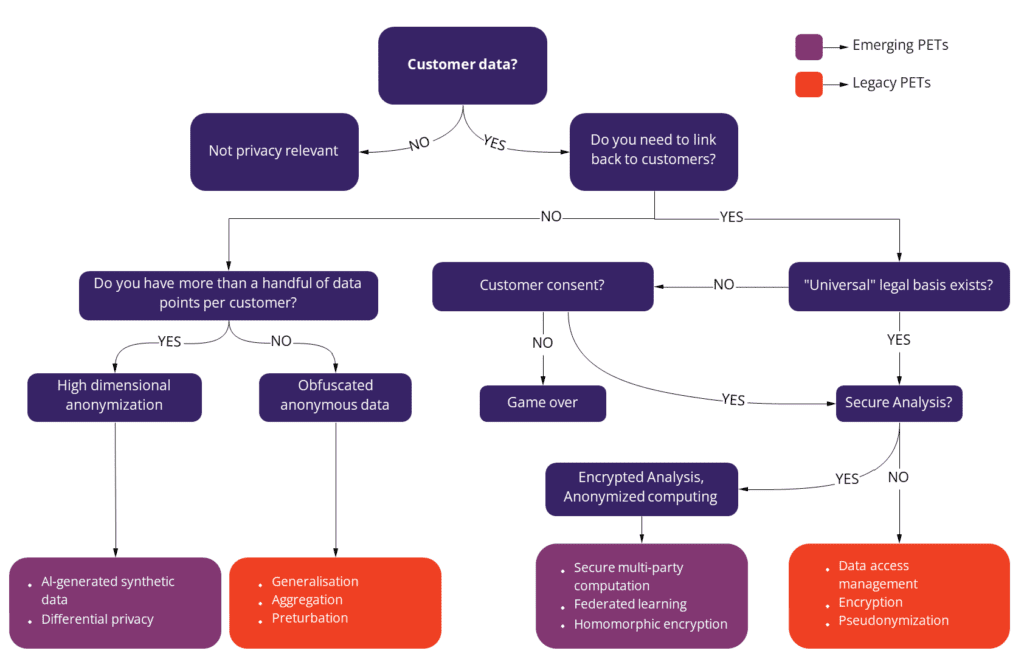
Privacy enhancing technologies protect data privacy in new ways. Legacy data anonymization techniques can no longer fully protect privacy. In their effort to mask or obfuscate data, legacy anonymization destroys data utility. As a result, these old technologies should not be considered to be privacy enhancing technologies or PETs.
Examples of privacy enhancing technologies
There are five major emerging privacy enhancing technologies that can be considered true PETs: homomorphic encryption, AI-generated synthetic data, secure multi-party computation, federated learning and differential privacy. These new generation privacy enhancing technologies are crucial for using personal data in safe ways.
Organizations handling sensitive customer data, like banks, are already using PETs to accelerate AI and machine learning development and to share data outside and across the organization. Most companies will end up using a combination of different PETs to cover all of their data use cases. Let's see how the five most promising privacy enhancing technologies work and when they come in handy!
1. Homomorphic encryption
Homomorphic encryption is one of the most well-known privacy enhancing technologies. It allows third parties to process and manipulate data in its encrypted form. In simple terms: someone who performs the analysis will never actually get to see the original data. But that's also one of the severe limitations of this technology. It's not helpful when the person who should do the analysis has no prior knowledge about the dataset as data exploration is virtually impossible.
Another limitation of homomorphic encryption is that it's incredibly compute-intensive and has restricted functionality. As a result, some queries are not possible on encrypted data. It's one of the least mature, but promising technologies when it comes to anti-money laundering and the detection of double fraud.
2. AI-generated synthetic data
AI-generated synthetic data is one of the most versatile privacy enhancing technologies. AI-powered synthetic data generators are trained using real data. After the training, the generator can create statistically identical but flexibly sized datasets. Since none of the individual data points match the original data points, re-identification is impossible.
The most popular synthetic data use cases include data anonymization, advanced analytics, AI and machine learning. The process of synthesization also allows for different data augmentation processes. Upsampling rare categories in a dataset can make AI algorithms more efficient. Subsetting large datasets into smaller, but representative batches is useful for software testing. Advanced synthetic data platforms offer statistically representative data imputation and rebalancing features. Since synthetic datasets do not maintain a 1:1 relationship with the original data, subjects are impossible to reidentify. As a result, it's not suitable for use cases where re-identification is necessary.
3. Secure multi-party computation
Secure multi-party computation is an encryption methodology. It allows multiple parties to collaborate on encrypted data. Similarly to homomorphic encryption, the goal here is to keep data private from participants in the computational process. Key management, distributed signatures, and fraud detection are some of the possible use cases here. The limitation of secure multi-party computation is the resource overhead. To pull off a SMPC stunt with success is pretty tricky - everything has to be timed right and processing has to happen synchronously.
4. Federated learning
Federated learning is a specific form of machine learning. Instead of feeding the data into a central model, the data stays on the device and multiple model versions are trained and operated locally. The result of these local trainings are model updates, which get fed back into and improve the central model. This decentralized form of machine learning is especially prevalent in IoT applications.
The training takes place on edge devices, such as mobile phones. Federated learning on its own doesn’t actually protect privacy, only eliminates the need for data sharing in the model training process. However, the fact that data isn’t shared doesn’t mean privacy is safe. The model updates in transitioning from the edge devices could also be hacked and leak privacy. To prevent this, federated learning is often combined with another PET, like differential privacy.
5. Differential privacy
Differential privacy is not as much a privacy-enhancing technology in itself, but a mathematical definition of privacy. Differential privacy quantifies the privacy leakage that occurs when analyzing a differentially private database. This measure is called the epsilon value. In an ideal world - or with an epsilon value of 0 - the result of said analysis wouldn’t differ no matter whether a given individual is present in the database or not.
The higher the epsilon the more potential privacy leakage can occur. In academia, epsilon values of below 1 are recommended to achieve strong anonymization. In practice, it’s still a challenge to determine a suitable epsilon value. This is important to keep in mind, as differential privacy does not automatically guarantee adequate privacy protection. It simply offers a mathematical guarantee for the upper boundary of potential privacy leakage. So getting the epsilon value set right is of utmost importance. It needs to be low enough to protect privacy, but not so low that the noise that has to be added to achieve this low epsilon value is diminishing data utility.
More often, privacy practitioners use it in combination with another PET, such as federated learning.
Which Privacy Enhancing Technology to use when?
Different privacy-enhancing technologies' benefits and limitations need to be weighed carefully. Some of them are more use case agnostic than others, but most organizations will have to invest in more than one PET to cover all use cases. Some legacy anonymization techniques might also have a place in the data tech stack as additional measures, but their use should be limited.