Set encoding types
When you add your original table data to a generator, MOSTLY AI assigns an encoding type to each column. The assignment depends on the data inside the columns (for file uploads and cloud storage files) or on the data types defined in the database schema (for database data sources).
About encoding types
The encoding type defines how your original data is encoded before AI model training. This is a requirement for the training phase, when the data needs to be in a format that can be processed for the purposes of machine learning.
As a best practice, check the auto-detected encoding types and, if needed, select an encoding type that is a better match for your data.
Set the encoding type of a column
When you add a table to a generator in the web application, MOSTLY AI analyzes the data in each column and auto-assigns the best possible encoding type. You can always select a different encoding type.
With the Synthetic Data SDK, you do not need to specify an encoding type when you submit a new generator configuration for training. MOSTLY AI will again analyze each column and assign the best possible encoding type. You can still use the model_encoding_type key to enforce an encoding type.
Steps
- On the generator Data configuration page, click a table to expand it and view its encoding types.
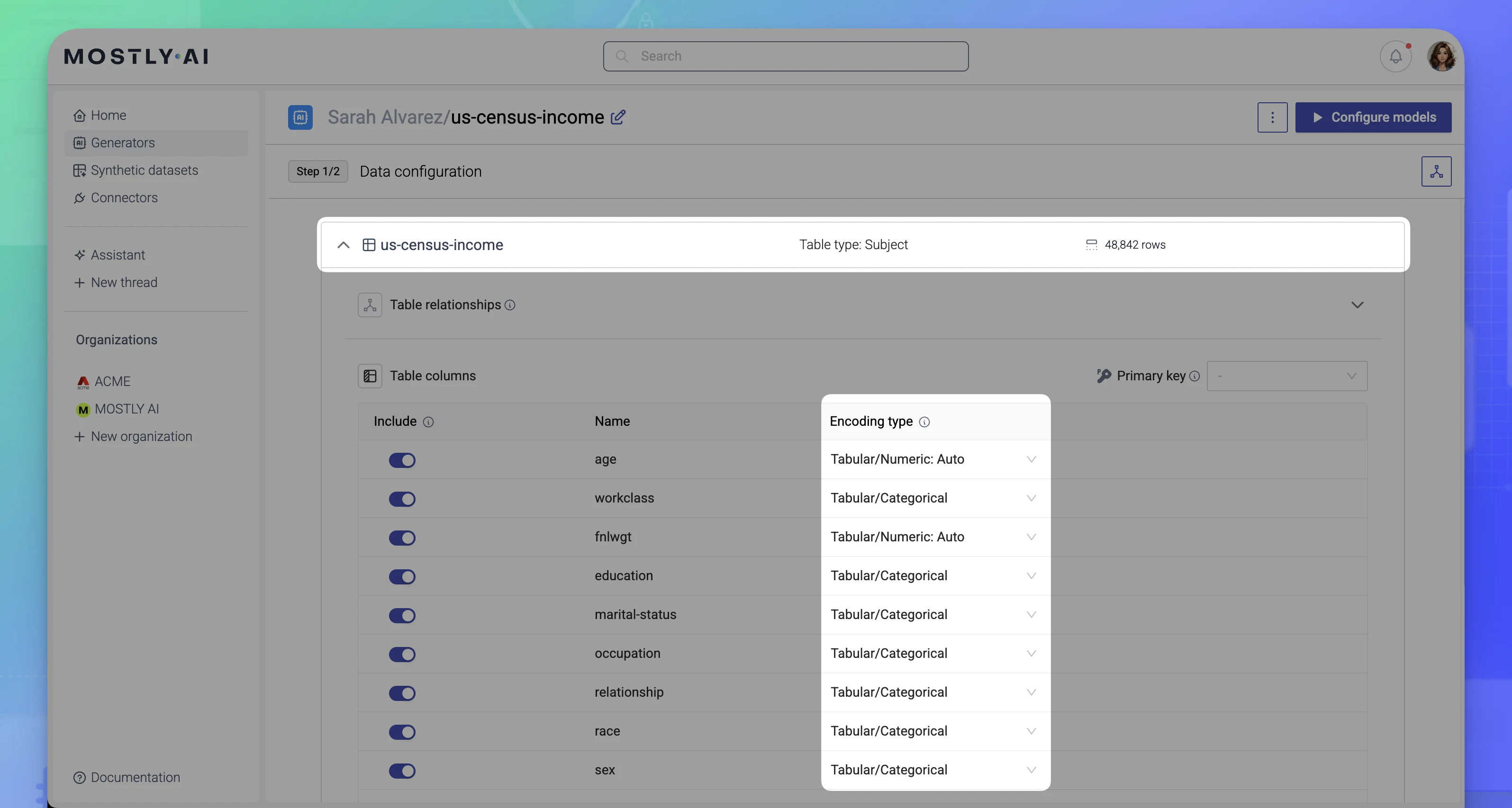
- Click in the Encoding type area for a column.
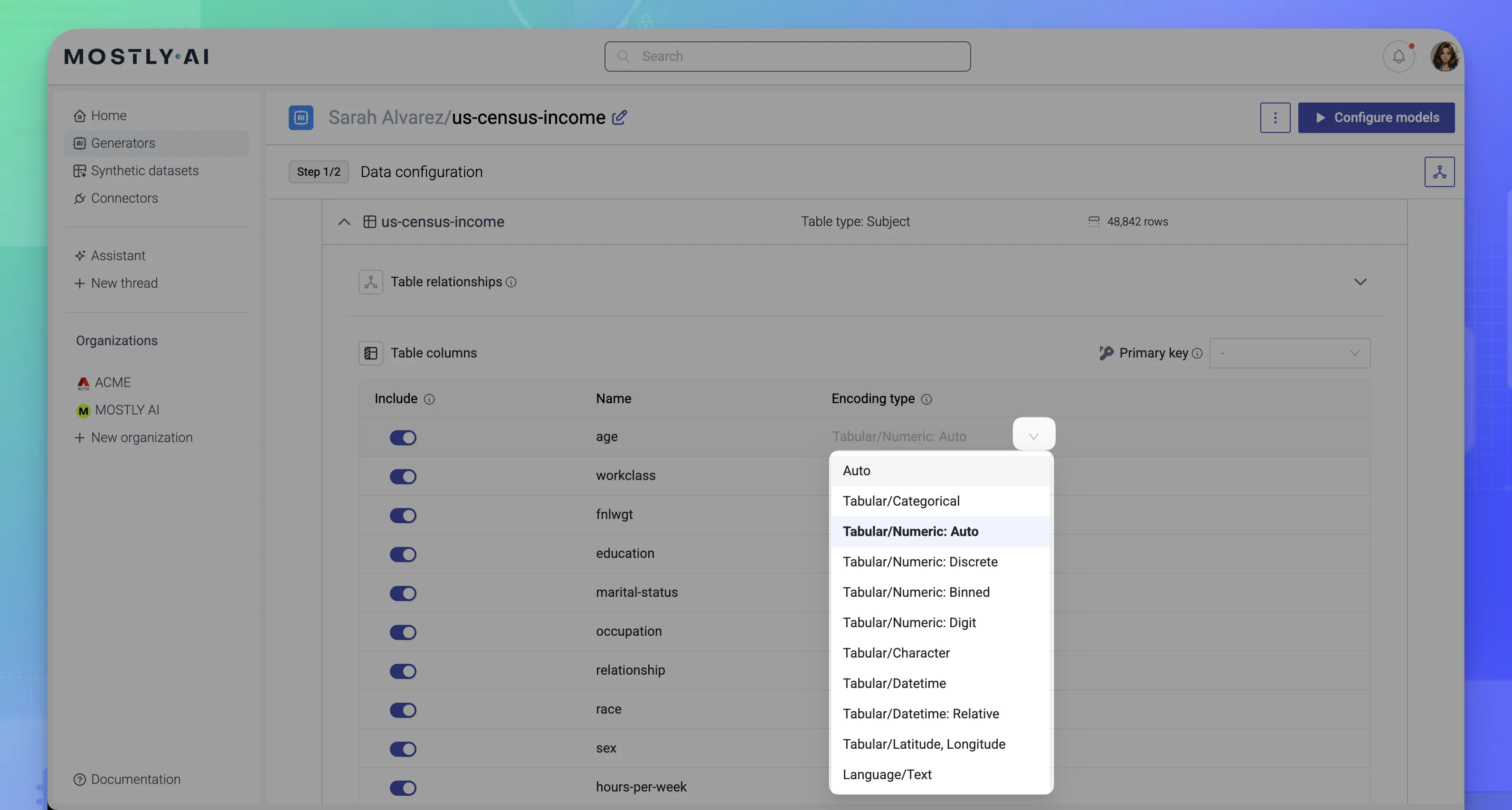
- Set a column type that best describes the data in the column.
For more information about each type, see the sections below.
Encoding types
When you select an encoding type, you also select the model to train or fine-tune. MOSTLY AI supports tabular and language models.
Tabular models. Tabular models train on original tabular data to then generate privacy-preserving tabular synthetic data. Their encoding types are prefixed with Tabular/ (in the Platform UI) or TABULAR_ (for the Synthetic Data SDK). MOSTLY AI supports three tabular model sizes.
The list of tabular models includes:
- MOSTLY AI/Small
- MOSTLY AI/Medium
- MOSTLY AI/Large
Language models. With language models, you can generate privacy-preserving synthetic text data. Encoding types for language models are prefixed with Language/ (when using the Platform UI) or💡Selecting a model size is part of the speed vs accuracy trade-off when training a generator. For details, see Increase model size and Select a smaller model.
LANGUAGE_(when using the Synthetic Data SDK). To learn more about the supported use cases, check out each Language encoding type.
The list of language models includes:
Tabular
Tabular encoding types include support for multiple data types, such as categorical, numeric, datetime, and geolocation data.
Categorical
A categorical variable has a fixed set of possible values that are already present in the input data. An example of such a variable is T-shirt size, which could consist of the following categories: ‘XS, S, M, L, XL’. The synthetic data will only contain categories that were present in the original data. Categorical variables thus prevent random values (for instance, ‘XM, A, B’) from appearing in your synthetic dataset.
If the automatic encoding type detection does not recognize a Numeric or Datetime column as such, it is encoded as Categorical.
You can control how the rare category protection mechanism works with Value protection settings and the Rare category replacement method which appear on the Model configuration page of a generator. These settings help with protecting rare categories. Rare categories may cause re-identification of outliers among your data subjects if they’re present in the resulting synthetic data.
There are two rare category protection methods available with which you can mask these categories:
Constant
Replaces rare categories with the value _RARE_.
_RARE_ category in your synthetic data and that can impact your downstream tasks. To avoid that, you can use the Sample method.Sample
Replaces rare categories with categories that will appear in the synthetic version of this column. The categories are sampled from the original data based on their frequency. The more frequent a category is, the more likely it will be selected.
Numeric: Auto
With Numeric: Auto, MOSTLY AI uses heuristics to decide the most appropriate Numeric encoding type based on the data in a column. For most cases, select Numeric:Auto or leave it selected by default.
Numeric: Discrete
Discrete treats the numeric data in the column as categorical values. You can use this option for columns that have categorical numeric codes, such as:
- ZIP codes, postal codes, country phone codes
- binary
TrueorFalsethat are represented as the numeric values0and1 - any categorical data which are represented with numeric values
Rare category protection also applies to Numeric: Discrete columns. When you generate a synthetic dataset, MOSTLY AI replaces rare numeric categories with a non-rare numeric category in the column (applying the Sample method as explained above for Categorical columns). _RARE_ values are not generated for Numeric: Discrete columns.
Numeric: Binned
You can use Binned for columns containing large integers or long decimals. MOSTLY AI bins the numerical values into 100 bins and considers each a category during training. During generation, MOSTLY AI samples values from the corresponding bin to generate the synthetic values in the column.
Numeric: Digit
Numeric: Digit recognizes the data in the column as numeric values.
Character
Use the Character encoding type to synthesize short strings with a consistent pattern, such as phone numbers, license plate numbers, company ID’s, transaction ID, and social security ID’s.
Datetime
Datetime refers to values that contain a date part and a time part. This encoding type enables MOSTLY AI to synthesize them and generate valid and statistically representative dates and times.
The following formats are supported:
| Format | Example | |
|---|---|---|
| Date | yyyy-MM-dd | 2020-02-08 |
| Datetime with hours | yyyy-MM-dd HHyyyy-MM-ddTHHyyyy-MM-ddTHHZ | 2020-02-08 092020-02-08T092020-02-08T09Z |
| Datetime with minutes | yyyy-MM-dd HH:mmyyyy-MM-ddTHH:mmyyyy-MM-ddTHH:mmZ | 2020-02-08 09:302020-02-08T09:302020-02-08T09:30Z |
| Datetime with seconds | yyyy-MM-dd HH:mm:ssyyyy-MM-ddTHH:mm:ssyyyy-MM-ddTHH:mm:ssZ | 2020-02-08 09:30:262020-02-08T09:30:262020-02-08T09:30:26Z |
| Datetime with milliseconds | yyyy-MM-dd HH:mm:ss.SSSyyyy-MM-ddTHH:mm:ss.SSSyyyy-MM-ddTHH:mm:ss.SSSZ | 2020-02-08 09:30:26.1232020-02-08T09:30:26.1232020-02-08T09:30:26.123Z |
Datetime: Relative
Datetime: Relative models the time interval between two subsequent events in the synthetic dataset. This encoding type causes the time between events to become very accurate, but the dates become less accurate.
Latitude, Longitude
Use the Latitude, Longitude encoding type to synthesize geolocation coordinates.
MOSTLY AI requires a geolocation coordinate to be encoded in a single field with the latitude and longitude as comma-separated values. The latitude must be on the comma’s left side and the longitude on the right.
The values must be in decimal degrees format and range from -90 to 90 for latitude and -180 to 180 for longitude. Their precision cannot be larger than five digits after the decimal dot. This translates to an accuracy of approx. 1 meter. Any additional digits will be ignored.
| Start location | End location | Some other location |
|---|---|---|
70.31311, 150.1 | -90.0, 180.0 | 37.311, 173.8998 |
-39.0, 120.33114 | 78.31112, -100.031 | -10.10, -80.901 |
Language
Use Language encoding types for the following use cases:
- fine-tune LLMs with tabular categorical, numeric, and datetime data
- fine-tune LLMs with original unstructured text data to then generate synthetic text data
- train on short text data to later generate privacy-preserving names, emails, and others
Categorical
Use the Language/Categorical encoding type to fine-tune an LLM with the categorical data in the selected column.
When you generate a synthetic dataset, you leverage the LLM pre-training and knowledge in the use cases listed below.
- Generate representative categories even when fine-tuning with smaller datasets
- Apply conditional simulation by seeding numeric values that weren’t present in the original data
Numeric
Use the Language/Numeric encoding type to fine-tune an LLM with the numeric data in the selected column.
Datetime
Use the Language/Categorical encoding type to fine-tune an LLM with the numeric data in the selected column.
Text
With the Language/Text encoding type, you have two general choices:
- train the not pre-trained MOSTLY AI/LSTM model with unstructured text to be able to generate unstructured natural language texts up to 1,000 characters
- fine-tune a HuggingFace LLM with original unstructured language texts of any length to generate unstructured synthetic text data
Models
MOSTLY AI supports the following models for generating tabular synthetic data and unstructured synthetic text.
Tabular
For tabular data, you can train tabular models of three different sizes, depending on the trade-off between speed and accuracy.
MOSTLY AI/Small
The MOSTLY AI/Small tabular model uses fewer parameters, takes less memory and time, at the cost of accuracy
MOSTLY AI/Medium
The MOSTLY AI/Medium tabular model uses an optimal amount of parameters and is best for most use cases.
MOSTLY AI/Large
The MOSTLY AI/Large tabular model maximizes accuracy with more parameters but requires extra memory and time to complete training.
Language
For unstructured text data, you can:
- train the not pre-trained MOSTLY AI/LSTM
- fine-tune a HuggingFace LLM
MOSTLY AI/LSTMFromScratch-3m
The LSTM is a custom-trained model that synthesizes unstructured natural language texts.
You can use this encoding type to generate realistic, representative, and anonymous financial transaction texts, short user feedback, medical assessments, PII fields, etc. As the resulting synthetic texts are representative of the terms, tokens, and their co-occurrence in the original data, they can be confidently used in analytics and machine learning use cases, such as sentiment analysis and named-entity recognition.
Remember, the LSTM will perform better when trained on short, structured, repetitive sequences like names and short sentences while an LLM will perform better for longer, less structured samples like descriptions, email bodies, or notes.
Our text synthesis model is language-agnostic and doesn’t contain the biases of some pre-trained models—any content is solely learned from the original training data. This means that it can process any language, vernacular, and slang present in the original data.
The amount of data required to produce usable results depends on the diversity of the original texts’ vocabulary, categories, names, etc. As a rule of thumb, the more structure there is, the fewer samples are needed.
The synthetic texts are generated in a context-aware manner—the messages from a teenager are different from those of an 85-year old grandmother, for instance. By considering the other attributes of a synthetic subject’s profile, MOSTLY AI is capable of synthesizing appropriate natural language texts for each of them.
Below, you can find two examples. The first example demonstrates MOSTLY AI’s ability to synthesize entirely new names from a multilingual dataset. And the second example shows the result of synthesizing Tripadvisor reviews. Here you can see that the resulting texts accurately retain the context of the establishment they discuss (Restaurant or Hotel) and the synthesized rating.
Multilingual names dataset
| Original | Synthetic |
|---|---|
Nationality Name 1: Czech Svoboda 2: Greek Chrysanthopoulos 3: Spanish Ventura 4: Russian Gagarin 5: Japanese Yokoyama 6: English Parsons 7: Spanish Ruiz 8: Russian Chekhov 9: English Blake 10: English Wigley | Nationality Name 1: English Olsewood 2: German Kort 3: Japanese Misaghi 4: English Roger 5: Russian Lusov 6: Russian Zhuszenko 7: Japanese Noraghi 8: English Dalman 9: Russian Michov 10: Polish Poskan 11: Arabic Shaif |
Tripadvisor reviews
| Original |
|---|
Establishment Rating Review 1: Restaurant 6 Not bad, great interior but let down by unimaginative food. Perfectly good for a quick lunch or drink though, good ales 2: Hotel 2 Awful!!!! stunk of smoke guttering outside window ledge filled with cigarette ends and bottles. NOISY air con unit in room, husband had no sleep. 3: Restaurant 8 Helpful staff, pleasant enough with quick service. Sat at bar by revolving food server. Everything seemed nice and fresh. Good value. 4: Hotel 8 We stayed in a standard room at the hotel. The room was adequate, though a bit short on cupboard drawer space. 5: Hotel 4 Expected much more from here and they just didn't deliver, for the price of the room it was no different than any of the other cheaper aparthotels. |
| Synthetic |
|---|
Establishment Rating Review 1: Restaurant 8 My only complaint are the portion sizes. Lovely restaurant with good food, though. 2: Restaurant 8 I'm a year-round regular. Service is really friendly. The starters are OK and the seafood buffet is amazing and tasty. Overall a nice menu throughout and our children love it. 3: Hotel 8 This is a fantastic hotel. Great food but few options, a brilliant room and spent an excellent time. Very clean environment and a high level of service. 4: Hotel 2 I booked an offer for a spa day. The food was below-average, the room was dated, smelled of fried fish, and the staff has an attitude. 5: Hotel 2 We've been here before. But for £70, the rooms are still poor and glamourless. We spent a few days with 5 people and 4 were not impressed. |
HuggingFace LLMs
MOSTLY AI supports fine-tuning HuggingFace LLMs with original unstructured text data to be able to generate privacy-preserving synthetic text data.
When you deploy MOSTLY AI in your organization’s private cloud, you can integrate with as many HuggingFace LLMs as needed. For configuration details, see the Models configuration page.
On the MOSTLY AI Platform at https://app.mostly.ai, you can find the following text models available.
The list below includes all models you can use with the Language/Text encoding type. You will find the not pre-trained MOSTLY AI/LSTM model and the HuggingFace LLMs currently available on https://app.mostly.ai.
If a model you want to use is not available, contact MOSTLY AI Support.