
“Airlines Passengers” is the first dataset which we at MOSTLY AI have published to the Databricks Marketplace. It’s a demonstration of our product, DataLLM, which allows customers to build new tabular data from little (“enrich”) or nothing (“mock”). In contrast to legacy tools like the `faker` library, we use a fine-tuned LLM for the data generation process. This makes it easier to specify the requirements in plain language and, crucially, injects real-world knowledge into the data. That is why we call it “smart” mock data.
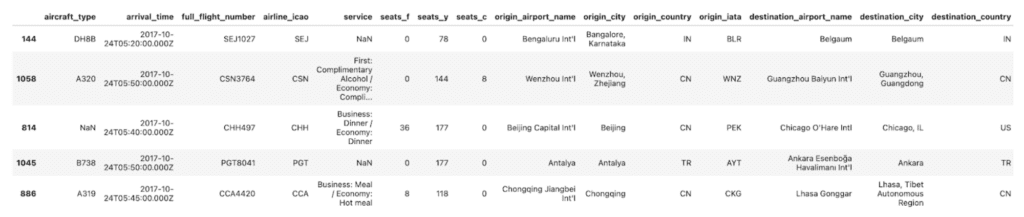
To illustrate this, we set out to generate mock passenger lists for real flights. Our starting point is a dataset with flights from the year 2017, from the top 100 airlines at the time. Each flight is listed with a flight number, origin and destination details, aircraft type, seat capacity and service details.
Getting from real flight data to synthetic passenger data
Our goal is to create passenger lists that look plausible in the context of the flight. For example, for a purely domestic flight within Malaysia, we expect the majority of the passengers to be Malaysian. Conversely, on a flight from Dubai to Chicago, we expect an international crowd with quite some Americans.
To achieve this we will follow a two step approach. First, we will enrich the flight data with the exact columns we need for step 2: a summary of the flight details, and the estimated number of passengers on the flight. Conveniently, LLMs are good at summarizing, too. We can use DataLLM itself to convert each row of the flights table into a one-line summary in plain English, and also to estimate the passenger count.
df['summary'] = datallm.enrich(df, prompt="""Summarise this flight to provide context for a passenger manifest and inflight menus.
For example: Flight LH234 from Frankfurt (DE) to New York (USA) operated by a B747 with 250 seats in economy and 48 seats in business class.
Service listed is "lunch in business class and economy class."
""", max_tokens=64)
df.summaryFig. 1: Code to summarize flight data in a specific format
And here is how we can ask DataLLM to estimate passenger counts:
df['pax'] = datallm.enrich(df, prompt="""How many passengers were on this flight?
Consider the flight could be less than capacity (not full) or full
but never more passengers than seats""", dtype="integer")Fig. 2: Code to extract an estimate for passenger count
Within seconds, DataLLM iterates through each row of the dataframe and adds the result to it.
Then, in step 2, we can create a mock passenger list for each flight. The end to end process is shown in Figure 3 below.
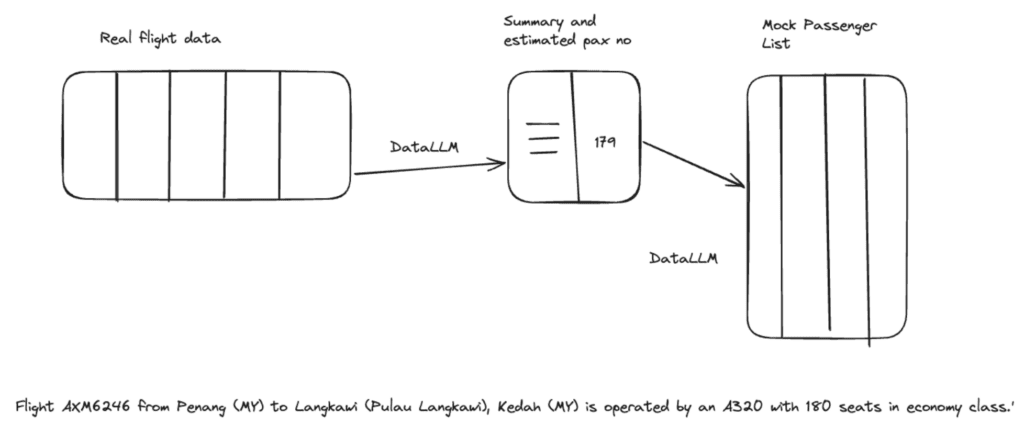
Providing context to DataLLM to mock the passengers
For each iteration of creating mock data, we provide a detailed prompt in text format which describes the desired dataset in two parts. The first part is generic (“We want a passenger list…”) and the second part is specific for each flight (“Flight LH419 from New York to Frankfurt…”). We also need to provide the number of passengers, which we asked DataLLM to estimate as part of the preparation of the flight data above.
Of course, we also provide detailed instructions for each single column to be created. In the case of our passengers, we want to see the following columns: name, age, nationality, special meal request (if any), and frequent flier code. These columns also showcase several of the prompt types that DataLLM supports, e.g. regular expressions.
for flight in df.itertuples():
print(f"Working on {flight.summary}")
paxlist = datallm.mock(n=flight.pax,
data_description="An official passenger manifest for an airline flight. "+flight.summary,
columns={
"Pax name": {"dtype": "string"},
"Age": {"dtype": "integer"},
"Nationality": {"dtype": "string"},
"Special Meal": {"categories": ["N/A", "Vegetarian", "Kosher", "Hindu", "Halal", "Gluten Free"]},
"Frequent flier code": {"regex": "[A-Z]{4}"}
})Fig. 2: Code sample showing the parameters for the mock data generation
The results
Iterating through 50 sample flights and creating the passenger lists took 15 mins, i.e. about 0.1s per passenger. You can see how well crafted the results are: a variety of ages, names, and nationalities, but in line with the context of the specific flight.
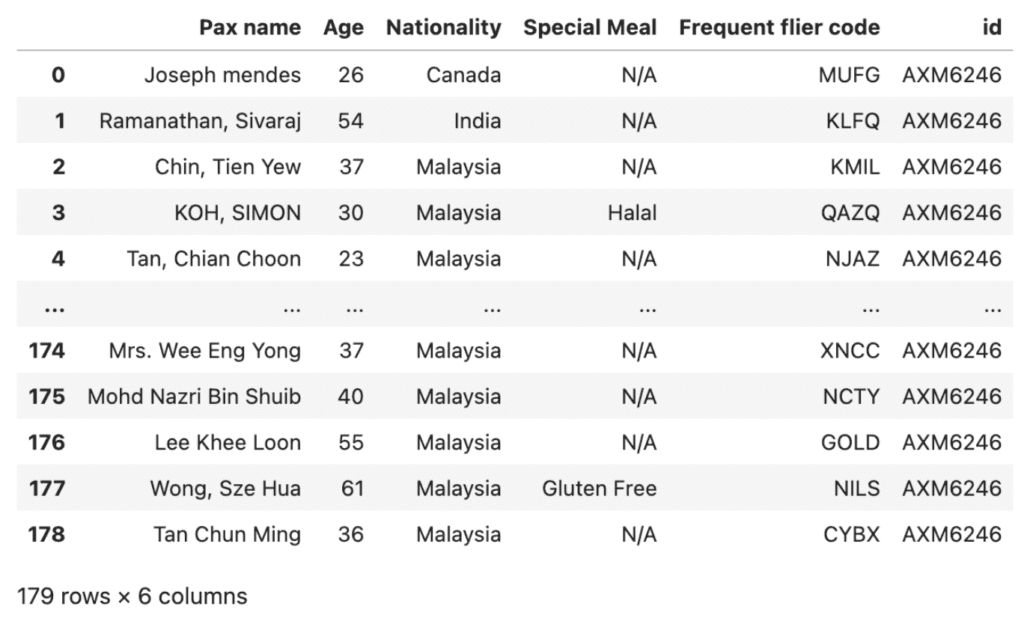
As we expected, a flight to the USA (from Dubai) has a lot more Americans on it:
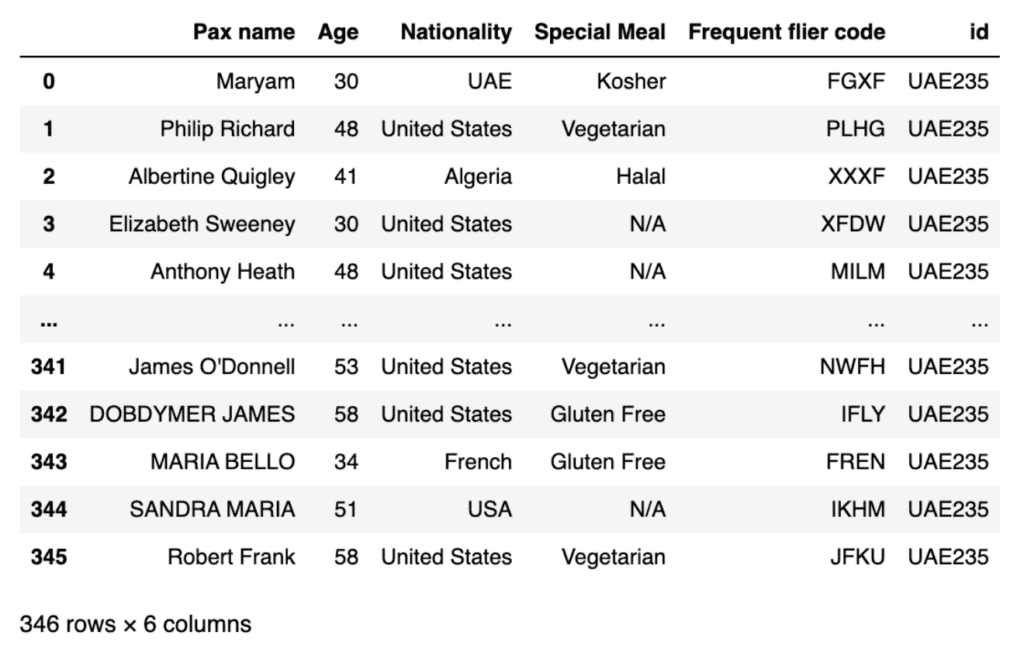
We don’t pretend we can generate real or accurate passenger lists from scratch, but we believe that these ones are a lot more plausible and useful than anything you could create with other tools today.
Trying it out in Databricks
You can access the final lists published on the Databricks Marketplace here … But the best way to consume our data product is to consume the embedded Databricks Notebook, which at the beginning has a link to a demo video. It then walks through each of the steps mentioned above. You can check it out here:
With a free API token from data.mostly.ai, you can create your own passenger lists for your own sample of flights. Once you have mastered the technique, you can use similar approaches to generate test and demo data or enhance existing data with real world knowledge.
We can’t wait to see what ideas and use cases you come up with!
Addendum
In order to use data from the Marketplace, your Databricks role needs to have the privilege `USE MARKETPLACE ASSETS`. You may have to speak to your Databricks Admin to obtain it.


