Multi-table relationships
In a multi-table scenario, where you add 3 or more tables to a generator, you can have multiple tables with multiple relationships to other tables. For example, consider the Berka dataset.
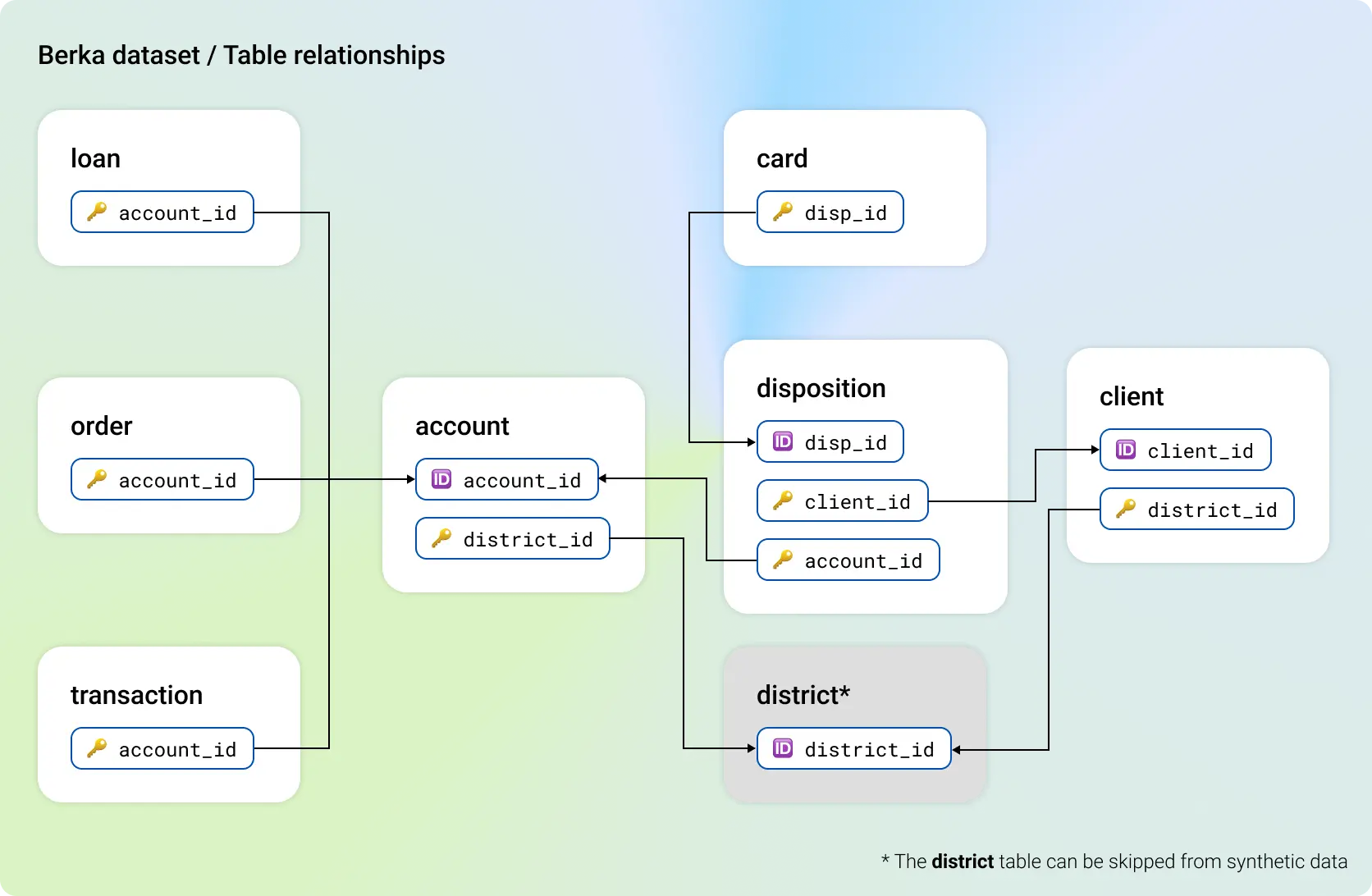
When you configure a multi-table generator, the most important task is to define the table relationships. The relationships define how the generator trains on your original data and how it retains the correlations and the referential integrity of your original data.
Context and non-context relationships
With a context relationship, your generator can fully retain the correlations and maintain the referential integrity between two tables. A non-context relationship maintains only the referential integrity. A table can have only one context relationship. Any additional relationships can be only non-context.
You define a relationship as context when you want the data in a table (child) to be generated in the context of the table it references (parent). Context relationships also help to fully retain the correlations across a grandparent - parent - child table hierarchy. You can again consider the Berka dataset.
Due to the context relationships, the correlations among account - disposition - card hierarchy are fully retained. The non-context relationship between client and disposition only maintains the referential integrity. You can switch this to a context relationship, but then the generator loses the opportunity to retain the hierarchical correlations among account - disposition - card.
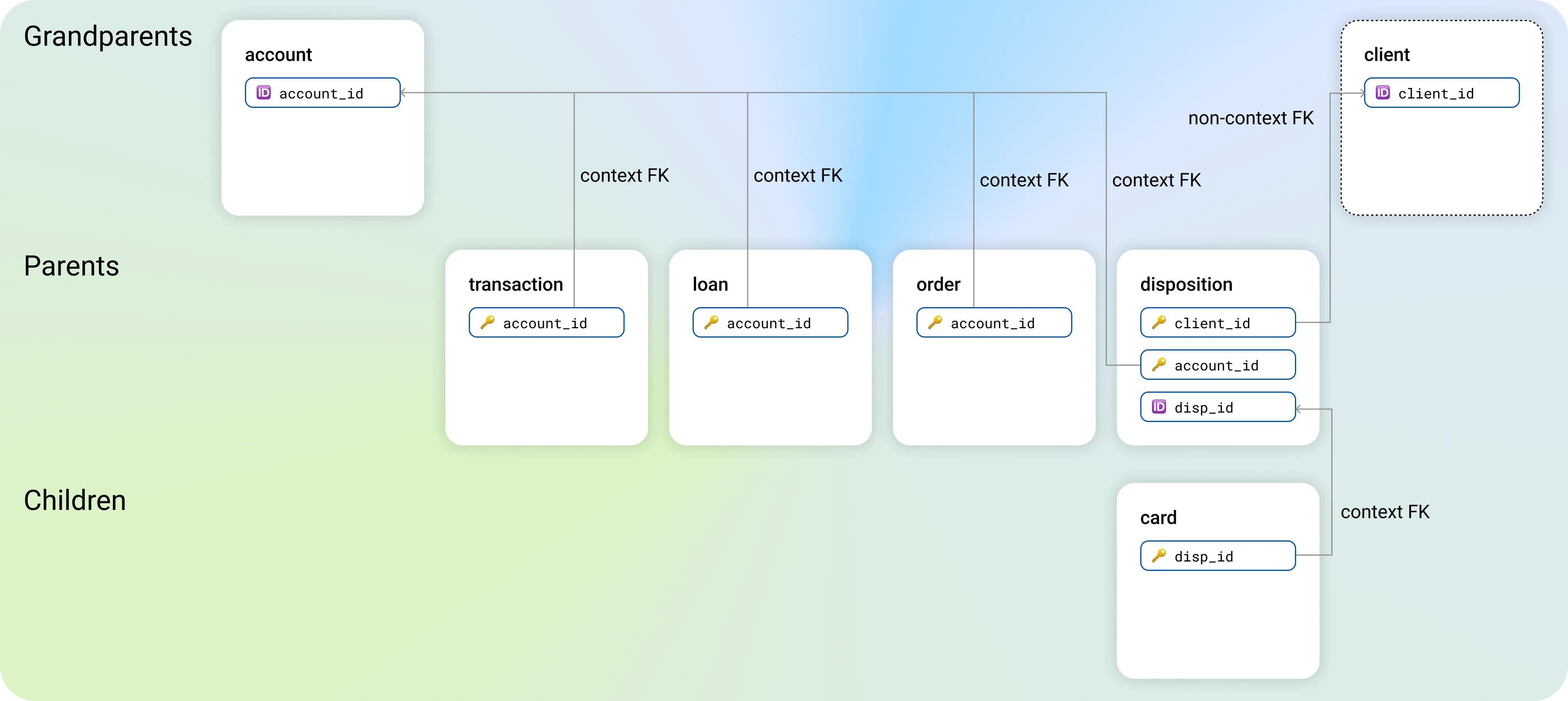
Decide: context or non-context
- If a time-series or events table has a single foreign key to another table, set that foreign key as context to make the time-series or events table a linked table.
- If a table has multiple foreign keys, prioritize as context the table with which you want to retain the correlations. Leave the remaining foreign keys as non-context.
Example: Berka relationships
For an example on how to set the table relationships in a multi-table dataset, you can use the Berka dataset. For reference, you can use the table schema from the illustrations above.
From the web interface, you can define each relationship with the configuration of a foreign key between two tables. For reference, use the diagrams above.
Steps
-
Download the Berka dataset and add all tables to a new generator.
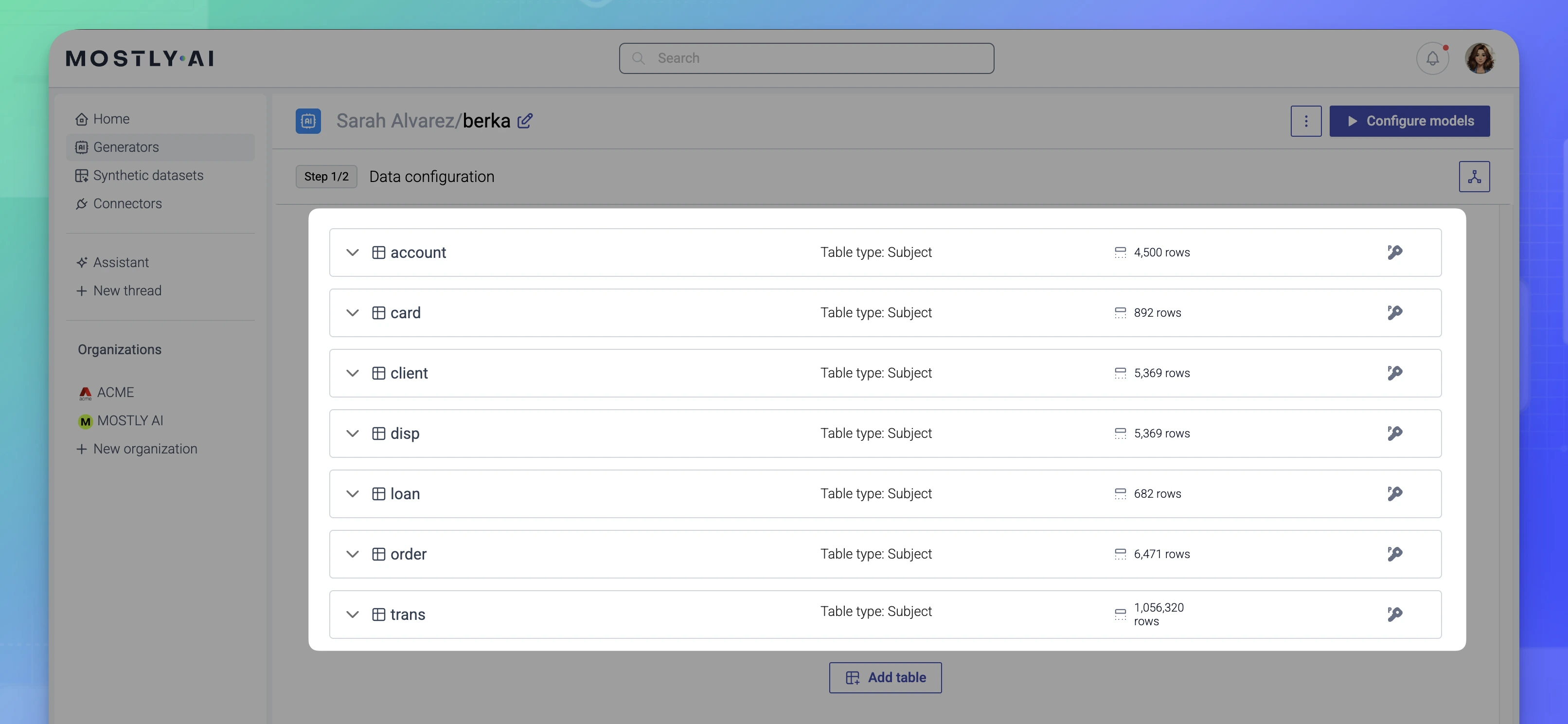
-
Define all required foreign keys.
📑For information about how to create a foreign key, see Two-table scenario.
-
Set a context foreign key from the
loantable (account_idcolumn) to theaccounttable. -
Set a context foreign key from the
ordertable (account_idcolumn) to theaccounttable. -
Set a context foreign key from the
transactiontable (account_idcolumn) to theaccounttable. -
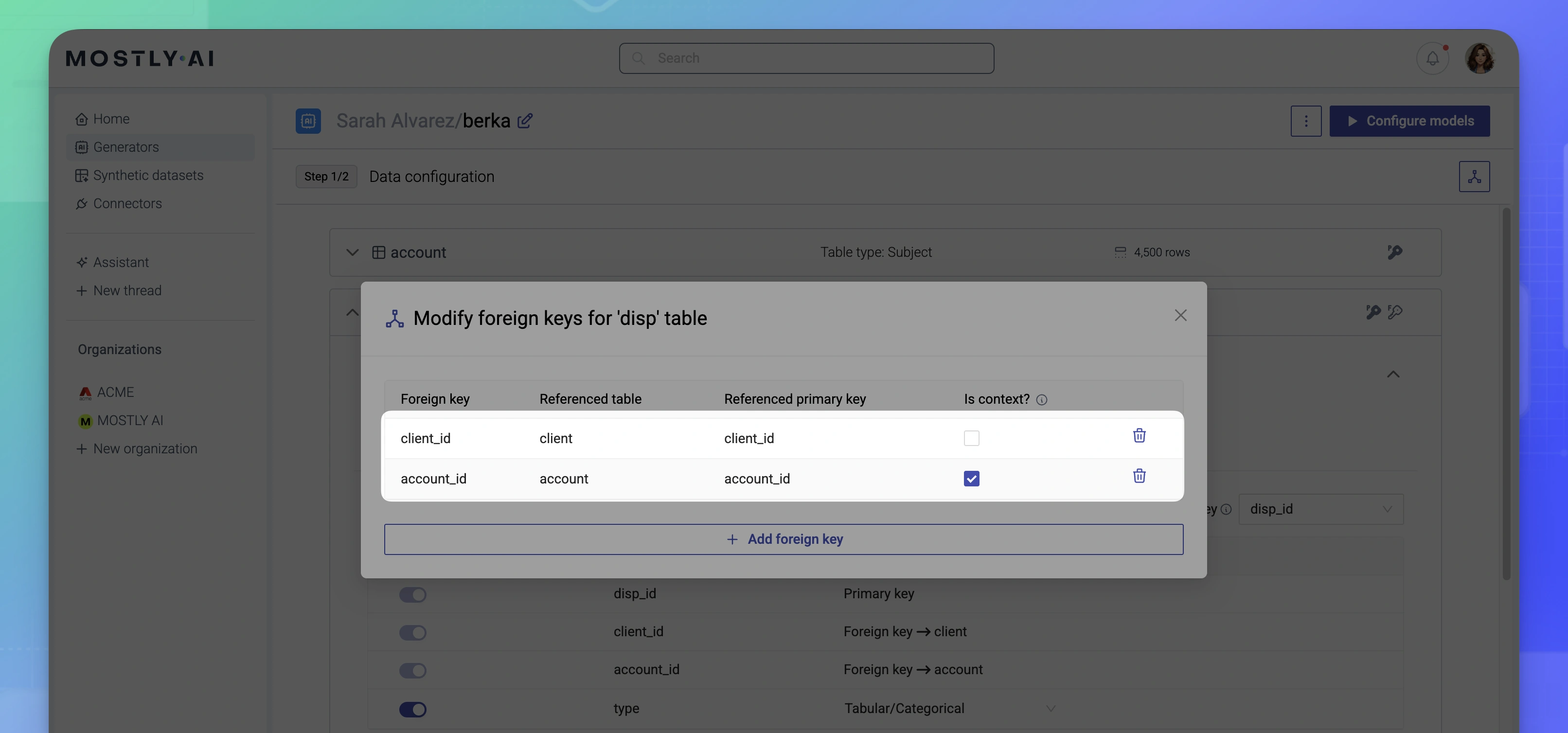
Set two foreign keys from the
disptable: one to theaccounttable, and another to theclienttable.💡Only one of the foreign keys can be context. Set as context the relationship for which you want to fully retain the correlations between the two tables.
To learn more, see Context foreign key and Non-context foreign key.
- Set a context foreign key from the
cardtable (disp_idcolumn) to thedisptable.
- Set a context foreign key from the
Result
With all required foreign keys set, the Data configuration page provides a hierarchical overview of the table relationships and lists all primary keys and foreign keys
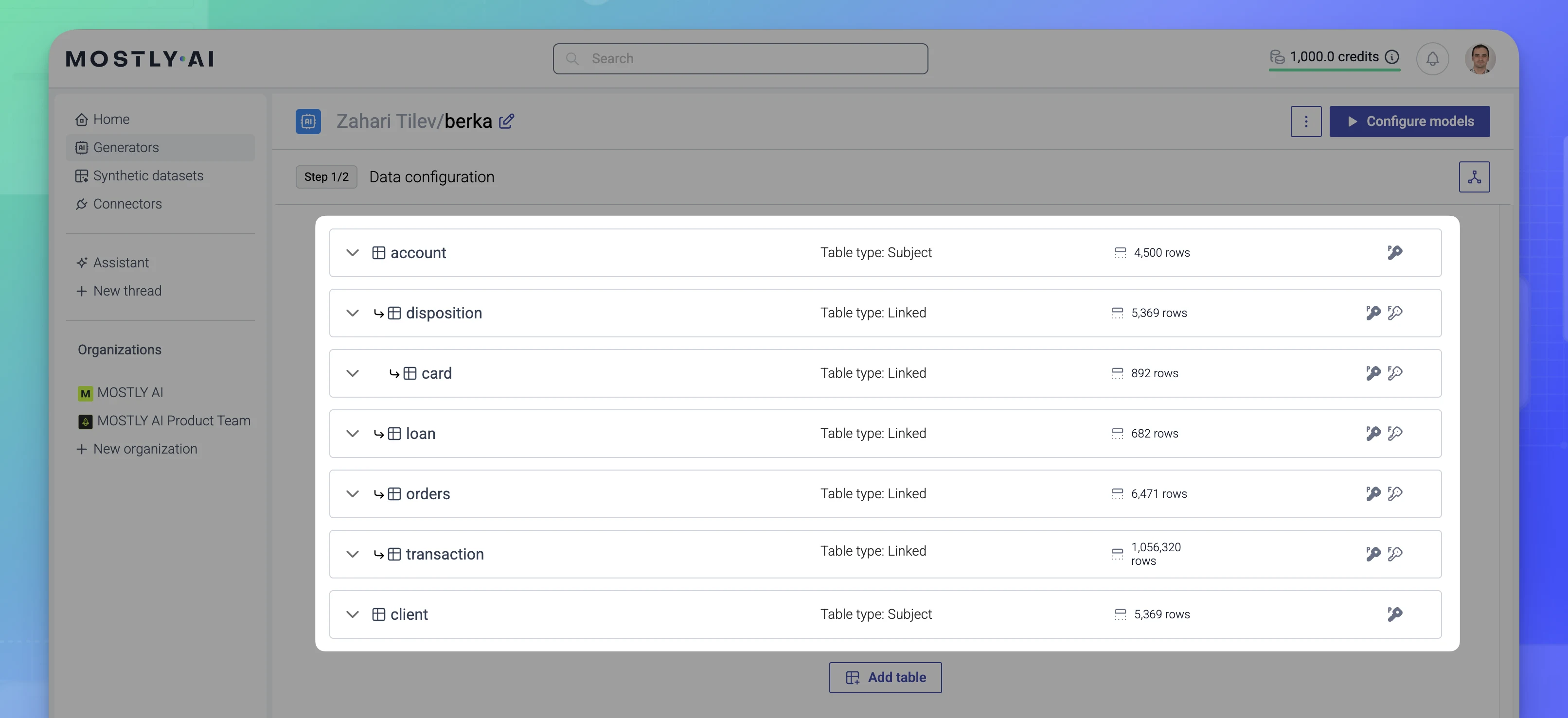
You can also review the relationship diagram.
What’s next
To train the generator on the Berka dataset, click Configure models and then Start training.
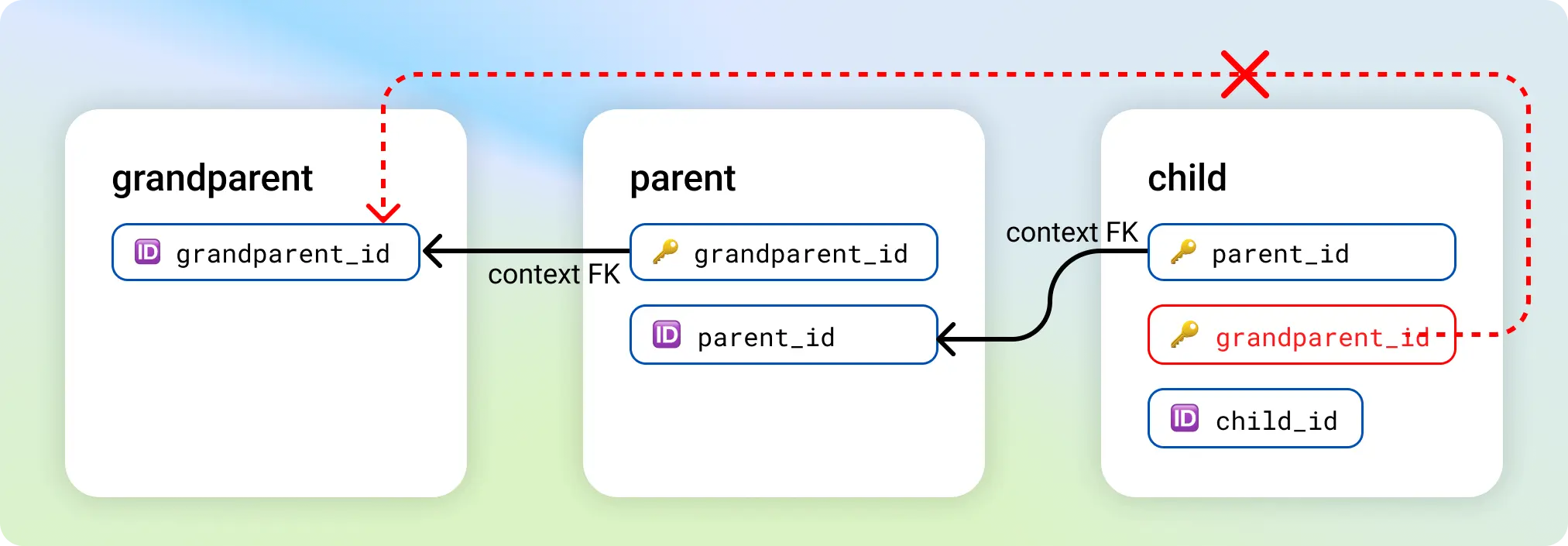
Exception: Child to grandparent relationship
If you have a hierarchy of three tables where a child table references both the grandparent and the parent, you might run into issues during generator training.
The solution is to exclude the grandparent foreign key column of the child table from training and propagate the column as a post-processing step after you generate a synthetic dataset.