TL;DR The broad adoption of connected devices equipped with GPS sensors adds geo context to nearly all customer data assets. However, location data—in particular, location traces—are nearly impossible to anonymize with legacy techniques as they allow for easy re-identification. The latest release of MOSTLY GENERATE ships with geo data support, thus allowing any organization to synthesize and truly anonymize their geo enriched data assets at scale.
The rise of geo data
Every phone knows its own location. And every watch, car, bicycle, and connected device will soon know its own location too. This creates a huge trove of geospatial data, enabling smart, context-aware services as well as increasing location intelligence for better planning and decision-making across all industries. Footprint data, a valuable asset of telecommunications companies, is a sought-after data type helping businesses and governments optimize urban services and find the best locations for facilities. This geospatial data can help fight pandemics, allowing governments and health experts to relate regional spread to other sociodemographic attributes. Financial institutions and insurance companies can improve their risk assessment. For example, home insurance prices can be improved through the mapping of climate features. The list of geo data use cases is long already but likely to get longer the more we continue tracking locations.
Yet, all of these devices are used by people. Thus, that data more often than not represents highly sensitive personal data—i.e., private information that is to be protected. It's not the movements of the phones but the movements of the people using the phones that are being tracked. That's where modern-day privacy regulations come into play and impose restrictions for what kind of data may be utilized and how such data may be utilized. In addition, these regulations are accompanied by significant fines to ensure that the rules are being adhered to.
These privacy regulations indisputably state that the sheer masking of direct identifiers (like names or e-mail addresses) does NOT render your data assets anonymous if the remaining attributes still allow for re-identification. For geo data, which yields a characteristic digital fingerprint for each and every one of us, the process of re-identification can be as simple as a mere database lookup. Montjoye et al. have demonstrated in their seminal 2013 Nature article that two coarse spatio-temporal data points are all that it takes to re-identify over half of the population. But more importantly, the authors demonstrate that further coarsening the data provides little to no help if multiple locations are being captured per individual, a finding that exposes a fundamental constraint to legacy data anonymization techniques.
For that reason, many of the public data-sharing initiatives, which started out with the best of intentions to foster data-driven innovation, had to stop their activities related to geo data. See the following note regarding Austin's shared mobility services, which ceased their granular-level data sharing in 2019, when the privacy implications were brought to their attention:
** Note About Location Data and Privacy (Apr 12, 2019) **
After discussion with colleagues and industry experts, we have decided to remove the latitude and longitude data from our public shared micromobility trips dataset in order to protect user privacy. [...] There is no consensus from the community on how best to share this kind of location data [...]
So, Austin, and other smart cities alike, look no further—we've developed the right solution for you.
Geo support within MOSTLY AI 1.5
At MOSTLY AI, we've been dedicated to solving the long-standing challenge of anonymization with AI-based synthetic data ever since our foundation. And, geo data, despite or because of its high demands, has been a focal part of our research activities. In particular, as we increasingly encountered this data type residing within nearly any enterprise data landscape across a broad range of industries.
Thus, fast forward to 2021, we are filled with joy and pride to finally announce that our industry-leading synthetic data platform, now ships with direct geo data support. So, aside from categorical, numeric, temporal, and textual data attributes, users can now also explicitly declare an arbitrary number of attributes to contain geo coordinates. The synthesized dataset will then faithfully represent the original data asset, with statistical relationships between the geo and non-geo attributes all being retained.
Internally, our patent-pending technique provides an efficient representation of geo information that adaptively scales its granularity to the provided dataset. This allows the generated synthetic data to represent regional just as well as local characteristics, all happening in a fully automated fashion.
Case study for synthetic geo positions
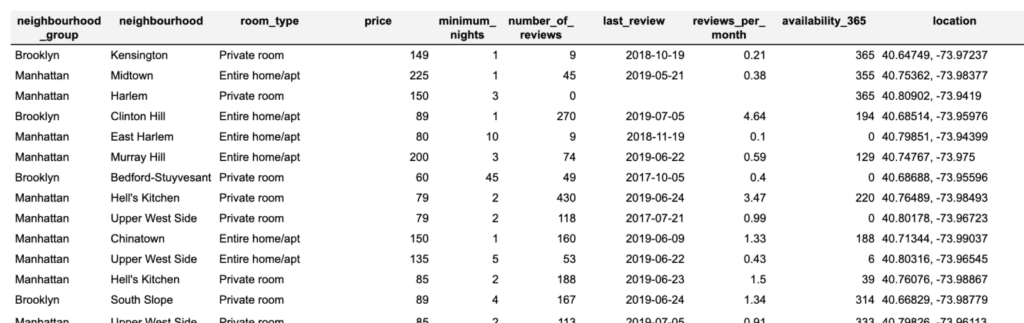
For the purpose of demonstration, let's start out with a basic example on top of 2019 Airbnb listings for New York City. That dataset consists of close to 50,000 records, with 10 measures each, whereas one of them represents the listing location encoded as latitude/longitude coordinates. While this dataset is rather small in terms of its shape and size when compared to typical customer datasets, it still shall provide us a good first understanding of the newly added geo support.
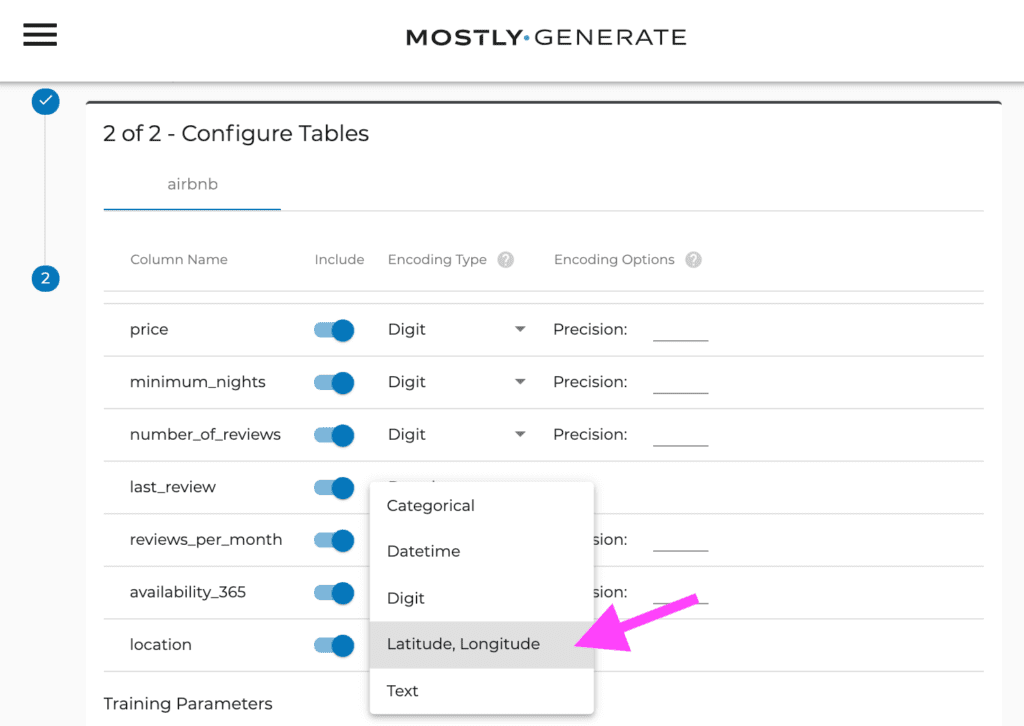
Synthesizing a geo-enriched dataset is as simple as synthesizing any other dataset thanks to MOSTLY AI's easy-to-use user interface. One simply needs to provide the dataset (in this case, we uploaded the dataset as a CSV file) to then inform the system about the geo-encoded attribute. All that is left to do is trigger the synthesis process, which then executes the encoding, the training, and the generation stages. Once the job is completed, users of the platform can then download the synthesized dataset, as well as a corresponding quality assurance report.
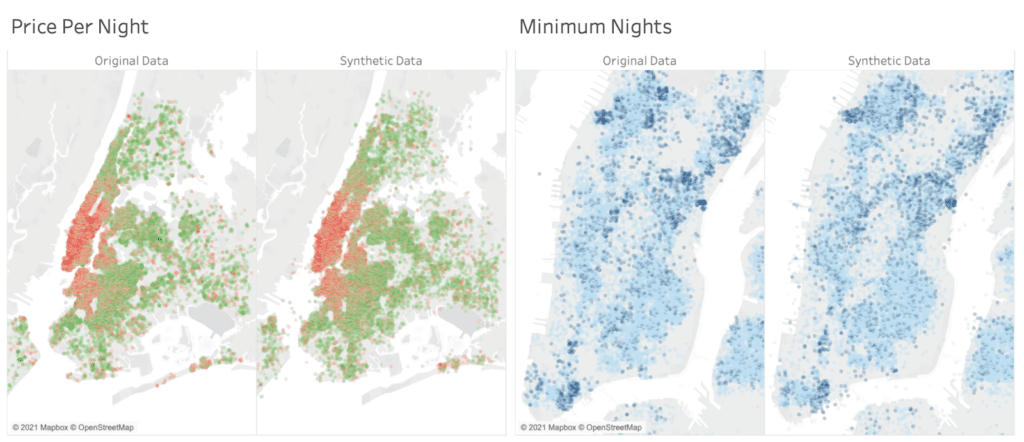
A quick check shows that the basic statistics are well retained. For example, the average price per night is ~$212 for an entire home, compared to ~$70 for a shared room. The average minimum stay is ~8.5 nights in Manhattan vs. 5 nights in Queens. All these are perfectly reflected within the synthetic data. With the focus of this article being on the geo properties, we continue our analysis leveraging Tableau, a popular data visualization solution. Like any other analytical tool, it can process synthetic data in exactly the same way as the original data. However, any analysis on the synthetic data will be private by design, even though it operates on granular-level data.
Figure 4 provides a side-by-side comparison of the overall geo distribution of listings, where these are color-coded either corresponding to their listing price (red values represent high prices) or corresponding to their required minimum stay (dark blue represent longer stays). As can be seen, the distinct relationship between location and price is just as well retained as the relationship between location and minimum nights of stay. One can publicly share the synthetic geo data to allow for similar insights as with the original data, but without running the risk of exposing an individual's privacy.
Case study for synthetic geo traces
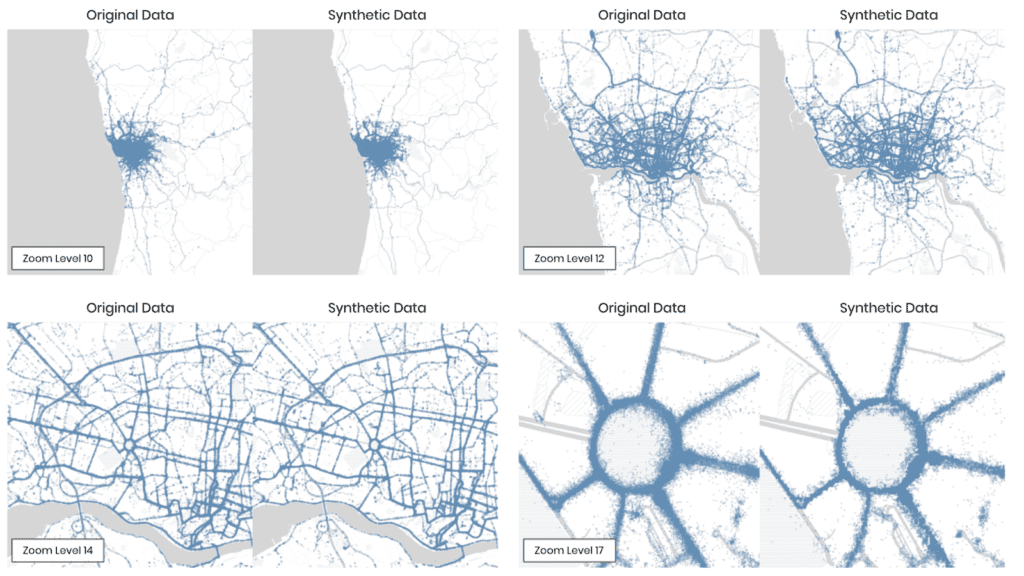
As a second demonstration, we will turn to the Porto Taxi dataset. It consists of over a million taxi trips, together with their detailed geo location captured at 15-second intervals. Thus, depending on the overall duration of the trip, we see a varying sequence length of recorded geo locations. The total amount of available data provides plenty of opportunities for the generative model to learn and retain detailed level characteristics of the dataset, while the general ease of use remains unchanged.
Figure 5 already visualizes the results side by side; i.e., both the recorded original and the generated synthetic taxi locations, showcasing the great out-of-the-box detail and adaptive resolution of MOSTLY AI's synthetic data platform. As one can see, even though each and every taxi trip has been generated from scratch, the emerging traffic patterns are identical at the city, district, and even block levels (see the roundabout zoomed in to focus on the bottom right corner of Figure 5).
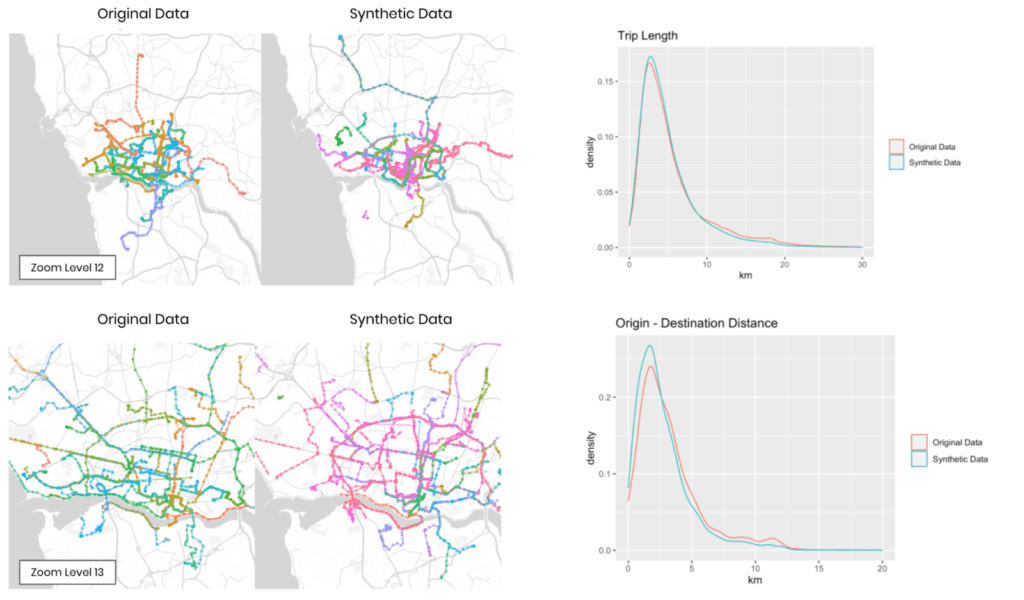
Further, Figure 6 shows randomly selected taxi trips as well as trip level statistics. All of these plots clearly show that not only the location but also the consistency of trips is faithfully represented. Synthetic trip trajectories remain coherent and do not erratically jump from one location to another. This thus yields a near-perfect representation of overall trip length, as well as of the distance between the trip origin and its destination. Note that the quality of the synthetic trips can be easily further improved, as we've only trained on ~10% of the original data and restrained from any dataset-specific parameter tuning.
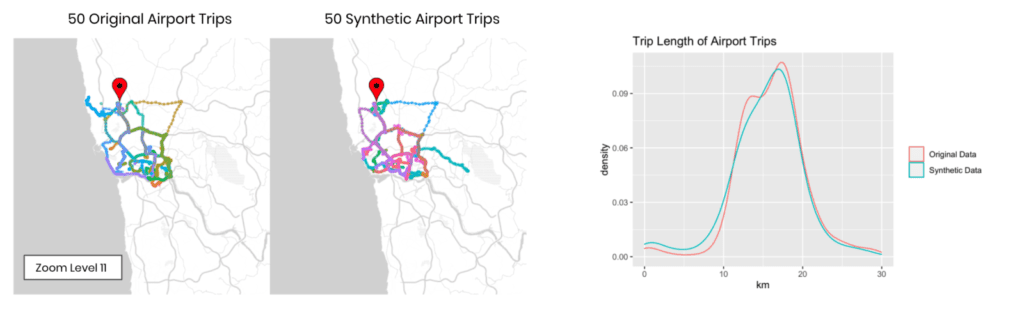
Finally, Figure 7 depicts each 50 randomly selected taxi trips to the International Airport of Porto. Once more, we see both the spatial distribution and the overall increased length of airport trips well reflected within the synthetic trips.
The future of geo data sharing is bright
Precise geolocation information is considered to be one of the hardest things to anonymize. This hampers many customer data assets that contain geographic references to be easily shared and utilized across teams. But with the value of customer trust and the value of customer data being increasingly recognized, we are thrilled to deliver the presented geo support within MOSTLY AI 1.5. It will provide you with truly anonymous yet highly accurate representations of your data assets and will help you on your mission to reduce wasteful operations and build context-aware smarter services. Thanks to AI-powered synthetic data, the future of open sharing of geo data is becoming bright again.
Acknowledgment
This research and development on synthetic mobility data is supported by a grant of the Vienna Business Agency (Wirtschaftsagentur Wien), a fund of the City of Vienna.



