Subject and linked tables requirements
To generate synthetic data from CSV, TSV, or Parquet files, get acquainted with the guidelines to learn how to best prepare your subject and table files.
Your files must have the format of a single subject table or a subject table - linked table dataset.
We recommend synthesizing datasets in Parquet format.
If you want to synthesize CSV files, make sure that they have the required data format.
For more information, see CSV requirements.
Single subject table
- We recommend that subject tables have more than 5,000 subjects.
There is no minimum size. However, the more subjects, the better the training algorithm can generalize their features, which results in a decreased privacy risk. - Each subject must refer to a distinct real world entity.
- Each row describes one subject.
- Each row can be treated independently.
The order of rows carries no information, and the contents of one row do not affect others. - Ensure that the column names do not contain any private information.
vendor_a_purchases, vendor_b_purchases, or similar. Not only would vendor names already appear in the metadata, but they could also slip through rare category protection (e.g., there’s a vendor_a column, but this vendor only appeared five times in the whole dataset). You can solve this problem by simply having a vendor column with the vendor names in it.A subject is an entity or individual whose privacy you are going to protect. A subject table, therefore, contains records that describe these subjects.
Each row in a subject table describes the profile of a unique subject. They contain fields that tell something about them, such as their name, gender, height, place of residence, or income.
In practice, two or more real-world entities may have identical features when they’re described as subjects in the subject table. Conversely, a customer can make several online purchases using different accounts or without logging in to their account. This results in a subject table that contains multiple records with different identifiers for the same person.
MOSTLY AI delivers the most accurate results if the subject table reflects the real world as closely as possible. If real-world entities share identical properties, then this should be left as such. But if multiple records contain the same contact details, it’s plausible that it’s the same person and could be considered for merging.
Below you’ll find an example of a subject table. You can use it as a guideline to create your own.

Subject table - linked table dataset
- This structure is ideal for processing lists, sequences, or time-series data.
- It consists of two tables
- a subject table that satisfies the requirements for a Single subject table
- a linked table
- Each record in the subject table must have a unique ID (primary key)
- Each record in the linked table must include the unique ID of the subject record it is linked to (foreign key)
- Avoid excessively long sequence lengths (number of linked records related to a single subject record).
MOSTLY AI can process lists, sequences, or time-series data when they’re formatted as subject table-linked table datasets. Here you can think of shopping lists, insurance claims, patient health records, or time-series data, such as online shopping journeys, purchase histories, or financial transactions.
Linked tables contain events, and MOSTLY AI processes these as properties of the subjects in your subject table. Therefore, they cannot exist without subjects, but subjects can have zero events. This relationship guarantees the subjects` privacy during synthesization, which is why these types of data need to be formatted into a subject table and a separate linked table.
The image below shows the columns that these tables must have to make this relationship. Each record in your linked table must have a field that specifies to which subject it belongs.
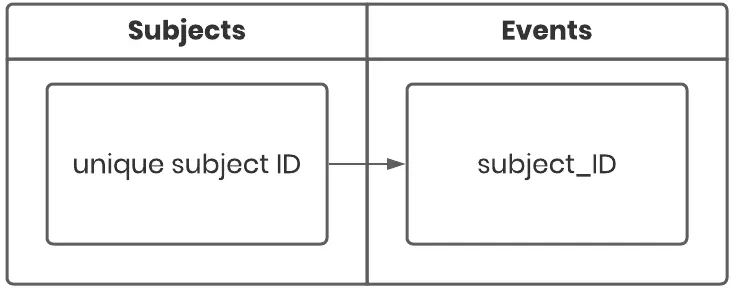
Below you’ll find an example of a basic customer journey dataset with two subjects. Alice Doe made a purchase after visiting the store twice, and Bob Joe was flagged as a churned customer after he no longer showed up for five days.
Subject table
id firstName lastName
1 Alice Doe
2 Bob JoeLinked table
users_id event_time event_type
1 2020-04-01 visit
1 2020-04-03 visit
1 2020-04-05 purchase
2 2020-03-13 visit
2 2020-03-18 churn