Computes
With flexible computes, you can define compute resources from Kubernetes clusters that you can then assign to run your generator training and synthetic data generation workloads. You can use compute resources to add GPU-capable compute that can significantly speed up the time to train new generators and generate synthetic datasets.
Add a new compute
You can define any of your existing Kubernetes compute resources as a new compute in MOSTLY AI.
Prerequisites
- Before you define a new compute, confirm the available compute resources in your Kubernetes cluster.
- You need to be an account Super Admin to add a new compute.
Kubernetes compute
Steps
-
From the profile menu, select Computes.
-
On the Computes page, click + New compute.
-
Select Kubernetes.
-
Define the compute configuration.
Kubernetes compute parameter Description Name A unique name for the compute. CPUs The number of CPU cores. Memory The amount of memory. GPUs The number of GPUs. GPU memory The amount of GPU memory. Toleration A toleration that matches the taint defined for your cluster.
⚠️ Leave empty if in thevalues.yamlyou need to set themostly_coordinator.deployment.core_job.tolerationOperatortoExists.Order Index The order in which the compute appears in the Compute drop-down.
The default compute hasorder_index=1. -
Click Save.
Result
The next time users configure a new generator training or synthetic dataset, they can select the new compute from the Compute drop-down list.
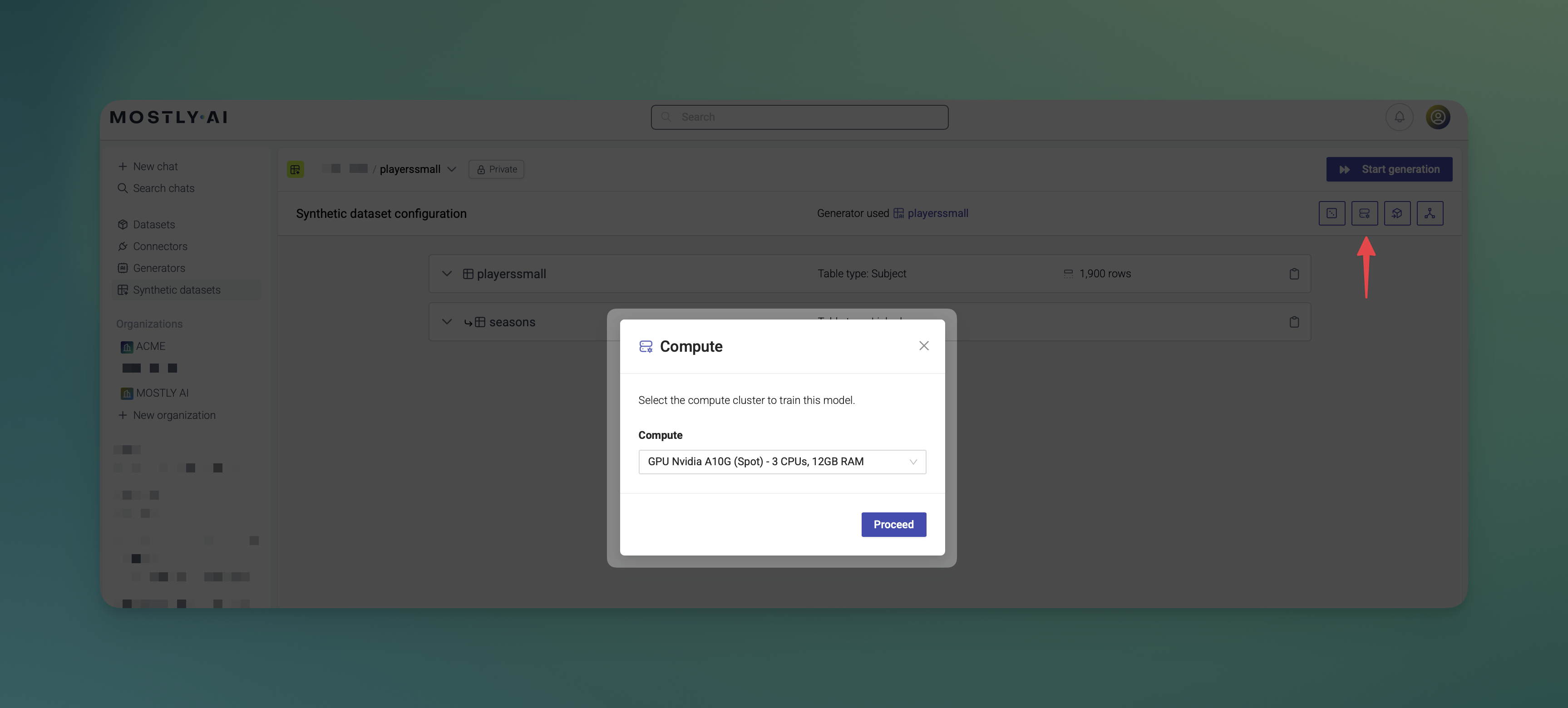
The new compute is visible in the Computes list. A Super Admin can edit or delete it at any time.
Edit a compute
You can make changes to exising computes.
Steps
- Open the Compute kebab menu and select Edit.
- Change the compute configuration.
- Click Save.
Result
The compute configuration is now updated.
Delete a compute
You can delete an existing compute from its kebab menu.
Steps
- Open the Compute kebab menu and select Delete.
- Click Yes, delete compute in the confirmation pop-up.