
[Update April 2025: We have open-sourced our quality assurance toolkit for synthetic data under a fully permissive license at https://github.com/mostly-ai/mostlyai-qa. Please refer to that repository, respectively to the accompanying paper for an up-to-date approach on measuring fidelity vs. privacy of synthetic data in practice.]
This is the second part of our blog post series on anonymous synthetic data. While Part I introduced the fundamental challenge of true anonymization, this part will detail the technical possibilities of establishing the privacy and thus safety of synthetic data.
The new era of anonymization: AI-generated synthetic copies
MOSTLY AI's synthetic data platform enables anyone to reliably extract global structure, patterns, and correlations from an existing dataset, to then generate completely new synthetic data at scale. These synthetic data points are sampled from scratch from the fitted probability distributions and thus bear no 1:1 relationship to any real, existing data subjects.
This lack of direct relationship to actual people already provides a drastically higher level of safety and renders deterministic re-identification, as discussed in Part I, impossible. However, a privacy assessment of synthetic data must not stop there but also needs to consider the most advanced attack scenarios. For one, to be assured, that customers’ privacy is not being put at any risk. And for two, to establish that a synthetic data solution indeed adheres to modern-day privacy laws. Over the past months, we have had two renowned institutions conduct thorough technical and legal assessments of MOSTLY AI's synthetic data across a broad range of attack scenarios and a broad range of datasets. And once more, it was independently established and attested by renowned experts: synthetic data by MOSTLY AI is not personal data anymore, thus adheres to all modern privacy regulations. ✅ While we go into these assessments’ details in this blog post, we are more than happy to share the full reports with you upon request.
The privacy assessment of synthetic data
Europe has recently introduced the toughest privacy law in the world, and its regulation also provides the strictest requirements for anonymization techniques. In particular, WP Article 29 has defined three criteria that need to be assessed:
- (i) is it still possible to single out an individual,
- (ii) is it still possible to link records relating to an individual, and
- (iii) can information be inferred concerning an individual?
These translate to evaluating synthetic data with respect to:
- the risk of identity disclosure: can anyone link actual individuals to synthetically generated subjects,
- the risk of membership disclosure: can anyone infer whether a subject was or was not contained in a dataset based on the derived synthetic data,
- the risk of attribute disclosure: can anyone infer additional information on a subject’s attribute if that subject was contained in the original data?
Whereas self-reported privacy metrics continue to emerge, it needs to be emphasized that these risks have to be empirically tested in order to assess the correct workings of any synthetic data algorithm as well as implementation.
Attribute disclosure
How is it possible for a third party to empirically assess the privacy of a synthetic data implementation? SBA Research, a renowned research center for information security, has been actively researching the field of attribute disclosure over the past couple of years and recently developed a sophisticated leave-one-out ML-based attribute disclosure test framework, as sketched in Figure 1. In that illustration, T depicts the original target data, that serves as training data for generating multiple synthetic datasets ST. T’ is then a so-called neighboring dataset of T that only differs with respect to T by excluding a single individual. Any additional information obtained from the synthetic datasets ST (based on T) as opposed to ST’ (based on T’) would reveal an attribute disclosure risk from including that individual. The risk of attribute disclosure can be systematically evaluated by training a multitude of machine learning models that predict a sensitive attribute based on all remaining attributes in order to then study the predictive accuracy for the excluded individual (the red-colored male depicted in Figure 1). A privacy-safe synthetic data platform, like MOSTLY AI with its in-built privacy safeguards, does not exhibit any measurable change in inference due to the inclusion or exclusion of a single individual.
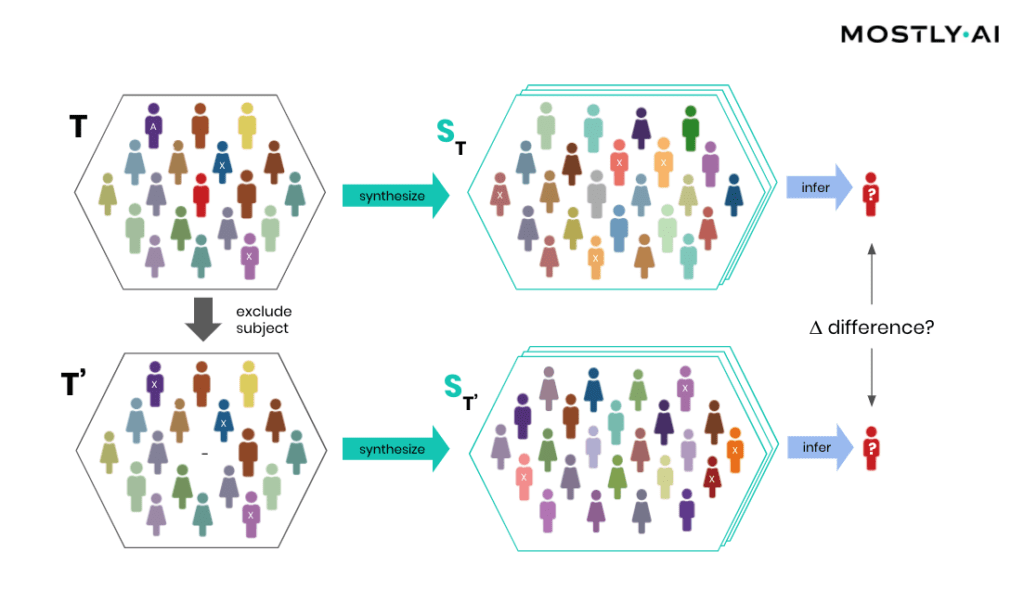
At this point, it is important to emphasize that it’s the explicit goal of a synthesizer to retain as much information as possible. And a high predictive accuracy of an ML model trained on synthetic data is testimony to its retained utility and thus value, and in itself not a risk of attribute disclosure. However, these inferences must be robust, meaning that they must not be susceptible to the influence of any single individual, no matter how much that individual conforms or does not conform to the remaining population. The bonus: any statistics, any ML model, any insights derived from MOSTLY AI’s anonymous synthetic data comes out-of-the-box with the added benefit of being robust. The following evaluation results table for the contraceptive method choice dataset from the technical assessment report further supports this argument.
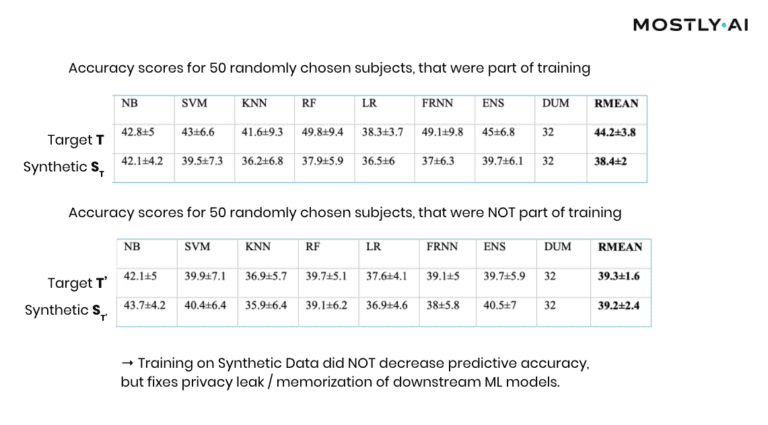
As can be seen, training standard machine learning models on actual data tends to be sensitive towards the inclusion of individual subjects (compare the accuracy of T vs. T’), which shows that the model has memorized its training data, and thus privacy has been leaked into the model parameters. On the other hand, training on MOSTLY AI’s synthetic data is NOT sensitive to individuals (compare ST with ST’). Thus, using synthetic data prevents the privacy leak / the overfitting of this broad range of ML models to actual data while remaining at the same level of predictive accuracy for holdout records.
Similarity-based privacy tests
While the previously presented framework allows for the systematic assessment of the (in)sensitivity of a synthetic data solution with respect to individual outliers, its leave-one-out approach does come with significant computational costs that make it unfortunately infeasible to be performed for each and every synthesis run. However, strong privacy tests have been developed based on the similarity of synthetic and actual data subjects, and we’ve made these an integral part of MOSTLY AI. Thus, every single time a user performs a data synthesis run, the platform conducts several fully automated tests for potential privacy leakage to help confirm the continuous valid working of the system.
Simply speaking, synthetic data shall be as close as possible, but not too close to actual data. So, accuracy and privacy, can both be understood as concepts of (dis)similarity, with the key difference being that the former is measured at an aggregate level and the latter at an individual level. But, what does it mean for a data record to be too close? How can one detect whether synthetic records are indeed statistical representations as opposed to overfitted/memorized copies of actual records? Randomly selected actual holdout records can help answer these questions by serving as a proper reference since they stem from the same target distribution but have not been seen before. Ideally, the synthetic subjects are indistinguishable from the holdout subjects, both in terms of their matching statistical properties, and their dissimilarity to the exposed training subjects. Thus, while synthetic records shall be as close as possible to the training records, they must not be any closer to them than what would be expected from the holdout records, as this would indicate that individual-level information is leaked rather than general patterns learned.
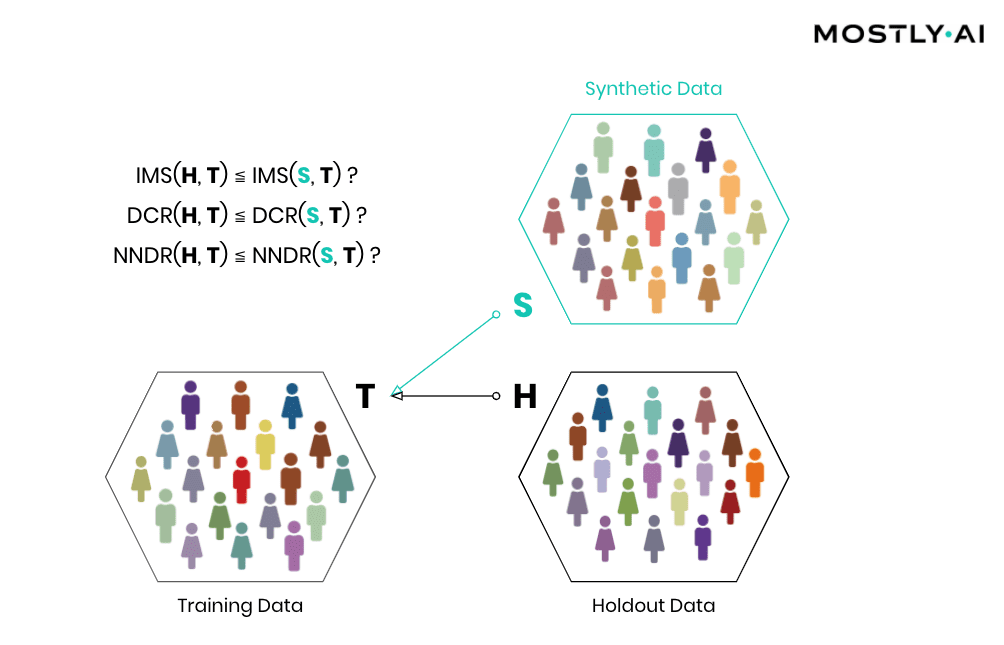
Then, how can the individual-level similarity of two datasets be quantified? A first, natural candidate is to investigate the number, respectively the share, of identical matches between these (IMS = identical match share). We thus have statistical tests automatically be performed that verify that the synthetic dataset does not have significantly more matches with the training data than what would be expected from a holdout data.
Important: the existence of identical matches within a synthetic dataset is in itself not an indicator for a privacy leak but rather needs to be assessed in the context of the dataset, as is done with our statistical tests. E.g., a dataset that exhibits identical matches within the actual data itself, shall also have a similar share of identical matches with respect to the synthetic data. Analogous to that metaphorical monkey typing the complete works of William Shakespeare by hitting random keys on a typewriter for an infinite time, any random data generator will eventually end up generating any data records, including the full medical history of yours. However, as there is no indication which of the generated data points actually exist and which not, the occurrence of such matches in a sea of data is of no use to an attacker. Yet further, these identical matches must NOT be removed from the synthetic output, as such a filter would 1) distort the resulting distributions, but more importantly 2) would actually leak privacy, as it would reveal the presence of a specific record in the training data by it being absent from a sufficiently large synthetic dataset!
But one has to go further and not only consider the dissimilarity with respect to exact matches but also with respect to the overall distribution of their distance to closest records (DCR). Just adding noise to existing data in a high-dimensional data space does not provide any protection, as has been laid out in the seminal Netflix paper on reidentification attacks (see also Part I). Taking your medical record, and changing your age by a couple of years, still leaks your sensitive information and makes that record re-identifiable, despite the overall record not being an exact match anymore. Out of an abundance of caution and to provide the strictest guarantees, one, therefore, shall demand that a synthetic record is not systematically any closer to an actual training record than what is again expected from an actual holdout record. On the other hand, if similar patterns occur within the original data across subjects, then the same (dis-)similarity shall be present also within the synthetic data. Whether the corresponding DCR distributions are significantly different can then be checked with statistical tests that compare the quantiles of the corresponding empirical distribution functions. In case the test fails, the synthetic data shall be rejected, as it is too close to actual records, and thus information on real individuals can potentially be obtained by looking for near matches within the synthetic population.
While checking for DCR is already a strong test, it comes with the caveat of measuring closeness in absolute terms. However, the distance between records can vary widely across a population, with Average Joes having small DCRs and Weird Willis (=outliers) having very large DCRs. E.g., if Weird Willi is 87 years old, has 8 kids, and is 212 cm tall, then shifting his height by a couple of centimeters will do little for his privacy. We have therefore developed an advanced measure that normalizes the distance to the closest record with respect to the overall density within a data space region, by dividing it by the distance to the 2nd closest record. This concept is known as the Nearest Neighbor Distance Ratio (NNDR) and is fortunately straightforward to compute. By checking that the NNDRs for synthetic records are not systematically any closer than expected from holdout records, one can thus provide an additional test for privacy that also protects the typically most vulnerable individuals, i.e., the outliers within a population. In any case, all tests (IMS, DCR, and NNDR) for a synthetic dataset need to pass in order to be considered anonymous.
Conclusion
We founded MOSTLY AI with the mission to foster an ethical data and AI ecosystem, with privacy-respecting synthetic data at its core. And today, we are in an excellent position to enable a rapidly growing number of leading-edge organizations to safely collaborate on top of their data for good use, to drive data agility as well as customer understanding, and to do so at scale. All while ensuring core values and fundamental rights of individuals remain fully protected.
Anonymization is hard - synthetic data is the solution. MOSTLY AI's synthetic data platform is the world’s most accurate and most secure offering in this space. So, reach out to us and learn more about how your organizations can reap the benefits of their data assets, while knowing that their customers’ trust is not put at any risk.
Credits: This work is supported by the "ICT of the Future” funding programme of the Austrian Federal Ministry for Climate Action, Environment, Energy, Mobility, Innovation and Technology.


