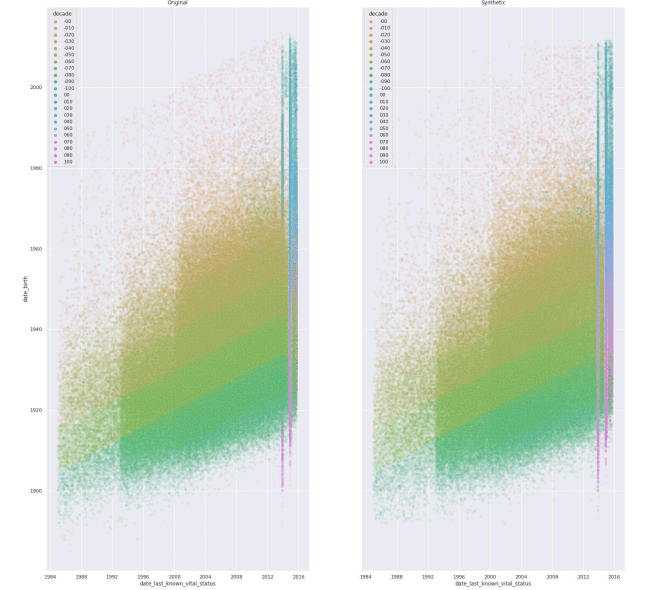
We are very proud to have created a synthetic data generator that stands up under such close scrutiny and are convinced that in the coming years synthetic data will be an even more valuable tool for policymakers - in the EU and beyond.


