
AI algorithms require large volumes of up-to-date, high-quality training data to learn from. In many cases, the training data needs to be annotated by humans in order to help the machines make sense of it. However, in just as many cases, that very same training data should not or must not be provided to humans due to its privacy-sensitive nature.
This is particularly true when it comes to teaching machines to understand voice commands. For example, Amazon is reportedly employing thousands of workers across the world that continuously listen to Alexa conversations and transcribe and annotate their content. The fact that this made major headlines shows the increased sensitivity among the public towards this mass-scale sharing of personal data. Such practice, therefore, poses a severe regulatory and reputational risk for organizations.
But what options do exist for safely providing privacy-sensitive data for text annotation purposes? Encryption and monitoring certainly can’t prevent abuse, as in the end, it requires the annotators to access decrypted data again. Also, legacy data masking is known to have become largely ineffective to protect data due to the increased ease of re-identification. Thus, this calls for a truly privacy-preserving way to share granular-level, representative data at scale. This calls for synthetic text.
The need for data for AI training
Let’s assume you are a leading organization that wants to provide voice interactions within your products or services. This will allow you to smartly react and adapt to your users and their voiced needs. The user experience of such functionality will depend on the algorithm’s ability to correctly detect users’ intent, which itself will rely on the availability of up-to-date, large-scale annotated training data. While it might be straightforward to get started on the AI journey with made-up data, the best data source is the actual commands voiced by the end users. However, these cannot be shared for annotation, at least not without explicit customers’ consent. Thus, the continuous maintenance of ground truth data for your algorithms becomes costly, dragging, and hard to scale across countries, languages, and dialects. The results will be felt by your customers, who remain misunderstood by your service and will start looking for smarter alternatives.
AI-generated synthetic data allows you to obtain an up-to-date statistical representation of your gathered customer interactions, which is not restricted and can be freely shared with annotators. This enables scaling the annotation process, both in data volume as well as data diversity, by collaborating with any 3rd party. The flexibility and agility of synthetic data will give you an edge in high-quality training data and ultimately an edge in a race to ever smarter products and services without putting the privacy of your customers at risk.
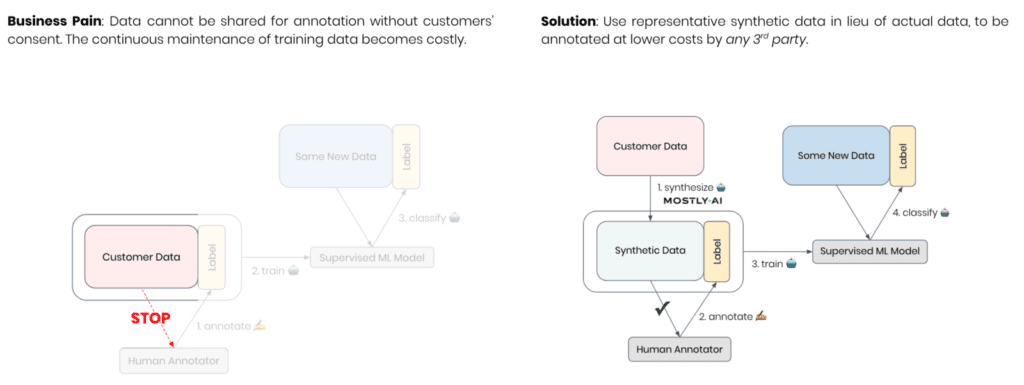
As-good-as-real synthetic text at the press of a button
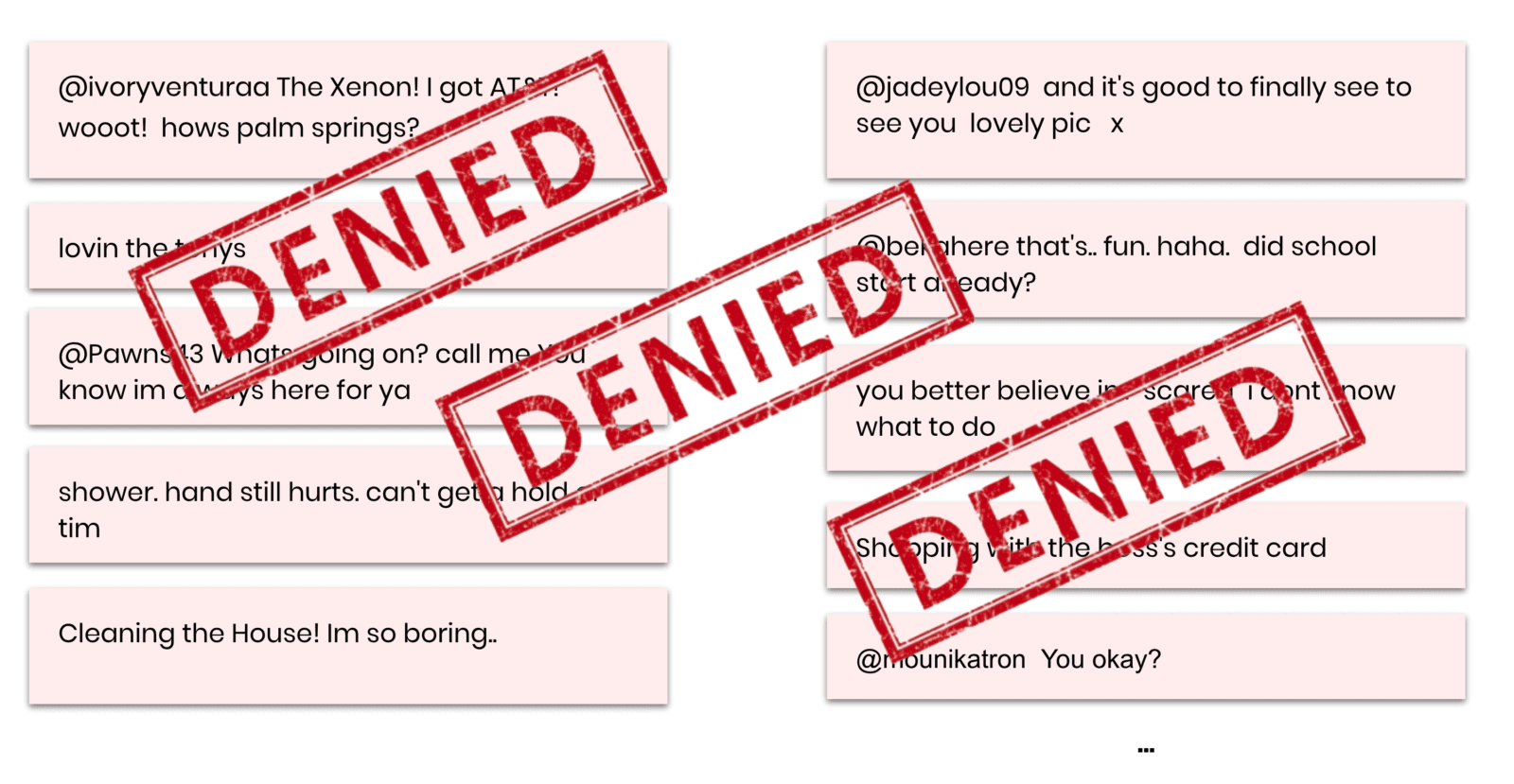
To demonstrate the efficiency of synthetic data for annotation, we will use a dataset of 1.6 million tweets [src] as our restricted customer data and consider the task of sentiment detection as our learning objective. So, let’s start out by taking a look at some of the actual messages that are contained in the dataset. And at the same time, let’s bring to our attention that this is the privacy-sensitive data that you or any of your colleagues are actually NOT supposed to look at.
Let’s then leverage MOSTLY AI’s category-leading synthetic data platform to create a statistical representation of the dataset. This provides you with an unlimited source of new unrestricted synthetic messages. This works for any language, any domain, and any content—with, as well as without, the additional context information on the user or the message itself.
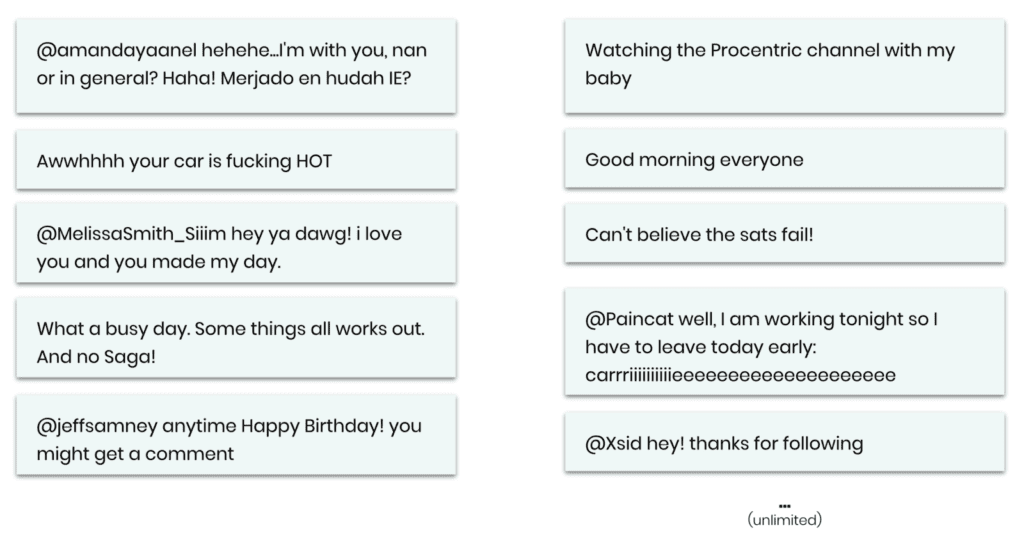
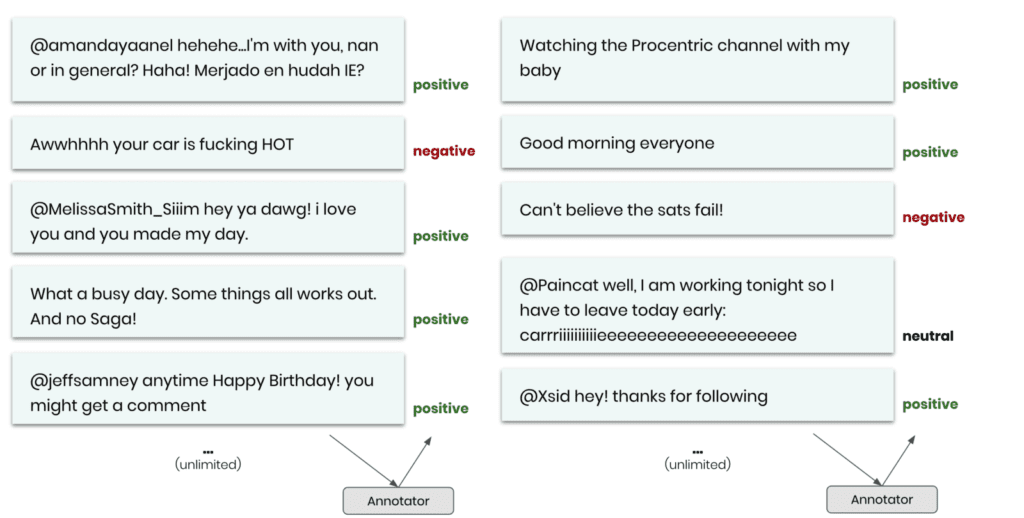
Simply studying, inspecting, and sharing these samples will tremendously help your whole organization to establish a deep understanding of your customers and how they interact with your services. But, further, these samples can now be shared with any number of annotators without risking anyone’s privacy. The key business question is then: Is the annotated synthetic data as good as the annotated original data when serving as training data for a supervised machine learning model?
As we don’t have human annotators readily available for our demonstration, we will make the case by using an existing sentiment classifier to perform the annotation. The task is then to train a downstream machine learning model that can correctly detect the sentiment for new and unseen data samples. We will thus measure our performance in terms of predictive accuracy on an annotated holdout dataset.
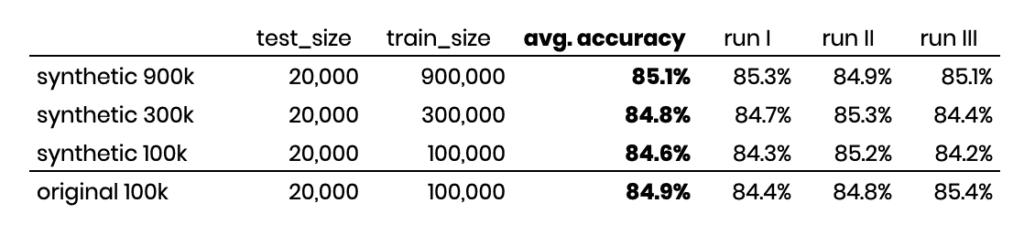
If we then train a capable text model on 100,000 annotated synthetic samples, we find an accuracy rate of 84.6% (measured for 20,000 actual holdout samples across three independent runs). This is nearly on par with the accuracy rate of 84.9% if we were to annotate the original, privacy-sensitive data. Thus, MOSTLY AI’s synthetic data serves as a privacy-safe alternative that doesn’t require giving up on high model accuracy. Even more, the ability to upsample, as well as to outsource annotation at lower costs, allows more training data to be annotated on a continuous basis, which ultimately results in even higher accuracy and thus better user experience.
And an important side aspect is that the developed models can be inspected, validated, and governed with the help of synthetic data by anyone, including a diverse team of AI model validators. According to Gartner, these will play an increasingly important role in managing the AI risk within the enterprise. Synthetic data allows them to do exactly that but without being held back by privacy concerns.

Data privacy and data innovation can coexist
To conclude: Users expect smart services. Users expect to be understood. Yet, users expect that their privacy is not being sacrificed along the way. MOSTLY AI’s world-class synthetic data allows leading enterprises to achieve exactly that and make data protection and data innovation both work at the same time. Talk to us to learn more.


