TL;DR: Synthetic financial data is the fuel banks need to become AI-first and to create cutting-edge services. In this report, you can read about:
- banking technology trends in 2022 from superapps to personalized digital banking
- data privacy legislations affecting the banking industry in 2022
- the challenges in AI/ML development, testing and data sharing that synthetic data can solve
- the most valuable data science and synthetic data use cases in banking: customer acquisition and advanced analytics, mortgage analytics, credit decisioning and limit assessment, risk management and pricing, fraud and anomaly detection, cybersecurity, monitoring and collections, churn reduction, servicing and engagement, enterprise data sharing, and synthetic test data for digital banking product development
- synthetic data engineering: how to integrate synthetic data in financial data architectures
Table of Contents
- Banking technology trends
- The state of data privacy in banking in 2022
- The most valuable synthetic data use cases in banking
- Synthetic data for AI, advanced analytics, and machine learning
- Synthetic data for enterprise data sharing
- Synthetic test data for digital banking products
- How to integrate synthetic data generators into financial systems?
- The future of financial data
Banks and financial institutions are aware of their data and innovation gaps and AI-generated synthetic data is their best bet. According to Gartner:
By 2030, 80 percent of heritage financial services firms will go out of business, become commoditized or exist only formally but not competing effectively.
A pretty dire prophecy, but nonetheless realistic, with small neobanks and big tech companies eyeing their market. There is no way to run but forward.
The future of banking is all about becoming AI-first and creating cutting-edge digital services coupled with tight cybersecurity. In the race to a tech-forward future, most consultants and business prophets forget about step zero: customer data. In this blog post, we will give an overview of the data science use cases in banking and attempt to offer solutions throughout the data lifecycle. We'll concentrate on the easiest to deploy and highest value synthetic data use cases in banking. We'll cover three clusters of synthetic data use cases: data sharing, AI, advanced analytics, machine learning, and software testing. But before we dive into the details, let's talk about the banking trends of today.
Banking technology trends
The pandemic accelerated digital transformation, and the new normal is here to stay. According to Deloitte, 44% of retail banking customers use their bank's mobile app more often. At Nubank, a Brazilian digital bank, the number of accounts rose by 50%, going up to 30 million. It is no longer the high-street branch that will decide the customer experience. Apps become the new high-touch, flagship branches of banks where the stakes are extremely high. If the app works seamlessly and offers personalized banking, customer lifetime value increases. If the app has bugs, frustration drives customers away. Service design is an excellent framework for creating distinctive personalized digital banking experiences. Designing the data is where it should all start.
A high-quality synthetic data generator is one mission-critical piece of the data design tech stack. Initially a privacy-enhancing technology, synthetic data generators can generate representative copies of datasets. Statistically the same, yet none of the synthetic data points match the original. Beyond privacy, synthetic data generators are fantastic data augmentation tools too. Synthetic data is the modeling clay that makes this data design process possible. Think moldable test data and training data for machine learning models based on real production data.
The rise of superapps is another major trend financial institutions should watch out for. Building or joining such ecosystems makes absolute sense if banks think of them as data sources. Data ecosystems are also potential spaces for customer acquisition. With tech giants entering the market with payment and retail banking products, data protectionism is rising. However, locking up data assets is counterproductive, limiting collaboration and innovation. Sharing data is the only way to unlock new insights. Especially for banks, whose presence in their customers' lives is not easy to scale unless via collaborations and new generation digital services. Insurance providers and telecommunications companies are the first obvious candidates. Other beyond-banking service providers could also be great partners, from car rental companies to real estate services, legal support, and utility providers. Imagine a mortgage product that comes with a full suite of services needed throughout a property purchase. Banks need to create a frictionless, hyper-personalized customer experience to harness all the data that comes with it.
Another vital part of this digital transformation story is AI adoption. In banking, it's already happening. According to McKinsey,
"The most commonly used AI technologies (in banking) are: robotic process automation (36 percent) for structured operational tasks; virtual assistants or conversational interfaces (32 percent) for customer service divisions; and machine learning techniques (25 percent) to detect fraud and support underwriting and risk management."
It sounds like banks are running full speed ahead into an AI future, but the reality is more complicated than that. Due to the legacy infrastructures of financial institutions, the challenges are numerous. Usually, there is no clear strategy or fragmented ones with no enterprise-wide scale. Different business units operate almost completely cut off with limited collaboration and practically no data sharing. These fragmented data assets are the single biggest obstacle to AI adoption. McKinsey estimates that AI technologies could potentially deliver up to $1 trillion of additional value in banking each year. It is well worth the effort to unlock the data AI and machine learning models so desperately need. Let's take a look at the number one reason or rather excuse banks and financial institutions hide behind when it comes to AI/AA/ML innovation: data privacy.
The state of data privacy in banking in 2022
Banks have always been the trustees of customer privacy. Keeping data and insights tightly secured has prevented banks from becoming data-centric institutions. What's more, an increasingly complex and restrictive legislative landscape makes it difficult to comply globally.

Let’s be clear. The ambition to secure customer data is the right one. Banks must take security seriously, especially in an increasingly volatile cybersecurity environment. However, this cannot take place at the expense of innovation. The good news is that there are tools to help. Privacy-enhancing technologies (PETs) are crucial ingredients of a tech-forward banking capability stack. It's high time for banking executives, CIOs, and CDOs to get rid of their digital banking blindspots. Banks must stop using legacy data anonymization tools that endanger privacy and hinder innovation. Data anonymization methods, like randomization, permutation, and generalization, carry a high risk of re-identification or destroy data utility.
Maurizio Poletto, Chief Platform Officer at Erste Group Bank AG, said in The Executive's Guide to Accelerating Artificial Intelligence and Data Innovation with Synthetic Data:
"In theory, in banking, you could take real account data, scramble it, and then put it into your system with real numbers, so it's not traceable. The problem is that obfuscation is nice, and anonymization is nice, but you can always find a way to get the original data back. We need to be thorough and cautious as a bank because it is sensitive data. Synthetic data is a good way to continue to create value and experiment without having to worry about privacy, particularly because society is moving toward better privacy. This is just the beginning, but the direction is clear."
Modern PETs include AI-generated synthetic data, homomorphic encryption, or federated learning. They offer the way out of the data dilemma in banking. Data innovators in banking should choose the appropriate PET for the appropriate use case. Encryption solutions should be looked at when necessary to unencrypt the original data. Anonymized computation, such as federated learning, is a great choice when models can get trained on users' mobile phones. AI-generated synthetic data is the most versatile privacy-enhancing technology with just one limitation. Synthetic datasets generated by AI models trained on original data cannot be reverted back to the original. Synthetic datasets are statistically identical to the original datasets they were modeled on. However, there is no 1:1 relationship between the original and the synthetic data points. This is the very definition of privacy. As a result, AI-generated synthetic data is great for specific use cases—advanced analytics, AI and machine learning training, software testing, and sharing realistic but unencryptable datasets. Synthetic data is not a good choice for use cases where the data needs to be reverted back to the original, such as information sharing for anti-money laundering purposes, where perpetrators need to be re-identified. Let's look at a comprehensive overview of the most valuable synthetic data use cases in banking!
The most valuable synthetic data use cases in banking
Synthetic data generators come in many shapes and forms. In the following, we will be referring to MOSTLY AI's synthetic data generator. It is the market-leading synthetic data solution able to generate synthetic data with high accuracy. MOSTLY AI's synthetic data platform comes with advanced features, such as direct database connection and the ability to synthesize complex data structures with referential integrity. As a result, MOSTLY AI can serve the broadest range of use cases with suitably generated synthetic data. In the following, we will detail the lowest hanging synthetic data fruits in banking. These are the use cases we have seen to work well in practice and generate a high ROI.
| CHALLENGES | HOW CAN SYNTHETIC DATA HELP? |
|---|---|
AI/AA/ML
|
|
TESTING
|
|
DATA SHARING
|
|
Synthetic data for AI, advanced analytics, and machine learning
Synthetic data for AI/AA/ML is one of the richest use case categories with many high-value applications. According to Gartner, by 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated. Machine learning and AI unlocks a range of business benefits for retail banks.
- Advanced analytics improves customer acquisition by optimizing the marketing engine with hyper-personalized messages and precise next best actions.
- Intelligence from the very first point of contact increases customer lifetime value.
- Operating costs will be lower if decision-making in acquisition and servicing is supported with well-trained machine learning algorithms. Lower credit risk is also a benefit that comes from early detection of behaviors that signal a higher risk of default.
Automated, personalized decisions across the entire enterprise can increase competitiveness. The data backbone, the appropriate tools, and talent need to be in place to make this happen. Synthetic data generation is one of those capabilities essential for an AI-first bank to develop. The reliability and trustworthiness of AI is a neglected issue. According to Gartner:
65% of companies can't explain how specific AI model decisions or predictions are made. This blindness is costly. AI TRiSM tools, such as MOSTLY AI's synthetic data platform, provide the Trust, Risk and Security Management needed for effective explainability, ModelOps, anomaly detection, adversarial attack resistance and data protection. Companies need to develop these new capabilities to serve new needs arising from AI adoption.
From explainability to performance improvement, synthetic data generators are one of the most valuable building tools. Data science teams need synthetic data to succeed with AI and machine learning use cases. Here is how to use synthetic data in the most common AI banking applications.
CUSTOMER ACQUISITION AND ADVANCED ANALYTICS
CRM data is the single most valuable data asset for customer acquisition and retention. A wonderful, rich asset that holds personal data and behavioral data of the bank's future prospects. However, due to privacy legislation, up to 80% of CRM data tends to be locked away. Compliant CRM data for advanced analytics and machine learning applications is hard to come by. Banks either comply with regulations and refrain from developing a modern martech platform altogether or break the rules and hope to get away with it. There is a third option. Synthetic customer data is as good as real when it comes to training machine learning models. Insights from these type of analytics can help identify new prospects and improve sign-up rates significantly.
MORTGAGE ANALYTICS, CREDIT DECISIONING AND LIMIT ASSESSMENT
AI in lending is a hot topic in finance. Banks want to reach out to the right people with the right mortgage and credit products. In order to increase precision in targeting, a lot of personal data is needed. The more complete the customer data profile, the more intelligent mortgage analytics becomes. Better models bring lower risk both for the bank and for the customer. Rule-based or logistic regression models rely on a narrow set of criteria for credit decision-making. Banks without advanced behavioral analytics and models underserve a large segment of customers. People lacking formal credit histories or deviating from typical earning patterns are excluded. AI-first banks utilize huge troves of alternative data sources. Modern data sources include social media, browsing history, telecommunications usage data, and more. However, using these highly personal data sources in their original for training AI models is often a challenge. Legacy data anonymization techniques destroy the very insights the model needs. Synthetic data versions retain all of these insights. Thanks to the granular, feature-rich nature of synthetic data, lending solutions can use all the intelligence.
RISK MANAGEMENT AND PRICING
Pricing and risk prediction models are some of the most important models to get right. Even a small improvement in their performance can lead to significant savings and/or higher revenues. Injecting additional domain knowledge into these models, such as synthetic geolocation data or synthetic text from customer conversations, significantly improves the model's ability to quantify a customer's propensity to default. MOSTLY AI's ability to provide the accuracy needed to generate synthetic geolocation data has been proven already. Synthetic text data can be used for training machine learning models in a compliant way on transcripts of customer service interactions. Virtual loan officers can automate the approval of low-risk loans reliably.
It is also mission-critical to be able to provide insight into the behavior of these models. Local interpretability is the best approach for explainable AI today, and synthetic data is a crucial ingredient of this transparency.
FRAUD AND ANOMALY DETECTION
Fraud is one of the most interesting AI/ML use cases. Fraud and money laundering operations are incredibly versatile, getting more and more sophisticated every day. Adversaries are using a lot of automation too to find weaknesses in financial systems. It's impossible to keep up with rule-based systems and manual follow-ups. False positives cost a lot of money to investigate, so it's imperative to continuously improve precision aided with machine learning models. To make matters even more challenging, fraud profiles vary widely between banks. The same recipe for catching fraudulent transactions might not work for every financial institution. Using machine learning to detect fraud and anomaly patterns for cybersecurity is one of the first synthetic data use cases banks usually explore. The fraud detection use case goes way beyond privacy and takes advantage of the data augmentation possibility during synthesization. Maurizio Poletto, CPO at Erste Group Bank, recommends synthetic data upsampling to improve model performance:
Synthetic data can be used to train AI models for scenarios for which limited data is available—such as fraud cases. We could take a fraud case using synthetic data to exaggerate the cluster, exaggerate the amount of people, and so on, so the model can be trained with much more accuracy. The more cases you have, the more detailed the model can be.
Training and retraining models with synthetic data can improve fraud detection model performance, leading to valuable savings on investigating false positives.
MONITORING AND COLLECTIONS
Transaction analysis for risk monitoring is one of the most privacy-sensitive AI use cases banks need to be able to handle. Apart from traditional monitoring data, like repayment history and credit bureau reports, banks should be looking to utilize new data sources, such as time-series bank data, complete transaction history, and location data. Machine learning models trained with these extremely sensitive datasets can reliably microsegment customers according to value at risk and introduce targeted interventions to prevent defaults. These highly sensitive and valuable datasets cannot be used for AI/ML training without effective anonymization. MOSTLY AI's synthetic data generator is one of the best on the market when it comes to synthesizing complex time-series, behavioral data, like transactions with high accuracy. Behavioral synthetic data is one of the most difficult synthetic data categories to get right, and without a sophisticated AI engine, like MOSTLY AI's, results won't be accurate enough for such use cases.
CHURN REDUCTION, SERVICING, AND ENGAGEMENT
Another high-value use case for synthetic behavioral data is customer retention. A wide range of tools can be put to good use throughout a customer's lifetime, from identifying less engaged customers to crafting personalized messages and product offerings. The success of those tools hinges on the level of personalization and accuracy the initial training data allows. Machine learning models are the most powerful at pattern recognition. ML's ability to identify microsegments no analyst would ever recognize is astonishing, especially when fed with synthetic transaction data. Synthetic data can also serve as a bridge of intelligence between different lines of business: private banking and business banking data can be a powerful combination to provide further intelligence, but strictly in synthetic form. The same applies to national or legislative borders: analytics projects with global scope can be a reality when the foundation is 100% GDPR compliant synthetic data.
ALGORITHMIC TRADING
Financial institutions can use synthetic data to generate realistic market data for training and validating algorithmic trading models, reducing the reliance on historical data that may not always represent future market conditions. This can lead to improved trading strategies and increased profitability.
STRESS TESTING
Banks can use synthetic data to create realistic scenarios for stress testing, allowing them to evaluate their resilience to various economic and financial shocks. This helps ensure the stability of the financial system and boosts customer confidence in the institution's ability to withstand adverse conditions.
Synthetic data for enterprise data sharing
Open financial data is the ultimate form of data sharing. According to McKinsey, economies embracing financial data sharing could see GDP gains of between 1 and 5 percent by 2030, with benefits flowing to consumers and financial institutions. More data means better operational performance, better AI models, more powerful analytics, and customer-centric digital banking products facilitating omnichannel experiences. The idea of open data cannot become a reality without a robust, accurate, and safe data privacy standard shared by all industry players in finance and beyond. This is a vision shared by Erste Group Bank's Chief Platform Officer:
Imagine if we in banking use synthetic data to generate realistic and comparable data from our customers, and the same thing is done by the transportation industry, the city, the insurance company, and the pharmaceutical company, and then you give all this data to someone to analyze the correlation between them. Because the relationship between well-being, psychological health, and financial health is so strong, I think there is a fantastic opportunity around the combination of mobility, health, and finance data.
It's an ambitious plan, and like all grand designs, it's best to start building the elements early. At this point, most banks are still struggling with internal data sharing with distinct business lines acting as separate entities and being data protectionist when open data is the way forward. Banks and financial institutions share little intelligence, citing data privacy and legislation as their main concern. However, data sharing might just become an obligation very soon with the EU putting data altruism on the map in the upcoming Data Governance Act. While sharing personal data will remain strictly forbidden and increasingly so, anonymized data sharing will be expected of companies in the near future. In the U.S., healthcare insurance companies and service providers are already legally bound to share their data with other healthcare providers. The same requirement makes a lot of sense in banking too where so much depends on credit history and risk prediction. While some data is shared, intelligence is still withheld. Cross-border data sharing is also a major challenge in banking. Subsidiaries either operate in a completely siloed way or share data illegally. According to Axel von dem Bussche, Partner at Taylor Wessing and IT lawyer, as much as 95% of international data sharing is illegal due to the destruction of the EU-US Privacy Shield by the Schrems II decision.
Some organizations fly analysts and data scientists to the off-shore data to avoid risky and forbidden cross-border data sharing. It doesn't have to be this complicated. Synthetic data sharing is compliant with all privacy laws across the globe. Setting up synthetic data sandboxes and repositories can solve enterprise-wide data sharing across borders since synthetic data does not qualify as personal data. As a result, it is out of scope of GDPR and the infamous Schrems II. ruling, which effectively prohibited all sharing of personal data outside the EU.
Third-party data sharing within the same legislative domain is also problematic. Banks buy many third-party AI solutions from vendors without adequately testing the solutions on their own data. The data used in procurement processes is hard to get, causing costly delays and heavily masked to prevent sensitive data leaks through third parties. The result is often bad business decisions and out-of-the-box AI solutions that fail to deliver the expected performance. Synthetic data sandboxes are great tools for speeding up and optimizing POC processes, saving 80% of the cost.
Synthetic test data for digital banking products
One of the most common data sharing use cases is connected to developing and testing digital banking apps and products. Banks accumulate tons of apps, continuously developing them, onboarding new systems, and adding new components. Manually generated test data for such complex systems is a hopeless task, and many revert to the old dangerous habit of using production data for testing systems. Banks and financial institutions tend to be more privacy-conscious, but their solutions to this conundrum are still suboptimal. Time and time again, we see reputable banks and financial institutions roll out apps and digital banking services after only testing them with heavily masked or manually generated data. One-cent transactions and mock data generators won't get you far when customer expectations for seamless digital experiences are sky-high.
To complicate things further, complex application development is rarely done in-house. Data owners and data consumers are not the same people, nor do they have the full picture of test scenarios and business rules. Labs and third-party dev teams rely on the bank to share meaningful test data with them, which simply does not happen. Even if testing is kept in-house, data access is still problematic. While in other, less privacy-conscious industries, developers and test engineers use radioactive test data in non-production environments, banks leave testing teams to their own devices. Manual test data generation with tools like Mockaroo and the now infamous Faker library misses most of the business rules and edge cases so vital for robust testing practices. Dynamic test users for notification and trigger testing are also hard to come by. To put it simply, it's impossible to develop intelligent banking products without intelligent test data. The same goes for the testing of AI and machine learning models. Testing those models with synthetically simulated edge cases is extremely important to do when developing from scratch and when recalibrating models to avoid drifting. Models are as good as the training data, and testing is as good as test data. Payment applications with or without personalized money management solutions need the synthetic approach: realistic synthetic test data and edge case simulations with dynamic synthetic test users. Synthetic test data is fast to generate and can create smaller or larger versions of the same dataset as needed throughout the testing pyramid from unit testing, through integration testing, UI testing to end-to-end testing.
Erste Bank's main synthetic data use case is test data management. The bank is creating synthetic segments and communities, building new features, and testing how certain types of customers would react to these features.
Normally, the data we use is static. We see everything from the past. But features like notifications and triggers—like receiving a notification when your salary comes in—can only be tested with dynamic test users. With synthetic data, you push a button to generate that user with an unlimited number of transactions in the past and a limited number of transactions in the future, and then you can put into your system a user which is alive.
These live, synthetic users can stand in for production data and provide a level of realism unheard of before while protecting customers' privacy. The Norwegian Data Protection Authority issued a fine for using production data in testing, adding that using synthetic data instead would have been the right course to take.
Testing is becoming a continuous process. Deploying fast and iterating early is the new mantra of DevOps teams. Setting up CI/CD (continuous integration and delivery) pipelines for continuous testing cannot happen without a stable flow of high-quality test data. Synthetic data generators trained on real data samples can provide just that – up-to-date, realistic, and flexible data generation on-demand.
How to integrate synthetic data generators into financial systems?
First and foremost, it's important to understand that not all synthetic data generators are created equal. It's particularly important to select the right synthetic data vendor who can match the financial institution's needs. If a synthetic data generator is inaccurate, the resulting synthetic datasets can lead your data science team astray. If it's too accurate, the generator overfits or learns the training data too well and could accidentally reproduce some of the original information from the training data. Open-source options are also available. However, the control over quality is fairly low. Until a global standard for synthetic data arrives, it's important to proceed with caution when selecting vendors. Opt for synthetic data companies, which already have extensive experience with sensitive financial data and know-how to integrate synthetic data successfully with existing infrastructures.

The future of financial data is synthetic
Our team at MOSTLY AI is working with large banks and financial organizations very closely. We know that synthetic data will be the data transformation tool that will change the financial data landscape forever, enabling the flow and agility necessary for creating competitive digital services. While we know that the direction is towards synthetic data across the enterprise, we know full well how difficult it is to introduce new technologies and disrupt the status quo in enterprises, even if everyone can see the benefits. One of the most important tasks of anyone looking to make a difference with synthetic data is to prioritize use cases in accordance with the needs and possibilities of the organization. Analytics use cases with the biggest impact can serve as flagship projects, establishing the foundations of synthetic data adoption. In most organizations, mortgage analytics, pricing, and risk prediction use cases can generate the highest immediate monetary value, while synthetic test data can massively accelerate the improvement of customer experience and reduce compliance and cybersecurity risk. It's good practice to establish semi-independent labs for experimentation and prototyping: Erste Bank's George Lab is a prime example of how successful digital banking products can be born of such ventures. The right talent is also a crucial ingredient of success. According to Erste Bank's CPO, Maurizio Poletto:
Talented data engineers want to spend 100% of their time in data exploration and value creation from data. They don't want to spend 50% of their time on bureaucracy. If we can eliminate that, we are better able to attract talent. At the moment, we may lose some, or they are not even coming to the banking industry because they know it's a super-regulated industry, and they won't have the same freedom they would have in a different industry.
Once you have the attraction of a state-of-the-art tech stack enabling agile data practices, you can start building cross-functional teams and capabilities across the organization. The data management status quo needs to be disrupted, and privacy, security, and data agility champions will do the groundwork. Legacy data architectures keeping banks and financial institutions back from innovating and endangering customers' privacy need to be dealt with soon. The future of data-driven banking is bright, and that future is synthetic.
The choice for mankind lies between freedom and happiness and for the great bulk of mankind, happiness is better.
The above is my favorite quote from George Orwell's dystopian classic, 1984. This is one among several chilling quotes that can be revisited and newly interpreted to provide searing insight into present-day events.
With a slight tweak, this quote can be re-imagined by encapsulating the challenge of big data privacy.
The choice for mankind lies between
freedomprivacy andhappinessutility, and for the great bulk of mankind,happinessutility is better.
The key here is choice.
From an individual perspective, the choice is between privacy and convenience. We share our personal data because we receive something of value in return.
For the modern enterprise, the choice comes down to two ingredients of digital transformation:
- protecting its customers' privacy,
- and unlocking the valuable insights contained within customer data.
It is a difficult choice when framed as a zero-sum game, but does it have to be so?
This is the question that compelled me to join the MOSTLY AI team. MOSTLY AI is reshaping the paradigm with realistic and representative synthetic data. We are creating a data ecosystem in which privacy and utility can co-exist.
In this blog, we will look at privacy vs. utility in personalized digital banking.
Digital transformation in banking with personalized customer experience
The COVID-19 pandemic has accelerated the shift to digital banking. In this new world, personalized customer experiences are sacrosanct.
'The goal of digital banking is to offer easily understandable client-focused services that help customers to improve their financial health,' says Tomas Balint, Data Chapter Lead at the George digital banking team at Erste Group. 'To achieve this goal, banks need to translate complex customer interactions into clear data evidence and use this evidence to provide simple and relevant advice to their customers.'
Data-driven personalization analyzes customer data in real time. Machine-learning models provide personalized services based on the customer's financial profile. These machine-learning models need quality data—and lots of it. Models learn what is important to the customer. This is how banks can provide relevant and timely advice during the digital banking experience. However, accessing customer data for the purposes of analytics requires specific consent.
Is it possible to provide personalized customer experiences without personal data? And if so, would that constitute the perfect balance of privacy and utility?
Digital banking personalization drives business impact
In the latest World Retail Banking Report, 57% of consumers say they now prefer internet (online) banking to traditional branch banking. 55% of consumers now prefer using mobile banking apps to stay on top of their finances, up from 47% in the pre-pandemic era.
The shift to digital banking was well underway before the pandemic, driven in large part by changing customer expectations. As customers, we expect the same level of personalization in our digital banking experience that we have become accustomed to in other aspects of our life. Our mobile banking app should make it simple to understand how much money we have, how we spend our money, and what we can do with our money. Customers are embracing personalized insights, achieving satisfaction scores of 4.4 out of 5, according to Personetics' 2020 global banking analysis. Better experiences equal happier customers, and happier customers make the bank more money.
There are several powerful incentives for banks to accelerate digital transformation, including:
- increased value of sales per customer,
- improved customer acquisition rates,
- reduced customer churn,
- lower servicing costs, and
- an enhanced halo effect.
To put this into perspective, BCG estimates that for every $100 billion in assets that a bank has, it can achieve as much as $300 million in revenue growth by personalizing its customer interactions.
The privacy–personalization paradox
The challenge for banks is that they must contend with two opposing truths in their quest to develop this lucrative personalized customer experience.
- Customers expect personalized digital banking experiences.
- Customers are increasingly skeptical about how their data is used.
Balancing these two opposing truths is no easy feat and goes straight to the heart of the privacy vs. utility trade-off. We have previously spoken on this blog about how privacy kills data-driven innovation for banks. Furthermore, our colleagues on Mobey's AI and Data Privacy Expert Group have recently spoken at length about how operating with data at scale without sacrificing privacy along the way is a major challenge in banking.
Power your personalization in banking with synthetic data
So, we have established that personalized customer experiences drive business impact. However, banks must contend with privacy obstacles in the form of customer consent.
How it works: Data lifecycle

1. Customer generates transaction data through digital banking activity
2. Data stored natively in Elasticsearch for easy search & retrieval
3. Data analytics team requests data for predictive analysis
4. Compliance team verifies specific consent obtained for 30% of data
5. That data is transferred to Hadoop, transformed to tabular format
6. Data is used to train ML algorithms on what’s important to customers
7. The accuracy of the ML models are assessed by the business team
8. Interface team inserts accurate models into application plug-ins
9. Mobile app delivers personalized insights and advice to customers
Challenge: Only 30% of customers give specific consent to use their transactional data for the purposes of data analytics, therefore the quality and coverage of the ML models is suboptimal.
Let's take a look at a sample data lifecycle involved in creating personalized customer experiences. As we can see from figure 1, there are a number of steps involved:
- taking customer transactional data,
- analyzing customer transactional data,
- learning patterns from the data, and
- delivering it back to customers in the form of relevant advice and opportunities.
Machine learning underpins the data-driven workflow and enables complex, holistic, and predictive analyses of customer behavior.
As we know, the performance and accuracy of machine learning models are predicated on the quality and volume of data available to train them. A lack of data covering the full breadth and depth of real-life conditions is often a reason why a machine-learning model performs poorly.
We can assume that only 30% of customers (a generous assumption in our experience) provide consent to use their data for analytic purposes. The bank must operate within the bounds of those privacy constraints, even if it's to the detriment of the machine learning model's accuracy. From speaking with our banking customers, we know that commercial teams are constantly pushing their counterparts in data analytics teams for more accurate models. Their goal is to create more personalized recommendations and ultimately generate more revenue for the bank. The constant drive for improvement is understandable as every granular increase in model accuracy can equate to significant downstream revenue.
For those banks striving for granular improvements in accuracy, they should cast their eye at synthetic data. Synthetic data can provide those granular improvements in your machine learning accuracy and then some. We have previously demonstrated how you can boost your machine learning accuracy with synthetic data. By leveraging synthetic data in your machine learning algorithms, you can unlock the insights contained within the data you cannot access (i.e., data that you do not have consent to process).
Figure 2 shows a simple workflow where a bank creates a mixed dataset of original data and synthetic data. This creates 100% coverage of the customer transactional data, ready to supercharge your machine learning accuracy.
A sufficient amount of accurate training data is critical for the success of any machine learning initiative. There is no more important machine learning initiative in digital banking than creating a personalized customer experience.

Data-driven personalization means greater market share for banks
Banks who master data-driven personalization will continue to achieve higher levels of digital-enabled sales and greater market share. Personalization has become a competitive imperative. Banks need to think outside of the box in order to survive; they need to go synthetic.
I will sign off with another one of my favorite quotes from George Orwell's 1984.
'Sanity is not statistical.'
The majority does not always determine what is right or correct. The prevailing wisdom in the modern bank maintains that you can achieve privacy or utility, privacy or personalization, but not both. Here at MOSTLY AI, we disagree.
What is AI-generated synthetic data?
MOSTLY AI’s synthetic data platform is based on a groundbreaking machine learning technology, ready to create privacy regulation compliant, highly accurate synthetic versions of datasets. The synthetic data versions generated by MOSTLY AI retain up to 99% of the information contained in the original, yet real individuals are impossible to re-identify. The implications for the financial industry and the ways in which this technology can be applied are manifold.
Large financial institutions and banks have always been among the most conservative users of technology and for a good reason. Nowhere else is data so rich and so risky, so full of hidden stories and telltale patterns. What makes these oceans of information so valuable is precisely what makes them so sensitive. And customers are well aware of this. 87% of Americans consider credit card data moderately or extremely private, whereas only 68% consider health and genetic information private. In other words, people are shyer about their wallets than their medical secrets.
Considering this sentiment, it is not surprising that financial businesses guard their customers’ data very carefully. Customers demand and reward this scrutiny. With the advance of data-driven services, personal relationships are no longer the main driver of trust. Instead, one of the biggest drivers of loyalty for banking customers is the ability to trust their bank in protecting their personal data.
The great banking dilemma: innovation versus data-privacy

Source: Raconteur, The World of Fintech
Customers in the financial world are hungry for cutting edge innovations. Data is the fuel required by technologies to make these advances. New disrupting fintech players have been making these innovations happen with Revolut, Monzo, Transferwise and others picking the low hanging fruits left untouched by traditional institutions. So far, the great data gateways at banks and large financial organizations have been closed and heavily guarded for security reasons.
While security remains a high priority, it is now possible to open those gateways without jeopardizing safety by letting synthetic copies of your valuable data assets do its magic for the financial industry. MOSTLY AI's enterprise-grade synthetic data platform is changing the game by offering a safe, trustworthy and compromise-free solution for using previously untapped data assets, bridging the gap between technological ambitions and real-world possibilities.
How does AI-generated synthetic data work and why is it superior to data masking?
By creating synthetic copies from your valuable data assets, such as credit card transaction records, client identity repositories, purchase records of financial products or high value investment portfolios, you can unlock rich and as yet untouched stories of human behavior, while also preserving their complexity. For example, when it comes to spending money, shopping behavior is surprisingly easy to predict by training machine learning algorithms on credit card data.
Researchers of this study used anonymized datasets. There are different approaches to traditional anonymization, but they have one thing in common: a lot of valuable data gets thrown away to prevent re-identification of customers. With synthetic data, these algorithms can account for much broader and deeper insights, while anonymization methods come with serious limitations, very often rendering datasets effectively useless.
No matter how thorough the process to remove sensitive bits of data was, it is still shockingly easy to re-identify datasets anonymized with traditional techniques. MOSTLY AI’s synthetic data platform satisfies two seemingly opposing needs: it provides a true reflection of real life data, yet is impossible to re-identify - hence the revolutionary nature of this technology. The potentials are huge. There are just so many stories hidden in behavioral datasets ready to be discovered with the right tools. Customer behavior can be used to value companies, to predict credit risk, to build data-driven services and to guide marketing efforts, just to mention a few examples of how magical machine learning algorithms can be when fed with good quality datasets of financial behavior.
So what are the most important ways in which financial organizations can benefit from using synthetic data in 2020?
#1 Make the most of AI and cloud computing technologies
Machine learning algorithms are hungry beasts when it comes to data and computing power. Banks and financial institutions often miss out on these innovative technologies, because uploading sensitive data to cloud platforms is just out of the question for privacy reasons. A synthetic version of a sensitive dataset can stand in for the purpose of training algorithms, which - once trained - can be brought back to the premises and used on the original data.
In addition, synthetic data can improve the performance of machine learning algorithms by as much as 15% by providing significantly more samples than otherwise available in the original data and by upsampling minority classes that would otherwise remain underrepresented.
In other cases, existing datasets are simply too small to be used for modelling purposes. Recessions for example are too rare to study without putting the data on synthetic steroids. Similarly, credit risk assessment models usually need to be tested against extreme events, such as surprise election outcomes, like the Brexit referendum or the 2016 US presidential election, where polls failed to predict results. These extreme events lack enough data points and AI-generated synthetic data can fill in this gap to improve the training of crucial models, such those applied to predict credit risk by conducting more thorough stress-testing.
MOSTLY AI' synthetic data platform can scale up existing data and build more robust datasets out of all rare events, like in the early days of a product launch or in case of a rarely purchased, but high value service. Similarly, high quality AI-generated data provides excellent input for the initial training of robo-advisor programs before launching fully automated financial adviser platforms.
#2 Create products and services that genuinely meet customer needs
And not just in-house either. Synthetic data benefits product and service development as it brings meaningful insights into the design process. Safely sharing the synthetic version of datasets with innovation partners, third party service providers and researchers also becomes possible, opening up new spaces of cooperation and co-creation. Networks of interconnected services and products are the future of banking and synthetic data will play an important role in setting up these complex ecosystems.
During API development and testing, it’s crucial to provide quality sandbox environments for developers, complete with realistic data, so by the time a service goes live, apps developed by third parties are prepared for all types of consumer behavior. Synthetic data help engineers ensure that their software works in various planned and unplanned scenarios, significantly reducing product downtimes after a launch. Synthetic test data is easy to create and provides a realistic and privacy-compliant drop-in placement for production data.
#3 Share banking data with third parties in a safe way
Synthetic data makes safe, no-risk monetization of data possible. Although third-party data sharing is the biggest challenge for historically cautious financial players, it is now a real possibility and it will soon be the backbone of financial services. Whether it’s raw data through an API or in the form of synthetic datasets, this future is here and institutions need to step up their game or risk losing out to disruptors. These new players are ready to take the leap. NGOs and other charities working on improving the lives of particular at-risk groups or society at large could also benefit from access to synthetic financial datasets. Such cooperations could earn banks and financial institutions a huge amount of publicity and scientific credit at research communities. Using synthetic data sandboxes for POC processes can speed up processes and save huge amounts on data provisioning costs.
#4 Improve fraud detection processes
Detecting fraud doesn’t have to be a costly and tedious manual process - there is no need to look at specific transactions to train algorithms, only patterns to see if the amounts justify an audit or are perfectly in line with what’s expected. Synthetic data can do this with high accuracy in a quick and painless way by generating unique and rare fraud patterns that your automation can use for fraud detection.
However, the advantages don’t end there. Fraud detection datasets are usually highly imbalanced and so traditional machine learning often are challenged. MOSTLY AI is also able to fix class imbalances engraved in an original dataset and thus help downstream models to perform better.
Synthetic data can boost the performance of fraud detection and AML models, leading to a more accurate detection of positive cases.
#5 Make life easier for yourself and your organization
The lengthy and often overly complicated legalities of sharing data can make such efforts virtually impossible, even when the data lake’s access privileges only have to be granted to another department in your organization. A familiar and painful situation for those working in large institutions: by the time the permission arrives, the business need is not met in time. To speed up and simplify data-driven operations, the use of synthetic data can do wonders, doing away with the need to get the blessings of the legal department and providing access to datasets for any number of colleagues, even across borders or within tight budget constraints and deadlines. Since it doesn't classify as personal data, synthetic data can be shared across international borders even after the landmark ruling of Schrems II.
The takeaway: AI-generated synthetic data is a must-have in finance
In summary, AI-powered synthetic data is a privacy-preserving way for financial institutions to use advanced machine learning services and algorithms, to develop data-driven products, such as robo-advisors, to monetize their data reserves, to improve fraud detection, to fix historically biased datasets and to simplify data sharing in-house, with partners and third parties. Simply put, it’s a must-have technology for financial power houses, whose very existence rests on and will increasingly be governed by the data economy. GDPR/CCPA compliant behavioral data is an asset, which needs to be actively cultivated and harvested for the benefit of customers and institutions alike. Find out more about synthetic data use cases in finance!
Feature image by tuetyi.com
Learn how innovators outrun competitors in banking!
Accelerating digital transformation has been at the top of the agenda for financial institutions. Download our ebook to find out how AI-generated synthetic data can give your organization a competitive edge.
Scaling AI - Is it on your 2023 Roadmap yet?
Scaling AI is high up on the agenda of everyone in 2023. With the generative AI boom introducing a new-found urgency to successfully introducing and scaling AI, it is now simply a question of survival if banks and financial institutions can make it work.
AI applications reduce time, effort and cost for organizations of all sizes, taking care of crucial functions in fraud detection, personalization and customer assistance. The larger the institution, the more likely it is that they are already implementing AI strategies: 75% of banks with over $100 billion in assets already have one in 2020.
AI use cases in banking now range from cybersecurity, credit decisioning, churn reduction, personalized services and products to fraud and anomaly detection. The race has been on for the past few years to develop truly AI-first banking services. Here is an early attempt from the Bank of America in 2021:
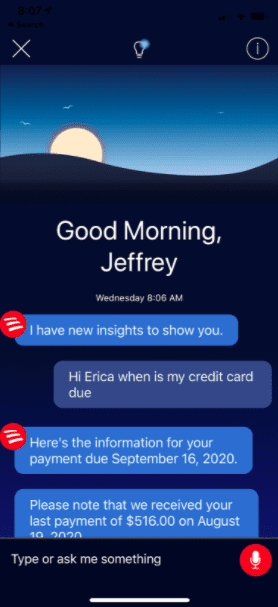
While Bank of America is one of the big players who already had a robust AI plan in place back then, 74% of C-suite banking executives surveyed by Accenture believe if they don’t figure out scaling AI in the near term, they’ll go out of business within five years.
Five. Years. And that was in 2021.
The referenced study by Accenture - the main points of which we will recap in this blogpost - shows that approximately 84% of C-Suite executives know they must leverage AI to reach growth goals. Yet, a staggering 76% said they struggle with the task of scaling.
What’s even more alarming - it appears that less than 25% of banks are effectively and strategically scaling AI today. However, there’s good news. The ones that are scaling AI are achieving insane ROI (nearly 3 times the return on investment compared to their counterparts).
If scaling AI was easy, everyone would do it
Scaling is easy when you are big, right? Not necessarily. Larger banks, like BoA and its top competitors, may face complex enterprise rules, siloed infrastructure and way too much red tape.
However, they also might achieve greater investment returns due to their ability to invest and spread innovations throughout their organizations. So for these giants it’s well worth the effort to work their way around organizational hurdles. What about smaller players? Should they even try to scale and compete?
After grouping the surveyed companies by size, Accenture found that scaling success rate and ROI had little to do with the size of the company. What it really comes down to is establishing a framework and culture that empowers your company and employees to thrive. No matter how large or small your financial institution is, you’re just as likely to succeed with AI. All you need to do is meet the three main challenges of scaling.
Three main challenges financial institutions face when trying to scale AI:
#1 Lack of clear AI strategy from the top
#2 Misaligned planning and governance across teams
#3 Overwhelming amount of data or a lack of it
Challenge #1: Lack of clear AI strategy from the top
Solution: Get others involved

Companies that have successfully scaled AI typically get buy-in from the top. To be a strategic scaler requires alignment from the C-suite, and this usually means you need to appoint a Chief Data, Analytics or AI Officer. Does your financial institution have someone with this title or role? If not, it’s time to find her.
To scale strategically, the most efficient banks create holistic AI teams. These teams need to combine expertise from numerous areas and departments with backgrounds in machine learning, AI, data science, as well as engineering, and also need to include specialists focused on data quality, dashboards and management.
By establishing such multidisciplinary teams, a company-wide behavioral change is created, fostering a culture of embracing AI, speeding up the overall process and success rate. A staggering 92% of the strategically scaling companies mentioned by Accenture follow this model.
Challenge #2: Misaligned planning and governance across teams
Solution: Be methodical in your approach

While many financial institutions take a startup-like approach by zigzagging between potential solutions to figure things out as they go, the most effective way to scaling AI is to establish structure and governance to help guide strategy and planning.
Planned initiatives must align with true business needs and each challenge must be assigned to a specific stakeholder who reports to the head of AI. This setup reduces the likelihood of misaligned efforts and ensures there is clear ownership of each project. The head of the AI team needs visibility to hold this person and her team accountable, and to also keep the C-suite and the board invested and updated.
It might sound counterintuitive but in order to move quickly and accomplish more in less time, you first need to slow down. Scaling AI requires a long-term commitment and a high-level strategy. Believe it or not, the most effective AI-focused executives at banks set longer and more realistic timelines, which empowers them to pilot and then launch more initiatives across their organizations.
In fact, as the Accenture study points out, 65% of the successfully scaling banks plan 12-24 months to pilot and scale new AI projects. Thanks to the super methodical and intentional approach, these financial institutions end up spending less time and money overall: their pilots succeed and are then implemented at a greater scale.
Challenge #3: Overwhelming amount or lack of data
Solution: Identify and synthesize business-critical data

If your organization has difficulty making sense of the crazy amount of data it’s collected, you’re not alone. According to IBM's report from 2016, more than 90% of all data in the world at that time was generated in the space of only two years! Most organizations don’t know how or what to do with it all. Even after data has been collected, it must be organized, managed, sanitized, and shared so that it can be utilized effectively.
The most efficient banks sift through all their repositories and identify the most important data to share. This includes data that can ultimately be used to improve engagement, drive revenue and reduce fraud.
In order to accomplish these goals, customer transaction and production data must be shared across borders, between teams, and with external vendors—which can be difficult to do because of compliance rules tied to financial and privacy sensitive data.
To overcome these privacy hurdles, banks leverage AI-powered synthetic data to create cloud-based synthetic data lakes. Repositories like this can then be accessed by teams in and out of the bank to accomplish their goals, like working with imbalanced datasets to improve algorithms to mitigate fraud. And this brings us full circle.
Synthetic data empowers banks to make data readily accessible, which results in a greater number of people and teams involved, and fosters a culture of collaboration. It also creates the foundation of a scalable AI process and playbook all teams can leverage. JPMorgan is already using synthetic data to conduct pilots with vendors that require privacy sensitive business-critical data. And you can too.
These teams onboard other AI vendors which promotes a positive cycle that can propel your bank to new levels of success. These thriving banks are discovering AI platforms that improve their machine learning capabilities resulting in quicker identification of data that should be synthesized and shared with other teams.
Scaling AI starts with the data. It's time to replace code with data and to do so with maximum attention to privacy, fairness and security.
Key learnings for scaling AI
Companies that successfully reached new heights established data-minded multidisciplinary teams across key verticals. Their specialists and experts achieved results by fostering a culture that embraces AI and by taking the following actions to heart:
- Realize an effective alignment strategy from the C-level downwards by appointing a Chief Data, Analytics, or AI Officer.
- Establish structure and governance to help guide strategy and planning.
- Set realistic timelines. Successful projects planned 12-24 months to pilot and scale new AI projects.
- Make business-critical data assets readily accessible by leveraging AI-powered synthetic data to create cloud-based synthetic data lakes.
Don't break things
In the first part of this PrivacyTech in Banking series, I looked into the effect that privacy has on data-driven innovation in the financial services industry. Moving fast and breaking things is extremely bad advice when it comes to privacy. The main reason why privacy turns out to be a killer of your data-driven innovation project lies in the fact that privacy is closely related to trust - the most valuable asset a financial institution has (to lose). But privacy protection stays tricky even if the banks don’t try to cut corners.
In this blog post, I would like to look into the seemingly magical solution to all privacy problems: anonymization - and its evil twin pseudonymization. But first things first, let’s talk about anonymization.
Let’s talk about Anonymization
GDPR defines anonymous information as “…information which does not relate to an identified or identifiable natural person or [as] personal data rendered anonymous in such a manner that the data subject is not or no longer identifiable”. Hence if there is no way to (re-)identify the customer, the information is anonymous and isn’t beholden to privacy regulations anymore. From a privacy perspective, anonymous data is free to use, share, and monetize. Problem solved. Right? Well, not quite.
Only a little bit re-identifiable
When we talk about anonymization we need to distinguish between anonymous data, as described in the previous paragraph, and the classical anonymization techniques which are used to make private data less personal but maintain the semantics and syntax.
Some widely known classical anonymization methods include randomization, noise injection, tokenization, suppression, shuffling, generalization, etc. Normally multiple anonymization techniques are combined into a more or less standardized anonymization design process that results in less personal data.
One of the biggest general misconceptions about anonymization today is that anonymized data is equal to anonymous data. Anonymity is a binary class. Data is either anonymous or it isn’t. If the data subject can be re-identified - with more or less effort - no matter how sophisticated your anonymization process is - then that data ISN’T anonymous. And guess what, the majority of anonymized data isn’t anonymous.
Have I just revealed something novel? Actually no, the truth about anonymization has been here for a while, it’s just not evenly distributed. More and more anonymization practitioners are getting vocal about the fact that calling less personal data ‘anonymous’ creates a false sense of security that gives people tacit permission to share data without worrying about privacy.
Understanding the Privacy-Utility Trade-off
So how big is the utility gap between “less personal data” (or data that was anonymized through classical anonymization) and truly anonymous data?
Most of the classical anonymization techniques in use today cannot produce truly anonymous data. Instead, they are making data less personal - all while trying to retain as much data utility as possible. The more information that gets masked or obfuscated, the weaker insights of the datasets and vice versa. This is the so-called privacy-utility trade-off.

In the era of big data, however, anonymization is getting much more difficult and large-scale datasets - with often hundreds or thousands of attributes - uncover the shortcomings of classical anonymization methods. Today the “privacy - utility trade-off” has reached the paradox state where the entire utility of a dataset can be destroyed (making it completely useless for the intended application scenario) and still, the data won’t be anonymous (see below).

Looking for trouble with anonymized (but not anonymous) data
In the next section of this blog post, I would like to look deeper into two big problems anonymization is facing when it comes to re-identification of data subjects:
- Problem #1 can be described as “I still don’t know who you are, but I can definitely identify you as a unique data subject in the dataset”
- Problem #2 is sitting on top of problem #1 and is putting the final nail into the coffin of classical anonymization techniques. It can be described as “If I link your anonymized data with additional data, all it takes is one matching record to definitely identify you and all of your data in the anonymized dataset”
Let’s look a bit more in-depth into both problems and put them into a banking perspective.
Problem #1: A few data points is all it takes to make an individual unique
We all are more special than we think we are. The richness and high granularity of our (recorded) behavior are what make us so unique. Big data is a blessing when it comes to understanding and anticipating customer behavior (utility) but it’s a curse when it comes to anonymization (privacy).
Researchers could prove that 80% of total customers could be re-identified by only 3 random credit card transactions when only the merchant and the date of the transaction were revealed. Recently, I personally participated in a project where a big bank tried to reproduce these findings. The bank was surprised to find that 70% of their customers could be re-identified by only 2 random payment card transactions.
Consider, neither merchant nor date of transaction are considered PII attributes. And still, these unique behavioral traces can be used as a fingerprint to definitely identify someone. These so-called indirect identifiers are deeply interwoven with customer data and can’t be easily removed.
Problem #2: Sometimes all it takes is a single data point
The process of keeping anonymized data separate from any additional customer information is already very difficult for a single organization. Privacy sensitive data is queried daily across different business units and is stored and used in different contexts. One matching record of two queries is all it takes to re-identify a customer.
This problem grows even bigger if we look at how the data flows between different legal entities that share a relationship with the same customer. As this blog post series is focusing on the banking industry let’s take the example of the payment card process and the famous 4-corner model to demonstrate the multi-party anonymization challenge.
At the moment when the customer makes the purchase with the payment card, the privacy-sensitive data is moved and processed by many different legal entities: acquirer, merchant, card issuer, card scheme, payment facilitators, etc. Many of the aforementioned stakeholders collect and store the record of the same payment transaction and would be able to easily re-identify a customer if they would get an anonymized dataset of another party in their hands. Sharing anonymized data outside of the organization means looking for trouble.
How not to monetize financial data
Talking about trouble, let’s look into an example of what happens when a company shares not-as-anonymous-as-expected financial data with third parties. Selling credit card data is a big business across the world, especially in the United States. This February an internal document of the largest financial data broker in the US leaked to the public acknowledging that the consumer payment data could be unmasked, respectively re-identified.
The leaked document revealed what type of data the financial data broker shares with its business customers, how the data is managed across its infrastructure, and the specific anonymization techniques used to protect the privacy of the payment cardholders. To cut the story short - the shared data was not at all anonymous - it was only pseudonymized. But what is pseudonymization after all and why do I refer to it as the anonymization’s evil twin?
Pseudonymization ≠ Anonymization
According to GDPR pseudonymization stands for “the processing of personal data in such a way that the data can no longer be attributed to a specific data subject without the use of additional information.” GDPR also states that“…data which have undergone pseudonymization, which could be attributed to a natural person by the use of additional information, should be considered to be information on an identifiable natural person.” Therefore pseudonymized data are considered to be personal data and must comply with the GDPR.
During the pseudonymization, all personally identifiable information (PII) like name, address, or social security number is identified and either removed, masked, or replaced with other values. The rest of the data (not direct PII) stays the same. This means that pseudonymized data still contain parts of identifiable information hidden in the non-PII attributes. This is also the reason why GDPR considers pseudonymization to be only a data protection technique and it is not considered to be a part of anonymization techniques.
Bullshit Anonymization
Using pseudonymization as a synonym to anonymization is wrong and it makes an already complicated situation only worse but it happens all the time within the banking industry. Re-identifying customers from data that has been anonymized by classical anonymization techniques is getting easier and easier - but re-identifying customers from pseudonymized data is child’s play. Remember the story about the financial data broker from above who was selling pseudonymized data?
The opinions of two academic researchers interviewed in the original news article commenting on the level of anonymization are spot on. The less diplomatic one reads “This is bullshit 'anonymization'” and the moderate one states “the data in itself seems to me to only be pseudonymized”. Now add one and one together and ask yourself how many poorly anonymized or only pseudonymized datasets are circulating within your organization at this very moment?
When classical anonymization techniques and pseudonymization fail
Faced with huge legal and reputational risks and aware that classical privacy methods fail to guarantee privacy protection, banks are extremely reluctant to use, share, and monetize customer data. Zero-Trust policies are replacing castle-and-moat approaches. Each access to customer data has to be previously mapped and restricted to the bare minimum.
Access to customer data gets scarce and only reserved for a few vetted data scientists and data engineers. This leads to bottlenecks and prevents or impedes many important activities within the bank: data-driven innovation, product development, and testing with as-production-like-as-possible data, startup co-operations, as well as the easy setup of sandboxes for open banking. Data Security and Data Privacy Officers become the inhibitors of the progress and take the blame for the insufficiencies of classical privacy methods.
Is this the harsh reality banks have to get used to? Are there privacy methods at sight that could change the current paradigm that privacy protection always comes at the cost of data utility? Can we keep the Zero-Trust policies in place while at the same time creating innovation sandboxes for internal teams and partner networks to create value from high-quality anonymous data? In my next blog post, I will answer these questions and look into a new privacy method that lets you have the cake and eat it too. Stay tuned.
Whenever companies spend money and make investments, they are looking for one thing: a positive return on investment (ROI). At the end of the day, this can be achieved through lowering costs or increasing revenues. If you look at a profit and loss statement, there aren’t any other levers to pull. In practice, investment decisions are more complicated though. But with this blog post I won't dive into the complexities of corporate purchasing processes. Instead I will highlight some of the very clear economic values that synthetic data brings to organizations and discuss how to quantify them.
Because although it sounds great in principle to “unlock data silos” and “enable data-driven innovation”, it won’t necessarily get you approval for your business case by itself. There are arguably many different angles one could take to look at this topic. I decided to structure the discussion around two very simple questions:
How large will the likely ROI be?
How easy is it to quantify the likely ROI?
This gives the following nice matrix:
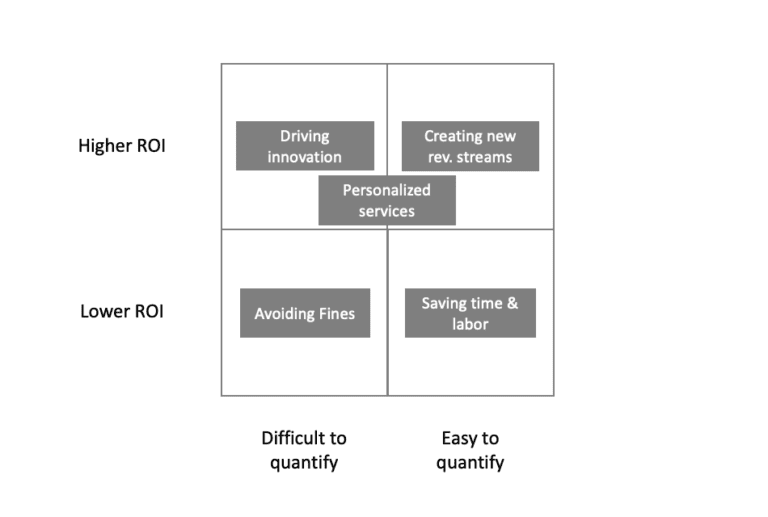
With that matrix in mind let’s look at two very quantifiable value creators of synthetic data and three lesser so:
Synthetic data to create new revenue streams
Let’s start on a strong note. This use-case sits in the desirable top right corner of our matrix and that is for a good reason. At one point or another, it becomes the goal of most companies to create additional revenue streams that lie outside of its current core business. History has shown that companies that innovate in such a way are more likely to survive over a long time period and are more resistant to external shocks. We’ve all read it so many times that I won’t repeat here that data is the … Instead, let’s think about the following scenario. You operate a large hospital chain. Every day thousands of patients are treated with certain medications. You do not only collect this data, but also important information about the results of these treatments. That data is not only gold for any pharmaceutical company, it’s also gold for health insurance companies, researchers and the entire health system in general. The only problem is: you can’t share that individual data on a granular level due to privacy concerns and HIPAA.
Enter the world of synthetic data. You have implemented a solution to synthesize this treatment data and are able to share these datasets in a privacy preserving way. However, you are not giving this data away for free, as you are well aware of the value you are creating for the recipients of this data. In fact, with a quick back of the envelope calculation you are able to assess the impact of your data for different recipients: reduced health insurance costs by x%, improved medication performance by y%, etc.
Depending on the data assets that you own and the potential recipients, the rewards can be huge and the ROI of this business case easy to quantify. But while we have seen synthetic data creating new waves of revenue streams for some companies, overall progress in this space has been relatively slow as organizations tend to focus on internal data monetization opportunities first.
Saving time (and manual labor) with synthetic data
Time is money and that is especially true when time involves manual labor. If you look at the booming robotic process automation (RPA) industry, that becomes obvious. It’s straightforward to calculate the ROI for any of these solutions. Estimate the time a manual process takes, look at the labor costs associated with it, subtract the cost of implementing and maintaining the RPA solution, and there you have your ROI.
While it’s not as straightforward with synthetic data projects, the concept is the same. Creating test data or anonymizing datasets is often a manual and time-consuming process. Depending on who is involved, these tasks are often completed by data engineers or data scientists who are expensive and in high demand. Imagine a scenario where it currently takes you about three months before you have a specific dataset anonymized for sharing with a third party. This involves manual work to anonymize the data, coordination with legal on the approach, as well as final clearance. While three months may sound like a long time, there are companies where such a process can take up to six months or longer!
Now imagine a process that takes one week instead, which becomes possible when you are using synthetic data with automated privacy safeguards that have already been pre-checked by legal. There is no extensive manual work involved. The process is simple: you provide the input data, the data is synthesized by the platform, and you are good to go with the output data. The one week delay basically results from a certain backlog where your data request needs to wait until other work has been completed.
The ROI calculation for the manual labor saved is straight forward, but probably will only result in overall lower ROI values. But on top of that, you get an extra benefit that is more difficult to quantify: reduced time to data! This time saving could result in an important partnership won or competitive edge that otherwise might have been a lost opportunity instead.
Synthetic data to avoid privacy fines
Regulations can sometimes be a burden and painful. While most of us do not like to deal with bureaucracy and excessive rules, we are certainly happy that particular regulations exist and welcome some with open arms. I prefer to fly a plane that is well maintained, with a pilot who has gone through proper training, for example. At MOSTLY AI, we are big fans of privacy regulations. Yes, they can have a negative impact on business, but they also promote what should be in our all interest: the protection of our privacy. We see a vast number of companies in the market that have started to embrace that mindset as well. For some that have not, legislators have taken precautionary measures in the form of fines for privacy violations. Like it or not, ensuring compliance by meeting privacy standards, and thus avoiding fines, is a legitimate reason for companies to invest in technology. Synthetic data comes in handy here as well.
Imagine you are working with an outsourced software testing company. Because you really need to be sure that these tests are performed as realistically as possible, you are using real customer data for these tests. Your service provider has ensured many safeguards for your data but becomes the victim of an internal hack and some of your sensitive customer data finds its way to the darknet. Suddenly, you’re faced not only with negative press but also with a hefty fine, because you did not have consent from all of your users to hand their personal data to this outsourced service provider.
When calculating the ROI for this case you have to take three things into consideration: what is the likelihood of such an event happening, what is the possible fine you could be confronted with, and what is the potential reputational damage you might suffer. While the number of fines and the amounts associated with related GDPR violations have increased dramatically in 2019 (reaching up to hundreds of million EUR per fine, see for example here), the actual risk your company might be facing could still be relatively small. As such, it’s not only difficult to quantify possible fines, but the business case will also likely show a rather low ROI. In general, we do not like to base business cases purely on this scenario – protecting your customer’s privacy is something that should be done, because it is the right thing to do, not in order to avoid possible fines!
Creating personalized services with synthetic data
You don’t have to necessarily create entirely new revenue streams - synthetic data allows you to significantly improve existing revenue streams as well. If you are a large organization that handles sensitive customer data (for example a bank or insurance company) it is likely that your product team has very limited access to actual granular customer data. This leads to certain challenges when it comes to data-driven innovation. For example how would you design a new mobile banking app, if you had no access to the actual transaction data of your customers? Quite likely, you would need to rely on assumptions and secondary research, which both come with a whole bunch of limitations.
Synthetic data, on the other hand, enables product teams to work with -as-good-as-real data of their customers in a privacy-compliant manner. It allows them to design and bring to market highly personalized services and products. The ROI drivers for this use case most often come in the form of lower customer churn and number of new customers won (and indirectly via higher customer satisfaction). All of these are KPIs that can be easily measured, however, the possible impact is not always trivial to quantify upfront. As such this scenario sits somewhere in between “easy” and “difficult” to quantify in our matrix.
Driving innovation on top of synthetic datasets
Let’s end this blog post with the generic “driving innovation” use-case of synthetic data. Why? Because the ROI can be massive. Imagine you are a large bank. One thing you have been struggling with in the past is working with innovative start-ups, due to lengthy legal processes and constraints in sharing data. Let’s assume you were using a synthetic data platform that would allow you to quickly and easily share certain data assets with several promising start-ups while ensuring that the privacy of your customers stays protected. Now imagine that one of those start-ups develops a game-changing micro-lending app based on the insights it gathers from your synthetic, yet highly representative customer data. You decide to enter a strategic partnership with that start-up. Fast forward five years: that start-up has grown to become a unicorn and through your partnership, you create tens of millions in additional revenue every year. Possible? Certainly! Easy to quantify the ROI today? Definitely not!
But that’s exactly the challenge companies are currently facing, not only when it comes to investments in synthetic data solutions, but investments in innovation in general. At MOSTLY AI we strongly believe in the power of data and the value that comes from using data for customer-centric product development. These investments might not return a positive ROI this year, but they certainly can in the long run.
This blog post sheds some light on the complexity of evaluating the concrete value of synthetic data. Of course, every company and every purchase decision is unique. If you are currently in the process of exploring solutions to create synthetic data, I’d be happy to help you quantify the value that you might be able to get out of such a solution - just reach out to me via LinkedIn.
About the author
Tobias Hann, holds a PhD in business from the Vienna University of Business and Economics as well as an MBA from the Haas School of Business, UC Berkeley. After having worked several years in management consulting and at various start-ups, he currently serves as the CEO of MOSTLY AI.
Looking back at data-driven Innovation in Banking
Looking back at my years at a retail bank that involved developing new digital offerings, I often remember hearing the proverb “You can’t have your cake and eat it too.” Trade-offs are an integral part of innovation in a heavily regulated and risk-averse environment like banking.
Normally, you start with a really exciting idea. This later gets watered down by a series of trade-offs (security and legal requirements, infrastructure limitations, etc.) which then results in a super-secure and compliant outcome that fits perfectly into a bank’s infrastructure. But the offering itself is often “dead on arrival”. Hence, a large part of my job at that time consisted of applying lateral thinking methods: finding ways around the internal limitations in order to keep innovations alive.
Some of my most exciting projects back then were data monetization projects. We were asking ourselves how could our bank unlock the untapped utility hidden in credit and debit transactional data and transform it into added value for our private and corporate customers. The sky seemed to be the limit. But very soon we realized that the biggest limiting factor was much closer to earth. In fact, it was as close as the office of our bank’s data protection officer.
Innovation vs. Privacy
As you could imagine, a customer's data is subject to quite stringent data protection legislation. I’ll use GDPR as the most popular data protection regulation to explain the major challenges of data-driven innovation in banking, but using other regulations wouldn’t make a big difference to my arguments. Let’s look at three major privacy-related stumbling blocks that you have to get around if you want to succeed with your data-based innovation:
a. Legal basis
Everything starts with a legal basis for processing customer data. Most data-driven innovations require a previous customer’s consent. In addition to explicit consent, there are some other legitimate reasons for data processing, such as the “need to process the data in order to comply with a legal obligation”. But don’t expect that your idea will fall into one of those categories. Getting customer consent for data processing is a herculean challenge on its own. It’s essential to make sure that customer consent was given freely, specific to the data usage intent, informed, unambiguous, and able to be revoked at any time. Even the best marketing campaigns won’t get you more than 15-20% approval for your new service from your target group. Many predictive applications require a critical mass of data subjects, whose data are feeding the algorithms. Therefore ask yourself early whether you will be able to get a sufficient number of customers to consent.
b. Security and Confidentiality
With the legal basis fulfilled, a step not many ideas overcome, the next challenge awaits you: secure processing. The processing itself must guarantee appropriate security and confidentiality of the personal data. This is usually a mix of different security measures of data protection involving data access management over encryption to data anonymization – the seemingly magical solution that transforms personal data into non-personal, free to use data, as it falls outside GDPR’s scope.
These security and protection measures are a necessity for all phases of product development that require customer data. Data has to be protected throughout the product life cycle with permanently changing product features, product-related infrastructure and up/downstream applications. A compelling argument for privacy and data security “by design”, as building strong privacy and security processes into your new data-driven product right from the very beginning allows keeping the effort to a minimum – even in a constantly changing environment.
c. Public perception
However, having a legal basis for data processing and even privacy and data security by design doesn’t offer absolute protection against a public outrage. If your new product or service is perceived as unethical, manipulative, reinforcing biases and disbalances the power between the bank and its customers it will not take much to fail upon arrival. Mark Zuckerberg famously said in 2004: “You can be unethical and still be legal; that’s the way I live my life.” This type of thinking might be an option for a company like Facebook but it is definitely not an alternative for a bank that needs to be trusted by its customers
Sometimes it’s not even the question of ethics. One inept communication can destroy the trust you spent years building. Letting public imagination run wild with privacy related topics can end in a disaster like what happened with this Dutch bank in 2014. Faced with public outrage, the bank had to refrain from its initial intention to use customers’ spending habits for targeted ads.
Required by law or not, be transparent, ethical, and aware that more and more of your customers are becoming data and privacy literate. Are the short term gains of an insight worth the collective trust of your customers? Don’t forget that data privacy is a very sensitive topic that requires extremely clear communication and an in-depth ethical review.
No lateral thinking will get you around privacy and data security requirements. Any mistake in the privacy design of your data-driven innovation could lead to a violation of data privacy legislation or, even worse, put your bank's most valuable asset at risk: customer trust.
Should you just give up being innovative?
There’s no “fail fast” in data privacy matters. There are so many moving parts, so many juggling balls to keep in the air concerning privacy and data security topics that at this point, most of the innovators within the bank will simply give up. Under those circumstances, you often have to choose between data-driven innovation and data privacy. You can’t have your cake and eat it too. Or can you?
More and more organizations are starting to understand that there is significant commercial value behind the ability to protect customer privacy. Because only customer data that can be used, shared, and monetized in a privacy-compliant way is commercially valuable data. Over the last few years, I’ve observed an entirely new market quietly developing with the goal of achieving the state-of-the-art privacy protection modern data-driven organizations require to operate and innovate with their customer data.
New Privacy Approaches enable Innovation
The three most promising new privacy approaches in this market are differential privacy, homomorphic encryption and AI-generated synthetic data.
Differential privacy is an abstract mathematical framework for privacy to find the maximum influence any single person can have on a given database query, algorithm, or any other statistical method to quantify privacy risk for individuals in the data set. In recent years applications of differential privacy have been used by tech giants like Google and Apple to run analytics on private data. Those applications faced some criticism from the privacy research community because they don’t reveal how they calculate differential privacy and some researchers argue that companies like Apple even sacrifice some privacy in order to increase data utility.
Homomorphic encryption is a class of encryption methods that enable computing on data while the data is encrypted. The data stays encrypted during the entire process of processing. The secret key doesn’t have to be shared with the entity that processes the data. The output of processing remains encrypted and can only be revealed by the owner of the secret key.
One of the most fascinating technologies in the PrivacyTech market is AI-generated synthetic data. It is artificially generated data that is based on a given real-world dataset. But even though synthetic data accurately resembles its real counterpart and its statistical properties, it does not include any customer’s actual information. Thus it is fully anonymous and exempt from GDPR.
To sum it up, these three new privacy protection techniques finally allow banks to leverage the utility hidden in customer data while at the same time providing the highest level of privacy protection. Privacy protection can’t be used as an excuse to not innovate with data anymore. Innovations in privacy protection are the key to fixing data-driven innovation.
This was the first part of a mini-series on PrivacyTech in banking. But before diving deeper into new privacy protection techniques and especially my favorite – synthetic data, in the next part, I will explore the shortcomings of various anonymization techniques frequently used at banks and the consequences involved. Your anonymized customer data isn’t as anonymous as you might think it is. Stay tuned...