TABLE OF CONTENT
- Why care about data anonymization tools?
- Data anonymization tools: What are they anyway?
- How do data anonymization tools work?
- Legacy data anonymization approaches
- The next generation of data anonymization tools
- Data anonymization approaches and their use cases
- The best and the worst data anonymization approaches
- Conclusion
Why should you care about data anonymization tools?
Data anonymization tools can be your best friends or your data quality’s worst enemies. Sometimes both. Anonymizing data is never easy, and it gets trickier when:
- You collect more data,
- Your datasets become more complex,
- Your adversaries come up with new types of privacy attacks,
- You remove PII from your data, thinking it will provide privacy protection,
- You add too much noise to the data and destroy the intellingence.
You try to do your best and use data anonymization tools on a daily basis. You have removed all sensitive information, masked the rest, and randomized for good measure. So, your data is safe now. Right?

As the Austrians—Arnold Schwarzenegger included—say: Schmäh! Which roughly translates as bullshit. Why do so many data anonymization efforts end up being Schmäh?
Data anonymization tools: What are they anyway?
Data anonymization tools conveniently automate the process of data anonymization with the goal of making sure that no individual included in the data can be re-identified. The most ancient of data anonymization tools, namely aggregation and the now obsolete rounding, were born in the 1950s. The concept of adding noise to data as a way to protect anonymity entered the picture in the 1970s. We have come a long way since then. Privacy-enhancing technologies were born in the 90s and have been evolving since, offering better, safer, and more data-friendly data anonymization tools.
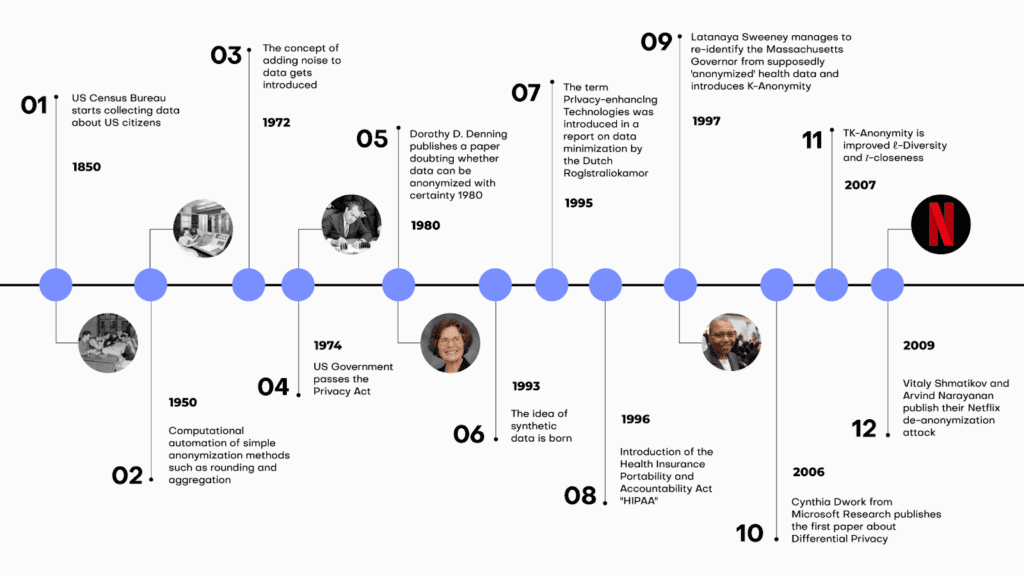
Data anonymization tools must constantly evolve since attacks are also getting more and more sophisticated. Today, new types of privacy attacks using the power of AI, can reidentify individuals in datasets that are thought of as anonymous. Data privacy is a constantly shifting field with lots of moving targets and constant pressure to innovate.
Data anonymization tools: How do they work?
Although a myriad of data anonymization tools exist, we can differentiate between two groups of data anonymization tools based on how they approach privacy in principle. Legacy data anonymization tools work by removing or disguising personally identifiable information, or so-called PII. Traditionally, this means unique identifiers, such as social security numbers, credit card numbers, and other kinds of ID numbers.
The trouble with these types of data anonymization tools is that no matter how much of the data is removed or modified, a 1:1 relationship between the data subject and the data points remains. With the advances of AI-based reidentification attacks, it’s getting increasingly easier to find this 1:1 relationship, even in the absence of obvious PII pointers. Our behavior—essentially a series of events—is almost like a fingerprint. An attacker doesn’t need to know my name or social security number if there are other behavior-based identifiers that are unique to me, such as my purchase history or location history. As a result, state of the art data anonymization tools are needed to anonymize behavioral data.
Which data anonymization approaches can be considered legacy?
Legacy data anonymization tools are often associated with manual work, whereas modern data privacy solutions incorporate machine learning and AI to achieve more dynamic and effective results. But let's have a look at the most common forms of traditional anonymization first.
1. What is data masking?
Data masking is one of the most frequently used data anonymization approaches across industries. It works by replacing parts of the original data with asterisks or another placeholder. Data masking can reduce the value or utility of the data, especially if it's too aggressive. The data might not retain the same distribution or characteristics as the original, making it less useful for analysis.
The process of data masking can be complex, especially in environments with large and diverse datasets. The masking should be consistent across all records to ensure that the data remains meaningful. The masked data should adhere to the same validation rules, constraints, and formats as the original dataset. Over time, as systems evolve and new data is added or structures change, ensuring consistent and accurate data masking can become challenging.
The biggest challenge with data masking: to decide what to actually mask. Simply masking PII from data using Python, for example, still has its place, but the resulting data should not be considered anonymized by any stretch of the imagination. The problem are quasi identifiers (= the combination of attributes of data) that if left unprocessed still allow re-identification in a masked dataset quite easily.

2. What is pseudonymization?
Pseudonymization is strictly speaking not an anonymization approach as pseudomized data is not anonymous data. However, it's very common and so we will explain it here. Pseudonymization replaces private identifiers with fake identifiers, or pseudonyms or removes private identifiers alltogether. While the data can still be matched with its source when one has the right key, it can't be matched without it. The 1:1 relationship remains and can be recovered not only by accessing the key but also by linking different datasets. The risk of reversibility is always high, and as a result, pseudonymization should only be used when it’s absolutely necessary to reidentify data subjects at a certain point in time.
The pseudonyms typically need a key for the transformation process. Managing, storing, and protecting this key is critical. If it's compromised, the pseudonymization can be reversed.
What’s more, under GDPR, pseudonymized data is still considered personal data, meaning that data protection obligations continue to apply.
Overall, while pseudonymization might be a common practice today, it should only be used as a stand-alone tool when absolutely necessary. Pseudonymization is not anonymization and pseudonymized data should never be considered anonymized.
3. What is generalization and aggregation?
This method reduces the granularity of the data. For instance, instead of displaying an exact age of 27, the data might be generalized to an age range, like 20-30. Generalization causes a significant loss of data utility by decreasing data granularity. Over-generalizing can render data almost useless, while under-generalizing might not provide sufficient privacy.

You also have to consider the risk of residual disclosure. Generalized data sets might contain enough information to infer about individuals, especially when combined with other data sources.
4. What is data swapping or perturbation?
Data swapping or perturbation describes the approach of replacing original data values with values from other records. The privacy-utility trade-off strikes again: perturbing data leads to a loss of information, which can affect the accuracy and reliability of analyses performed on the perturbed data. However at the same time the achieved privacy protection is not very high. Protecting against re-identification while maintaining data utility is challenging. Finding the appropriate perturbation methods that suit the specific data and use case is not always straightforward.

5. What is randomization?
Randomization is a legacy data anonymization approach that changes the data to make it less connected to a person. This is done through adding random noise to the data.
Some data types, such as geospatial or temporal data, can be challenging to randomize effectively while maintaining data utility. Preserving spatial or temporal relationships in the data can be complex.
Selecting the right approach (i.e. what variables to add noise to and how much) to do the job is also challenging since each data type and use case could call for a different approach. Choosing the wrong approach can have serious consequences downstream, resulting in inadequate privacy protection or excessive data distortion.
Data consumers could be unaware of the effect randomization had on the data and might end up with false conclusions. On the bright side, randomization techniques are relatively straightforward to implement, making them accessible to a wide range of organizations and data professionals.
6. What is data redaction?
Data redaction is similar to data masking, but in the case of this data anonymization approach, entire data values or sections are removed or obscured. Deleting PII is easy to do. However, it’s a sure-fire way to encounter a privacy disaster down the line. It’s also devastating for data utility since critical elements or crucial contextual information could be removed from the data.

Redacted data may introduce inconsistencies or gaps in the dataset, potentially affecting data integrity. Redacting sensitive information can result in a smaller dataset. This could impact statistical analyses and models that rely on a certain volume of data for accuracy.
Next-generation data anonymization tools
The next-generation data anonymization tools, or so-called privacy-enhancing technologies take an entirely different, more use-case-centered approach to data anonymization and privacy protection.
1. Homomorphic encryption
The first group of modern data anonymization tools works by encrypting data in a way that allows for computational operations on encrypted data. The downside of this approach is that the data, well, stays encrypted which makes it very hard to work with such data if it was previously unknown the user. You can't perform e.g. exploratory analyses on encrypted data. In addition it is computationally very intensive and, as such, not widely available and cumbersome to use. As the price of computing power decreases and capacity increases, this technology is set to become more popular and easier to access.
2. Federated learning
Federated learning is a fairly complicated approach, enabling machine learning models to be trained on distributed datasets. Federated learning is commonly used in applications that involve mobile devices, such as smartphones and IoT devices.
For example, predictive text suggestions on smartphones can be improved without sending individual typing data to a central server. In the energy sector, federated learning helps optimize energy consumption and distribution without revealing specific consumption patterns of individual users or entities. However, these federated systems require the participation of all players, which is near-impossible to achieve if the different parts of the system belong to different operators. Simply put, Google can pull it off, while your average corporation would find it difficult.
3. Synthetic data generation
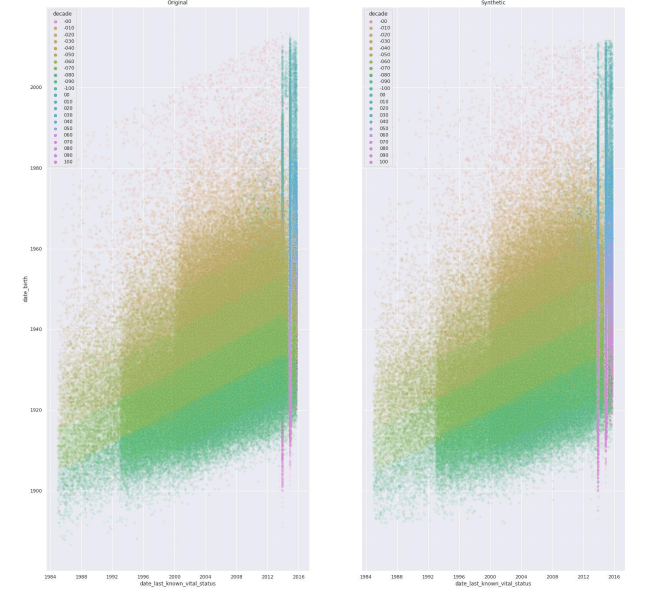
A more readily available approach is an AI-powered data anonymization tool: synthetic data generation. Synthetic data generation extracts the distributions, statistical properties, and correlations of datasets and generates entirely new, synthetic versions of said datasets, where all individual data points are synthetic. The synthetic data points look realistic and, on a group level, behave like the original. As a data anonymization tool, reliable synthetic data generators produce synthetic data that is representative, scalable, and suitable for advanced use cases, such as AI and machine learning development, analytics, and research collaborations.
4. Secure multiparty computation (SMPC)
Secure Multiparty Computation (SMPC), in simple terms, is a cryptographic technique that allows multiple parties to jointly compute a function over their private inputs while keeping those inputs confidential. It enables these parties to collaborate and obtain results without revealing sensitive information to each other.
While it's a powerful tool for privacy-preserving computations, it comes with its set of implementation challenges, particularly in terms of complexity, efficiency, and security considerations. It requires expertise and careful planning to ensure that it is applied effectively and securely in practical applications.

Data anonymization approaches and their use cases
Data anonymization encompass a diverse set of approaches, each with its own strengths and limitations. In this comprehensive guide, we explore ten key data anonymization strategies, ranging from legacy methods like data masking and pseudonymization to cutting-edge approaches such as federated learning and synthetic data generation. Whether you're a data scientist or privacy officer, you will find this bullshit-free table listing their advantages, disadvantages, and common use cases very helpful.
| # | Data Anonymization Approach | Description | Advantages | Disadvantages | Use Cases |
|---|---|---|---|---|---|
| 1 | Data Masking | Masks or disguises sensitive data by replacing characters with symbols or placeholders. | - Simplicity of implementation. - Preservation of data structure. | - Limited protection against inference attacks. - Potential negative impact on data analysis. | - Anonymizing email addresses in communication logs. - Concealing rare names in datasets. - Masking sensitive words in text documents. |
| 2 | Pseudonymization | Replaces sensitive data with pseudonyms or aliases or removes it alltogether. | - Preservation of data structure. - Data utility is generally preserved. - Fine-grained control over pseudonymization rules. | - Pseudomized data is not anonymous data. - Risk of re-identification is very high. - Requires secure management of pseudonym mappings. | - Protecting patient identities in medical research. - Securing employee IDs in HR records. |
| 3 | Generalization/Aggregation | Aggregates or generalizes data to reduce granularity. | - Simple implementation. | - Loss of fine-grained detail in the data. - Risk of data distortion that affects analysis outcomes. - Challenging to determine appropriate levels of generalization. | - Anonymizing age groups in demographic data. - Concealing income brackets in economic research. |
| 4 | Data Swapping/Perturbation | Swaps or perturbs data values between records to break the link between individuals and their data. | - Flexibility in choosing perturbation methods. - Potential for fine-grained control. | - Privacy-utility trade-off is challenging to balance. - Risk of introducing bias in analyses. - Selection of appropriate perturbation methods is crucial. | - E-commerce. - Online user behavior analysis. |
| 5 | Randomization | Introduces randomness (noise) into the data to protect data subjects. | - Flexibility in applying to various data types. - Reproducibility of results when using defined algorithms and seeds. | - Privacy-utility trade-off is challenging to balance. - Risk of introducing bias in analyses. - Selection of appropriate randomization methods is hard. | - Anonymizing survey responses in social science research. - Online user behavior analysis. |
| 6 | Data Redaction | Removes or obscures specific parts of the dataset containing sensitive information. | - Simplicity of implementation. | - Loss of data utility, potentially significant. - Risk of removing contextual information. - Data integrity challenges. | - Concealing personal information in legal documents. - Removing private data in text documents. |
| 7 | Homomorphic Encryption | Encrypts data in such a way that computations can be performed on the encrypted data without decrypting it, preserving privacy. | - Strong privacy protection for computations on encrypted data. - Supports secure data processing in untrusted environments. - Cryptographically provable privacy guarantees. | - Encrypted data cannot be easily worked with if previously unknown to the user. - Complexity of encryption and decryption operations. - Performance overhead for cryptographic operations. - May require specialized libraries and expertise. | - Basic data analytics in cloud computing environments. - Privacy-preserving machine learning on sensitive data. |
| 8 | Federated Learning | Trains machine learning models across decentralized edge devices or servers holding local data samples, avoiding centralized data sharing. | - Preserves data locality and privacy, reducing data transfer. - Supports collaborative model training on distributed data. - Suitable for privacy-sensitive applications. | - Complexity of coordination among edge devices or servers. - Potential communication overhead. - Ensuring model convergence can be challenging. - Shared models can still leak privacy. | - Healthcare institutions collaboratively training disease prediction models. - Federated learning for mobile applications preserving user data privacy. - Privacy-preserving AI in smart cities. |
| 9 | Synthetic Data Generation | Creates artificial data that mimics the statistical properties of the original data while protecting privacy. | - Strong privacy protection with high data utility. - Preserves data structure and relationships. - Scalable for generating large datasets. | - Accuracy and representativeness of synthetic data may vary depending on the generator. - May require specialized algorithms and expertise. | - Sharing synthetic healthcare data for research purposes. - Synthetic data for machine learning model training. - Privacy-preserving data sharing in financial analysis. |
| 10 | Secure Multiparty Computation (SMPC) | Enables multiple parties to jointly compute functions on their private inputs without revealing those inputs to each other, preserving privacy. | - Strong privacy protection for collaborative computations. - Suitable for multi-party data analysis while maintaining privacy. - Offers security against collusion. | - Complexity of protocol design and setup. - Performance overhead, especially for large-scale computations. - Requires trust in the security of the computation protocol. | - Privacy-preserving data aggregation across organizations. - Collaborative analytics involving sensitive data from multiple sources. - Secure voting systems. |
The best and the worst data anonymization approaches
When it comes to choosing the right data anonymization approach, we are faced with a complex problem requiring a nuanced view and careful consideration. When we put all the Schmäh aside, choosing the right data anonymization strategy comes down to balancing the so-called privacy-utility trade-off.

The privacy-utility trade-off refers to the balancing act of data anonymization’ two key objectives: providing privacy to data subjects and utility to data consumers. Depending on the specific use case, the quality of implementation, and the level of privacy required, different data anonymization approaches are more or less suitable to achieve the ideal balance of privacy and utility. However, some data anonymization approaches are inherently better than others when it comes to the privacy-utility trade-off. High utility with robust, unbreakable privacy is the unicorn all privacy officers are hunting for, and since the field is constantly evolving with new types of privacy attacks, data anonymization must evolve too.
As it stands today, the best data anonymization approaches for preserving a high level of utility while effectively protecting privacy are the following:
Synthetic Data Generation
Synthetic data generation techniques create artificial datasets that mimic the statistical properties of the original data. These datasets can be shared without privacy concerns. When properly designed, synthetic data can preserve data utility for a wide range of statistical analyses while providing strong privacy protection. It is particularly useful for sharing data for research and analysis without exposing sensitive information.
Privacy: high
Utility: high for analytical, data sharing, and ML/AI training use cases
Homomorphic Encryption
Homomorphic encryption allows computations to be performed on encrypted data without the need to decrypt it. This technology is valuable for secure data processing in untrusted environments, such as cloud computing. While it can be computationally intensive, it offers a high level of privacy and maintains data utility for specific tasks, particularly when privacy-preserving machine learning or data analytics is involved. Depending on the specific encryption scheme and parameters chosen, there may be a trade-off between the level of security and the efficiency of computations. Also, increasing security often leads to slower performance.
Privacy: high
Utility: can be high, depending on the use case
Secure Multiparty Computation (SMPC)
SMPC allows multiple parties to jointly compute a function over their private inputs without revealing those inputs to each other. It offers strong privacy guarantees and can be used for various collaborative data analysis tasks while preserving data utility. SMPC has applications in areas like secure data aggregation and privacy-preserving collaborative analytics.
Privacy: High
Utility: can be high, depending on the use case
Data anonymization tools: the saga continues
In the ever-evolving landscape of data anonymization strategies, the journey to strike a balance between preserving privacy and maintaining data utility is an ongoing challenge. As data grows more extensive and complex and adversaries devise new tactics, the stakes of protecting sensitive information have never been higher.
Legacy data anonymization approaches have their limitations and are increasingly likely to fail in protecting privacy. While they may offer simplicity in implementation, they often fall short in preserving the intricate relationships and structures within data.
Modern data anonymization tools, however, present a promising shift towards more robust privacy protection. Privacy-enhancing technologies have emerged as powerful solutions. These tools harness encryption, machine learning, and advanced statistical techniques to safeguard data while enabling meaningful analysis.
Furthermore, the rise of synthetic data generation signifies a transformative approach to data anonymization. By creating artificial data that mirrors the statistical properties of the original while safeguarding privacy, synthetic data generation provides an innovative solution for diverse use cases, from healthcare research to machine learning model training.
As the data privacy landscape continues to evolve, organizations must stay ahead of the curve. What is clear is that the pursuit of privacy-preserving data practices is not only a necessity but also a vital component of responsible data management in our increasingly vulnerable world.
At MOSTLY AI we talk about data privacy a lot. And we were even the first in the world to produce an entire rap dedicated to data privacy!
But what really is data privacy? And what is it not? This blog post aims to provide a clear understanding of the definition of data privacy, its importance, and the various measures being taken to protect it.
The data privacy definition
Data privacy, also referred to as information privacy or data protection, is the concept of safeguarding an individual's personal information from unauthorized access, disclosure, or misuse. It entails the application of policies, procedures, and technologies designed to protect sensitive data from being accessed, used, or shared without the individual's consent.
To fully understand data privacy we thus need to understand Personal information first. Personal information, often referred to as personally identifiable information (PII), is any data that can be used to identify, locate, or contact an individual directly or indirectly.
Personal information encompasses a wide range of data points, including but not limited to, an individual's name, physical address, email address, phone number, Social Security number, driver's license number, passport number, and financial account details. Moreover, personal information can extend to more sensitive data such as medical records, biometric data, race, ethnicity, and religious beliefs. In the digital realm, personal information may also include online identifiers like IP addresses, cookies, or device IDs, which can be traced back to a specific individual.
In essence, data privacy is all about the protection of personal information. Why is that important?
Why is data privacy important?
Even if you don’t care about data privacy at all, the law cares. With numerous data protection regulations and laws in place, such as the General Data Protection Regulation (GDPR) in the European Union, it is essential for organizations to adhere to these regulations to avoid legal consequences. Gartner predicts that by 2024, 75% of the global population will have its personal data covered under privacy regulations.
Many companies have realized that data privacy is not only a legal requirement, but something customers care about too. In the Cisco 2022 Consumer Privacy Survey, 76 percent of respondents said they would not buy from a company who they do not trust with their data. Ensuring data privacy helps maintain trust between businesses and their customers and can become an important competitive differentiation.
Data privacy is an important element of cybersecurity. Implementing data privacy measures often leads to improved cybersecurity, as organizations take steps to safeguard their systems and networks from unauthorized access and data breaches. This helps to ensure that sensitive personal information such as financial data, medical records, and personal identification details are protected from identity theft, fraud, and other malicious activities.
And in case you’re still not convinced, how about this: The right to privacy or private life is enshrined in the Universal Declaration of Human Rights (Article 12) – data privacy is a Human Right! Data privacy empowers individuals to have control over their personal information and decide how it is used, shared, and stored.

How to protect data privacy in an organization?
Every company, every business is collecting and working with data. To ensure data privacy there is not one thing that a company needs to do, but many things.
Foremost data privacy needs to start from the top in an organization because leadership plays a critical role in establishing a culture of privacy and ensuring the commitment of resources to implement robust data protection measures. When executives and top management prioritize data privacy, it sends a clear message throughout the organization that protecting personal information is a fundamental aspect of the company's values and mission. This commitment fosters a sense of shared responsibility, guiding employees to adhere to privacy best practices, comply with relevant regulations, and proactively address potential risks.
Once the support from the top management is established, data privacy needs to be embedded in an organization. This is typically achieved through implementing privacy policies. Organizations should have clear privacy policies outlining the collection, use, storage, and sharing of personal information. These policies should be easily accessible and comprehensible to individuals.
These policies define certain best practices and standards when it comes to data privacy. Companies that take data privacy seriously follow these, for example:
- Data minimization: Collecting only the necessary data for the intended purpose, and not retaining it longer than required, helps reduce the risk of unauthorized access or misuse.
- Data anonymization: Data anonymization is the process of removing or obfuscating personally identifiable information from datasets. The goal of data anonymization is to protect the privacy of individuals whose data is included in the dataset. Anonymized data can be shared more freely than non-anonymized data, as the risk of exposing sensitive information is greatly reduced.
- Encryption: Encrypting sensitive data ensures that even if unauthorized access occurs, the information remains unreadable and unusable.
- Access control: Implementing strict access control measures, such as strong passwords and multi-factor authentication, helps prevent unauthorized individuals from accessing sensitive data.
An entire industry around best practices and how these can be ensured (and audited!) has emerged.: Regularly auditing and monitoring data privacy practices within an organization helps identify any potential vulnerabilities and rectify them promptly.
The two most recognized standards and audits are ISO 27001 and SOC 2. ISO 27001 is a globally recognized standard for information security management systems (ISMS), providing a systematic approach to managing sensitive information and minimizing security risks. By implementing and adhering to ISO 27001, organizations can showcase their dedication to maintaining a robust ISMS and assuring stakeholders of their data protection capabilities.
On the other hand, SOC 2 (Service Organization Control 2) is an audit framework focusing on non-financial reporting controls, specifically those relating to security, availability, processing integrity, confidentiality, and privacy. Companies undergoing SOC 2 audits are assessed on their compliance with the predefined Trust Services Criteria, ensuring they have effective controls in place to safeguard their clients' data.
By leveraging ISO 27001 and SOC 2 standards and audits, organizations can not only bolster their internal security and privacy practices but also enhance trust and credibility with clients, partners, and regulatory bodies, while mitigating risks associated with data breaches and non-compliance penalties. We at MOSTLY AI have heavily invested in this space and are certified under both ISO 27001 and SOC 2 Type.
Lastly, let’s turn to the human again: the employees. Numbers are floating around the Internet that claim to show that 95% of all data breaches happen due to human error. Although the primary source for this number could not be identified, it’s probably correct. Therefore, educating employees about data privacy best practices and the importance of protecting sensitive information plays a crucial role in preventing breaches caused by human error.
Data privacy is everyone's business
Data privacy is an essential aspect of our digital lives, as it helps protect personal information and maintain trust between individuals, businesses, and governments. By understanding the importance of data privacy and implementing appropriate measures, organizations can reduce the risk of data breaches, ensure compliance with data protection laws, and maintain customer trust. Ultimately, data privacy is everyone's responsibility, and it begins with awareness and education.
The protection of personally identifiable information (PII) has become an important concern in the data industry. As part of regular data-processing pipelines, datasets often need to be shared to be processed, for example with external clients or with cloud services for high-performance processing. During this process, it’s vital to ensure that sensitive information is not exposed. Data privacy compliance breaches can do serious harm to a company’s reputation and can result in high fines.
Data anonymization is a technique that can be used to protect personally identifiable information by removing or obfuscating sensitive data. Python is a popular programming language that can be used to perform data anonymization. In this article, we will explore four different techniques for data anonymization in Python: randomization, aggregation, masking, and perturbation.
Performing data anonymization in Python with open-source solutions can be a low-effort method for providing a basic level of privacy protection. However, there are important security tradeoffs to consider. While performing data anonymization in Python may be helpful in quick prototyping scenarios, these techniques are generally considered legacy data anonymization techniques that do not offer sufficient protection for data pipelines running in production. Fully synthetic data is the new industry-standard for production-grade data analysis.
What is data anonymization?
Data anonymization is the process of removing or obfuscating personally identifiable information from datasets. The goal of data anonymization is to protect the privacy of individuals whose data is included in the dataset. Anonymized data can be shared more freely than non-anonymized data, as the risk of exposing sensitive information is greatly reduced.
Data anonymization in Python techniques
There are several techniques that can be used for performing data anonymization in Python. These techniques include randomization, aggregation, masking, and perturbation.
1. Randomization
Randomization involves replacing sensitive data with random values. For example, a person's name might be replaced with a randomly generated string of characters.
Let’s look at how to perform data anonymization in Python using the randomization technique. We’ll start with something simple. We’ll use Python’s built-in random library together with pandas to scramble the characters in the Name column in an attempt to obscure the identities of the people in our dataset:
import pandas as pd
import random
# Load the dataset
df = pd.read_csv('sensitive_data.csv')
df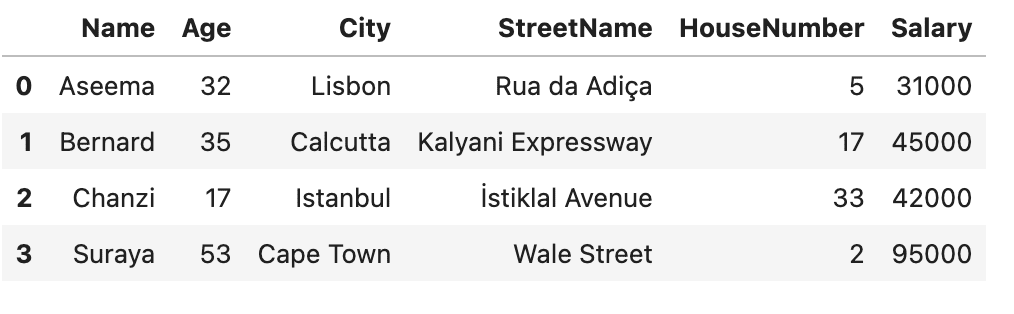
# define a function to randomize column values
def randomize_values(col_values):
col_values_list = list(col_values) # convert string to list
random.shuffle(col_values_list)
return ''.join(col_values_list) # convert list back to string
# apply the function to the desired column(s)
column_to_randomize = 'Name'
df[column_to_randomize].apply(randomize_values)
df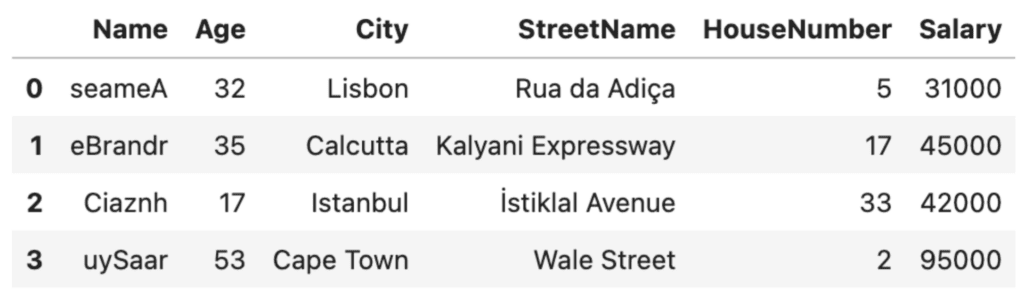
This is clearly a very rudimentary anonymization technique. The good thing about this technique: it’s quick. The bad thing: it may fool a third-grader…but not much more. The first letters of the names are still capitalized and from there, it’s not very hard to imagine what the real names might be, especially if someone has prior knowledge of the people in the dataset. Of even more concern is the fact that the addresses and ages are still clearly visible. We need to do better.
Let’s expand our randomize_values function to scramble all of the columns containing strings in our dataframe. We’ll use random.choices() instead of random.shuffle() to improve our anonymization:
import string
# define function that operates on entire dataframe
def randomize_values(df):
for column in df.columns:
if df[column].dtype == 'O': # check if column has object dtype
df[column] = [''.join(random.choices(string.ascii_letters + string.digits, k=10)) for _ in range(len(df))] # generate a list of random strings
return df
# apply function to dataframe
df_rand = randomize_values(df)
df_rand
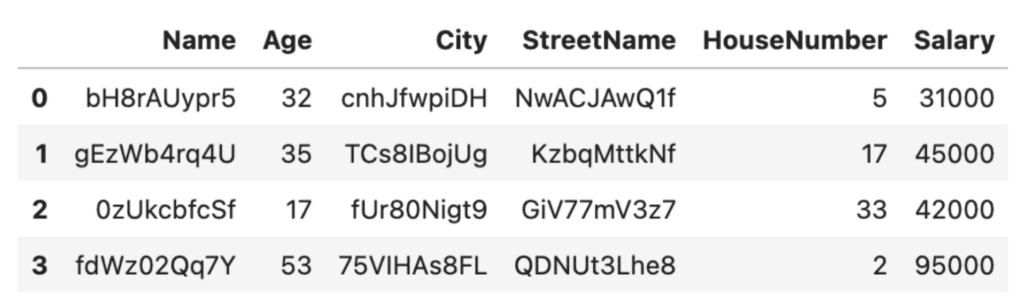
This is looking much better! The downside here is that it'll be easy to lose track of who's who this way. To help with this, it’s recommended practice to create a lookup table. We will give each row a unique identifier so that we can use that as a key to look up how the anonymized rows correspond to their original entries.
Let’s add a new row UniqueID to the original, non-scrambled DataFrame:
# add a new column with unique integer-only IDs
df['UniqueID'] = list(range(1001, 1005))
df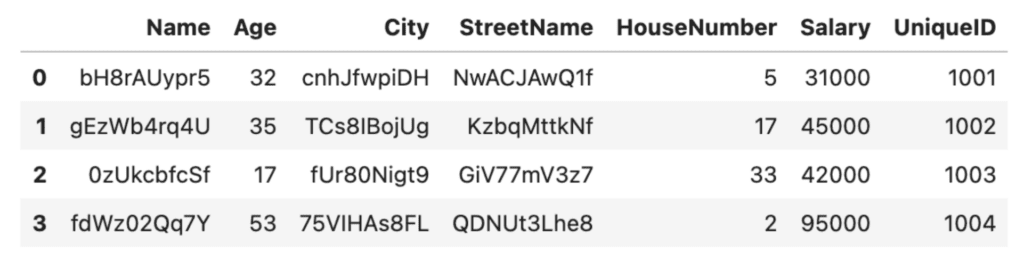
In this case, we chose to create a unique ID column of int data type so that our randomize_values function will not scramble it. For production purposes, you will probably want to build something a little more scalable and robust, for example using the Python uuid library.
We can now apply randomize_values again to get the anonymized rows with the unique IDs.
# apply function to dataframe
df_rand = randomize_values(df)
df_rand
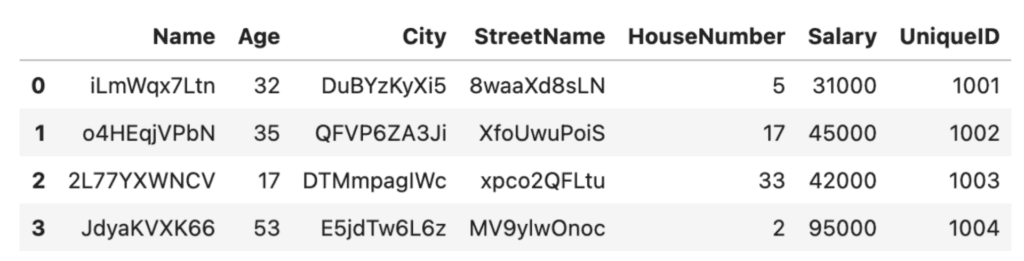
Randomization is a relatively low-effort method to perform data anonymization in Python. It’s important to note, however, that this low-effort benefit comes with some serious tradeoffs. First of all, the data utility has decreased significantly: it’s hard to imagine running any meaningful analysis on top of the scrambled City names, for example. Secondly, there are tradeoffs to consider in terms of robustness and security. For example, if a dataset contains a small number of unique values, it may be possible to use statistical analysis to identify individuals based on the random values.
Let’s now look at a second technique for performing data anonymization in Python: aggregation.
2. Aggregation
Aggregation involves combining data from multiple individuals to create a group-level view of the data. For example, instead of storing data for each individual separately, data might be aggregated into ranges or groups.
Let’s say we're happy with the randomization technique used above for hiding the names and addresses of the people in our dataset. However, we want to take our data anonymization one step further and also hide the numerical values. We can use Python to aggregate the numerical values, for example anonymizing the ages by grouping the individuals in our dataset into age brackets using the pandas .cut() method and specifying the bins and labels:
# Anonymize the ages by grouping them into age ranges
bins = [0, 18, 30, 45, 60, 100]
labels = ['0-18', '19-30', '31-45', '46-60', '60+']
df['Age'] = pd.cut(df['Age'], bins=bins, labels=labels)
df
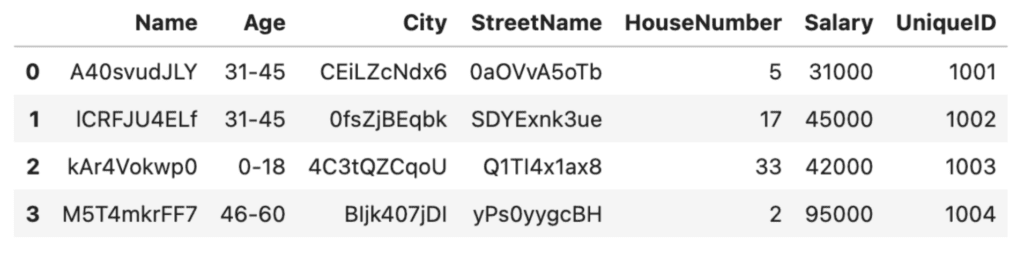
We can do something similar with the salaries:
# Anonymize the salaries by grouping them into ranges
bins = [0, 30_000, 50_000, 80_000, 100_000, 200_000]
labels = ['0-30K', '31-50K', '51-80K', '81-100K', '100K+']
df['Salary'] = pd.cut(df['Salary'], bins=bins, labels=labels)
df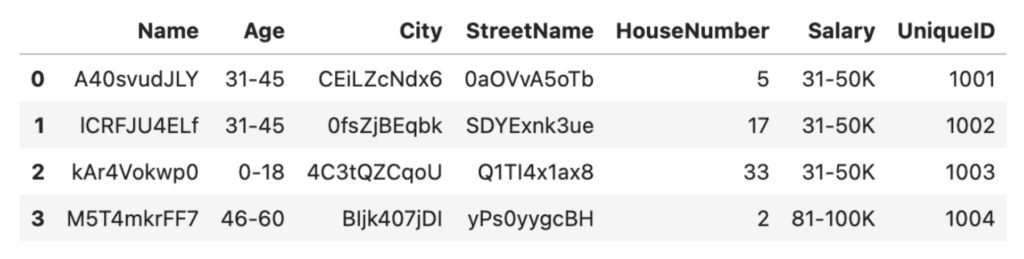
Excellent, it's now no longer possible to get any personally identifiable age or salary characteristics from our anonymized dataset. This was a relatively simple technique to achieve data anonymization. However, we've traded it for a significant amount of granularity. In the Salary column, we now have only 2 unique values (31-50K and 81-100K) instead of the original four. This reduces the types of analysis we can run on this dataset, decreasing its data utility.
There are many other ways to achieve anonymization by aggregation in Python, for example using groupby(). The important thing to remember is that while aggregation is technically an effective technique for data anonymization, it may often not be a feasible solution for your use case, especially if your analysis requires specific levels of data granularity.
3. Masking
The third technique for performing data anonymization in Python is masking. Masking involves replacing sensitive data with a similar but non-sensitive value. For example, a person's name might be replaced with their initials or a pseudonym.
In the randomization example above, we replaced people's names, cities, and street names with random characters. This is an effective anonymization technique (provided you have created a correct and securely-stored lookup table) but can make the dataset less intuitive to work with. If humans are going to be part of the data analysis process, you may want to use an anonymization technique where the anonymized contents still indicate something about the type of information they contain. Pseudonyms can be helpful for this.
Let's take a look at some Python code that uses masking to anonymize the names, cities, and street names in our dataset:
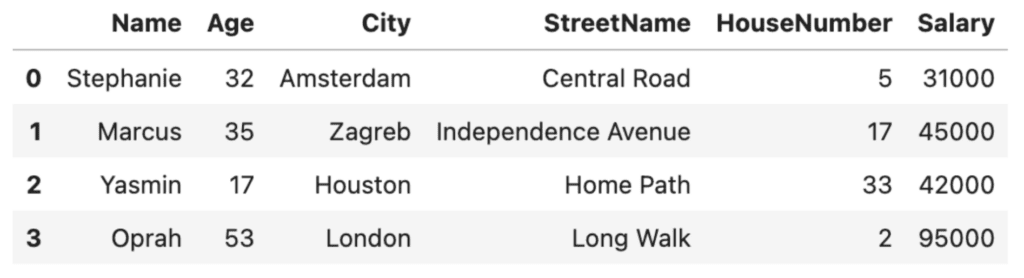
# take a look at the original dataset
df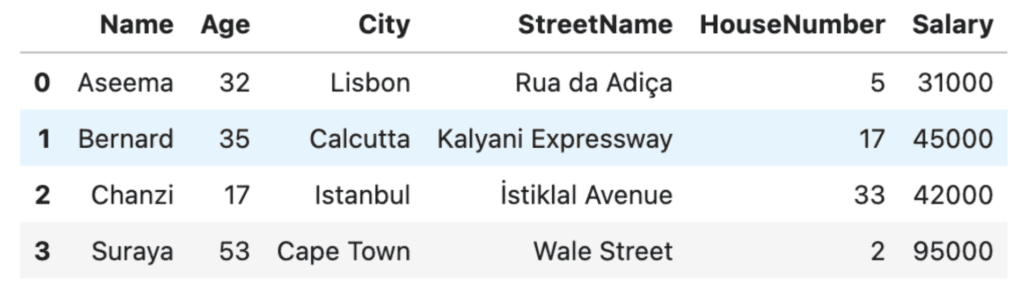
# mask the sensitive values by using pseudonyms for the names, cities and street names
masked = df.copy()
masked['Name'] = ['Stephanie', 'Marcus', 'Yasmin', 'Oprah']
masked['City'] = ['Amsterdam', 'Zagreb', 'Houston', 'London']
masked['StreetName'] = ['Central Road', 'Independence Avenue', 'Home Path', 'Long Walk']
masked
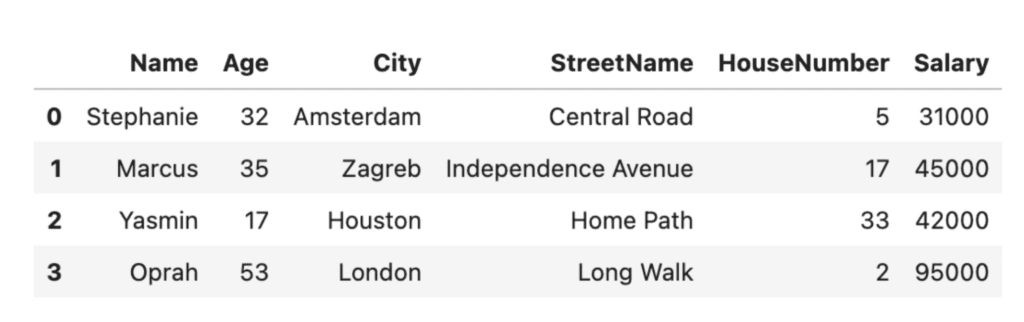
Masking can be an effective technique for data anonymization, but it may not always provide sufficient protection. If the masked value is still unique to an individual, it may be possible to use statistical analysis to identify them. It’s also important to note that pseudonymization alone is not GDPR-compliant.
Masking can also be difficult to perform programmatically. In the code above, we manually entered the alternative values. This is feasible for a small toy dataset with 4 rows, but imagine having to come up with and type out pseudonyms for a dataset containing millions of rows (!) Unless you can find a programmatic way to mask the data, masking may mean trading in efficiency for human legibility.
There are open-source Python libraries available that help you to perform this type of masking programmatically. One example is anonymizedf, which builds on pandas and faker to easily substitute original columns with masked substitutes. We’ll walk through a quick example below:
from anonymizedf.anonymizedf import anonymize
# prepare data for anonymization
an = anonymize(df)
# add masked columns
fake_df = (
an
.fake_names("Name", chaining=True)
.fake_whole_numbers("Salary", chaining=True)
.fake_whole_numbers("Age", chaining=True)
.fake_categories("City", chaining=True)
.fake_whole_numbers("HouseNumber", chaining=True)
.show_data_frame()
)
# subset only anonymized columns
fake_df = fake_df[['Fake_Name', 'Fake_Salary', 'Fake_Age', 'Fake_City', 'Fake_HouseNumber', 'StreetName']]
fake_df
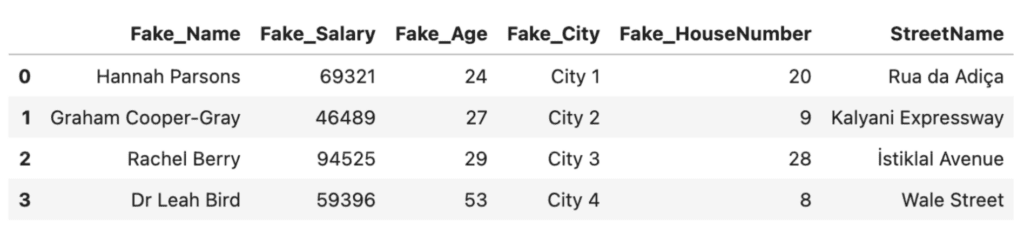
Anonymizedf and Faker are helpful open-source solutions that can help you perform data anonymization in Python. However, they also have their drawbacks. Being open-source, there are security risks associated with using these solutions on production data. The solutions are also limited in their flexibility: the an.fake_whole_numbers method, for example, simply outputs random integers between the lowest and highest value found in the original column. There is no way to control the distribution of the values in that column which is important for downstream machine-learning and other analysis projects, as we’ll see in the next section.
4. Perturbation
The fourth and final technique for performing data anonymization in Python is perturbation. Perturbation involves adding random noise to sensitive data to make it harder to recognize. For example, a person's salary might be increased or decreased by a small amount to protect their privacy. The amount of noise added can be adjusted to balance privacy with data utility. Data utility is generally a function of how well we can preserve the overall distribution in the dataset.
Perturbation is generally only used for numerical and categorical columns. Let's take a look at an example of performing perturbation on a numerical column in Python. We'll write a function called add_noise that will use the numpy library to add noise to the Salary column. The amount of noise can be controlled using the std (standard deviation) keyword argument.
import numpy as np
def add_noise(df, column, std = None):
if std == None:
std = df[column].std()
withNoise = df[column].add(np.random.normal(0, std, df.shape[0]))
copy = df.copy()
copy[column] = withNoise
return copy
perturbation = add_noise(df, 'Salary', std=100)
perturbation
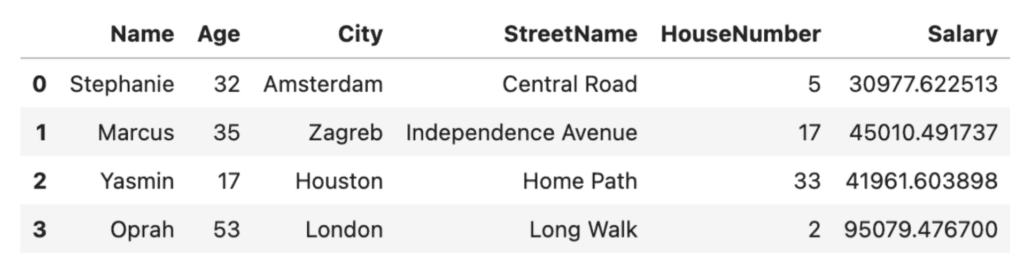
If we compare this to our original Salary values, we’ll see a minor deviation. This will likely preserve the original distribution of the dataset, but is it enough to guarantee the privacy of the individuals in our dataset? Probably not.
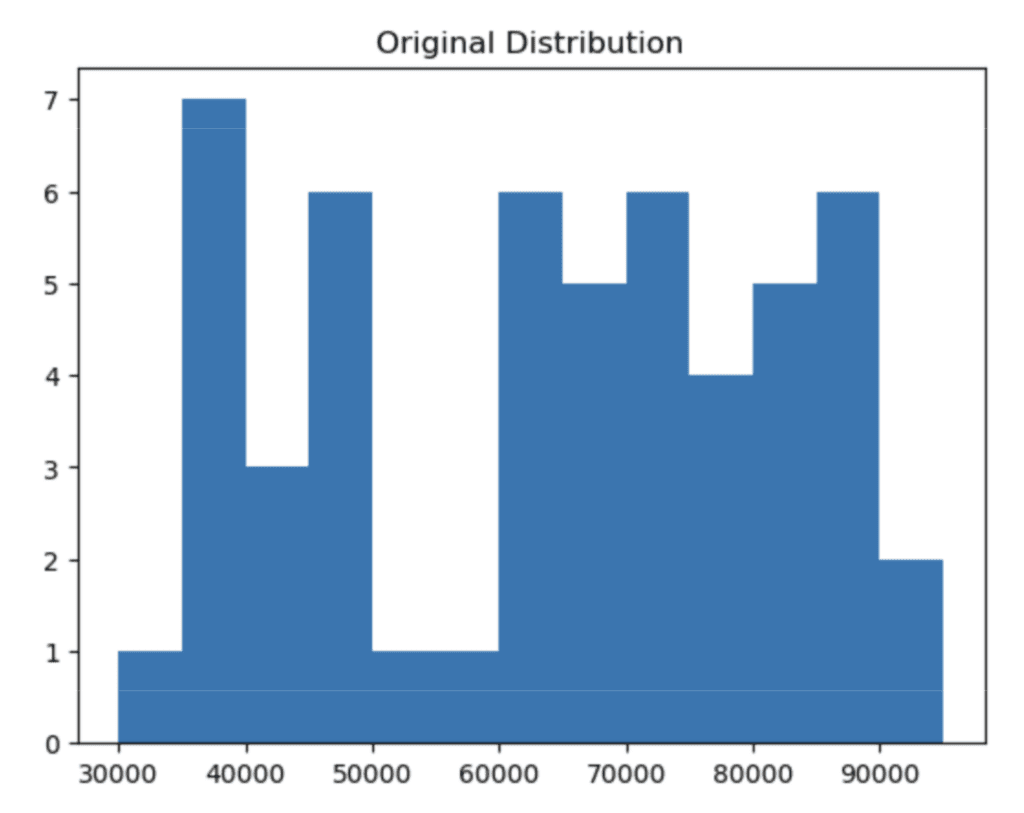
A toy dataset with 4 rows is not enough data to observe the effect of perturbation on the dataset’s distribution. Let’s work with a slightly larger fictional dataset that has 60 rows of data. This will allow us to clearly see the tradeoff of privacy (perturbation) and accuracy (data utility). For reproducibility of the code in this tutorial, we’ll create a larger DataFrame by simply copying the original df 15 times.
# create a large dataset
df_large = pd.concat([df, df, df, df, df, df, df, df, df, df, df, df, df, df, df])Let’s plot a histogram of the original Salary column:
# plot the distribution of the salary column using 5K bins
plt.hist(
'Salary',
data=df_large,
bins = np.arange(start=30_000, stop=100_000, step=5_000),
)
plt.title(“Original Distribution”);
Now apply our add_noise function with varying degrees of noise:
df_large_pert_10 = add_noise(df_large, 'Salary', std=10)
df_large_pert_100 = add_noise(df_large, 'Salary', std=100)
df_large_pert_2000 = add_noise(df_large, 'Salary', std=2000)And then visualize the distributions with noise:
fig, (ax1,ax2,ax3,ax4) = plt.subplots(nrows=1, ncols=4, sharey=True, figsize=(20,10))
ax1.hist(
'Salary',
data=df_large,
bins = np.arange(start=30_000, stop=100_000, step=5_000),
)
ax1.title.set_text('Original Distribution')
ax2.hist(
'Salary',
data=df_large_pert_10,
bins = np.arange(start=30_000, stop=100_000, step=5_000),
)
ax2.title.set_text('With Noise - std=10')
ax3.hist(
'Salary',
data=df_large_pert_100,
bins = np.arange(start=30_000, stop=100_000, step=5_000),
)
ax3.title.set_text('With Noise - std=100')
ax4.hist(
'Salary',
data=df_large_pert_2000,
bins = np.arange(start=30_000, stop=100_000, step=5_000),
)
ax4.title.set_text('With Noise - std=2000')
;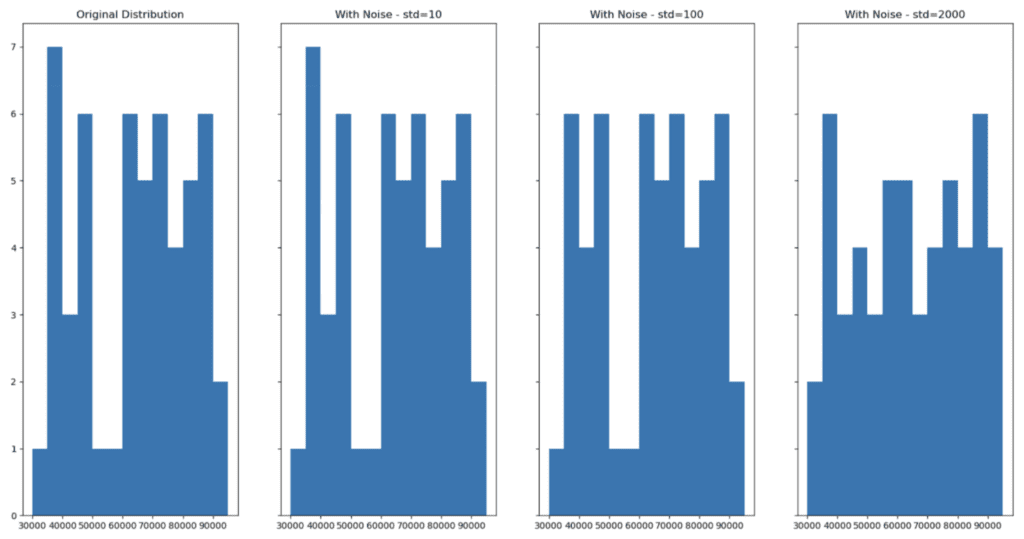
As we can see, adding noise (increasing privacy) can lead to a change in the distribution of the dataset (decreasing accuracy). Finding the perfect balance where privacy is ensured and accuracy is maintained is a difficult task to execute manually.
Automate data anonymization with MOSTLY AI
MOSTLY AI offers a fully-managed, no-code service for performing data anonymization. You can generate fully anonymized, synthetic datasets that maintain the distributions of your original dataset, striking that sweet spot between guaranteed privacy and maximum data utility. It offers built-in AI recognition of all data types and provides you with detailed reports to inspect both the utility (accuracy) and security (privacy) of your synthetic data. It takes into account any correlations between columns (both within and between related tables) and can automatically perform data augmentation techniques like imputation and rebalancing. Give it a try by signing up for a free account, we give you 100K rows of synthetic data for free, every day.
Data anonymization in Python: conclusion
Data anonymization is a critical step in protecting sensitive data and ensuring compliance with data privacy regulations. While Python provides libraries that can be leveraged to perform data anonymization. As we have seen in this blog, each of the four techniques presented also has serious drawbacks. They all require manual coding (and are thus sensitive to human error) and in many cases don’t actually provide the necessary level of privacy protection. That’s why performing data anonymization yourself, for example in Python, is generally considered to be a legacy technique that is not suitable for production environments.
Synthetic data anonymization is one of the core generative AI use cases for tabular data. Synthetic data provides solid guarantees about security and privacy protection. This type of data is completely made up and therefore contains virtually no risks of exposing any sensitive information from the original dataset. Powerful deep learning algorithms extract characteristic patterns, correlations and structures from the original dataset and use that to generate data that is entirely synthetic. As data privacy regulations continue to evolve, it is essential to stay up-to-date with the latest techniques and best practices for data anonymization. By doing so, you can ensure that your data is protected, and your business remains compliant. If you don’t want to worry about the risks of performing your data anonymization manually, consider giving MOSTLY AI a try and let us know how you get on!
Download your guide to data anonymization!
What is data value?
The value of data is easy to see, right? For us data nerds, the answer is an emphatic yes. While this may be true, it is not always the case for everyone within your organization. Data is used to understand and improve business processes. This increases operational efficiency. Ultimately, it drives revenue, saves time and saves money. How much more clear could the business value be?
Unfortunately, there are many factors that contribute to the perceived and actual effectiveness of data within organizations. In a statista report that covers the leading challenges of using data to drive business value, we see a wide variety of results. These can be categorized into two main buckets, which will be discussed in depth:
- Data challenges
- Organizational/cultural challenges
Outside of these challenges, organizations are also tasked with splitting their time on data defense and data offense. Both are necessary for high data performance. Both are also going to impact the way that organizations see the value of their data.
There is a lot at stake here. The data value problem is complex, with multiple different dimensions - from a growing necessity to protect data privacy, to the impact this protection has on data quality. It is also a problem born from the unlimited potential impact that data can have on an organization's profits, innovation, efficiency, and additional revenue streams. Changes to data management made at the top, are going to have major implications downstream. Prioritization of data strategies/goals is going to be necessary. This is an important conversation that is being had by many organizations around the world, and is one that MOSTLY AI is dedicated to being a part of.
So… where does this conversation begin? Below are the questions, insecurities, and important topics we hear most often from clients and prospects.
Data defense: the foundation of responsible and effective data usage
Data defense is a strategic approach to data management that aims to “ensure data security, privacy, integrity, quality, regulatory compliance, and governance”. This is a huge umbrella that encompasses multiple business functions and c-level positions. It also reflects the emphasis that organizations are placing on a strong defensive strategy. This emphasis comes from two main sources - higher levels of risk with data breaches, and increasing amounts of data privacy protection legislation. In 2019, the average total cost of a data breach was $3.92 million USD. This cost includes liability for the damages - more specifically, the cost of patching the vulnerability, compensating victims for damages, and expenses related to litigation. It also includes costs associated with the negative impacts on customer trust and brand reputation. This is a massive potential hit, which is why such great measures are being taken to avoid it. Finally, according to Gartner, over 75% of the world's population will have its personal data covered under modern privacy regulations. The necessity of strong data defense today is only going to be heightened as data breaches continue to grow and evolve, and as legislation expands around the globe to protect personal data.
The complexity of data defense brings with it many challenges in demonstrating the business value of data. The data challenges include data quality issues, managing compliance, and not knowing what data exists. The organizational challenges include data access, data sharing capabilities, and data cohesion across multiple different functions. These challenges manifest themselves as regulatory violations, a lack of performance in data driven projects due to data quality issues, lengthy wait times on data which stalls progress on these projects, disorganization internally, and frustration felt at all levels within the organization.
Clearly many organizations, especially those in industries that contain high levels of PII/PHI (Personal Identifiable Information/Personal Health Information), are going to be spending a lot of time and resources on data defense. This time, energy, money, and employee allocation will need to clearly indicate the business value being added in this space. In order to do so, answers to the challenges mentioned above have to exist.
While there is no one answer to solve these problems, MOSTLY AI is working to drive business value while simultaneously easing the burden of the data/organizational challenges that are prevalent inside so many organizations.
The most common data challenges
Data challenges are felt across many different job functions that handle the data stored internally. In order to manage data compliance, privacy protection is an absolute necessity. Right now, “more than 70% of employees have access to data they should not”. Traditional methods of anonymization which are commonly used (data masking, permutation, randomization, and generalization) are not fully effective in guaranteeing privacy protection, and also have major negative implications on the quality of the data afterwards. This has an impact on the downstream tasks that rely on the integrity of the original data in order to perform up to expectations.
MOSTLY AI's synthetic data generator allows for a safer, smarter, and faster way of protecting sensitive data. While guaranteeing zero risk of re-identification, our synthetic data is also able to maintain a very high degree of accuracy of the original data which it is created from. This means that the data looks, feels, and behaves the exact same way as the original data, without any risk of compliance violations. It means that synthetic data used downstream will meet/exceed expectations.
Organizational challenges across industries
Organizational challenges are also felt amongst the entirety of the organization that works with data. According to Harvard Business Review, “Cross-industry studies show that, on average, less than half of an organization’s structured data is actively used in making decisions”. This speaks to the highly prevalent issue that organizations face in accessing data. Some of the contributing factors to this include lengthy approval processes for data sharing internally (due to data sensitivity), and a lack of understanding of what is in the data/what data is relevant to whom (due to data volume). Another big challenge here are the organizational silos which contribute to a lack of data cohesion.
While there are many different potential solutions, it is essential that synthetic data is relied upon to ease the burden of these problems. At MOSTLY AI, one of our main use cases is enhanced data sharing capabilities. Due to the fact that synthetic data is completely privacy safe, the approval processes for sharing data internally are vastly simplified. This not only allows everyone within the organization to access the same high quality data, but it allows them to do so quicker. Having fully accessible data also will have a massive impact on the ability for organizations to become cohesive in their data strategy and utilization.
How to demonstrate data value?
Demonstrating value is possible within data defense. Once the burden of the challenges that make this difficult are eased, there is plenty of opportunity to add value. One of these ways is through increased operational efficiency, using MOSTLY AI generated synthetic data. As a result of more uniform, fully privacy safe data, accessing it will no longer take weeks to months. This data access does not only apply to the business unit or team that it originated in, but across the entire organization. Take, for example, Telefónica - a customer of ours who had large amounts of data locked away for use by the analytics team. After utilizing MOSTLY AI synthetic data generation, millions of records were able to be used in a GDPR-compliant way to power their analytics and AI projects. Examples like this carry so much power. This means that projects will not be stalled due to lack of relevant data or long wait times. Decreased time to data, and the implications of using this “real-time” data downstream, is something that can be measured and clearly demonstrated to the highest levels of leadership within the organization.
Value can also be seen in the reduction of risk associated with using synthetic data. How many of your downstream projects contain original production data? Looking at the number of data compliance violations (and the costs associated with them) that occurred both before and after utilizing synthetic data, will paint a clear picture for the value of your data from a risk reduction standpoint.
Another defensive activity is in protecting your organization against fraud, money laundering, theft, or other anomaly scenarios. Building analytical models to detect and inform your organization based on warning signals within customer data can result in significant cost savings, and credibility maintenance with your customers. These models help reduce false positives and detect new fraud/anomaly cases, but their performance is highly dependent on the quality of the training data. Using MOSTLY AI generated synthetic data - our customers can train models on fully private data without having to worry about compromising customers privacy.
Data offense: the driver of revenue, profitability, and customer satisfaction
When thinking about sports, everyone loves watching their team while they are on offense. It is where the magic happens, where the points are scored, and where they are able to get creative. This is also where data leadership within organizations gets excited. Data offense is absolutely essential for organizations in standing out from competition. It also plays a big role in allowing for growth, and making shareholders happy. As a result, there are a lot of eyes on the way organizations are using data offensively. On top of that, there are also growing expectations surrounding the business value that data can add.
Many of the challenges that organizations face in proving the business value of data that are seen in data defense can also be seen in data offense. If the challenges were not dealt with during defensive activities, organizations will have to deal with lack of high data quality, difficulty accessing relevant data, and low operational efficiency in their offensive efforts. These issues will impact the perceived value of an organization's data, but will also result in a loss of revenue/profit/customer satisfaction that could have been generated without them. This emphasizes the need to address these challenges, and to do so quickly.
Driving offense with synthetic data
Offense strategies consist of using data to support the business objectives of increased revenues, customer satisfaction, and profits. Each of these objectives requires rich analytics and smart/accurate models. As discussed previously, the success of these projects will depend on the data that is informing and empowering them. You could use unprotected, original data that carries major compliance violations with it. You could also use data that has lost referential integrity after the time consuming process of manual anonymization, masking, generalization, pseudonymization, etc. Unfortunately both of these strategies require compromise - you are either losing data quality (which is so vitally important to build smart/accurate models), or you can turn a blind eye to the privacy protection legislation that is only growing more prevalent and restricting.
MOSTLY AI recognizes that data can be an organization’s greatest asset. We also recognize that certain things shouldn’t be compromised when using data. Synthetic data allows for smart, safe, and powerful data usage by ensuring privacy protection without loss in data quality. Below are brief summaries of how organizations are currently using synthetic data to increase revenue, customer satisfaction, and profits.
Increase of revenue, customer satisfaction, and profits using synthetic data
Driving revenue with data has many different forms. It could be utilizing the data for marketing/sales insights that lead to increased customer acquisition, or the monetization of data. Our CEO, Tobi Hann, discusses a particular data monetization use case which highlights our unique data sharing capabilities to drive revenue.
Synthetic data also enables product teams to work with customer data that looks, feels, and behaves the exact same way as the original data, but in a privacy safe way. This results in the creation and deployment of highly personalized products and services for the end user. This can result in KPI’s that are very demonstrative of the value of the data in the form of lower customer churn and increased numbers of new customers won (i.e. higher customer satisfaction). More happy customers means more revenue.
Profitability is a goal that every organization shares. Higher profits can be achieved by analyzing data to optimize pricing which balances risk and profitability. Finding a maximum price point that does not drive customers away has to be done using high quality customer data. It also has to be done using highly accurate and smart models. Feeding these models with data that can be rebalanced, augmented, or downsampled, based on the scenario, enables increased performance. Higher profits, derived from data, will clearly demonstrate the value of that organization's data.
| Original or Traditionally Anonymized Data | AI-generated Synthetic Data | |
| Data Defense | Many potential compliance violations Long wait times for data access Data quality issues for downstream usage, after protection | No risk of compliance violations Data consistency across multiple business units Ability to enhance model performance for anomaly situations (fraud, laundering, theft, etc) |
| Data Offense | Either using non-protected or slightly dated data for offensive activities Low data quality has major implications (monetarily) on performance of offensive activities such as pricing models, or drawing insights from sales/marketing activities | Fully privacy safe and “real-time” data to enhance offensive activities Fully representative data with no decrease in data quality Customizable data in order to increase model performance based on the situation |
Don't compromise on value
Right now, organizations are having to compromise on either data quality or data privacy protection. The data quality is a must have, in order to enhance all downstream tasks. The data privacy protection is a must have in order to stay compliant in a world that is committed to protecting personal data.
MOSTLY AI generated synthetic data allows for data usage without compromise.
It is a tool that helps solve challenges organizations face in demonstrating the business value of their data.
It is a tool that helps that value shine even brighter.
It is a tool that can and should be used in both offensive and defensive data strategies.
It is a technological solution that encourages and facilitates a positive change in data culture and performance.
Policies are designed for far-reaching, societal-level impact. We expect them to be solidly evidence-based and data-driven. The pandemic highlighted how much we rely on (and that we oftentimes still lack) good quality data that is comprehensive and easy to access across nation, states, research groups and different institutions.
However, the status quo of data anonymization and data sharing, especially in healthcare and policy applications, severely limit the amount of information that can be retained. Finding better ways to collaborate on data without compromising privacy is key for policy makers, researchers and businesses across Europe. As part of this mission, the European Commission’s Joint Research Centre thoroughly looked into the opportunity AI-generated synthetic data presents for privacy-safe data use. They concluded with a very strong endorsement for synthetic data in their final report:
Synthetic data will be the key enabler for AI
- "[Synthetic data] can become the unifying bridge between policy support and computational models, by unlocking the potential of data hidden in silos; thus becoming the key enabler of AI in business and policy applications in Europe."
- "Resulting data not only can be shared freely, but also can help rebalance under-represented classes in research studies via oversampling, making it the perfect input into machine learning and AI models"
It is very cost efficient to use synthetic data for privacy protection
- "Synthetic data change[s] everything from privacy to governance"
- “Synthetic data eliminates the bureaucratic burden associated with gaining access to sensitive data"
- "among the privacy-preservation technique studies analysed, data synthesis gave the best price/effort ratio."
Synthetic data is a mature privacy enhancing technology (PET) that is ready to be deployed
- "Synthetic data have proven great potential and are the go-to methods ready to be deployed in real-life scenarios. Policy applications can now be researched and developed with little risk involved."
- "Commercial solutions still beat the available research and open source solutions by a huge margin at the time of writing."
- "A robust commercial solution for hierarchical data synthesis was offered by the company MOSTLY.AI to test the synthesis quality. The results, available in the accompanying archive both as a PDF report and CSV files with the data correlations, are impressive."
Synthetic data improves fairness, diversity and inclusion
- “...policy makers will have the opportunity to create radically new policy instruments based on more detailed less biased population data.”
- "policy support can embrace diversity by stopping averaging out, and thus marginalisation of under-represented minorities by shifting away from aggregate-level statistics; capture the full diversity within the population, and start coping with its complexity, rather than continue ignoring it."
Synthetic data facilitates open data, data democratization, and data literacy
- "Data democratization – a new type of Open Data would emerge from the shift towards the synthetic data"
- "synthetic data in policy making process will enable involvement of much broader communities [..] same goes for algorithmic governance"
- "Data literacy is today as what was computer literacy in 1990s. Synthetic data have potential to accelerate their learning path towards data-driven decision & policy making by making available data closer to the people’s perspective."
Why is not everyone in the EU using synthetic data (yet)?
With such strong proof for the maturity, quality and cost-efficiency of AI-generated synthetic data, it begs the question why not every European institution or private sector organization rich in sensitive data is using synthetic data yet? Particularly, as the European Commissions’s JRC report pointed out, that synthetic data not only helps with privacy protection, but also with accelerating AI adoption, democratizing data access, improving AI fairness and facilitating much-needed data literacy across Europe.
Looking at the EU Commission’s strategy for AI and their Digital Decade, this indeed seems to be an interesting question. According to their AI strategy, it’s the EU’s ambition to “become a global leader in developing cutting-edge, trustworthy AI” and to “ensur[e] that AI is human-centric”. But to ensure widespread adoption of AI amongst European institutions and businesses, it’s self-evident that broad access to high-quality, yet privacy-safe data is a necessity. The same holds true for two of the four main goals that the EU Commission set for itself as part of their Digital Decade. One is the digital transformation of businesses, the other a “digitally skilled population and highly skilled digital professionals”. But: a business that cannot quickly access and innovate with its data (while ensuring compliance with European data protection law) cannot digitally transform. And a European workforce, that cannot openly access granular data simply cannot become data literate, let alone highly digitally skilled.
Thus we at MOSTLY AI strongly support the call to action of the European Commission’s JRC on what shall be done next. "More important than focusing on how to synthesize data is:
- what can we achieve with the new data available at scale,
- how to convince data owners to unleash their coveted data to the broadest audience,
- and how to accommodate this massive new ability into the policy formulation and assessment." [formatting and bulletpoints by the author]
With synthetic data, the technology is already there. It’s mature, cost-efficient, accurate and ready to be deployed. What is left to do by policy makers, if they really want the EU to excel on its path towards digital transformation and widespread development and adoption of human-centric, trustworthy AI, is to open up the access to data - and AI-generated synthetic data will be the single-most valuable tool to help the regulators to do that.
What if the EU would use open synthetic data to fight cancer?
Synthetic images are already playing a crucial role in the training of computer vision models designed to detect tumors and cancer cells. Just like synthetic tabular data, synthetic images can improve the accuracy of AI-powered decision support tools dramatically. For example, Michigan Medicine's neurosurgery team increased the accuracy of their AI models from 68% to 96% with synthetic training data. How? Simply put, the more images the model can look at, the better it gets at detecting pathologies. Synthetic data generation allowed them to upsample the number of images available for model training.
What has been done using synthetic images can be extrapolated to other data types, such as structured tabular data. Rebalancing imbalanced datasets or using synthetic data to augment datasets can help improve model accuracy not just for cancer detection but also for other rare diseases or events, such as lockdowns, unusual energy consumption patterns or recessions.
Data sharing is also key here. Medical research is often plagued with the difficulty of sharing or obtaining large enough datasets where the correlations weren’t destroyed by old data anonymization techniques, like aggregation or data masking. Researchers in different countries should be able to work on the same data in order to arrive at the same conclusions, without endangering the privacy of patients.
To date, there is no open synthetic cancer dataset available in the EU that can be freely accessed by researchers and policymakers. But what if? What if the valuable raw data that was already collected about millions of European cancer patients would be synthesized and - for the very first time - made available to a broad group of researchers? Just imagine the advances in healthcare our society could achieve. With MOSTLY AI's synthetic data platform this can become a reality.
The EU Commission’s JRC used MOSTLY AI's synthetic data generator for synthetic cancer data - with impressive results
For their study on synthetic data, the Joint Research Center leveraged MOSTLY AI's synthetic data platform to train on half a million of real-world cancer records. They then generated 2 million highly accurate, yet truly anonymous synthetic cancer patient records. Chapter 6 of the report includes the details of their analysis. But to summarize in their own words, “the results [...] are impressive.”
“The resulting dataset has shown astonishing level of realism (are we looking at the original or the synthetic data?) while maintaining all the privacy test. Resulting data not only can be shared freely, but also can help rebalance under- represented classes in research studies via oversampling, making it the perfect input into machine learning and AI models.”
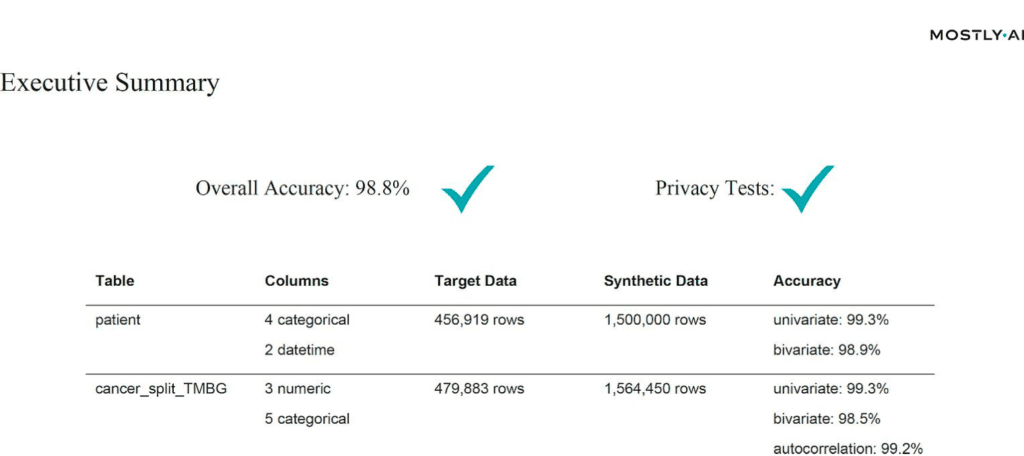
In particular, compared to an open-source alternative, MOSTLY AI could show its strength with its high level of automation. While the open-source solution required several person-months in an attempt to clean up the sample data, MOSTLY AI’s solution delivered out-of-the-box with top-in-class accuracy and rule adherence:
“Commercial solutions still beat the available research and open source solutions by a huge margin at the time of writing”
We are very proud to have created a synthetic data generator that stands up under such close scrutiny and are convinced that in the coming years synthetic data will be an even more valuable tool for policymakers - in the EU and beyond.
Privacy enhancing technologies protect data privacy in new ways. Legacy data anonymization techniques can no longer fully protect privacy. In their effort to mask or obfuscate data, legacy anonymization destroys data utility. As a result, these old technologies should not be considered to be privacy enhancing technologies or PETs.
Examples of privacy enhancing technologies
There are five major emerging privacy enhancing technologies that can be considered true PETs: homomorphic encryption, AI-generated synthetic data, secure multi-party computation, federated learning and differential privacy. These new generation privacy enhancing technologies are crucial for using personal data in safe ways.
Organizations handling sensitive customer data, like banks, are already using PETs to accelerate AI and machine learning development and to share data outside and across the organization. Most companies will end up using a combination of different PETs to cover all of their data use cases. Let's see how the five most promising privacy enhancing technologies work and when they come in handy!
1. Homomorphic encryption
Homomorphic encryption is one of the most well-known privacy enhancing technologies. It allows third parties to process and manipulate data in its encrypted form. In simple terms: someone who performs the analysis will never actually get to see the original data. But that's also one of the severe limitations of this technology. It's not helpful when the person who should do the analysis has no prior knowledge about the dataset as data exploration is virtually impossible.
Another limitation of homomorphic encryption is that it's incredibly compute-intensive and has restricted functionality. As a result, some queries are not possible on encrypted data. It's one of the least mature, but promising technologies when it comes to anti-money laundering and the detection of double fraud.
2. AI-generated synthetic data
AI-generated synthetic data is one of the most versatile privacy enhancing technologies. AI-powered synthetic data generators are trained using real data. After the training, the generator can create statistically identical but flexibly sized datasets. Since none of the individual data points match the original data points, re-identification is impossible.
The most popular synthetic data use cases include data anonymization, advanced analytics, AI and machine learning. The process of synthesization also allows for different data augmentation processes. Upsampling rare categories in a dataset can make AI algorithms more efficient. Subsetting large datasets into smaller, but representative batches is useful for software testing. Advanced synthetic data platforms offer statistically representative data imputation and rebalancing features. Since synthetic datasets do not maintain a 1:1 relationship with the original data, subjects are impossible to reidentify. As a result, it's not suitable for use cases where re-identification is necessary.
3. Secure multi-party computation
Secure multi-party computation is an encryption methodology. It allows multiple parties to collaborate on encrypted data. Similarly to homomorphic encryption, the goal here is to keep data private from participants in the computational process. Key management, distributed signatures, and fraud detection are some of the possible use cases here. The limitation of secure multi-party computation is the resource overhead. To pull off a SMPC stunt with success is pretty tricky - everything has to be timed right and processing has to happen synchronously.
4. Federated learning
Federated learning is a specific form of machine learning. Instead of feeding the data into a central model, the data stays on the device and multiple model versions are trained and operated locally. The result of these local trainings are model updates, which get fed back into and improve the central model. This decentralized form of machine learning is especially prevalent in IoT applications.
The training takes place on edge devices, such as mobile phones. Federated learning on its own doesn’t actually protect privacy, only eliminates the need for data sharing in the model training process. However, the fact that data isn’t shared doesn’t mean privacy is safe. The model updates in transitioning from the edge devices could also be hacked and leak privacy. To prevent this, federated learning is often combined with another PET, like differential privacy.
5. Differential privacy
Differential privacy is not as much a privacy-enhancing technology in itself, but a mathematical definition of privacy. Differential privacy quantifies the privacy leakage that occurs when analyzing a differentially private database. This measure is called the epsilon value. In an ideal world - or with an epsilon value of 0 - the result of said analysis wouldn’t differ no matter whether a given individual is present in the database or not.
The higher the epsilon the more potential privacy leakage can occur. In academia, epsilon values of below 1 are recommended to achieve strong anonymization. In practice, it’s still a challenge to determine a suitable epsilon value. This is important to keep in mind, as differential privacy does not automatically guarantee adequate privacy protection. It simply offers a mathematical guarantee for the upper boundary of potential privacy leakage. So getting the epsilon value set right is of utmost importance. It needs to be low enough to protect privacy, but not so low that the noise that has to be added to achieve this low epsilon value is diminishing data utility.
More often, privacy practitioners use it in combination with another PET, such as federated learning.
Which Privacy Enhancing Technology to use when?
Different privacy-enhancing technologies' benefits and limitations need to be weighed carefully. Some of them are more use case agnostic than others, but most organizations will have to invest in more than one PET to cover all use cases. Some legacy anonymization techniques might also have a place in the data tech stack as additional measures, but their use should be limited.
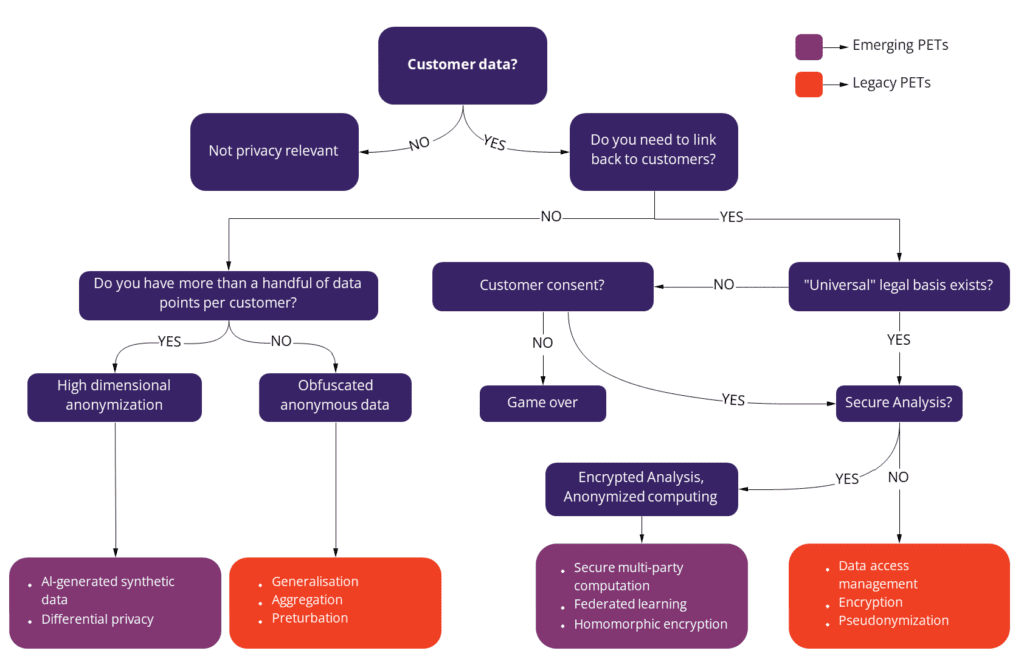
The synthetic data guide
If you would like to learn about adding AI-generated synthetic data to your privacy stack, download the complete guide with case studies!
A new, powerful breed of privacy attacks is emerging. One that uses AI to re-identify individuals based on their behavioral patterns. This advent has broad implications for organizations, both from compliance as well as from a risk perspective, as legacy anonymization measures are highly vulnerable. And it’s these risks that drive the surge in demand for privacy-preserving synthetic data, enabled by MOSTLY AI, as a safe and future-proof alternative - even against AI-based re-identification attacks.
The ineffectiveness of data masking
Modern-day privacy regulations, like GDPR and CCPA, consider a dataset to be anonymous, if none of the contained records can “reasonably” be re-identified, i.e. be linked to a natural person or a household. Given that, it is of critical importance to understand how re-identification works, and how it continues to evolve thanks to technological advancements (as is e.g. explicitly required by GDPR recital 26).
There used to be a time, not that long ago, where the masking of direct identifiers, like full names or social security numbers, was deemed to be sufficient to “anonymize” a dataset (see here for a more thorough historical perspective). But it is the simple composition of any of the remaining attributes that allows for the instant re-identification of individual subjects. While masking increases the effort to re-identify manually, and thus might look like an appropriate measure, it doesn’t make it any more difficult for computer-assisted attacks. It’s as simple as making a basic database query to successfully single out individuals within a huge sea of data.
One might even argue that pseudonymization techniques like masking and transformations are harmful, as it instills a false sense of security, leading organizations to risky data sharing practices. Due to an absence of direct identifiers, some individuals without privacy training, might wrongly assume that a redacted dataset is well protected, and share or process accordingly. Security, that is assumed to protect whereas it does not, is the worst possible kind, as it leads an organization to lower its guard.
But aside from lack of knowledge, there is certainly also an intentional ignorance of the problem, that can be encountered if privacy runs counter to commercial interest. Particularly by data brokers, organizations that resell insufficiently anonymized personal data, like mobility or browsing behavior to third parties. They bet on data protection authorities not enforcing the law, and/or on the broader public not caring enough, as they presumably lack the technical expertise. But one can tell that times are changing, if the New York Times, the Guardian, as well as your favorite Late Night host start to pick up the subject.

The well-established risk of linkage attacks
The previously described type of re-identification is also known as a linkage attack. Linkage attacks work by linking a not-yet-identified dataset (eg. a database of supposedly anonymous medical health records) with some easier-to-obtain auxiliary information on specific individuals (e.g. the day and time that a politician gave birth). The attack is then simply performed by looking for overlapping matches between the common attributes of these two sources of information. Once such a match is found, the direct identifiers can be attributed to the supposedly anonymous data records. In the previously stated example, finding a subject that gave birth at the same date and time as the politician, would then allow to attribute all the other medical records of that subject to the named politician - even though no direct identifiers were contained in the accessed database. Anyone with a basic knowledge of data querying techniques can perform such a “hack”, thus it is certainly “reasonably” likely to be performed by a malicious actor.
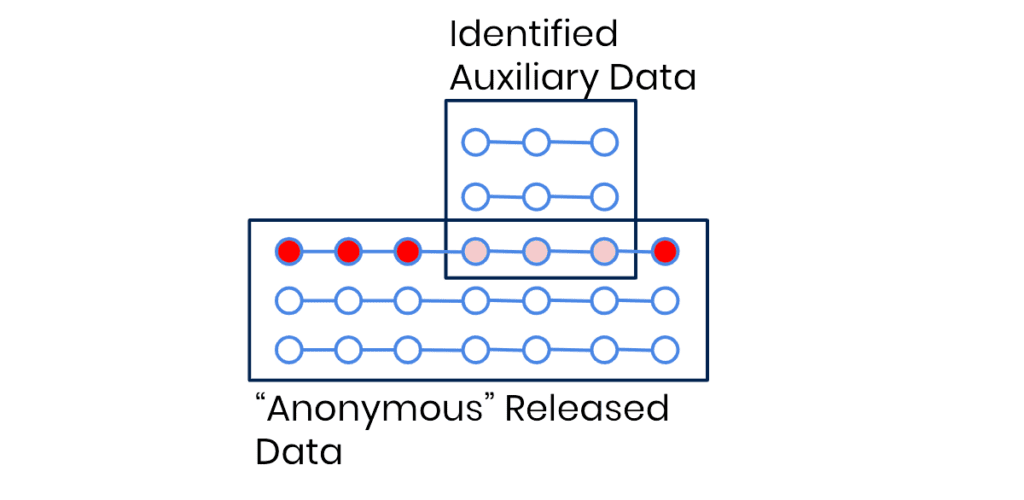
But linkage attacks are by far not only a concern for politicians and other prominent individuals in your customer database. They are similarly easy to perform on people like you and me. Other prominent examples of this type of attack include the re-identification of NY taxi trips, the re-identification of telco location data, the re-identification of credit card transactions, the re-identification of browsing data, the re-identification of health care records, and so forth. Also when turning towards the prominent case of re-identified Netflix users, we see a type of linkage attack being deployed. There the notable difference is, that Netflix had actually tried to prevent attacks by not only removing all user attributes, but also by adding random noise to obfuscate single records. However, as it turned out, these were all still ineffective, and a linkage attack based on fuzzy matches could be easily performed.
The new rise of powerful profiling attacks
Enter a new breed of even more capable privacy attacks, that leverage AI to re-identify individuals based on their behavioral patterns: profiling attacks. While conceptually it has been known that these types of profiling attacks are possible, their feasibility and ease of implementation has only recently been demonstrated in peer-reviewed papers. Firstly, and most prominently, by a group of leading privacy researchers, including Yves-Alexandre de Montjoye, from the Imperial College London in their recent Nature paper. There they showcase how to successfully re-identify call data records purely based on the implicit relationships between subjects, i.e. on the graph topology. Secondly, joint research by the Vienna University of Economics and Business and MOSTLY AI, demonstrated the applicability of the approach in their paper on re-identifying browsing patterns.
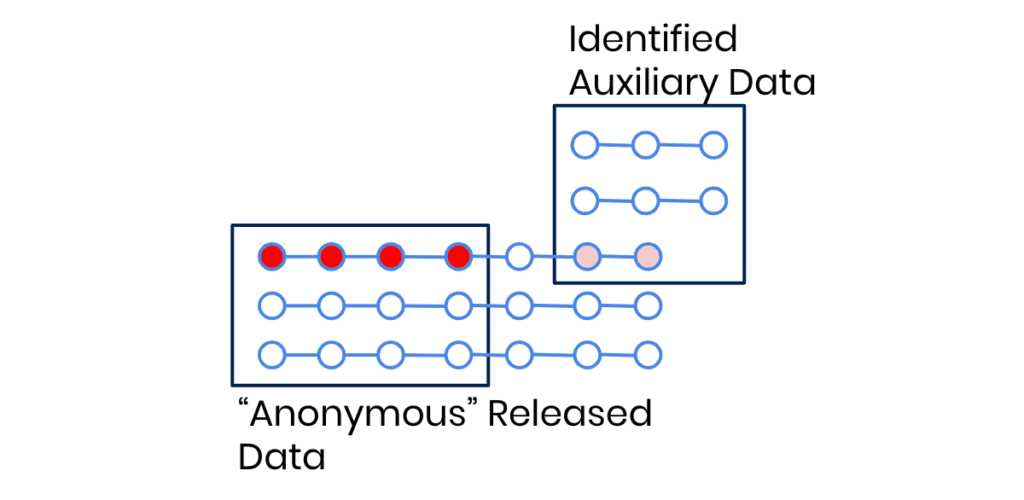
The basic idea is simple, and borrows from modern-day face recognition algorithms. An AI model is trained specifically for the re-identification of subjects, by tasking it to correctly match a randomly selected anchor sample (e.g., an image of Arnold Schwarzenegger) with any of two alternative samples, whereas only one stemmed from the same subject (i.e., another image of Arnold, plus one from a different actor). See Figure 4 for a basic illustration of the concept - for faces, for signatures, and for browsing behavior. In all of these applications the model has to learn to extract the characteristic traits, the uniquely identifying patterns, the “identifying fingerprint” of a data record, while disregarding any other irrelevant information. That characteristic information can then be distilled from any new data in the form of a numeric vector, which then allows to define a distance measure between records of individual subjects. Equipped with that, the profiling attack itself is subsequently as simple as looking for the nearest neighbor of the identified auxiliary data record within the not-yet-identified database.
What is truly remarkable and has a significant impact on the scope of privacy regulations is the efficiency of this methodology. Even though neither geographic, nor temporal, nor subject-level information, nor any overlapping event data have been available, the researchers were able to successfully re-identify the majority of subjects with a generic, domain-agnostic approach. One that works for re-identifying faces, signatures, as well as any sequence of tabular data. The authors further demonstrated the robustness of the method. Creţu et al. showed that the characteristic relations within call data records remained stable across several months, thus allowing re-identification based on data collected at a significantly later stage, casting major concerns on current data retention policies. And Vamosi et al., on the other hand, showed the robustness towards data perturbations. Even in cases where a third of the data points were completely randomly substituted, the re-identification algorithm found the correct match 27% of the time in a pool of thousands of candidates. Thus, the AI-based re-identification is shown to be highly robust against noise. If we expand the search to find matches within the Top 10 or Top 100 nearest neighbors, the success rate goes up significantly . This also means that just a single additional, seemingly innocuous data point - like age or zip code - will likely result in a perfect match once combined with the power of a profiling attack.
Synthetic data is immune to AI-based re-identification attacks
The three basic techniques applied by legacy anonymization solutions are 1) the removal of attributes, 2) the generalization of attributes, and 3) the obfuscation or transformation of attributes. However, by now we have arrived in an era where dozens, hundreds, if not thousands of data points are being gathered for each and every individual which together result in these unique digital fingerprints that make it ridiculously easy for AI to find matching behavioral patterns. The more attributes of an individual are captured, the more it stands out in today's high-dimensional data spaces. And it is due to this mathematical law of high dimensions, that any of these legacy anonymization methods fail to offer protection against linkage and profiling attacks unless they destroy almost the entirety of the contained information.
Thus, leading organizations, that recognize the business value of customer trust, stop the risky practice of transferring actual production data into non-production environments. The data of a customer shall ideally only be used for serving that actual customer. For all other purposes they start to break the susceptible 1:1 link to actual data subjects, and adopt statistically representative synthetic data at scale.
Yet, as we’ve also demonstrated before, synthetic data is not automatically private by design. It needs to be properly empirically vetted. The distance measure from the newly introduced AI-based profiling attacks now provides one of the strongest possible assessments of the privacy of synthetic behavioral data. And with that, it is shown that synthetic data by MOSTLY AI - thanks to its range of in-built privacy mechanisms - is truly privacy-preserving. And thus fully anonymous under GDPR, CCPA and in the strictest possible sense.
Hence, the news is out: The time for legacy anonymization is up and privacy-preserving synthetic data is the future. If you are ready to embark on that future, don’t hesitate to contact us, and we are happy to onboard you to MOSTLY AI - the leader in structured synthetic data.
Credits: The research collaboration between WU Wien and MOSTLY AI is supported by the "ICT of the Future” funding programme of the Austrian Federal Ministry for Climate Action, Environment, Energy, Mobility, Innovation and Technology.
Working within the sales team allows me to speak with a wide range of companies across a broad spectrum of industries. Data protection and data innovation seem to be the main concerns that I encounter. In the following blog post, I'll give an overview of the most common data and privacy business problems I hear about from our clients. The general trend is that companies want to access the vast amount of data that can help with strategic decisions and improve their services and products. There seem to be some underlying themes when it comes to having a strong data protection framework and being more data-driven and innovative. The two things appear antithetical to each other on the surface.
The data privacy vs. utility trade-off
We refer to this as the privacy vs. utility trade-off. Until a few years ago, the methods of protecting customers’ data have either been pseudonymization or some other form of data masking. This not only destroys the utility of the data set, but classic anonymization endangers privacy in more ways than one. MOSTLY AI is challenging this dangerous status quo by providing synthetic data alternatives to help companies become more innovative and data-driven. We are taking on the privacy-utility trade-off.
The most common business problems synthetic data can solve
#1 “Privacy gaps and the risk of re-identification are real threats”
With stringent regulations such as GDPR, CCPA, and so forth, the need for organizations to have a strong data protection strategy in place is of the utmost importance. So is the watertight protection of sensitive personal information. Within the banking, insurance, healthcare, and pharma sectors, this is an important function because they know how randomly data breaches can strike and the consequences they can have. At the same time, there is a need to use this data to keep the company’s operations going and improve its service. Companies try to reconcile these, and what they often end up with is an illusion of privacy provided by less-than-secure, outdated anonymization techniques. Although privacy budgets doubled in 2020 to an average of $2.4 million, privacy departments often still lack the technological competencies necessary to assess data privacy risks and to use privacy-tech solutions to offer meaningful access to data.
Synthetic data really changes the way things are done, as it allows companies to share synthetic data sets, which still provide the full picture but without the sensitive information. This helps companies continue with their objectives while mitigating the risk of sensitive data being leaked and re-identified.
We often ask clients to try to think of data as a product they should build and sell across their organizations. As with all products, the method of manufacturing is what makes that product safe to use. According to Gartner, 59% of privacy incidents originate with an organization’s own employees, and although data literacy certainly helps, the goal of every organization should be to provide safe-to-use data products in the first place. Synthetic data products are safe to use in all downstream tasks, from analytics to testing and AI training.
#2 ‘Getting access to data takes time’
We all know that the sensitive information that companies have needs to be protected, which is done by implementing a strong, strict data governance policy with checks and balances in place. It’s an important function, but it also means that the process to get access to data internally can take a while. This means that projects can take longer or even be killed, and this can cause frustration.
Customer data needs to be used across many departments. Some examples include Product’s desire to analyze customer data so that more customer-centric products can be made. QA needs data that mimics customer data realistically to help test applications and ensure that all edge cases are covered. Data, BI, and Analytics need to analyze the data to make findings that assist management in making strategic decisions. You know what I mean, though; the demand for data internally is significant.
This is where synthetic data has really helped our clients. They were able to decrease their time to data dramatically through our MOSTLY AI synthetic data platform. Synthetic data sandboxes can even speed up traditionally cumbersome processes, such as POC evaluations in which potentially sensitive data needs to be shared with third parties. Once synthesized, Data Governance was satisfied that the data adhered to data privacy legislation and cleared the data for use. This meant that projects weren’t stalled or losing momentum.
#3 “I’m trying to scale AI, but don’t have the right data”
Most companies that we deal with sit upon a huge amount of sensitive data. We can see that all companies know the importance of and want to share this data internally to improve access to the information within the organization. AI adoption is especially fraught with data access issues.
The problem is that most data is stored away in siloed warehouses that require a lengthy internal process to access. Data issues are the main reasons why companies fail to implement AI successfully. Also, the data provisioning overhead is staggering; data scientists spend most of their time cleaning and organizing data instead of using it.
Synthetic data is more than just a privacy-safe data alternative for AI training. We’ve helped customers augment their data for AI training by synthesizing better-than-real datasets. The result is privacy-compliant AI, which performs better than models trained on production data. Using synthetic data for fraud detection is typically one of those use cases where even a few percentage points of performance improvement can result in huge savings.
Biased data gets a lot of companies into trouble when AI starts learning discriminatory patterns from imbalanced datasets. Synthetic data provides a fair solution and allows models to learn about a doctored, bias-free reality. What’s more, synthetic data can serve as a window into the souls of AI algorithms and is expected to play an important role in Explainable AI. With the recent AI regulation proposal from the EU, high-risk AI systems, such as HR software, will be subject to strict regulations demanding high quality of the datasets and regulatory oversight. Synthetic training data will be a crucial ingredient to compliance.
#4 “We are striving for a more data-driven culture”
This is one of the most common statements I come across. What we see is that all companies have their own techniques and strategies that are meant to force this cultural change. Though when it comes to implementing, both on a macro and micro level, it’s starting to get difficult as the first step towards data literacy, sharing sensitive data is difficult in itself, and the time taken to get approval means that these projects get lagged.
The difficulty we see with companies is that they’re restricted internally with this data and need to apply some data masking to actually use it. This destroys its utility, and it still can be re-identified. We think that data literacy needs a revamp. Organizing datathons are a great way to put people in touch with what’s being measured, driving innovations and increasing data literacy. Using synthetic data sandboxes, you can maximize impact and even open up these events to external talent and academia.
#5 “We want to use real data in testing environments but have trouble gaining access of this data”
We see many companies with the challenge of wanting to use real production data in non-productive environments, such as QA and testing. We can't blame them either, as the challenge they have is wanting accurate data to test their applications, and we all appreciate how difficult this process can be. Some try to create their own solution or MVP, but that doesn't yield the results they want. The data needs to be realistic to be properly used for testing environments.
What's more, most companies use partially masked data for testing, exposing production data and their customers' privacy in the process. Production data has no place in testing, no matter how scrambled or pseudonymized it is. The only safe and GDPR-compliant way forward is to go synthetic, and those who act against the inertia of embedded bad practices will emerge as the winners, gaining a competitive edge through innovation.
The need for test data is one of the main reasons why clients come to us, wanting to solve this issue by using realistic and safe synthetic data through our MOSTLY AI synthetic data platform. They have seen improvements in the testing of their products and have reduced the time taken to manually recreate their data sets with dummy data internally. They are able to attain realistic synthetic data within a short period of time once the original dataset has been placed. The resulting highly realistic synthetic version allows companies to develop data-driven digital products, ready to serve real customer needs from day one.
Do you have a question? I'm happy to talk synthetic data with you. Please feel free to contact us!
Learn about good data governance and the responsible use of AI at the next Synthetic Data Meetup!
Our speaker, Belinda Enoma, is a privacy & cybersecurity consultant in the legal and IT space. She will highlight good data governance practices and areas for algorithmic compliance and challenges that need to be continuously addressed as models are created.
She is a renowned conference host, speaker, writer and founder of istartandfinish.com. Belinda is also a mentor and coach to women in the cybersecurity and data protection industry.
Her published work includes “Data breach in the travel sector and strategies for risk mitigation,” (Journal of Data Privacy and Protection Volume 3.4, 2020). She is a Certified Information Privacy Professional (CIPP/US) and has an LLM from Benjamin N. Cardozo Law School, New York.
Register for the virtual meetup and save the date: Thursday, March 4, 2021
12:00 PM EST / 18:00 PM CET. See you there!