
What is AI-generated synthetic data?
MOSTLY AI’s synthetic data platform is based on a groundbreaking machine learning technology, ready to create privacy regulation compliant, highly accurate synthetic versions of datasets. The synthetic data versions generated by MOSTLY AI retain up to 99% of the information contained in the original, yet real individuals are impossible to re-identify. The implications for the financial industry and the ways in which this technology can be applied are manifold.
Large financial institutions and banks have always been among the most conservative users of technology and for a good reason. Nowhere else is data so rich and so risky, so full of hidden stories and telltale patterns. What makes these oceans of information so valuable is precisely what makes them so sensitive. And customers are well aware of this. 87% of Americans consider credit card data moderately or extremely private, whereas only 68% consider health and genetic information private. In other words, people are shyer about their wallets than their medical secrets.
Considering this sentiment, it is not surprising that financial businesses guard their customers’ data very carefully. Customers demand and reward this scrutiny. With the advance of data-driven services, personal relationships are no longer the main driver of trust. Instead, one of the biggest drivers of loyalty for banking customers is the ability to trust their bank in protecting their personal data.
The great banking dilemma: innovation versus data-privacy
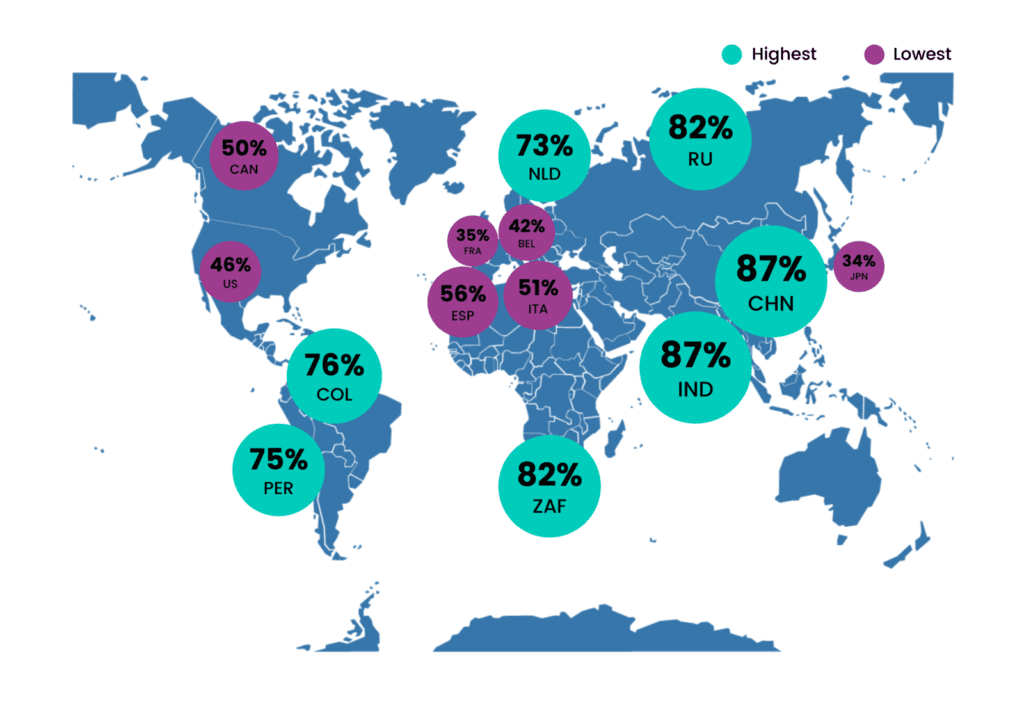
Source: Raconteur, The World of Fintech
Customers in the financial world are hungry for cutting edge innovations. Data is the fuel required by technologies to make these advances. New disrupting fintech players have been making these innovations happen with Revolut, Monzo, Transferwise and others picking the low hanging fruits left untouched by traditional institutions. So far, the great data gateways at banks and large financial organizations have been closed and heavily guarded for security reasons.
While security remains a high priority, it is now possible to open those gateways without jeopardizing safety by letting synthetic copies of your valuable data assets do its magic for the financial industry. MOSTLY AI's enterprise-grade synthetic data platform is changing the game by offering a safe, trustworthy and compromise-free solution for using previously untapped data assets, bridging the gap between technological ambitions and real-world possibilities.
How does AI-generated synthetic data work and why is it superior to data masking?
By creating synthetic copies from your valuable data assets, such as credit card transaction records, client identity repositories, purchase records of financial products or high value investment portfolios, you can unlock rich and as yet untouched stories of human behavior, while also preserving their complexity. For example, when it comes to spending money, shopping behavior is surprisingly easy to predict by training machine learning algorithms on credit card data.
Researchers of this study used anonymized datasets. There are different approaches to traditional anonymization, but they have one thing in common: a lot of valuable data gets thrown away to prevent re-identification of customers. With synthetic data, these algorithms can account for much broader and deeper insights, while anonymization methods come with serious limitations, very often rendering datasets effectively useless.
No matter how thorough the process to remove sensitive bits of data was, it is still shockingly easy to re-identify datasets anonymized with traditional techniques. MOSTLY AI’s synthetic data platform satisfies two seemingly opposing needs: it provides a true reflection of real life data, yet is impossible to re-identify - hence the revolutionary nature of this technology. The potentials are huge. There are just so many stories hidden in behavioral datasets ready to be discovered with the right tools. Customer behavior can be used to value companies, to predict credit risk, to build data-driven services and to guide marketing efforts, just to mention a few examples of how magical machine learning algorithms can be when fed with good quality datasets of financial behavior.
So what are the most important ways in which financial organizations can benefit from using synthetic data in 2020?
#1 Make the most of AI and cloud computing technologies
Machine learning algorithms are hungry beasts when it comes to data and computing power. Banks and financial institutions often miss out on these innovative technologies, because uploading sensitive data to cloud platforms is just out of the question for privacy reasons. A synthetic version of a sensitive dataset can stand in for the purpose of training algorithms, which - once trained - can be brought back to the premises and used on the original data.
In addition, synthetic data can improve the performance of machine learning algorithms by as much as 15% by providing significantly more samples than otherwise available in the original data and by upsampling minority classes that would otherwise remain underrepresented.
In other cases, existing datasets are simply too small to be used for modelling purposes. Recessions for example are too rare to study without putting the data on synthetic steroids. Similarly, credit risk assessment models usually need to be tested against extreme events, such as surprise election outcomes, like the Brexit referendum or the 2016 US presidential election, where polls failed to predict results. These extreme events lack enough data points and AI-generated synthetic data can fill in this gap to improve the training of crucial models, such those applied to predict credit risk by conducting more thorough stress-testing.
MOSTLY AI' synthetic data platform can scale up existing data and build more robust datasets out of all rare events, like in the early days of a product launch or in case of a rarely purchased, but high value service. Similarly, high quality AI-generated data provides excellent input for the initial training of robo-advisor programs before launching fully automated financial adviser platforms.
#2 Create products and services that genuinely meet customer needs
And not just in-house either. Synthetic data benefits product and service development as it brings meaningful insights into the design process. Safely sharing the synthetic version of datasets with innovation partners, third party service providers and researchers also becomes possible, opening up new spaces of cooperation and co-creation. Networks of interconnected services and products are the future of banking and synthetic data will play an important role in setting up these complex ecosystems.
During API development and testing, it’s crucial to provide quality sandbox environments for developers, complete with realistic data, so by the time a service goes live, apps developed by third parties are prepared for all types of consumer behavior. Synthetic data help engineers ensure that their software works in various planned and unplanned scenarios, significantly reducing product downtimes after a launch. Synthetic test data is easy to create and provides a realistic and privacy-compliant drop-in placement for production data.
#3 Share banking data with third parties in a safe way
Synthetic data makes safe, no-risk monetization of data possible. Although third-party data sharing is the biggest challenge for historically cautious financial players, it is now a real possibility and it will soon be the backbone of financial services. Whether it’s raw data through an API or in the form of synthetic datasets, this future is here and institutions need to step up their game or risk losing out to disruptors. These new players are ready to take the leap. NGOs and other charities working on improving the lives of particular at-risk groups or society at large could also benefit from access to synthetic financial datasets. Such cooperations could earn banks and financial institutions a huge amount of publicity and scientific credit at research communities. Using synthetic data sandboxes for POC processes can speed up processes and save huge amounts on data provisioning costs.
#4 Improve fraud detection processes
Detecting fraud doesn’t have to be a costly and tedious manual process - there is no need to look at specific transactions to train algorithms, only patterns to see if the amounts justify an audit or are perfectly in line with what’s expected. Synthetic data can do this with high accuracy in a quick and painless way by generating unique and rare fraud patterns that your automation can use for fraud detection.
However, the advantages don’t end there. Fraud detection datasets are usually highly imbalanced and so traditional machine learning often are challenged. MOSTLY AI is also able to fix class imbalances engraved in an original dataset and thus help downstream models to perform better.
Synthetic data can boost the performance of fraud detection and AML models, leading to a more accurate detection of positive cases.
#5 Make life easier for yourself and your organization
The lengthy and often overly complicated legalities of sharing data can make such efforts virtually impossible, even when the data lake’s access privileges only have to be granted to another department in your organization. A familiar and painful situation for those working in large institutions: by the time the permission arrives, the business need is not met in time. To speed up and simplify data-driven operations, the use of synthetic data can do wonders, doing away with the need to get the blessings of the legal department and providing access to datasets for any number of colleagues, even across borders or within tight budget constraints and deadlines. Since it doesn't classify as personal data, synthetic data can be shared across international borders even after the landmark ruling of Schrems II.
The takeaway: AI-generated synthetic data is a must-have in finance
In summary, AI-powered synthetic data is a privacy-preserving way for financial institutions to use advanced machine learning services and algorithms, to develop data-driven products, such as robo-advisors, to monetize their data reserves, to improve fraud detection, to fix historically biased datasets and to simplify data sharing in-house, with partners and third parties. Simply put, it’s a must-have technology for financial power houses, whose very existence rests on and will increasingly be governed by the data economy. GDPR/CCPA compliant behavioral data is an asset, which needs to be actively cultivated and harvested for the benefit of customers and institutions alike. Find out more about synthetic data use cases in finance!
Feature image by tuetyi.com
Learn how innovators outrun competitors in banking!
Accelerating digital transformation has been at the top of the agenda for financial institutions. Download our ebook to find out how AI-generated synthetic data can give your organization a competitive edge.


