Deliver synthetic data to databases or cloud buckets
When you configure the generation of a synthetic dataset, you can select to deliver the generated synthetic data to a database or cloud storage bucket.
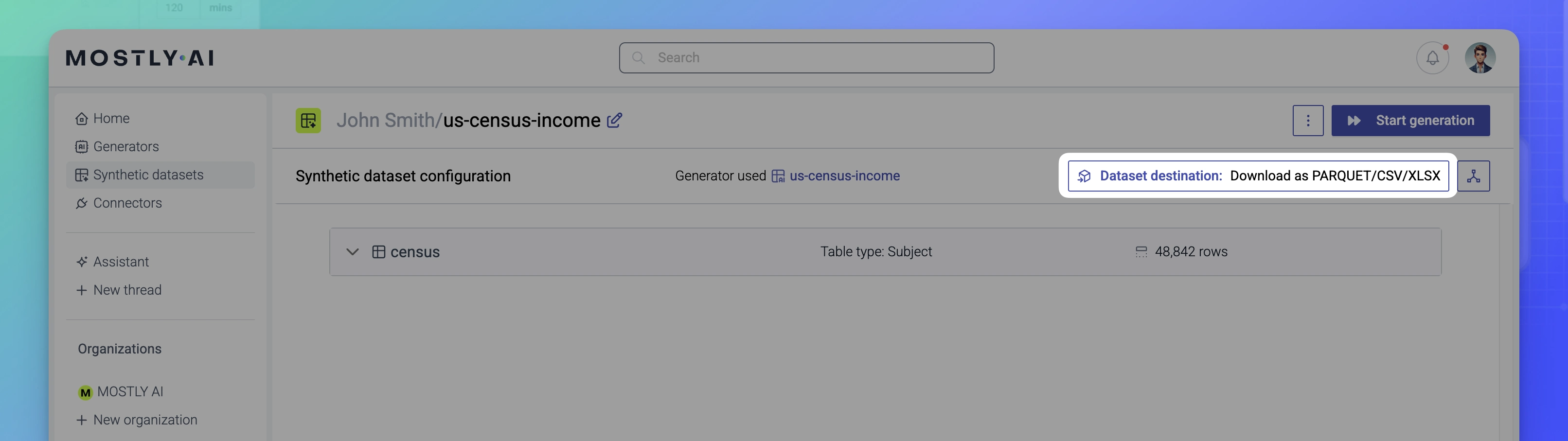
If you use the web application, you can select a destination before you start the synthetic dataset generation from the Dataset destination button.
💡
* Regardless of any destination you select, the generated synthetic dataset will always be available to download as a Parquet file. * CSV downloads are also available for synthetic datasets with less than 10M data points. * XSLX downloads include up to 10k samples of data.
Steps
- On the Synthetic dataset configuration page, click Dataset destination.
- On the Synthetic dataset destination dialog, configure the destination.
- For Destination, select a database or cloud bucket destination.
💡
The Destination drop-down lists only connectors that have the Destination access type.
You can type to filter the names among the list of destination connectors.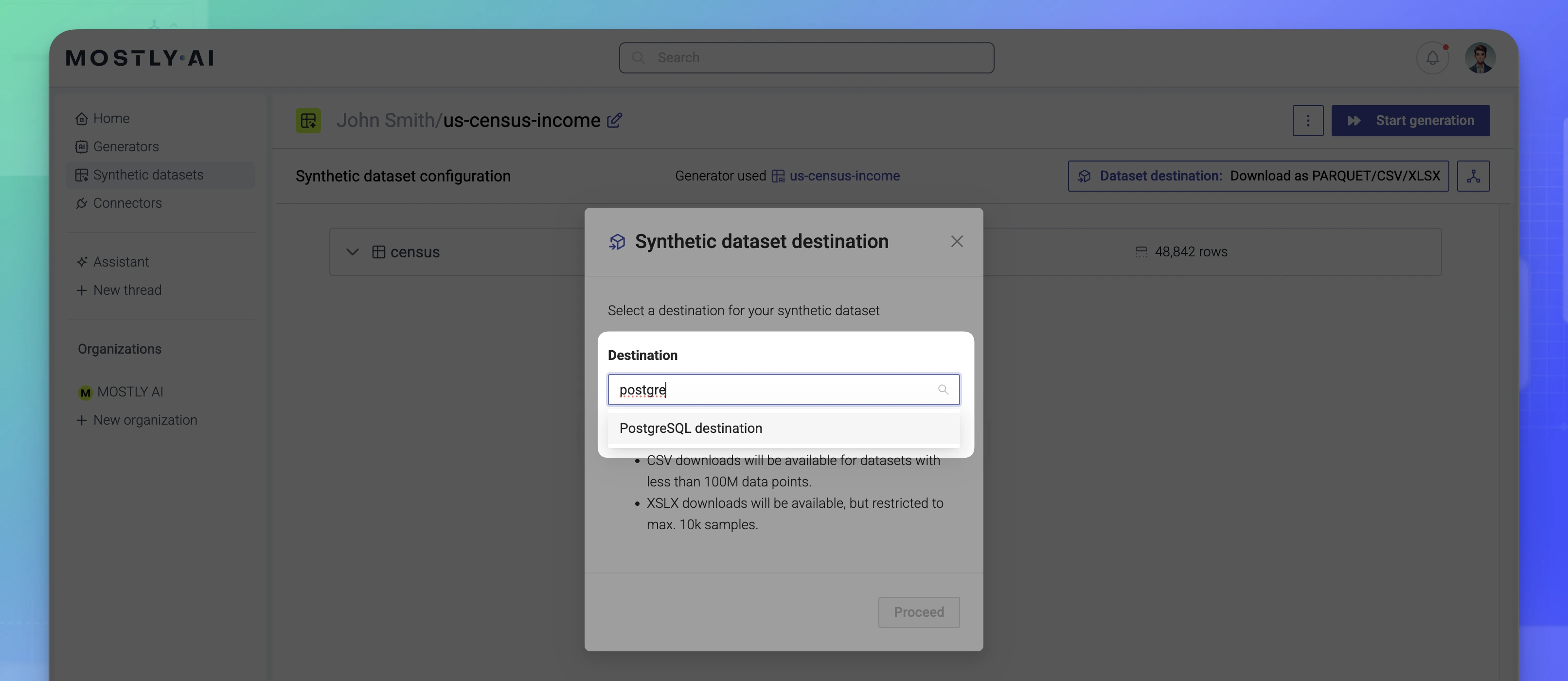
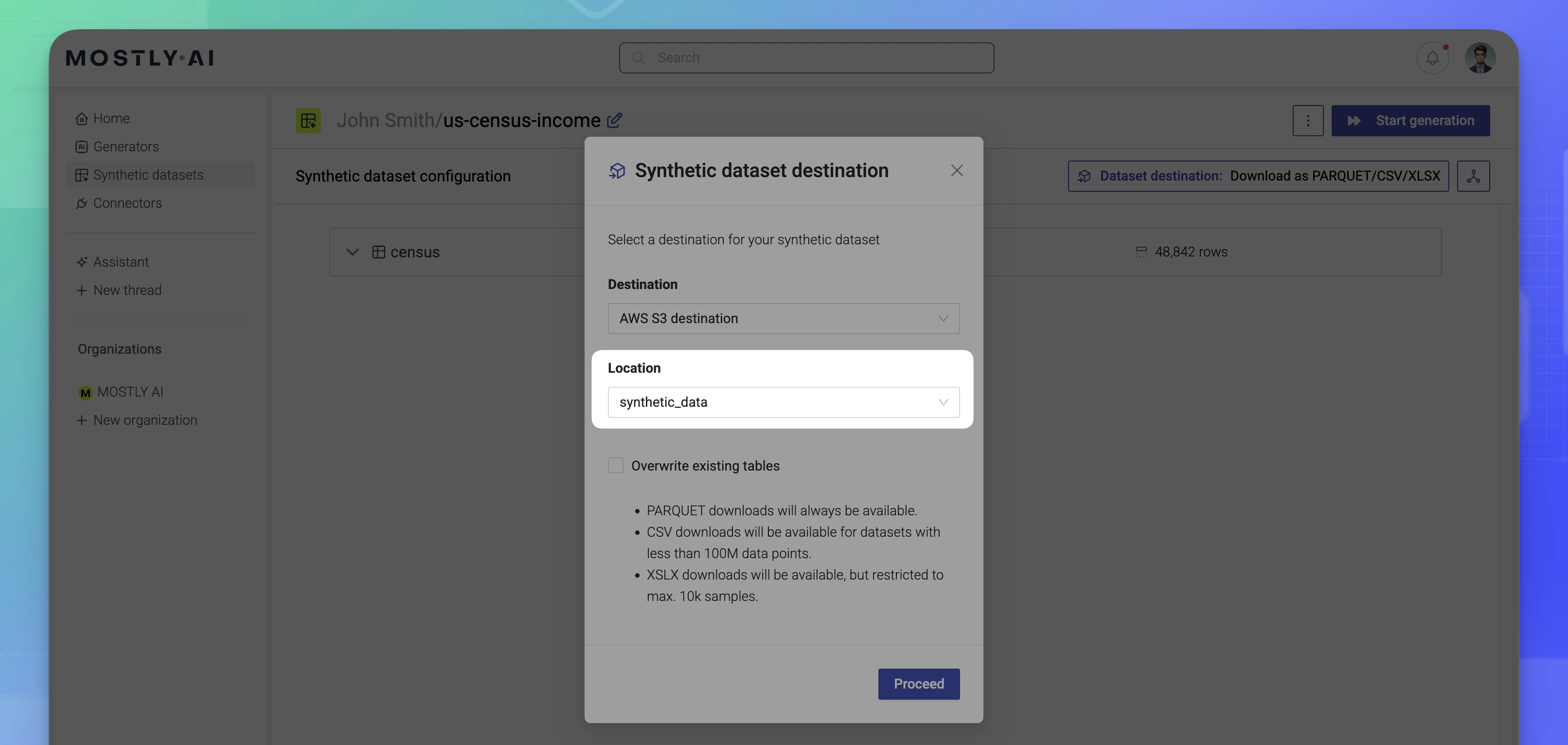
- For Location, select a database, database schema, or cloud bucket folder where you want to deliver the generated synthetic dataset.
For databases, you can select a database schema or a table from the Location drop-down menu.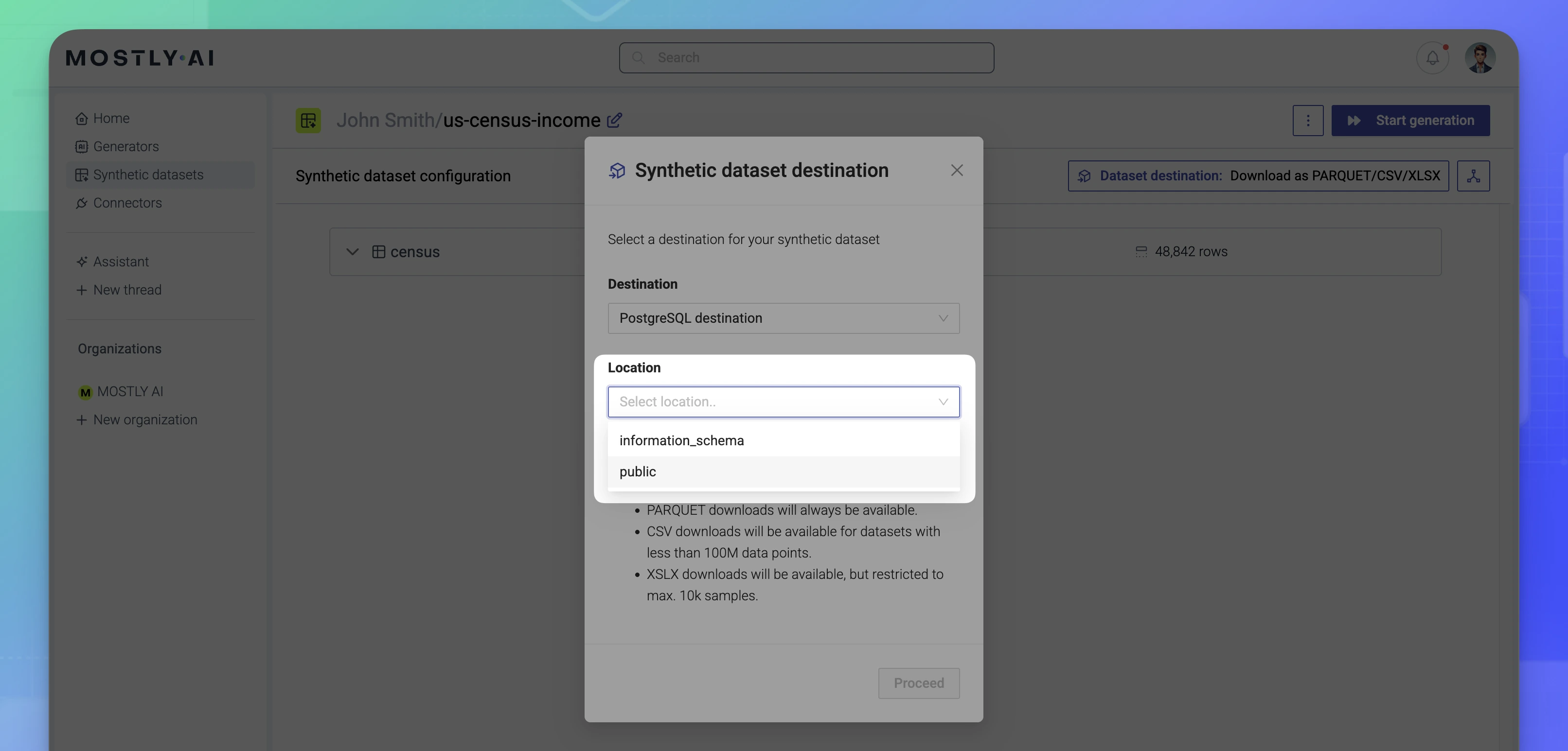 For cloud storage buckets, type the folder path in the Location text box.
For cloud storage buckets, type the folder path in the Location text box.
- For Destination, select a database or cloud bucket destination.
- (Optional) Select Overwrite existing tables if you deliver to the same destination over and over again and want to maintain a fresh copy of synthetic data.
- Click Proceed.
Result
When the synthetic dataset is generated, MOSTLY AI delivers it to the specified location.