Troubleshoot common deployment issues
Learn how you can troubleshoot MOSTLY AI deployment issues that might occur in any Kubernetes environment.
404 not found error after deploying
If immediately after deploying MOSTLY AI and attempting to access the application, you see a 404 not found error, it might be that you are trying to access the application on the HTTPS protocol without having set up a TLS certificate.
Problem
Immediately after deploying the MOSTLY AI application, you attempt to access the application through a FQDN or static IP address, the browser shows a 404 not found error.
Cause
You might be trying to access the application on the HTTPS protocol without having set up a TLS certificate. The URL looks as listed below:
https://your-fqdn.comSolution
- Access the application through HTTP protocol, as shown in the URL below.
http://your-fqdn.com - If the issue persists, clear your browser cache and try again, or try opening the application in an Incognito or Private window in your browser.
Generator is stuck in Queued status
After you deploy MOSTLY AI, your first sanity test can be to train a new generator. However, the generator training might make no progress and remain in the Queued status indefinitely.
Problem
After starting the training of a new generator, its status is Queued and it remains as such indefinitely without making progress.
Cause
The most likely cause for this is that in your values.yaml file, all CPU and memory resources available to the worker nodes have been allocated to the Default compute.
Solution
Reallocate the Default compute resources to be lower than the total resources allocated for your worker nodes. For example, if your worker nodes have 14 CPUs and 24 GB of memory each, allocate 10 CPUs and 20 GB of memory to the Default compute.
- In the
values.yamlfile, edit thedefaultComputePoolsection for themostly-appservice.values.yamlmostly-app: deployment: ... mostly: defaultComputePool: name: Default type: KUBERNETES toleration: engine-jobs resources: cpu: 10 memory: 20 gpu: 0 - Save the
values.yamlfile. - Remove your current deployment by deleting the
mostly-ainamespace.bash copy kubectl delete namespace mostly-ai - Re-deploy MOSTLY AI.
bash copy helm upgrade --install mostly-ai ./mostly-combined --values values.yaml --namespace mostly-ai --create-namespace
Queued jobs make no progress when scheduled on a worker node requiring the operator Exists
Problem
After you deploy and start a generator or synthetic dataset, you might see that the job is stuck in the Queued status without making any progress.
Cause
One reason may be that your Kubernetes cluster requires the definition of the mostly_coordinator.deployment.core_job.tolerationOperator to Exists in the values.yaml file.
Solution
Remove any Toleration values defined for your computes.
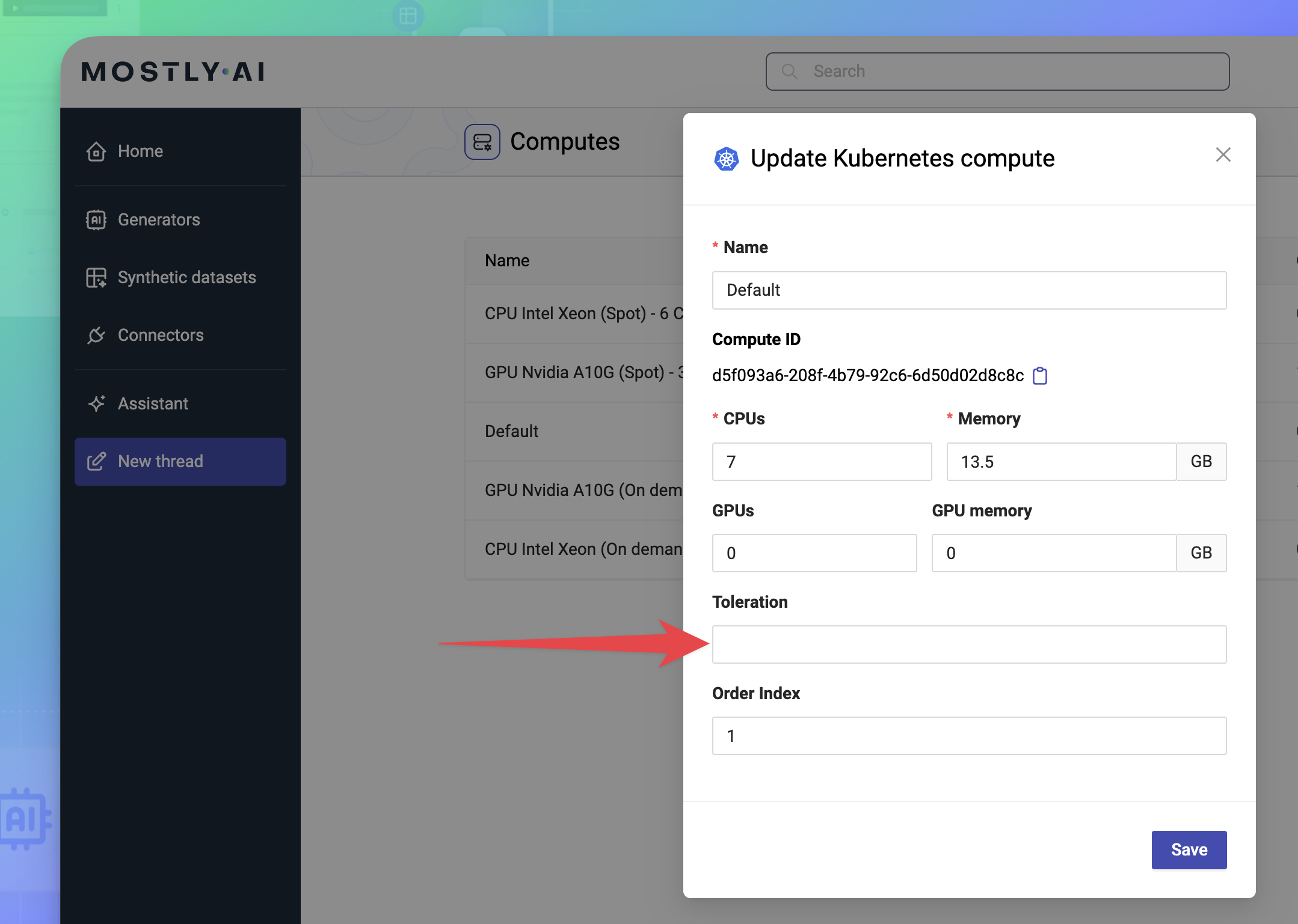
- As a Super admin, go to the Profile menu in the upper right and select Computes.
- For the Default compute, select it from the list and remove the Toleration value, and click Save.
- Repeat for any additional computes added to your MOSTLY AI deployment.