
TL;DR: Removing identical matches (as found in the original data) in a synthetic dataset does not protect, it actually leaks privacy.
Synthetic Data
While this blog post will cover a more advanced topic of synthetic data, let me briefly explain what synthetic data is, in case you’re new to it. Synthetic data - as we refer to it - is data that is created using Generative AI that was trained on original data to learn from. So basically you take an existing dataset and feed it as an input to a GenAI model. The model learns all the patterns and characteristics of the original data and then can be used to create a new version of that data: an artificial version, a synthetic dataset. Synthetic data is used today in various industries for different purposes but one of the main use cases is data anonymization. While synthetic data fully represents original data in its statistical characteristics, there is one important difference. When done right, synthetic data doesn’t contain any Personal Identifiable Information (PII). The GenAI model only learns generalizations of the original data and no individual data points. While synthetic data is therefore 100% useful, it’s also fully privacy safe, allowing organizations to work much more flexibly with it.
An interesting Question about Privacy
A common misconception of synthetic data and data privacy is what to do with exact matches in the synthetic data. As we’ve learned before, synthetic data is artificially created data based on statistical probabilities. To give an example, an original data record from a set of thousands of rows might look something like this

Example of an original data record (simplified US census data)
And a synthetic record then might look something like this

Example of a synthetic data record (simplified US census data)
It’s important to note that there is no 1:1 relationship between original data and synthetic data. So in the above example, the synthetic record is not “based” on that one exact original data record, but all the thousands of records the GenAI model was trained with.
But nevertheless, you get the idea: the synthetic data record “looks and feels” like an original data record. Once the data we’re talking about becomes sufficiently large enough (thousands of rows of data, dozens of columns) chances are that when a properly designed process is followed the synthetic data will always be completely different from the original data. But now an important question is sometimes brought up - what happens if there is an exact match in the synthetic data? A synthetic data record that looks exactly like an original data record. Would that be a privacy violation? Should we maybe even attempt to remove that match from the synthetic dataset?
Swiss Cheese
To answer these questions let’s now turn to Swiss Cheese. Let’s look at the following artificially made up example in a two dimensional space. Every blue dot represents a synthetic data record. In a post-processing step certain synthetic data records were removed because they were too close (or even identical) to the original data. Do you have any hunch which data records this might have been?
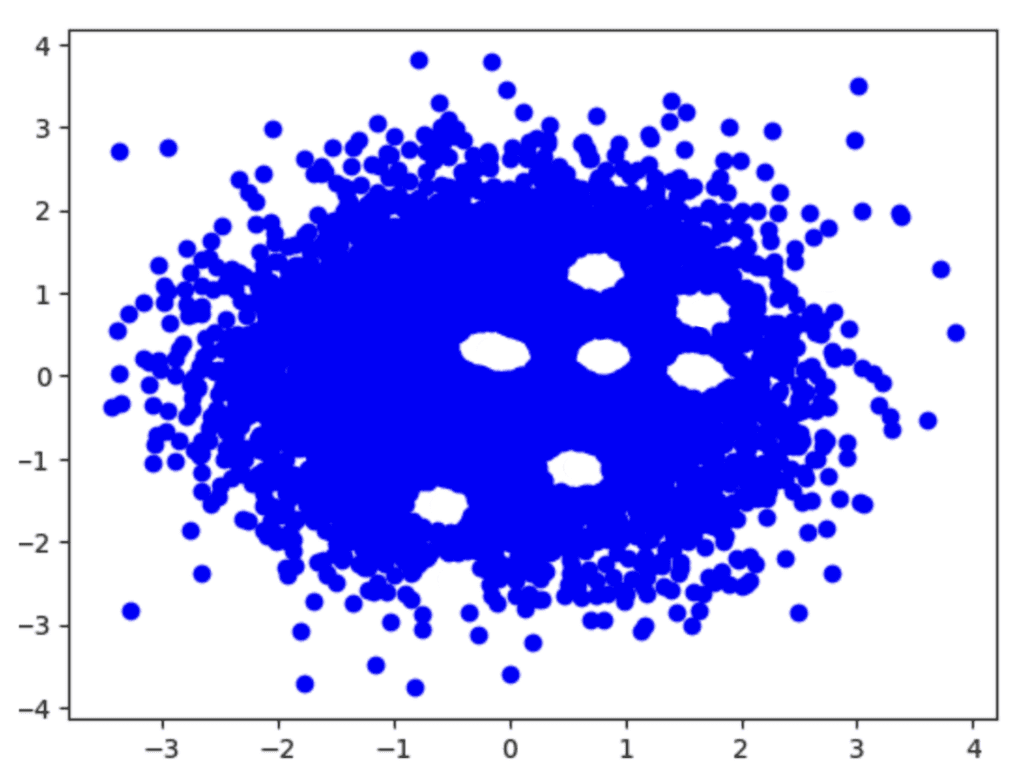
Visualization of Synthetic Data records
Well, I guess you didn’t have too much of a challenge to figure out that the “holes” in that blue sea of dots are quite good candidates for the artificially removed synthetic data records. And indeed, if we look at the original data records, labeled as “tgt” in red, they nicely fall into these holes as shown in the next chart.
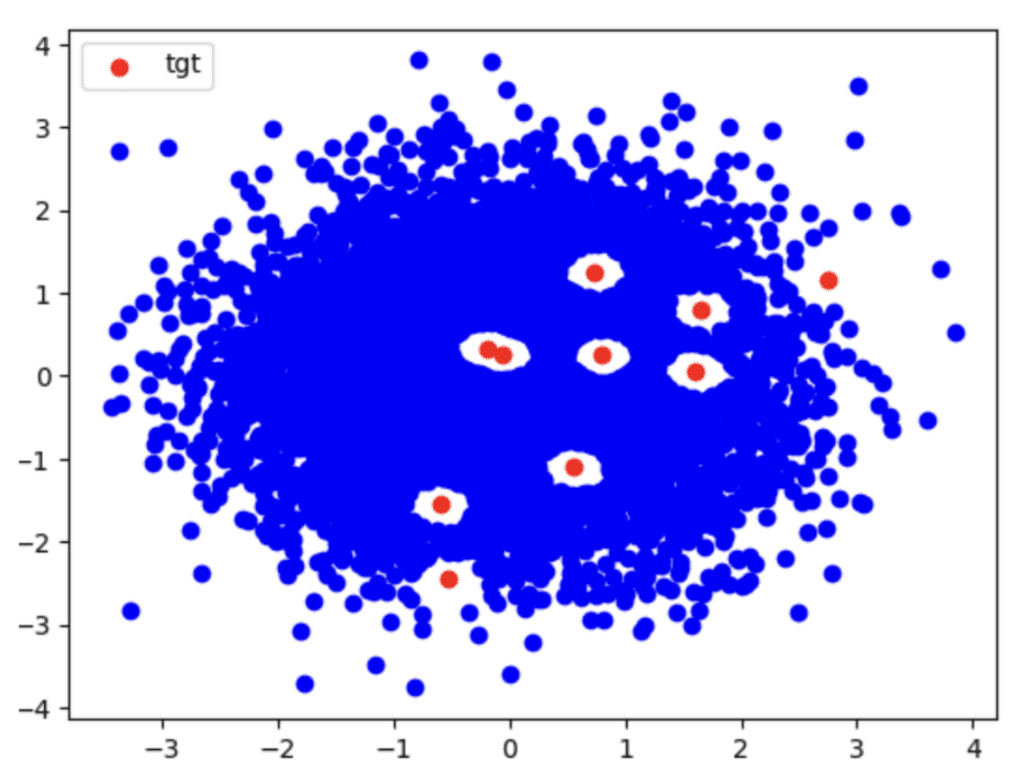
Visualization of Synthetic Data records and original Data records attempted to protect
But what does this mean concretely? This means that with the well-intentioned attempt to protect some target records in the original data by removing synthetic data records that were identical matches (or too close to the original data records) the exact opposite is achieved: something about the original data is disclosed and private information leaked!
Does that mean that you can just copy/paste original data and make the argument that it’s still safe data to use? No, of course not. You still need to follow a well designed process of synthetic data generation that preserves privacy. And that means you need to take care that the GenAI model only generalizes (e.g. does not overfit) and that you have a way of protecting extreme values in the data (e.g. rare categories). The MOSTLY AI Synthetic Data Platform does all of this automatically and you can find all the details about privacy preserving features here.
But once you've followed such a process - do not remove identical matches from the synthetic data!
Another perspective
I know it can still be a bit daunting to wrap your head around this. I remember an executive from a bank telling me once: “But what if a perfect match of a real world customer is present in the synthetic data. With everything: first name, last name, age, household income, etc. How can I explain to this person that his personal data was not leaked?” At first glance this indeed sounds like a difficult conversation to have. But the infinite monkey theorem provides another perspective to this. The theorem states that a monkey, hitting a keyboard an infinite amount of time, will at one point type surely any given text - including the complete works of William Shakespeare. So the question is not - what does this specific synthetic data record show. But instead one needs to ask, what was the process like that lead to the creation of this record. And if the process was a well designed and privacy-safe synthetic data generation process, then indeed this was not a privacy violation and the opposite is true. If one had artificially removed that record of that customer this would have put the personal data of this person at higher risk.
Identical Match Share (IMS)
As we’ve seen an identical match in the synthetic data is not necessarily a privacy violation. Can it then even make sense to look for identical matches? The answer is yes but one needs to look at the share of identical matches (IMS) within the original data and within the synthetic data.
That’s another aspect that might not be so intuitive to understand in the first place, but one can compare data with itself and one will likely find identical matches within that comparison. Consider a super simple dataset representing the customer base of a large bank that only contains two variables: age and gender. If you look at enough samples you will certainly find identical matches in that dataset itself (e.g. male and 37 years old). If we do this in a structured way (e.g. taking a sample of 500 rows of data and comparing that with a sample of 500 rows of data) we can calculate the share of identical matches within the original dataset (e.g. 5%).
If we then create a synthetic dataset of that original dataset we can perform a similar analysis: take a sample of 500 rows of synthetic data and calculate the IMS between the synthetic sample and the original data sample that we previously used. If our synthetic data was produced properly, we expect to find a similar IMS value (e.g. 5%) and certainly not a significantly larger IMS value for the synthetic sample. And this approach is exactly what you will find in the evaluation report of a trained Generator on the MOSTLY AI Synthetic Data Platform.
In Summary
Removing identical matches in a synthetic dataset does not protect, it actually leaks privacy!


