TL;DR AI governance requires access to models just as well as to data. However, in cases where the sensitive training data cannot be shared further, MOSTLY AI’s highly representative synthetic data serves as a drop-in replacement to enable model documentation, model validation, as well as model certification. These are key activities to establish trust in AI, particularly within industries, fundamentally dependent on the same people's trust they seek to serve.
The Importance of Explainability
With machine learning models being increasingly deployed for decision support within critical domains, such as finance, healthcare, or governmental services, the need to inspect, validate, and govern these algorithms rises just as well. This requires us, humans, to be in a position to understand models with respect to the what and the why. A quest that is commonly referred to as Explainable AI. The challenge is that the days of linear models or simple decision trees that are easily described and reasoned about are long counted. Nowadays, they are superseded by far more accurate, yet more complex learning algorithms that rely on large-scale training data to build their own model of the world together with its governing rules and relations. The consequence, however, is that no human being is capable of comprehending the complete decision boundaries of modern-day ML algorithms anymore, where ensemble methods and deep learning result in thousands, if not millions of model parameters. That certainly can’t mean that we shall give up on understanding the workings of an algorithm. The opposite is true. Anyone, independent of their technical background, should be able to “see” what drives a model decision so that we (as an individual, as an organization, as a society) can assess whether these indeed align with our intentions and value system. In fact, this is actually a historic opportunity to make decision processes transparent that otherwise have remained in the dark or were irrational, biased and inconsequent due to human judgment. And with growing regulatory pressure, and rising customer expectations, the wild wild west era of AI will come to an end, and Explainable AI will be a necessity for any organization soon.
Learning by Examples
So, how can these algorithms be made transparent to anyone? Given their complexity, neither disclosing the mathematical model, nor the implementation, nor the full training data will serve the purpose. Rather, it is easiest to learn about a system by observing as well as exploring its behavior. E.g., to gain an understanding of a sophisticated ML algorithm, one shall 1) observe its decisions across a variety of actual cases, and 2) explore its sensitivity with respect to modifications thereof. Particularly these what-if explorations help our understanding regarding what drives the decision of a model. This simple yet powerful concept of systematically exploring changes in model output given variations of input data is also referred to as local interpretability and can be performed domain- and model-agnostic at scale. I.e., the same principle can be applied to help us interpret credit scoring systems, sales demand forecasts, medical diagnostics, fraud detection systems, text classifiers, recommendation systems, and more.

One of the methods that popularized the approach is LIME, which stands for Local interpretable model-agnostic explanations. LIME has been quickly adopted since its introduction in 2016 by practitioners. Further enhanced methods, like SHAP and Anchors, continue to emerge, which all tremendously advance our understanding of how black-box models form their decisions. Yet, all of these approaches not only require access to the model but access to actual samples.
Demonstration
Let’s demonstrate the need for data for interpreting models with a concrete example of US Census income classification, taken from the excellent SHAP python package. In this example, a high-capacity machine learning model is trained on over 32’000 actual records to predict how likely individuals are or are not contained within the high-income class. That decision is based on 12 available attributes (occupation, gender, race, etc.), each contributing to the final model. While ML toolkits have made it increasingly easy to train powerful models that yield excellent predictive accuracy, they typically fall short in explaining how these models come up with their decisions. This is where approaches like SHAP step in that help interpret models.
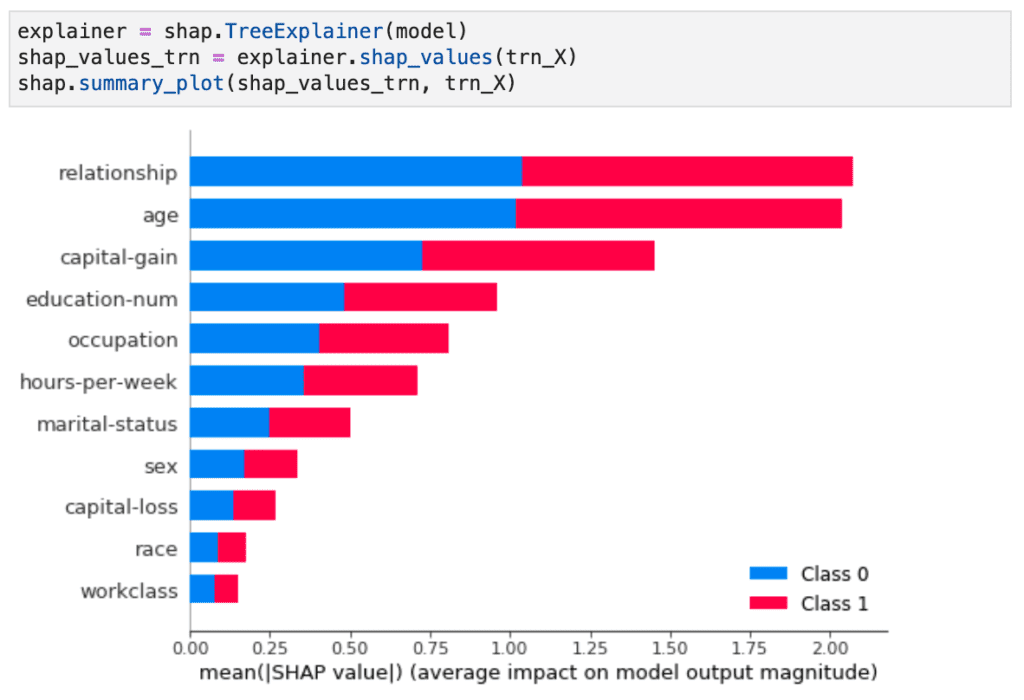
Figure 2 shows the basic workflow of instantiating a SHAP explainer within Python, by providing it with the model as well as the data. Or, to put it differently: no data → no explanations!
In the early days of ML adoption the model developers were also the ones who were tasked to interpret and validate “their” models. In these cases, the original training data is typically re-used for the explainer as well. However, with the significant real-world impact of deployed models on people’s lives, the development and the governance of AI models are increasingly separated to different teams, respectively to different organizations, like a certification body. Yet, this separation requires granular-level data to be shared, which due to the sensitivity of the underlying training data is oftentimes either too risky or outright forbidden. This is a fundamental barrier towards an urgently needed industry-wide adoption and enforcement of AI Governance. MOSTLY AI’s synthetic data to the rescue! As we’ve demonstrated before, it is highly representative and truly anonymous and serves as a drop-in replacement for actual data. As we’ll show in the following, not only to develop and test-drive ML models, but also to allow its behavior to be investigated for an unlimited amount of realistic and representative scenarios.
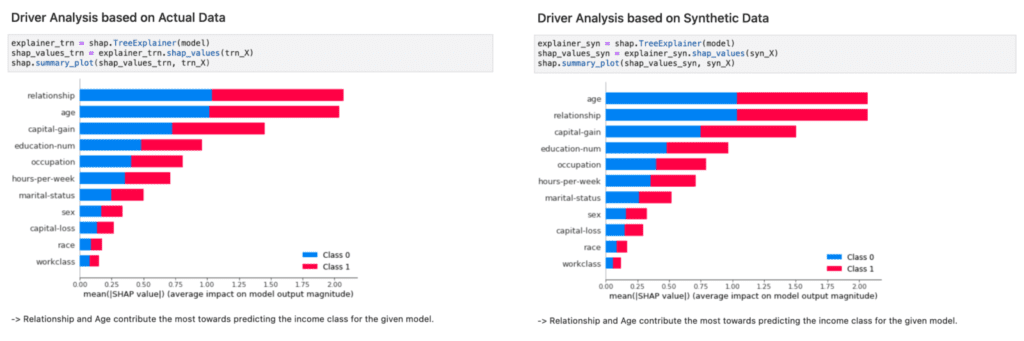
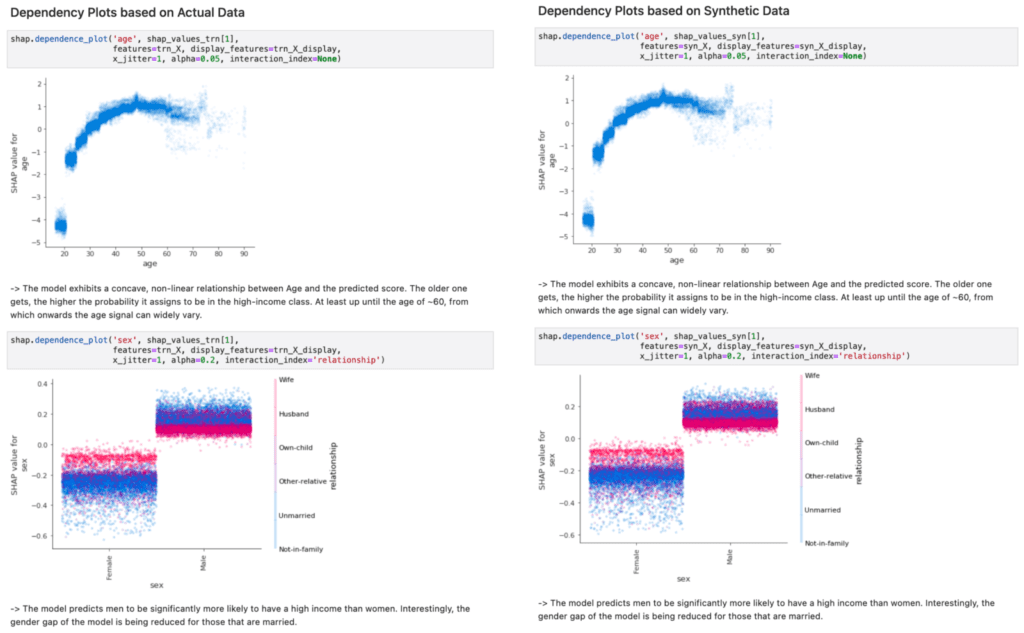
In Figure 3, we provide side-by-side comparisons of a range of model inspections. Once performed on top of the actual data used for model training on the left-hand side, and once performed on top of synthetic data on the right-hand side. As one can see, there is no notable difference between the results. And thus, the inspection, the documentation and the testing of models can be performed on top of MOSTLY AI’s synthetic data, within as well as across organizations, without putting the privacy of any actual customers at risk.
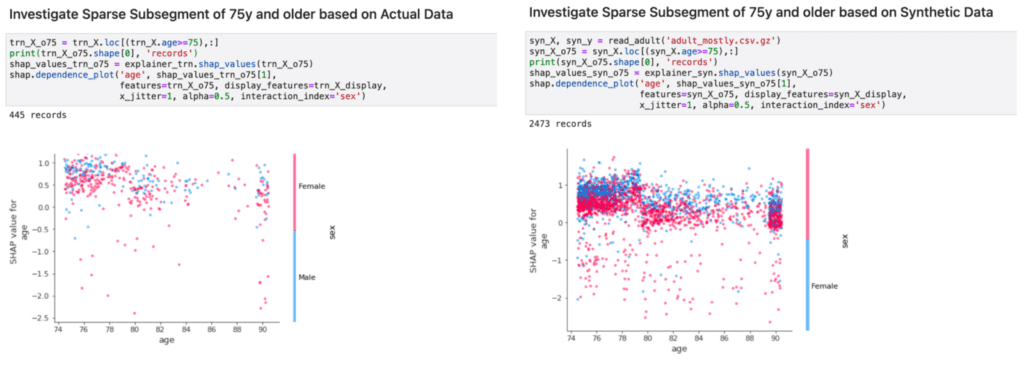
In addition, the ability to upsample, i.e., to generate an arbitrary amount of new representative records, allows to further inspect feature effects of the model on otherwise rare subsegments. This is of particular interest, as these minority groups are at risk of being overlooked due to their small population size. To strengthen that point, we demonstrate how the inspected model relates age and gender to the high-income category within the segment of 75 years and older citizens. Figure 4 shows that an upsampled synthetic dataset, that is 4 times larger than the original dataset, allows us to gather far more details on these otherwise small subsegments.
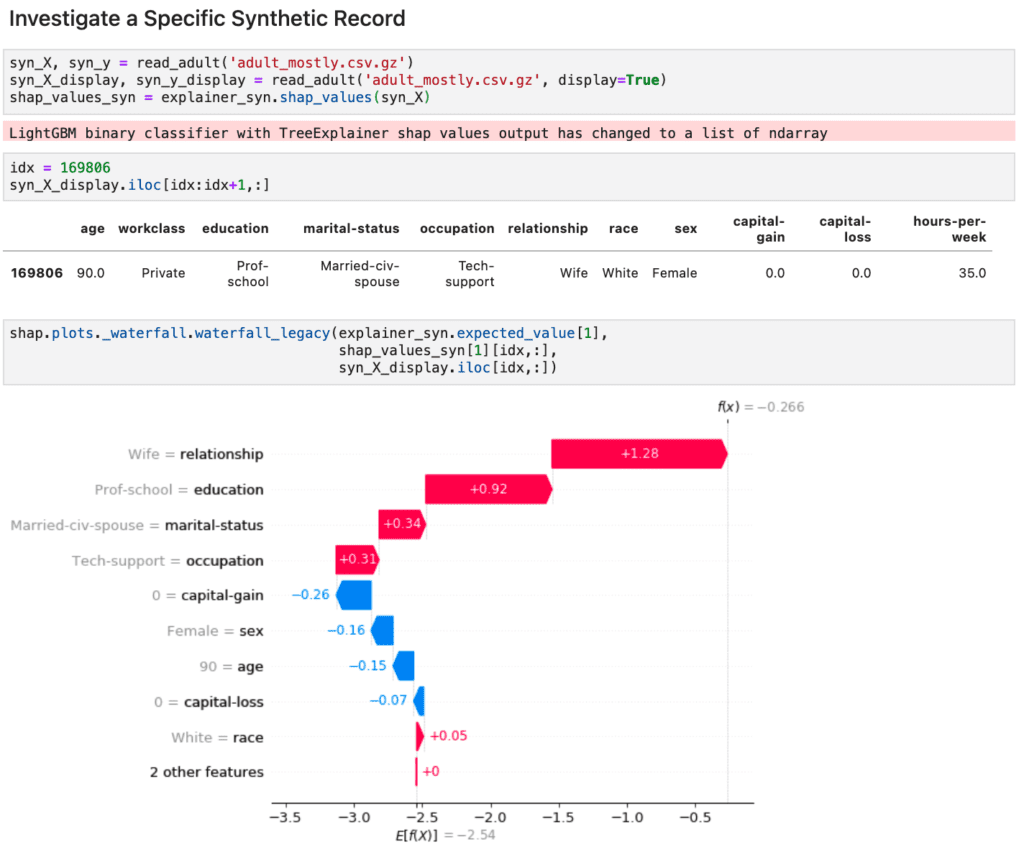
Finally, we can also inspect individual records with attribute combinations that didn’t necessarily exist within the provided original data. E.g., what if a 90 year old woman with the highest education level is still actively working? What type of score will the model provide in such a particular edge case that hasn’t been encountered yet as part of the model training? As shown in Figure 5, MOSTLY AI’s synthetic data also sheds light on these types of rare cases that are crucial to inspect to ensure a fair, responsible and robust AI to be deployed into production.
AI governance needs synthetic data
The need for AI governance is on the rise, yet it requires continuous access to typically highly sensitive data to be performed. We’ve demonstrated how MOSTLY AI’s world-leading and highly representative synthetic data serves as a perfect drop-in replacement for actual data to help interpret sophisticated ML models. This synthetic data enables our customers to participate in a much-needed collaborative cross-organizational AI ecosystem that spans from model developers through model testers to model validators. Going forward, we anticipate synthetic data to play a pivotal role in establishing transparency towards authorities, certification bodies as well as to customers - a major cornerstone of Ethical AI.
Curious to learn more? Please reach out to us to see how your organization can get started today!