What’s new in MOSTLY AI
5.10.0
January 12th, 2026
Generator Constraints
- Generators now support Constraints with initial support for Inequality and FixedCombinations (currently only available via Assistant & Synthetic Data SDK)
Upstream dependencies
- Upgraded Synthetic Data SDK to
5.10.1, Synthetic Data Engine to2.4.0(and with that upgraded to PyTorch 2.9).
5.9.1
Footer and full page view in shared artifacts
- Sharing Artifacts with MOSTLY AI, just got even better. Now you can view the Artifact in a full page view, and see the footer with all the links to the MOSTLY AI Platform.
Fixes
- Fix UI issue upon disconnecting from a OAuth2 provider on integrations page
- Increase byte buffer in assistant broker to prevent large file download errors
- Fix credit validation logic
- Fix UI button inconsistencies
5.9.0
Integrations using OAuth to external services
Now you can use OAuth to authenticate with external services with MOSTLY AI. Imagine being able to ask the MOSTLY AI Assistant to pull data from your various external services and use that data to train Generators, create Artifacts, or even generate Synthetic Datasets. Well you don’t have to imagine anymore, because as of version 5.9.0, you can!
Resolved issues
- Fix Download data submenu issue
Upstream dependencies
- Upgraded Synthetic Data SDK to
5.9.2, Synthetic Data Engine to2.3.3.
5.8.2
Resolved issues
- Fix ordering of the Artifacts page.
5.8.1
Resolved Issues
- Fix prompt caching for Anthropic models during MOSTLY AI Assistant Chats.
- Fix exception handling for asynchronous LLM completion calls during MOSTLY AI Assistant Chats.
5.8.0
December 1st, 2025
Improvements
- Stop stripping extra columns from seed data; retain all columns through generation and finalization.
- Update SDK auto-detection logic for DATETIME and short-string (TABULAR_CHARACTER) columns.
- Add openpyxl to the kernel image to ensure Excel files can be downloaded reliably in all environments.
- Show a warning when navigating away with messages still queued for execution.
Resolved issues
- Set Owner:Me as default filter on the resource list pages
- Ensure successful file sync when stopping the thread
Upstream dependencies
- Upgraded Synthetic Data SDK to
5.8.2, Synthetic Data Engine to2.3.1.
5.7.1
November 26th, 2025
Resolved issues
- Downgraded to
ipykernel < 7to improve stability for Python code execution in the Assistant. - Added automatic retry logic for Python code execution in the Assistant.
5.7.0
November 21st, 2025
Migrate mostly-app to non-blocking reactive Spring
- MOSTLY AI just became even more more efficient, using fewer resources to do the same work as previously. The platform is scaling fast and can now serve far more simultaneous users without needing to scale up hardware, is more resilient under spikes in traffic, and supports requests moving through the system more smoothly.
Navbar redesign
- Introducing the new and improved navigation bar for the MOSTLY AI Platform. Now you can get around faster, easier, and with fewer clciks than before.
Resolved issues
- Cap image size with base64 encoding consideration to prevent out-of-memory issues.
- Improved scheduling logic of pool manager for better resource utilization.
Upstream dependencies
- Upgraded Synthetic Data SDK to
5.7.0, Synthetic Data Engine to2.0.1, DuckDB to1.4.2.
5.6.0
November 14th, 2025
Cardinality Retention for Non-context Foreign Key Models
- We’ve increased the accouracy of Non-context Foreign Key Models by preserving more unique values when generating realistic values for non-context foreign keys.
Enhanced Context Compaction Behavior
- The MOSTLY AI Assistant now only triggers context compaction after finishing a user request, ensuring that the context is only compacted when it’s actually needed.
Assistant Settings Validation
- At save time, the MOSTLY AI platform now better validates the contents of submitted Assistant settings to ensure expected behavior.
Upstream dependencies
- Upgraded Synthetic Data SDK to
5.6.0, Synthetic Data Engine to2.0.0.
5.5.0
November 4th, 2025
User-Scoped Secrets in the Assistant
- Now you can define Secrets for use by the MOSTLY AI Assistant to make use of during Chats. Use Secrets to authetnicate API calls or store sensitive information that you don’t want to be visible in the UI. With MOSTLY AI, you’re in control.
Enhancements
- Provide real-time Credit calculations for your usage, ensuring you always know how much you’ve used and how much you have left.
- Increase process visbility during Generator training with enhanced progress messages.
- Improved foreign key matching ability for models with further fine-tuning.
Resolved issues
- Enable social sharing previews in the Artifact Library.
- Resolve issue with progress accuracy during Generator training showing Model Report generation as complete whilst still ongoing.
- Fix issues caused by table names in Generator configuration differing from the actual database table names.
Upstream dependencies
- Upgraded Synthetic Data SDK to
5.5.0, Synthetic Data Engine to1.7.0, and mostly-mock to0.2.2.
5.4.2
October 24th, 2025
Non-Context Foreign Key Models
- Non-context foreign keys are now supported by their own generative AI models. That means that every single foreign key in your dataset contains plausible values with respect to their parent primary key. Consider a case when you have a parent and a child. There are certain obvious things that must be true about their relationship: the parent must be a certain number of years older than the child. The parent should be assigned a certain gender based on their relationship to the child (mother, father). Now extrapolate that concept to less directly apparent relationships between data tables. With the deployment of non-context foreign key models, your synthetic data just got even smarter.
Enhancements
- Show user first and last name instead of username throughout platform UI.
- Enhanced login email design and content.
Upstream dependencies
- Update Synthetic Data SDK to
5.4.1, and Synthetic Data Engine to1.6.1.
5.4.1
October 21st, 2025
Introducing Popular Datasets
- We have seen a lot of community engagement around creating and sharing Datasets. To help you find the most popular datasets, we are now showing the most popular and trending Datasets on the platform homepage to make them even easier to explore.
Assistant Message Queue
- Got a question for the MOSTLY AI Assistant? Now you don’t have to wait for an ongoing process to conclude before asking. The Assistant Message Queue allows you to send multiple messages before an ongoing process is completed. The MOSTLY AI Assistant just got a whole lot more autonomous.
Improvements
- Introduce new platform homepage conversation starters with familiar MOSTLY AI platform actions: Analyze, Mock, Synthesize, Simulate
- Optimize Artifact Library experience for mobile users.
- Support Conditional Simulation features, even when Flexible Generation parameter is set to
off. - Display progress bars for Python tasks performed by the Assistant.
Resolved issues
- Ensure that generated files created during Assistant Chats are synced to cloud storage to improve recovery during kernel restarts.
5.3.1
October 13th, 2025
Context Summarization
- Reduce token consumption during Assistant chats by summarizing long running conversations in Assistant memory.
Resolved issues
- Resolve issue with intermittent kernel starting issues.
- Support for deleting Datasets if you have the appropriate permissions.
- Improve syntax and efficacy of UI error messages in the Artifact library.
5.3.0
October 9th, 2025
Introducing the Artifact Library
- Access your entire history of created Artifacts in the Artifact Library any time.
Redshift Connector now available
- Connect to your Amazon Redshift database to generate and store synthetic data directly from your data warehouse.
Improvements
- Show status in Chats sidebar to support users in better managing active sessions
- Copy-paste files and images directly from your clipboard to the Assistant chat
- Global search now supports looking up resources by UUID
- Unified chat prompt textbox and starters across all locations
- Displaying gzipped CSV files without explicitly unpacking them in now possible
Resolved issues
- Support string values for non-context foreign keys when generating synthetic data
- Resolve issues caused by UI caching across releases
Upstream dependencies
- Upgraded SDK to
mostlyai 5.3.0
5.2.5
October 1st, 2025
Improvements
- Increase the maximum number of tokens per LLM response from 5k to 20k.
Resolved issues
- Allow messages with only images to be sent to the Assistant to prevent unexpected output.
5.2.4
September 30th, 2025
Allow users to manually stop kernels
- Python sessions now have a Stop session option to manually stop the kernel.
Improvements
- All platform entity pages (Generators, Synthetic datasets, Connectors, Datasets) now have the Creator filter set to the logged in user by default.
- Standardize the position of the Download button across all Artifacts.
Resolved issues
- Resolve issue with accessing other user profiles on the MOSTLY AI Platform
Upstream dependencies
- Upgraded SDK to
mostlyai 5.2.6 - Upgraded Platform to
mostlyai-engine 1.5.7 - Upgraded Pytorch to
2.8.0 - Upgraded vLLM to
0.10.2
5.2.3
September 24th, 2025
Improvements
- Enhanced compatibility with Anthropic Claude family of models for Assistant
- Assign descriptive chat title after the first user message
Resolved issues
- Fix sorting of recent chats in sidebar
Upstream dependencies
- Upgraded SDK to
mostlyai 5.2.5 - Upgraded Platform to
mostlyai-engine 1.5.6
5.2.2
September 23rd, 2025
Improvements
- Standardize default naming for newly created resources
- Support preview images for HTML artifacts generated by the Assistant
- Support downloading an uploaded file within a Chat (useful for accessing resources in Shared Chats)
- Extend Assistant capabilities to include computer vision for reviewing uploaded images
Resolved issues
- Keep client connections active for long running prompts until Assistant broker service has finished responding
Upstream dependencies
- Upgraded PostgreSQL to
16.10.0 - Upgraded Synthetic Data SDK to
mostlyai 5.2.4
5.2.1
September 15th, 2025
Descriptive code block labels
- When executing Python code in the Assistant, code block labels describe the purpose of the code block.
Animated toasts for error notifications
- Error notifications now feature animated toasts to make them easier to recognize.
Improvements
- Update modal pop-ups (Datasets & Synthetic Datasets)
- Show small Mostly AI icon on header for mobile devices to improve responsiveness
- Improve mobile responsiveness for Assistant modals
- Improve artifact sharing experience by adding filename and download URL as new properties
Resolved issues
- Resolve issue with disordered messages when multiple streaming chats were active
- Redirect user to homepage when reaching parallel chat limit to make it easier to find the chat you want to continue
- Real-time credit update after generator/synthetic dataset job finishes to improve usage tracking
Upstream dependencies
- Upgraded to
mostlyai5.2.1
5.2.0
September 5th, 2025
Sequence completion via Platform
- Improve simulation features to include seed functionality for sequence compleation, supporting the creation of realistic data based on unseen series using the MOSTLY AI Platform.
Instant startup time for Python Sessions
- Implement always-ready kernel pool for instant startup time for Python sessions.
Improvements
- Switch to GPT-5 Nano as default for Mock Data generation.
5.1.0
September 2nd, 2025
Sequence completion via SDK
- Improve simulation features to include seed functionality for sequence compleation, supporting the creation of realistic data based on unseen series with the Synthetic Data SDK.
Paid subscriptions and payment integration with Stripe
- Introducing paid subscriptions and payment integration with Stripe
- Implement free and paid plan credit caps, usage display, and maximum free monthly credits
Improvements
- Increase visibility of consumed resources in chats by showing their usage in the chat list and details page.
- Enable name save upon clicking Enter in Rename modal.
- Improve Markdown handling and rendering by the Assistant
Resolved issues
- Patch new security vulnerabilities.
- Handle authentication error for asynchronous re-dispatches during artifact download.
- Resolve LiteLLM integration error.
5.0.4
August 11th, 2025
Improvements
- Enhance mobile responsiveness and UX.
Resolved issues
- Fix issue caused by malformed Assistant messages that prevented the chat from rendering.
- Ensure that latest usage data is fetched at each request.
5.0.3
August 1st, 2025
Improvements
- Smoother mobile scrolling and rendering experience.
- Display datasets for organizations and users.
- Code execution blocks better describe their purpose.
- Shared artificats open in a new tab.
Resolved issues
- Resolved issue where GIFs were not visible when shared.
- Prevent loading chats for unauthenticated users.
- Remove unnecessary scrollbars on homepage.
- Resolve key seeding issue for Primary Key-only flat tables.
5.0.2
July 25, 2025
Resolved issues
- Resolved async thread pool exhaustion issue.
5.0.1
July 24, 2025
Resolved issues
- Set default visibility for Artifacts to unlisted to improve sharing experience.
5.0.0
July 23, 2025
We’ve just made a major step towards truly bringing data to everyone at MOSTLY AI and it’s all about unlocking the full potential of LLMs for real-world data exploration.
Datasets available on the platform
Datasets are discrete collections of data created by a generator, uploaded to the platform directly, or accessed via connector. Build a dataset from scratch and explore it with the Assistant.
Sharable Artifacts
Anything that you create with the MOSTLY AI Assistant such as visualizations, GIFs, charts, and even datasets can be shared with your organization, other MOSTLY AI users, and the world. Contribute to public data intelligence today!
Improvements
- Fullscreen modal for message artifacts
- Enhanced layout on connectors, generators, and synthetic datasets pages
- Support storage configuration for compute resources
Resolved issues
- Support for empty primary key during generator creation
- Improve mobile responsiveness
v4.9.0
July 11th, 2025
Datasets available in public API
Adds Datasets as a new resource type, allowing users to upload files directly via API. Datasets are discrete collections of data created by a generator, uploaded to the platform directly, or accessed via connector.
Resource usage tracking for popularity sort
Tracks how often resources like generators, synthetic datasets, and connectors are used across chats. When a resource is shown in an Assistant message, its usage is recorded; if the resource or chat is deleted, the corresponding usage entry is removed. Resources can now be sorted number of uses value on the platform.
New homepage design
MOSTLY AI is a data intelligence platform for everyone. Our new homepage reflects that mission by offering users the ability to launch any task directly from the platform homepage. Leverage the Assistant to create a new dataset, build a generator, or configure a new connector using natural language prompts.
Improvements
- Platform: New sidebar menu with list of chats
Resolved issues
- Real-time credit updates for chat usage ensure accurate usage reporting.
Upstream dependencies
- Upgraded to
mostlyai4.8.3,mostlyai-engine1.4.8,mostlyai-mock0.1.14
v4.8.3
July 3rd, 2025
Enhance resource sharing experience
Introduce a unified Share feature that combines visibility settings and ownership transfer into one place, replacing the previous separate controls. Users can access this modal either by clicking the Share button or directly on the visibility badge, streamlining how sharing and access control are managed.
Consider token usage for credit consumption
Chatting with the Assistant is billed at a rate of 5.0 credits for every 1M tokens processed. This ensures token usage is factored into billing alongside computational resource consumption.
Improvements
- Platform - Make login page mobile responsive
- Assistant - Indicate if a previous streaming chat is ongoing after reload
- Assistant - Rename Threads to Chats, including URL routes
- Assistant - Enhance List of Chats page
- Assistant - Skip autoExpand / autoCollapse for Python blocks
Resolved issues
- CORE - Support generator probing with exclusively language columns
- Assistant - Resilient CSV handling for DataFrames
Upstream dependencies
- Upgraded to
mostlyai4.8.2,mostlyai-engine1.4.7,mostlyai-mock0.1.14
v4.8.2
June 27th, 2025
Resolved issues
- Fixed issue when using LLM models in generator training
v4.8.1
June 26th, 2025
Resolved issues
- Enable file uploads during Assistant chats
v4.8.0
June 26th, 2025
Interactive HTML artifacts in the Assistant
You can now generate and view fully interactive HTML content directly inside Assistant chats. This lets you create rich visualizations, reports, or custom UI elements that are rendered and usable in real time — perfect for sharing insights or building dynamic tools within your conversations.
MOSTLY AI MCP Server
The MOSTLY AI MCP Server is now available in beta at https://mcp.mostly.ai/sse/, offering 19 powerful tools to supercharge your synthetic data workflows. It seamlessly integrates with four leading MCP clients:
- Claude Desktop - Bring MOSTLY AI’s capabilities directly to your desktop environment.
- Claude Web UI - Seamless integration with Claude’s web interface
- VS Code - Enhanced development experience with synthetic data tools
- Cursor - Advanced AI-assisted coding with MOSTLY AI integration
Improvements
- Implemented periodic license validation for the AWS Marketplace offering to ensure proper subscription management and compliance for AWS users.
Resolved issues
- Fixed EmptyDataError when uploading a file in an inactive session, improving the reliability of file uploads in Assistant chats.
Upstream dependencies
- Upgraded to
mostlyai4.7.9,mostlyai-engine1.4.6,mostlyai-qa1.9.7 - Upgraded to vLLM 0.9.1, PyTorch 2.7.0, Triton 3.3.0 for improved performance and stability
v4.7.3
June 23rd, 2025
Improvements
- Added a collapsible Python code container with streaming animation to the Assistant, so the chat interface stays clean and focused on the output.
- Improved Assistant compatibility and behavior on iOS, ensuring a smoother mobile experience.
- Added a plus button and Python mode to the Assistant input area on the homepage, enabling file uploads and resource access without navigating into a chat.
- Introduced a retry mechanism for file uploads in the Generator table, to prevent failed uploads from blocking progress.
Resolved issues
- Fixed an issue where model samples were not shown even if available.
- Fixed missing generator training status when in the QUEUED state.
- Fixed an issue where the synthetic dataset details page failed to load if the underlying Generator was private and not accessible.
Upstream dependencies
- Upgraded to
mostlyai4.7.8,mostlyai-engine1.4.5- Fix issues with gated HuggingFace models
v4.7.2
June 6th, 2025
Resolved issues
- Fixed issue with downloading synthetic datasets via Assistant
Upstream dependencies
- Upgraded to
mostlyai4.7.3,mostlyai-qa1.9.7,mostlyai-mock0.1.6
v4.7.1
June 4th, 2025
Improvements
- You can now search with owner filter in search term to narrow down search results.
- Updated headers and top sections on the Configuration and Overview pages for better consistency and readability.
Resolved issues
- Fixed an error occurring during the training phase for generators without a model report.
- Fixed broken links from organization connectors to the connector detail pages.
- Corrected the URL when opening an organization from a connector’s detail page.
- Fixed an issue where the progress bar was not visible as expected.
- Fixed line break rendering issues in user messages within the Assistant chat.
- Fixed file download issues for filenames containing non-Latin characters.
- Removed duplicate option in connector list kebab menu
Upstream dependencies
- Upgraded to
mostlyai4.7.1,mostlyai-engine1.4.3,mostlyai-qa1.9.6- Fix error for dtype mismatch between PK / FK
- Fix error for c.read_data for UUID columns
- Upgraded opacus to 1.5.4, numpy to 2.2.6
v4.7.0
May 28th, 2025
Reproducable results with randomState
You can now ensure that Generators and Synthetic datasets produce consistent results across runs by setting a randomState.
Assistant artifacts
The Assistant now supports artifacts, allowing it to display resources (like Generators or Synthetic datasets) and files (like CSV, PNG) directly in your chats. A more interactive and organized way to work with results.
Multi-table mock data
We’ve introduced a new way to generate mock data with multi-table support directly via the Assistant. This enables more flexible and realistic mock data generation for complex scenarios.
Improvements
- You can now change the access type of a Connector after it’s been created.
- When creating a new Connector through the Synthetic dataset destination flow, we now automatically sets its access type to Write, ensuring it’s immediately usable for writing data.
- Added filters to the Assistant’s Chat list page, making it easier to navigate chats.
- Switched to uv for faster and more reliable Python package management in the Assistant backend.
Resolved issues
- Files uploaded to the Assistant are now more reliably retained across kernel restarts.
- When an invalid compute is assigned, the platform now selects a default one automatically.
- Fixed pagination issues in the connector selection step when adding data to a Generator.
- The Value protection option is now always visible, also for LANGUAGE models
Upstream dependencies
- Upgraded to
mostlyai4.7.0,mostlyai-engine1.4.2,mostlyai-qa1.9.6
v4.6.2
May 21st, 2025
Enhanced connector details
Introduced dedicated Connector Detail pages, providing comprehensive information about each connector including its configuration, usage statistics, and sharing options. This enhancement improves connector management and visibility.
Improvements
- Assistant: Added collapsible Python blocks for better organization and readability of code in chats
- Updated connector cards and API to display number of likes and descriptions
- Streamlined the “Connect your Data Source” flow when creating a new connector
- Added support for manual entry of full bucket paths in the Generator Add data flow
Resolved issues
- Fixed an issue where the number of parallel running chats wasn’t immediately updated after deleting a chat
- Optimized response time of API endpoint for creating new chats
- Improved error messages in logs to be more descriptive and LLM-compatible
Upstream dependencies
- Upgraded to
mostlyai4.6.3,mostlyai-qa1.9.5
v4.6.1
May 16th, 2025
Improvements
- Decreased the number of API calls from resources lists
Resolved issues
- Fixed explore buttons on Generators and Synthetic datasets
Upstream dependencies
- Resolve plotly vulnerability on QA
- Upgraded to
mostlyai4.6.3,mostlyai-qa1.9.5
v4.6.0
May 13th, 2025
Differential privacy value protection epsilon
Introduced Differential Privacy Value Protection for metadata analysis, extending DP beyond model training to include protected min/max ranges for numeric, categorical, and datetime columns. A new configuration parameter, valueProtectionEpsilon, allows fine-grained control over privacy budgets, improving metadata security while maintaining data utility.
Accuracy trivariates
Enhanced accuracy analysis with 3-way (trivariate) interactions, extending quality metrics to include univariate, bivariate, and trivariate accuracy calculations. The overall accuracy is now determined as the average across all three levels, resulting in stricter and more reliable assessments of model performance.
Improvements
- Assistant: Centered the input box in empty chats for a cleaner and more intuitive user experience.
- Assistant: Redesigned the chat header to be thinner, freeing up more space for the actual conversation area and improving usability.
- Assistant: Enabled direct URL links with assistant prompts in both text and Python modes for quicker navigation
- Assistant: Enable file uploads even if the session is not initialized.
- Add a python dictionary to generator details configuration section
- Upgrade to Keycloak v26
Resolved issues
- Preserve connector filtering and sorting after closing the new Connector modal.
- Update totalVirtualCpuTime in Assistant chats based on websocket events.
- Prevent large horizontal scrolls in wide tables within Assistant chats.
- Fixed issue where clicking on a connector in the connector list redirected to the Homepage.
- Smooth out the notifications menu.
- Fixed backend error (500) caused by expired sessions when attempting to restart them.
Upstream dependencies
- Upgraded to
mostlyai4.5.7,mostlyai-qa1.9.1
v4.5.6
Apr 30th, 2025
Improvements
- Adjust docker images to support broader compatibility across OCI-compliant platforms
v4.5.5
Apr 29th, 2025
Improvements
- Optimization of docker image metadata
v4.5.4
Apr 29th, 2025
Improvements
- Optimization of docker image metadata
v4.5.3
Apr 22nd, 2025
Chat bubbles in Assistant messages
Introduced chat bubbles in Assistant messages, enhancing the user interface and making conversations more intuitive and easier to follow. This visual improvement provides a more engaging and familiar chat experience.
New Nearest-Neighbor Distance Ratio (NNDR)
Introduced the new Nearest-Neighbor Distance Ratio (NNDR) metric, providing a more sophisticated approach to measuring distances between training, holdout, and synthetic data.
Resolved issues
- Fixed Virtual CPU time computation for re-started chats, ensuring accurate resource tracking and credits consumption.
Upstream dependencies
- Upgraded to
mostlyai4.5.6,mostlyai-qa1.7.0
v4.5.2
Apr 18th, 2025
Assistant: Automatic restart of inactive Python sessions
The Assistant now automatically restarts Python sessions that have become inactive. If your session times out, it will be reinitialized the next time you send a message. This allows you to continue the conversation in the same chat without manually starting a new session.
Filtering and sorting options for lists
We’ve added new filtering and sorting capabilities to lists across the platform. You can now filter resources by date, owner, and visibility, and sort them by date, popularity, or usage. These improvements make it easier to organize and locate the resources most relevant to you.
Improvements
- Replaced UBI with Wolfi as base images for faster startups
- Enabled rolling updates by adding readiness endpoints for services
Resolved issues
- Assistant: Prevent sending new messages while a response is still in progress
- Cancelled status is now displayed immediately when cancelling SD or generator processes
- Changes in the SD configuration are now saved when the field loses focus (on blur)
- Usernames from deleted users can now be reused
Upstream dependencies
- Upgraded to
mostlyai4.5.5,mostlyai-qa1.6.2,mostlyai-engine1.3.2- Faster QA report generation due to model2vec embeddings
- Use training and holdout data for calculating accuracy
v4.5.1
Apr 10th, 2025
Improvements
- Refactored the Assistant UI for improved stability, with a visual update that aligns the input island with the homepage design
Upstream dependencies
- Upgraded to
mostlyai4.5.2 mostlyai: Improved error message for time outs during Live Probing to provide clearer feedback.
v4.5.0
Apr 9th, 2025
Windows SDK generator import support
We now support importing of generators trained via SDK on Windows.
Improvements
- Switch to XGrammar for lower memory footprint of LANGUAGE models
Resolved issues
- Fixed access control for unlisted connectors by checking user permissions and redirecting to the VIEW modal when needed
- Enabled Organization and User Profile Settings buttons for Super Admin users
- Prevented cloning of generators that reference missing connectors
Upstream dependencies
- Upgraded to
mostlyai4.5.1,mostlyai-qa1.5.17,mostlyai-engine1.2.4
v4.4.3
Apr 4th, 2025
Direct query access for connectors
Added c.query() for direct access to database and bucket-based connectors. It streamlines data exploration by supporting custom queries on the fly.
Refined homepage layout
Improved the homepage layout for better clarity and usability, making it easier to navigate and access key features.
Gradient accumulation steps
Expose gradient accumulation steps as new training parameter. This allows accumulating gradients over multiple batches before updating model weights, enabling effective training with larger batch sizes even on memory-constrained hardware.
Improvements
- Assistant streaming support implemented for Python execution responses to the client
- Improved structure of the navigation bar
Resolved issues
- Fixed incorrect display of total rows showing 0 in synthetic datasets after generation
- Fixed delay in displaying the Fairness configuration form
Upstream dependencies
- Upgraded to
mostlyai4.4.8,mostlyai-qa1.5.13,mostlyai-engine1.1.11 mostlyai: Added list views for Databricks and BigQuery connectorsmostlyai-qa: Initialize SentenceTransformer only a single time when running Model Reportmostlyai-qa: Upgraded to latest Plotly versionmostlyai-engine: Improved batch size heuristic for LANGUAGE models
v4.4.2
Mar 28th, 2025
Direct write data access for connectors
Implemented c.write_data() and c.delete_data() functions for direct access to connectors.
Improvements
- Enhanced user experience by redirecting to login page when URL is not valid
- Assistant now only displays READY resources in popup menus
Resolved issues
- Fixed user information for audit logs
- Fixed vCPUTime updates for chats when kernel is not running
- Stopped triggering probe jobs for synthetic datasets
Upstream dependencies
- Upgraded to
mostlyai4.4.3,mostlyai-qa1.5.10,mostlyai-engine1.1.10 mostlyai-engine: Fixed OOM error for HF Language Models by calculating max tokens
v4.4.1
Mar 21st, 2025
Compute-based credits
MOSTLY AI is transitioning to a compute-based credit system for tracking usage. The new system is more accurate and fair, as it accounts for the actual compute resources used for training generators, generating synthetic datasets, and the usage in Assistant chats.
The system now tracks virtual CPU and GPU time across each resource. The Usage report is also updated to include the new Virtual CPU time and Virtual GPU time usage metrics.
Direct read / write access for connectors
Introducing new access types for connectors.
- Read protected. You can use this connector type only for generator training. The SDK and Assistant cannot use the connector to parse data into a DataFrame and run analyses.
- Read data. You can use this connector for generator training and for reading data. The SDK and Assistant can use the connector to read and parse data into a DataFrame and run analyses.
- Write data. You can use this connector to read from and write data back into the database or cloud storage bucket.
New visibility option: UNLISTED
You can now set your resources’ visibility to Unlisted. Unlisted resources are not visible in public resource list, but you can share them with others using a direct link.
Improvements
- The Assistant can use connectors as data sources
- Refined the Assistant system instructions
- Added drag & drop of files for Assistant
- Adapted scrolling behavior of Assistant
- Speed up page load times by replacing plotly with uplot
Resolved issues
- Fixed icons appearance in Safari browser
- Fixed the opening connector pop-up when clicking a connector from a user’s profile page
Upstream dependencies
- Upgraded to
mostlyai4.4.2,mostlyai-qa1.5.9,mostlyai-engine1.1.8 mostlyai-engine: Upgraded to PyTorch 2.6.0, vLLM 0.8.1mostlyai-engine: Improved BatchSize heuristic for LANGUAGE on GPU for faster trainingmostlyai-qa: Added new Coherence visualizations to QA reportsmostlyai-qa: Report Distances also for training vs holdout
v4.3.2
Mar 14th, 2025
Resolved issues
- Fixed separate Python calls merging into a single code block in the Assistant.
- Fixed extra arguments not being handled correctly in the Assistant configuration.
- Fixed selected column in Fairness and Rebalancing not clearing when clicking “X” in SD configuration.
- Added usernames in front of Assistant chat names.
- Fixed issue with RANDOM sampling of rows in case of sequential data.
v4.3.1
Mar 10th, 2025
Resolved issues
Resolved a HTTP 500 API status error related to probing generators. The error no longer appears when you probe a generator (mostly.probe) for samples or when the Assistant does so.
v4.3.0
Mar 10th, 2025
Single compute selection per synthetic dataset
Faster synthetic dataset generation is now fully available by selecting a single compute for a synthetic dataset.
Compute selection is now moved on the synthetic dataset level and ensure that both generation and Data report generation are performed on the same compute.
For details, see Select a compute for a synthetic dataset.
Disable Model and Data reports
You can now disable the generation of Model reports for generators and Data reports for synthetic datasets. This feature is particularly useful when you need to speed up the time to finalize a generator or a synthetic dataset.
For details, see Disable Model reports and Disable Data reports.
Improvements
- Allow non-members to see the list of members in an organization
- Implemented Tool Calling for the Assistant
- Prevent OOM errors by streaming large files instead of loading them into memory
Resolved issues
- Fixed the name display when a resource is unnamed
- Add public badge for resources on user profile page
- Fixed markdown links in the organization description section
- Fixed tasks restarts and keeping them in progress for generators using HuggingFace models
v4.2.3
Feb 28th, 2025
User profiles and usernames
Ever wanted to build your own public portfolio of synthetic data resources? Today, MOSTLY AI introduces user profiles and the ability to set a unique user identifier for your resources.
- Set a user name to uniquely identify each of your synthetic data resources.
- Make your own generators, synthetic datasets, and connectors public. The resources are then automatically made available to all users of the platform and listed publicly on your profile.
- Share your profile with others and showcase your portfolio of synthetic data resources.
For details, see User profiles.
Improvements
- Public resources are now made distinct with the new public badge
- In the Transfer ownership modal window, you can now view and select only organizations in which you have the Contributor role
Resolved issues
- After an organization is deleted (and, as a result, all of its resources are also deleted), all resource lists are updated automatically (without the need to refresh the page)
- The Assistant no longer makes multiple attempts to download a file when receiving a DataFrame
- Resolved an issue with the setup of multi-table generators where the parent subject table only has an
idcolumn
v4.2.1
Feb 25th, 2025
Resolved issues
- Improved the loading speed of user & organization images
- Improved the resiliency of internal CORE API service by increasing number of workers
- Resolved generator samples availability for LANGUAGE LSTM models
v4.2.0
Feb 21st, 2025
Language CATEGORICAL, NUMERIC, and DATETIME encoding types
You can now fine-tune LLMs with tabular data from columns containing categorical, numeric, and datetime values. You can do so with the new encoding types Language/Categorical, Language/Numeric, and Language/Datetime.
The new encoding types are particularly useful for original datasets with smaller sample sizes. You can then leverage the LLMs knowledge to still generate representative synthetic data.
For details, see Set encoding types.
Improvements
- Added a shortcut to the Training logs in the Data insights section
- Improvements in the Assistant system prompt. Among other issues resolved, the Assistant now handles DataFrames correctly
Resolved issues
- Resolved the page refreshes after an Assistant chat title is updated
- Removed
maxLengthconstraint on the Assistant messages - Limit the length for Column and Table Names to 256 chars
v4.1.1
Feb 12th, 2025
Improvements
- The organization email is now featured on the organization profile page
- Organization admins now get a notification when a user joins their organization
- Open in a new tab a generator from the Home page using Cmd + click on macOS or Ctrl + click on Windows
- Updated New status icon for generators and synthetic datasets
- Existing users are now assigned one of the predefined avatars if they do not have a profile picture
Resolved issues
- Resolved the alignment of the info icon for the Foreign key tooltip
- Ensure that text is centered when editing the name of an entity
- Resolved issues in the display of the total number of members in an organization
- Non-members can also see the members in an organization
- Resolved a misalignment in the Generate data button
- Resolved an issue with the unexpected expiration of organization invitations
- Resolved an issue with the display of tables and images in Assistant chats
- Values set for the configuration of differential privacy are now preserved when you collapse and expand the Differential privacy section (in Model configuration of a generator)
- Resolved an issue in the Assistant related to disappearing Python code snippets provided using the Python code mode
- When you are not member of any organizations and use the Owner: My organizations filter, the filtered list of results is now empty as expected
- The Manage visibility option is now disabled for all entity types when the entity status is different from Ready
v4.1.0
Feb 5th, 2025
Organizations
Introducing Organizations 🏢🌎📣
The team at MOSTLY AI has been hard at work to introduce Organizations for all users, teams, and organizations that want to collaborate on synthetic data projects. With Organizations, you can:
- establish an organization for your team to collaborate, contribute, and share synthetic data resources
- develop an organization’s portfolio of synthetic data resources (generators, synthetic datasets, and connectors)
- use role-based access (RBAC) to manage the roles and permissions team members have with regard to synthetic data resources
- empower organizations to make synthetic data resources public by managing their visibility
For details, see Organizations.
Public and private resources
You can now change the visibility of your generators, synthetic datasets, and connectors (referred to as resources, for brevity).
- You can share resources with everyone on the Platform by making them public.
- You can keep resources private (their default state after a resource is created).
- Apply the same visibility settings to an organization’s resources.
For details, see Public and private resources
v4.0.0
Jan 23rd, 2025
MOSTLY AI releases the most advanced Synthetic Data SDK 🎉
We are excited to announce the release of the MOSTLY AI Synthetic Data SDK, MOSTLY AI Engine, and MOSTLY AI QA, open-source Python libraries that bring the capabilities for AI-generated synthetic data, synthetic data models, and synthetic data quality assurance to your local compute environments. You now have the most sophisticated synthetic data generation and quality assurance tools at your fingertips.
- Open source Python libraries for synthetic data. You can review, tweak, adjust, and extend the code to fit your specific needs.
- Available in any local environment. You can use the SDK in your local Python environment as well as in any air-gapped or secure environment.
- Ready for notebook environments. Do
pip install -U mostlyaiin any notebooks environment: Databricks Notebooks, Snowflake Notebooks, Google Colab, Jupyter Notebooks, and so on. - Support for flexible compute resources. Make use of any available CPU & GPU configuration, taking into account hardware availability.
MOSTLY AI Synthetic Data SDK
The MOSTLY AI Synthetic Data SDK is an open source Python library that transfers the capabilities of producing AI-generated synthetic data back into local compute environments.
-
Install the open source Synthetic Data SDK.
shellpip install -U mostlyai -
Generate synthetic data in your local environment.
pythonfrom mostlyai.sdk import MostlyAI import pandas as pd # 2. Initialize the Synthetic Data SDK. mostly = MostlyAI(local=True) # starts a local server that exposes the MOSTLY AI REST API # 3. Train a generator df_original = pd.read_csv('https://github.com/mostly-ai/public-demo-data/raw/dev/census/census.csv.gz') g = mostly.train(name='census', data=df_original) # 4. Generate synthetic data with the trained generator sd = mostly.generate(g) # 5. Consume the synthetic data as a pandas DataFrame. sd.data()References:
- mostlyai repository on GitHub
- Python package documentation
MOSTLY AI Engine
The MOSTLY AI Engine is an open source Python library that handles all related to data preparation, AI model training and configuraiotn, data analysis, and data encoding for synthetic data generation.
In summary:
- Prepare, analyze, and encode original data.
- train a Generative AI model on the encoded data.
- Generate synthetic data samples:
- up-sample / down-sample
- conditionally generate
- rebalance categories
- impute missing values
- incorporate fairness
- adjust sampling temperature
References:
- mostlyai-engine repository on GitHub
- Python package documentation
MOSTLY AI Quality assurance
Evaluate synthetic data quality in any environment with the MOSTLY AI QA open-source Python library. The library provides a comprehensive set of metrics to assess the quality of synthetic data.
References:
- mostlyai-qa repository on GitHub
- Python package documentation
Export and import generators as unencrypted ZIP files
To support the Synthetic Data SDK and the MOSTLY AI open source initiative, you can now review the contents of MOSTLY AI generators. Export and import of generators is now available as unencrypted ZIP files.
Semantic versioning
With the release of MOSTLY AI Platform and Synthetic Data SDK version 4.0.0, all future releases will follow semantic versioning. For details, see Release lifecycle and support.
Improvements
- Export and import of generators is now available through unencrypted ZIP files
- Allow the configuration of Delta for Differential privacy
- Significantly improved accuracy for sequential context processing
Resolved issues
- Allow
maxEpochandmaxTrainingTimeto be defined as floats - Setting Temperature and Top P is now available even if Flexible generation for a generator is not enabled
- Allow special characters in column names for
LANGUAGEmodels
v321
Dec 24th, 2024
Resolved issues
- Fixed issue with Hugging Face model caching.
v320
Dec 23rd, 2024
Improvements
- Enhanced UX for Generator and Synthetic Datasets configuration screens, making navigation and configuration more intuitive and efficient.
- Enabled clear messaging by showing model report download links only when the report is available.
- Synchronized metrics schemas with mostlyai-qa, making IMS and DCR share metrics accessible via the Public API.
- Expanded flexibility by supporting non-integer values for maxEpoch and maxTrainingTime.
- Improved error handling during report generation to prevent these errors from causing job failures.
Resolved issues
- Enhanced precision by displaying TopP and Temperature values with up to three digits.
- Corrected a rendering issue in univariate plots for nearly constant columns.
- Fixed issue with kerberized and ssl hive connectors.
v316
Dec 16th, 2024
Databricks computes
You can now use Databricks as a compute for your generators and synthetic datasets.
For details, see Add a Databricks compute.
Resolved issues
- Resolved an issue with the Continue training feature of generators introduced in v313
- Resolved an issue to ensure that epochs continue from the last saved checkpoint when the Kubernetes pod running the generator training was restarted
- Resolved an issue during data pull when sibling table had a non-context foreign key
- Resolved an issue during data pull when a context table had a non-context relationship the foreign key of which consisted of N/As
- Implemented gradient accumulation for all models and adapted the batch size heuristics to take advantage of it. This speeds up training of larger LANGUAGE models.
- Fixed a QA issue for large integers + boolean columns
- Fixed a QA issue when all keys between target and context are non-overlapping, which could occur in complex multi-table setups
- Support HuggingFace models with missing Beggining of sequence (BOS) and End of sequence (EOS) tokens. This enables support for Pleias LANGUAGE models.
v314
Dec 6th, 2024
Improvements
- Data insights for synthetic datasets now shows generation settings to indicate configurations that can impact the distributions in the synthetic data. For details, see Evaluate synthetic dataset quality.
- Report DP epsilon (ε) also for intra-log progress messages
- Added schemas to Public API for specifying request bodies
- Upgraded to Python 3.12
Resolved issues
- Fixed occasional File upload errors
- Reduced memory overhead for HuggingFace models during validation
- Resolved cases of Assistant not properly saving all files to MinIO
- Reduced the memory overhead for LSTM model during generation
v313
Nov 28th, 2024
Improvements
- Reduced the number of parallel workers from 4 to 2 for Data API
- UI and API are now consistent for Temperature and Top P value ranges
- Implemented a retry mechanism for file uploads in Assistant chats
- Improved the messages in the new Notification center
- Refactored the
shareendpoint to be consistent withlikes
Resolved issues
- Resolved the
gated repoerror when fine-tuning LLMs from HuggingFace -
Generator.noOfSyntheticDatasetsis no longer incremented when live-probing generators - Window title now displayed correctly when adding a generator or synthetic dataset to an Assistant chat
v312
Nov 21st, 2024
Improvements
- Improvements to the Assistant system prompt
- The chart in the Training log now remains in place while the training log table is scrolled down
- Moved the Python mode button in assistant chats to improve usability
Resolved issues
- Fixed UI form issues when editing both Rebalancing and Fairness features
- User email now appears in the Share resource dialog window if a user did not set a first and last name in their profile
- QA reports no longer take into account records with zero sequence lengths for correlation plots due to bias introduced by the zero sequence lengths
- Resolved an issue that broke the generation of QA reports when a table column name contains a
.dot character - Harmonized
max_sample_size_embeddingsfor QA reports - Fixed training progress continuation when auto-restart is triggered
v311
Nov 15th, 2024
Differential privacy
You can now train generators with differential privacy enabled. When using the generators, any synthetic datasets you generate are protected with differential privacy.
For details, see Differential privacy.
Notification center
Get notified by the latest status changes to your generators and synthetic datasets or any objects shared with you. The Notification center is your one-stop shop for all the latest updates in the MOSTLY AI Platform.
For details, see Notifications.
Likes for generators and synthetic datasets
Users can now express appreciation for generators and synthetic datasets through likes. The number of likes is displayed for each generator and synthetic dataset.
For details, see Usage of generators and Usage of synthetic datasets.
Improvements
- Added informative tooltips to the statuses of On hold and Queued
v310
Nov 13th, 2024
Improvements
- Improved (more fast and robust) language model inference by using vLLM engine for GPU compute
- Use names of any length for all entities (generators, synthetic datasets, connectors, assistant chats, and computes). In the UI, the names are truncated and appear in full when you hover over them.
Resolved issues
- Resolved an error while trying to fetch an image file from an Assistant chat
- Synthetic dataset cloning is disabled for users with Viewer role
v309
Nov 11th, 2024
Continue the training of generators
You can now extend the training of a generator by reusing its existing model weights. You can find the new option named Continue training in the menu of a generator. When you use the option, MOSTLY AI creates a clone of the existing generator and you can modify the model and training parameters before starting the training. This feature is only available if the original data still exists in a database or a cloud storage bucket connector that can still be used as a data source.
For details, see Continue the training of generators.
New display of metrics in Data insights
The Data insights has been redesigned from scratch to provide a greater detail and overview of the quality metrics of each generator and synthetic dataset. You will find a better-organized view of the sample size and size of the original dataset, the accuracy, similarity, and distances metrics, showing the quality of the synthetic data as well as the holdout metrics (for reference).
For details, see Evaluate generator quality and Evaluate synthetic dataset quality.
Update account details
Users can now update their account details from their profile Settings page.
For details, see Update account details.
Delete account
Users can now use the new self-serve option to deleted their account. The option is available in the user profile settings.
For details, see Delete your account.
Improvements
- Increased the timeout for auto-detection of encoding types to 10s
- CPU is now the default compute for the common finalization tasks of synthetic datasets
Resolved issues
- Resolved an issue in reports generation when computing the embeddings of large datasets
- Fixed the continuous auto-restart of synthetic datasets that would fail while generating the Data report
v308
Oct 22nd, 2024
Conditional generation of synthetic text
Conditional generation (aka seeded generation) is now available for synthetic text 🎉
For any generators that fine-tune an LLM with your unstructured text data, you can now pass with a seed dataset values from other columns to generate synthetic text.
Auto-detection of TEXT columns
A new mechanism now auto-detects columns with unstructured text in your tabular data. Such columns are now automatically set to the Language/Text encoding type.
Improvements
- Generator export is now available only to users shared with who have the Owner or Editor role
Resolved issues
- Resolved an issue in the sequential MOSTLY_AI/Large model
- Resolved an issue with Model report generation in case of prevalent zero sequence lengths in the original data
v307
Oct 21st, 2024
Export assistant chats as Jupyter Notebooks
You can now run your assistant chats in a Jupyter Notebook environment. All assistant chats are now exportable .ipynb files.
For details, see Export as Jupyter Notebooks.
Tree viewer for object storage
The new tree viewer makes it easier to navigate folder and file hierarchies in your storage buckets when you want to add source data or deliver synthetic data.
For details, see Use a connector as a data source and Use a connector as a data destination.
Auto-detection of primary keys
Primary keys are now auto-detected and set automatically when you add tables to a generator.
Improvements
- Implemented a new mechanism to reduce any occurrences of
_INVALID_values generated for Language/Text columns - If you use Tabular/Datetime: Relative encoding type in a subject table column, generator training no longer fails and the encoding type is auto-set to Tabular/Datetime
- Upgraded to Angular 18.
- Upgraded to postgresql 16.4.0.
Resolved issues
- After you delete a primary key, the
primaryKeyattribute is now correctly set tonull
v306
Oct 14th, 2024
Improved auto-detection of date-time columns
This release includes several improvements in the auto-detection of date-time columns. For example, any string columns the contents of which resemble date-time values are now automatically set to the Tabular/Date-Time encoding type.
Auto-detection of geolocation columns
MOSTLY AI now auto-detects geolocation data in tabular columns. Columns with such data are now automatically set to the Tabular/Geolocation encoding type.
Improvements
- Implemented a GPU-efficient format enforcer for LLMs
- Right-click to open sidebar links in a new tab is now available
- Refactored the Assistant system prompt to ensure code samples are generated as expected
- Credits consumption now includes synthetic text generated in tabular columns with encoding type Language/Text
- Primary keys and foreign keys are not taken into account when determining encoding types
- Upgraded Keycloak to v25
Resolved issues
- Resolved an error which appeared when you start generating a synthetic dataset after uploading and removing a seed file
- Prevent the training of generators with no data added
- Overall generator accuracy now takes into account the accuracy of language models (fine-tuned LLMs)
- Resolved an issue with the calculation of used credits
- Resolved an issue with the reading of JSON files
- Resolved the
Error while processing this requesterror which appeared when attempting to upload files
v305
Oct 4th, 2024
Similarity metrics
The new Cosine similarity and Discriminator AUC metrics are now available at the top of Model and Data reports for generators and synthetic datasets.
Each report also contains a Similarity section with plots that represent how the training, synthetic, and holdout datasets compare to each other in terms of their distributions.
For details, see Overview of quality metrics and Similarity sections on the Evaluate generator quality page.
Improvements
- Hover over
_RARE_values shows explanation and a link to the documentation - Use Esc to close modal windows and drawers in the UI
- Lists retain state when using the Back and Forward buttons in your browser
- Enabled opening generators and synthetic datasets in a new tab
- The Coordinator API is now split into Job Control API and Job Message API
- The Secure Job Message API now uses a job-specific authentication token
- Preserve optimizer/LR schedule states beyond job resume
- Updated tooltip styles
Resolved issues
- Fixed a potential bias for long sequences (>1k) in case of small sample size (<10k)
- Fixed incoherent data for linked tables if
sample_size<generation_batch_size, which can occur in low-memory environments with star schemas - Improved the display and truncation of long-named generators and synthetic datasets
- Fixed an issue with the resume of LLM fine-tuning on GPUs
- Fixed an issue for text columns consisting of only NULL values
v304
Sep 26th, 2024
Improvements
- Added in-progress notifications for the cloning of generators and synthetic datasets and the download of synthetic datasets
Resolved issues
-
TABULARmodels no longer appear for tables withoutTABULAR/*encoding types. This applies to generators and synthetic datasets that have a table with a singleLANGUAGE/TEXTcolumn. - The Assistant no longer shows
Unable to fetcherror for a dataframe that was not saved to a file. - To ensure that you can import generators created prior to v303, the compute is not listed in the Training status section when you import such generators.
v303
Sep 23rd, 2024
Distances (DCR) metric now uses 10% validation set as a true holdout
The Distances metric (Distance to Closest Record) now uses a 10% validation dataset as a true holdout. The true holdout is drawn completely randomly from the original dataset.
With this approach, the distances are now calculated between the synthetic samples and their closest neighbors from the training dataset (90% of the original dataset after the holdout split). For reference, you also have the distances between the synthetic samples and their closest neighbors from the holdout dataset. You can then use both distances calculations to gauge that the synthetic samples are just as close to the training data as they are to the holdout data (the data not seen during training).
Distances (DCR) metric now uses embeddings
The Distances metric is now improved to use embeddings for both tabular and text columns. As embeddings aim to capture the semantic similarities between words, the metrics now calculate the L2 distance between samples converted to JSON that are then embedded in a vector space and the distances between samples are then compared.
For details, see Distances.
Improved resilience of running generators and synthetic datasets
MOSTLY AI now supports improved mechanisms to ensure that running generators and synthetic datasets complete training and generation successfully even in the case of unexpected infrastructure interruptions. Such failures can be the result of evicted compute nodes due to cluster resource polices that may reschedule a resource for other tasks.
For running generators, the training process automatically restarts from the last checkpoint with the saved model weights to ensure that training progress is never lost due to unexpected interruptions.
Improvements
- Selected compute now appears for each model in the Training status and Generation status sections
- Get the actual datetime of when a generator or synthetic dataset was created by hovering over the time elapsed value next to the Created by field
- Use the new Auto encoding type and MOSTLY AI will detect the best encoding type for a column
- For GPU computes: auto-select max generation batch size for faster LANGUAGE generation
- Logs download is now available for all jobs for all users
Resolved issues
- Resolved a UI issue in fairness configuration which in certain cases resulted in the configuration not being applied during generator training
- Relationship diagrams are now always available for synthetic datasets the generators of which have been deleted.
- Applied a fix to the
max_new_tokenheuristic to reduce the number of generated_INVALID_values from fine-tuned LLMs - Dropped the
accuracyproperty fromGeneratorListItementity in the REST API - Resolved an error that occurred when generating
Nonevalues for columns with theLanguage/Textencoding type
v302
Sep 16th, 2024
Resolved issues
- Resolved an issue to ensure that users continue with their previous workflow and are not redirected to the Home page when the authentication token expires but the session is still valid.
v301
Sep 13th, 2024
Clone generators
If you want to reuse the configuration of a generator, you can now use the new Clone operation. The Clone operation is available for all existing generators with the sole exception of those with file uploads. For such cases, you need to re-create the generator and re-upload the original files.
For details, see Clone a generator. In addition, you can also check out the Clone a synthetic dataset section.
Improvements
- Redirect to login after session timeout
- Cap length of Nested Sequence Context to 20 to limit peak memory
- Improved numeric stability of training
- Upgraded Pandas to 2.2
Resolved issues
- Fix startup conflict in case default compute env vars have been changed
- Preserve seed columns during generation
- Improved resilience of multi-table generation
- Trim context sequences to the max sequence length observed during training
v300
Sep 5th, 2024
Fine-tuning LLMs for synthetic text
MOSTLY AI introduces new integration with LLMs to enable synthetic text generation that is privacy-protected and highly correlated within tabular datasets.
The MOSTLY AI Platform makes available a number of HuggingFace language models for fine-tuning and synthetic text generation. More models can be made available upon request. Contact MOSTLY AI Support.
For on-premises deployments, you can integrate with any model and make it available for fine-tuning within your organization.
- For a quick start, see Quick start with fine-tuning LLMs.
- For LLM configuration details, see Models configuration.
- For the latest changes in encoding types, see Set encoding types.
Improvements
- The compute ID is now visible for each compute in the Update Kubernetes configuration window
Resolved issues
- The
createShareAPI endpoint is now available only to users who have Editor permission for a generator, synthetic dataset, or assistant chat.
v232
Aug 30th, 2024
Improvements
- To simplify single Compute setups, setting a toleration is no longer required
Resolved issues
- A fix to always use the first Compute, based on
order_index, as the default compute for new jobs - Resolved an issue introduced in v231 encounted when generating very large SDs during final MinIO cleanup
v231
Aug 28th, 2024
Improvements
- You can now type to search destination connectors in the Synthetic dataset destination selector
- Reduced the number of synthetic data copies kept in the internal storage.
- Download as CSV is now restricted to synthetic datasets containing less than 100M data points.
v230
Aug 27th, 2024
Resolved issues
- Added storage information to heartbeat log messages
- Added an error message when attempting to probe a generator that is still training
v229
Aug 26th, 2024
Resolved issues
- Fixed a race condition between writing resource monitor logs and uploading them to MinIO shared storage
- Synthetic datasets with a fairness configuration now run successfully on GPU-enabled computes
v228
Aug 23nd, 2024
Better error reporting for failed jobs
This release introduces new error reporting for failed jobs. A new heartbeat mechanism keeps track of running jobs and reports errors immediately when a step fails. The logs are available for download from the new error tooltip at the step at which a job fails.
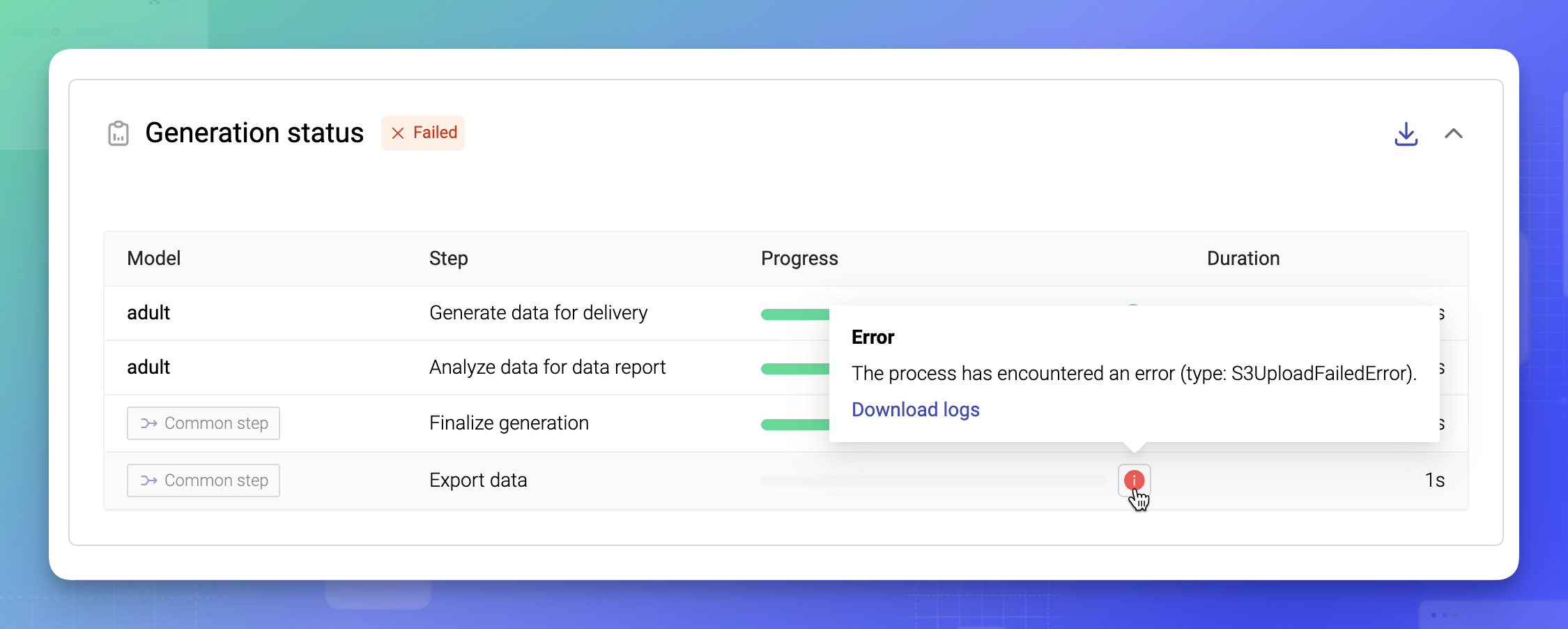
* The term job refers to the “training of a generator” or the “generation of a synthetic dataset”.
Improvements
- You can now cancel stalled jobs that are still reported as In progress
- Logs for running jobs are now uploaded with every “heartbeat” message to aid the troubleshooting of any jobs that fail
- Added logging of failures due to user defined in a connector lacking insufficient privileges when delivering synthetic data to a cloud storage bucket
v227
Aug 22nd, 2024
Assistant tokens usage
Each Assistant chat now includes information about the number of tokens used in the chat. Tokens are counted both for the number of tokens sent and received. Tokens used in Assistant chats count towards your daily credits usage.
Tokens are counted in chats starting from version 227. Chats created before this version will always have their tokens used count shown as 0.
For details, see Usage and credits.
Edit existing computes
Super admin accounts can now edit existing computes and change the number of CPUs and memory, or the number of GPUs and GPU memory, the cluster toleration, or the order index for a compute.
For details, see Edit a compute in the Administration section.
Logs available for failed jobs
You can now download the logs of failed jobs. The logs are available for download from the Training status and Generation status sections of generators and synthetic datasets, respectively.

Improvements
- Introduced heartbeat messages for Assistant chats to avoid unexpected timeouts and incomplete Python code execution
- Improved the error message when the downloading of logs for generators or synthetic datasets fails
- Improved the error message when a user tries to open a resource (generator, synthetic dataset, or connector) that is not shared with them
v226
Aug 16th, 2024
GPU support
MOSTLY AI introduces Nvidia CUDA GPU support for your synthetic data workloads 🎉
Our testing shows that you can now achieve the following with GPUs:
- ~2x to ~5x speedups of generator training across most single-table and multi-table scenarios
- ~24x speedup of generator training for datasets with sequence lengths of 100
- ~2x to ~9x speedups of synthetic data generation across most single-table and multi-table scenarios
With flexible computes now supported, you can assign the same or separate GPU computes to each AI model task, either when you train a generator, or when you generate synthetic data. For example, for your subject table AI model training you can use a CPU compute, and for linked tables with long sequences you can select a GPU compute and reduce overall training times.
To start, you can now define your custom compute that includes GPU and select the compute that best fits the needs for each task. For details, see Flexible compute.
Flexible compute
With flexible compute, we want to enable all custom deployments of MOSTLY AI to define flexible compute resources.
As long as the underlying hardware supports a compute resource with a defined number of CPUs and memory, or a defined number of GPUs and GPU memory, you can add a custom compute.
Thereafter, you can assign each AI model to use a different compute. This applies to both generator training and synthetic data generation.
For details, see Compute in the Administration section.
Easiest way to start Assistant chats
The New chat button is now available directly from the sidebar. You can now start new Assistant chats from anywhere in the app.
v225
Aug 16th, 2024
Resolved issues
- Increased the maximum length of Oracle VARCHAR2 columns to avoid potential failures when delivering synthetic data to Oracle databases
v224
Aug 14th, 2024
Resolved issues
- The Reports column title in Data insights for both generators and synthetic datasets now appears correctly
v223
Aug 8th, 2024
Search database schemas and tables when adding tables to generators
In the MOSTLY AI UI, you can now search your available databases schemas and tables from when you are adding database tables to a generator.
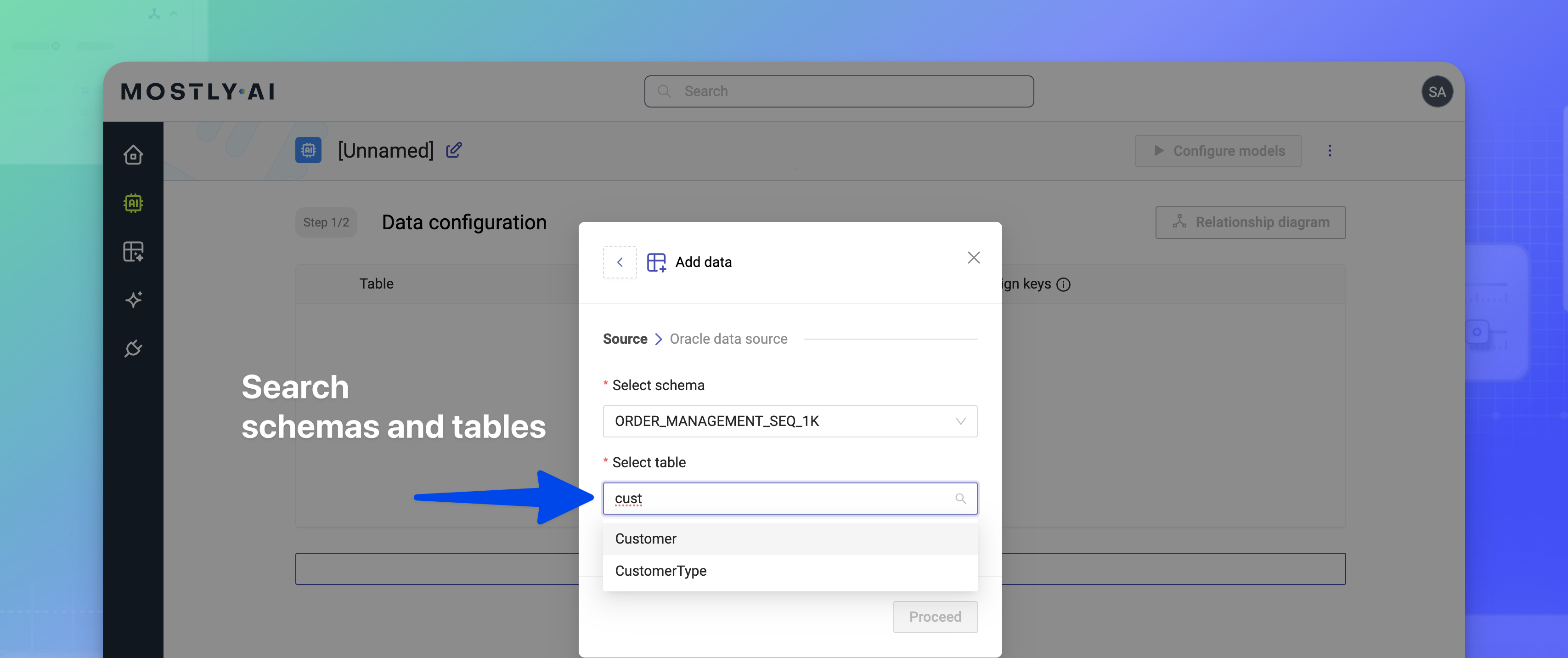
For details, see Add data from a database.
Monthly usage report
Organizations that deploy MOSTLY AI in their own private cloud environment now have access to their monthly usage in their monthly reports.
For details, see Monthly usage reports.
Resolved issues
- When delivering synthetic data to an Oracle database, the CLOB data type is now specified only for columns that originally had the CLOB data type in the source Oracle database
v222
Aug 2nd, 2024
Interactive data tables in Assistant chats
Assistant chats now support the display of tabular data in interactive tables. The interactions are available directly whenever the Assistant displays a data table. You can sort, search, paginate, and download the data in CSV format.
Run your Python code in Assistant chats
You can now run your own Python code in Assistant chats. For all those cases where you need to run your custom code and not the one generated by the Assistant, you can now paste your Python snippet directly and the Assistant will run it for you.
Improvements
- Introduced tokenization for Text-like columns for the calculation of their accuracy in the Model and Data reports
- Upgraded to pytorch 2.4.0
v221
Jul 29th, 2024
Personalize your Assistant experience
All users can now add custom instructions to personalize the Assistant responses. To customize, go to the Settings menu and insert your instructions. You can provide instructions for:
- Personal Insights: What would you like the Assistant to know about you to provide better responses?
- Response Style: How would you like the Assistant to respond?
Define these to tailor the assistant’s functionality to your needs.
Improvements
- While configuring a new synthetic dataset to generate data with fairness, an error message now informs that you cannot use the same column as a fairness target and a fairness sensitive column.
- Added client principal for Kerberos authentication for the Hive connector, enhancing security and compatibility with secure environments.
- Now we support custom SSL certificates for S3, improving connectivity and security for users requiring specific configurations.
Resolved issues
- Fix for maintaining internal sequence order.
v220
Jul 19th, 2024
Resolved issues
- Fix for an issue that caused empty rebalancing categories for generators with tables from multiple sources.
- Fix for AuthToken error messages appearing on UI.
v219
Jul 18th, 2024
Share MOSTLY AI assets publicly in your organization
Admins can now share Generators, Synthetic datasets, Connectors and Assistant chats with all users in their organization.
Use the Share button and turn on the Any authenticated user can view toggle.
Improvements
- Enforcing a timeout for testing Oracle connections to ensure more efficient and reliable connection checks.
Resolved issues
- Fix for an issue that prevented uploading a file in Assistant chats for some users.
v218
Jul 17th, 2024
File uploads in Assistant chats
The Assistant has made data insights easier than ever. And it can reason very well about your MOSTLY AI assets - generators and synthetic datasets. But you might also need to work with external data. The Assistant now supports this too.
You can now upload files in Assistant chats. You can do so with single or multiple files. Instant examples are typical data file types, such as CSV, Parquet, or Excel. But you can use any file type that an LLM can process.
For details, see Upload files in Assistant chats.
Add MOSTLY AI assets to Assistant chats
While you can use the Explore button from any generator or synthetic dataset to open the Assistant, you can now also add these assets directly to an Assistant chat. This way, you can easily refer to them in a conversation.
Use the new Resources menu and select either Use a generator or Use a synthetic dataset option. You are then able to select the asset from a UI list.
For details, see Use a generator or a synthetic dataset.
Python session status in Assistant chats
Each Assistant chat also runs a Python session in the background to run any Python code generated by the Assistant. That session expires after 15 minutes of inactivity. You can now track your Python session status in each chat. The session now is started as soon the chat is created.
For details, see Python session status.
Improvements
- The Public API now relaxes the requirements to define all columns in the configuration when you train a new generator. You can now specify any subset of columns and the generator will train only on the specified columns.
- Now we provide default system instructions for the Assistant and we made these editable.
- Performance improvements for users with many generators or synthetic datasets.
- Upgraded SQLAlchemy to version 2 to enable Databricks writes on Azure and Databricks read on SQL Warehouses.
Resolved issues
- Fix for using proper TEXT_MODEL-specific train parameters rather than using the base model parameters.
- switch to MS ODBC Driver 18 and Oracle thick client to improve connectivity.
v217
Jul 3rd, 2024
Improvements
- You can now stop ongoing Assistant responses by clicking the Stop button
Resolved issues
- Fixed the import/export of generators for deployments using S3 as storage backend
- Fixed the import/export of generators for specific multi-table scenarios
v216
Jul 3rd, 2024
Introducing fair synthetic data
MOSTLY AI introduces a new feature that allows the generation of fair synthetic data. It helps to generate statistical parity synthetic data where you can target a specific column for fairness (for example, income) and easily remove biases based on other sensitive columns in your datasets, such as race, sex, age, or any other attribute that you define as sensitive.
For details, see Generate fair synthetic data.
Redesigned navigation
MOSTLY AI supports a new look and feel with a redesigned navigation.
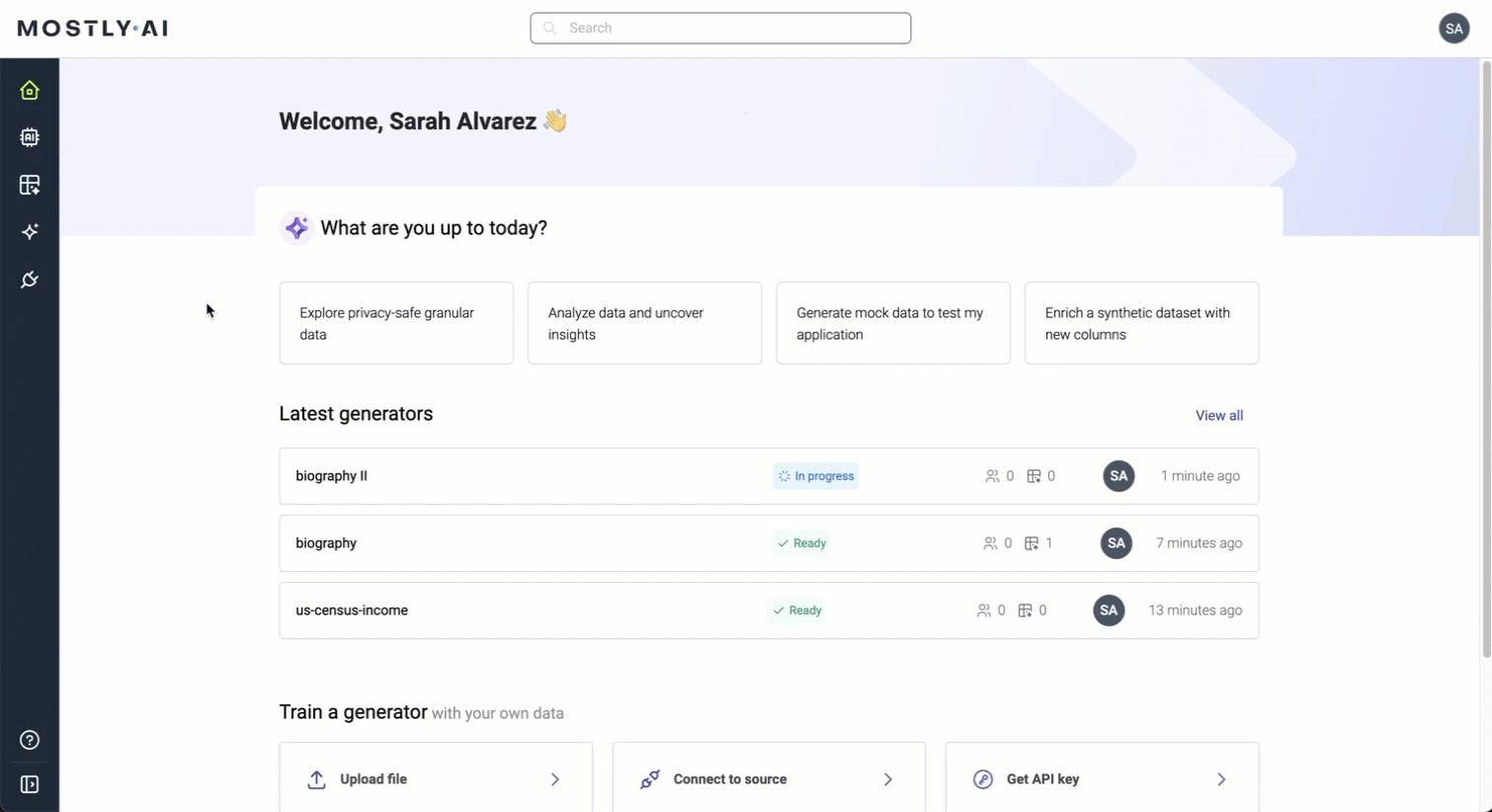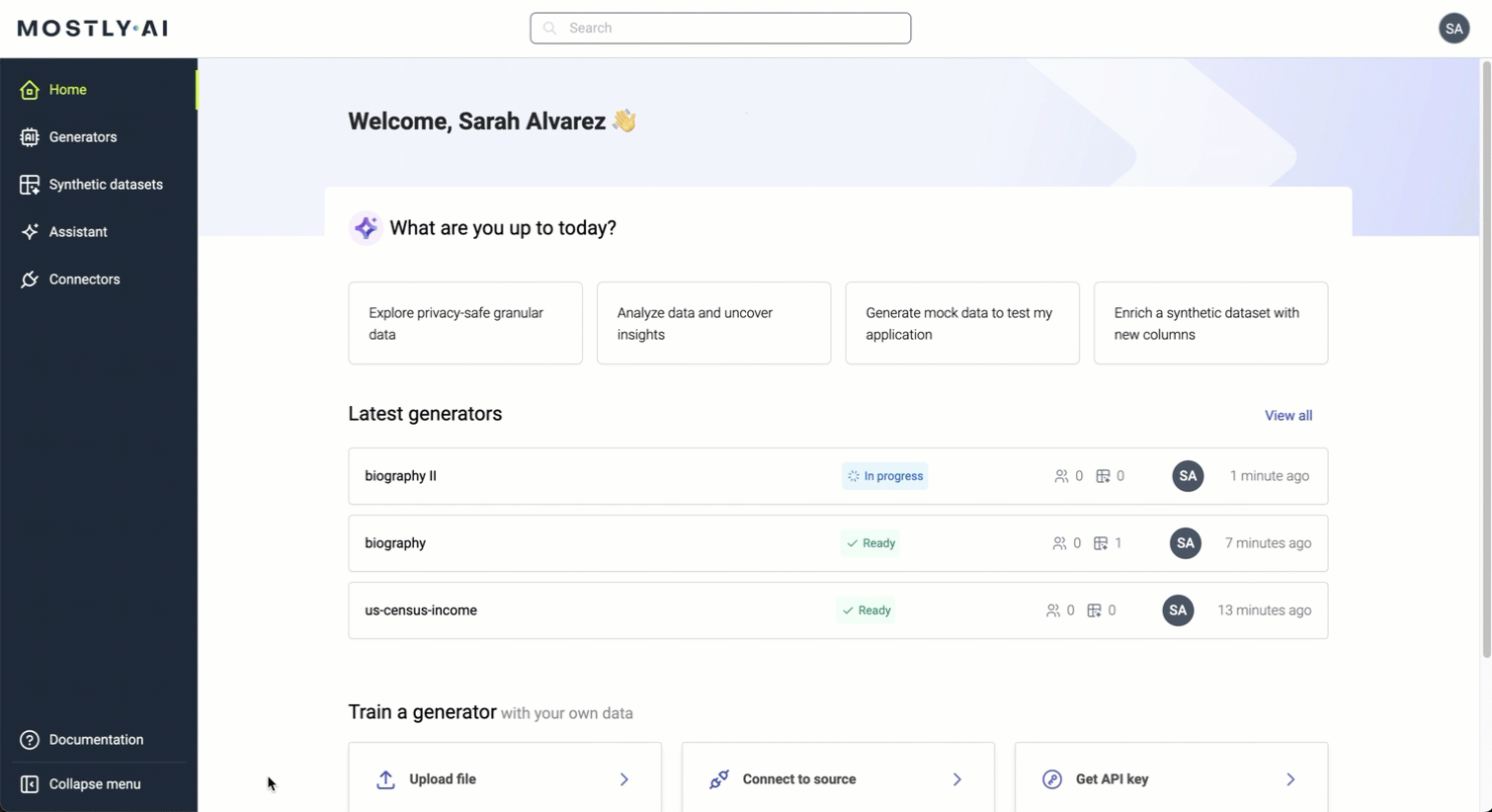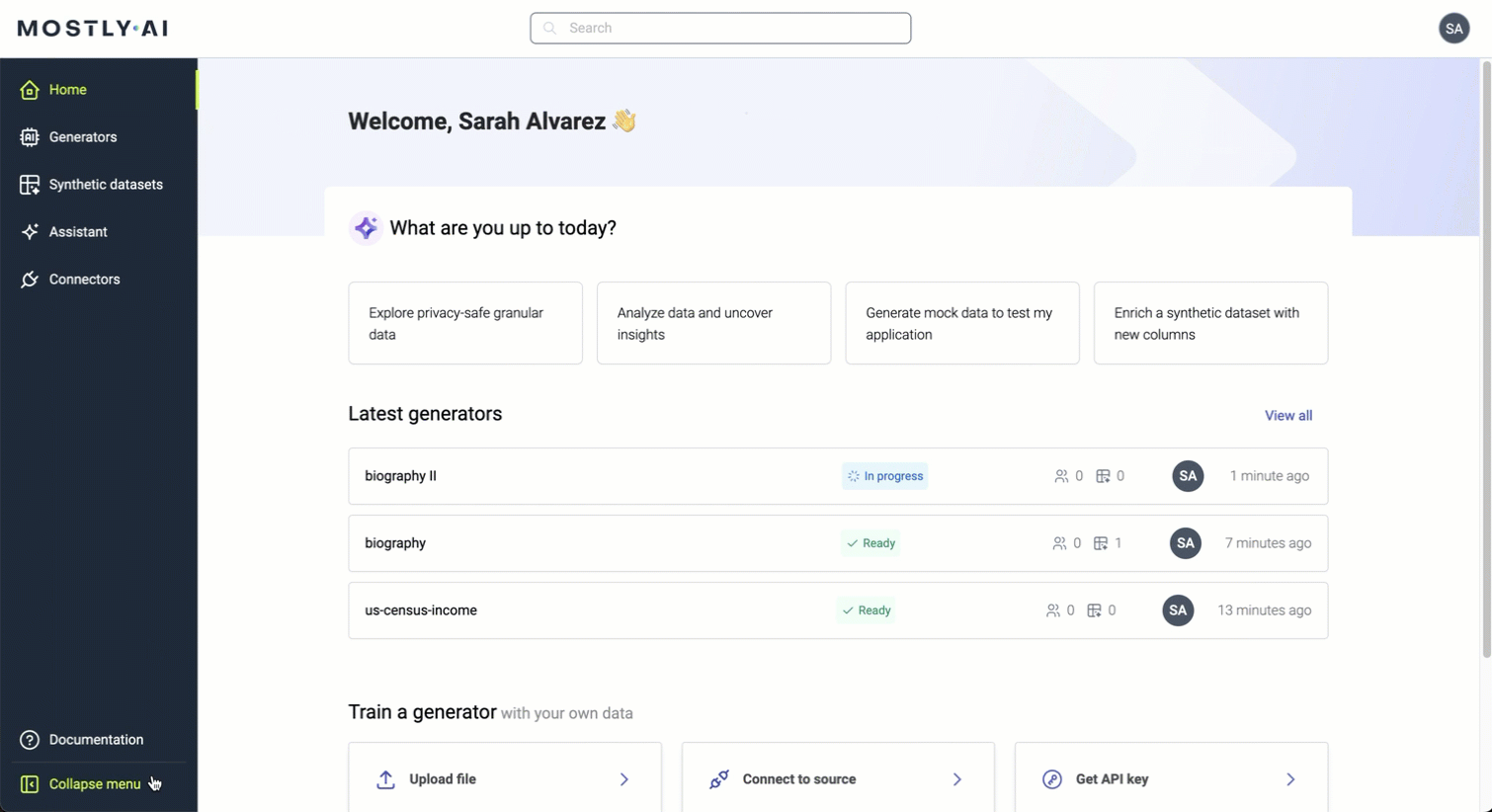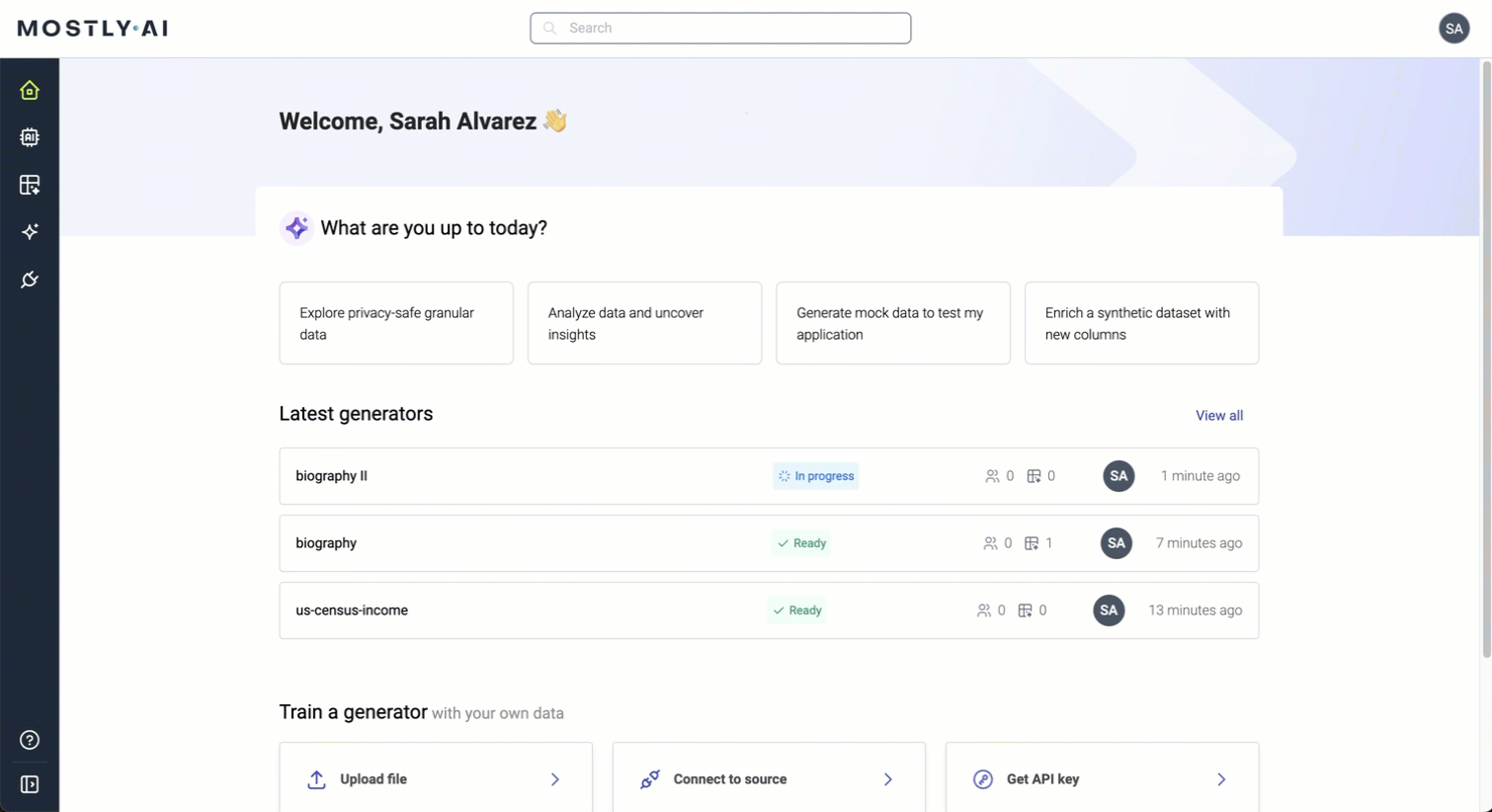
The new navigation bar now appears on the left, where you can now find the Generators, Synthetic datasets, Assistant, and Connectors. The menu expands when you click the Expand / Collapse button at the bottom.
Also, the Search bar is now centered at the top for easy access to your favorite entities.
Export and import of generators
You can now export and import generators between different instances of MOSTLY AI.
With this capability, organizations can now run the training of generators in secure environments close to original data, and then make a trained generator available in another environment where everyone at the organization can freely generate privacy-safe synthetic data.
For details, see Export and import of generators.
Navigation sections expand automatically
When you click one of the right-side navigation sections in generators and synthetic datasets, your browser scrolls down to focus on the section and the section is expanded automatically.
Improvements
- Upgraded the web app from Java 17 to Java 21
Resolved issues
- Resolved breaking Excel exports caused by same-named tables that differ in casing (for example,
playersandPlayers) - Resolved an incorrect propagation of
sampleSizeto child tables when adding a Text model
v215
Jun 26th, 2024
Resolved issues
- Resolved an issue when connecting to an Oracle database with a service name
v214
Jun 18th, 2024
Track modified generation in Data insights
The use of several features can cause the synthetic data you generate to have modified distributions when compared to the original data. These features include:
- Temperature and Top P
- Rebalancing
- Imputation
- Generate with seed
When you apply any of these features on the generation of synthetic data, the Data insights section now shows the Generation as Modified. (By default, the Generation is indicated as Representative). When you hover over Modified, it provides a list of the features that impact the distributions.
For details, see Evaluate synthetic dataset quality.
Updates in Data insights
Several additional improvements are now also part of Date insights.
- In synthetic datasets, you can now track Original total rows and Generated rows.
- In generators, you can now track Original total rows and Sample size.
- You can now check the hierarchy of table relationships in the Data insights section for generators and synthetic datasets.
- The Model and Data reports now open directly in your browser.
Improvements
- Display available categorical values when configuring rebalancing via UI
- Generated Parquet data now contains string[pyarrow] instead of large_string[pyarrow] fields, due to some python libraries experiencing issues handling the latter
- Support writing data back to a SSL-enabled Hive instance
- Support SSL-enabled Postgres connections without requiring custom certificates
- Trimmed down the base image of Assistant kernels to decrease load times when launching kernels on new machines within the cluster
- UI optimizations
Resolved issues
- Resolved an issue related to the incorrect deletion of a rebalancing category when more than one category was defined
- Resolved an issue with new deployments of MOSTLY AI where the
superadminaccount was unable to access the API
v213
Jun 12th, 2024
Improvements
- Login screen updated with new MOSTLY AI slogan
Resolved issues
- Fixed
is_ticket_alivelogic for Kerberos authentication - Fixed missing UI messages for seed upload
- Removed the prefix
/to fix file download when using S3 as internal storage
v212
Jun 11th, 2024
SSL support for Hive connectors
You can now use SSL along with Kerberos authentication to connect to your Apache Hive data sources. When you create a new Hive connector, you can now specify the SSL configuration options.
For details, see Use Apache Hive for synthetic data.
Auto-generated titles for Assistant chats
After the second message in a chat, the Assistant now automatically generates a title for the chat based on the conversation content. You can now identify and find Assistant chats more easily based on the their conversation context and name.
Improvements
- LightGBM is now part of the pre-installed Python packages that the Assistant can run
- Improvements in core- and engine-related error and warning messages
v211
Jun 6th, 2024
Improvements
- Implemented speed improvements for fetching large datasets and for data sources without indexes (10x faster and more)
- Assistant UI improvements & fixes (scrolling, avatar icon, mitigation strategies for repetitions, and others)
- Refreshed the UI header section for all entities with a new look and feel
- The relationship diagram is now available for all states of a generator and a synthetic dataset
- Renamed UUID to ID within the UI to be consistent with the REST API
- Resolved a regression which resulted in not showing the correct error message for file uploads
v210
May 31st, 2024
Introducing Assistant
Today marks a significant milestone for every data-centric organization, as we at MOSTLY AI are budding with excitement to unveil the Assistant, a pivotal step in our ongoing mission to make data access and data insights available to all.
The Assistant is designed to simplify the way you interact with data, enabling natural language conversations to generate data on the fly, get instant data insights, explore rich synthetic data, and much more.
We believe synthetic data is the key to tackling the ongoing challenges organizations have with access to data due to privacy concerns. The Assistant can now bring data insights at the fingertips of everyone, regardless of their expertise.
- To experience, go to https://app.mostly.ai and open the Assistant page.
- For more information, see Assistant documentation.
Refresh your API keys
With the introduction of the Assistant, API keys generated before v210 are no longer valid. To continue using the REST API and Python client, you need to generate a new API key.
Improvements
- Data insights section (available when you open a generator or synthetic dataset) now displays the hierarchy of table relationships
- Browsers now show a progress bar while downloading larger files
- Introduced
shortLivedFileTokensfor downloading files, reports, and logs (requires Python client version 0.3.8) - The default sample size for live probing is now set to 1
v209
May 23rd, 2024
Live probing of generators via Python client and Public API
You can now use the Python client and Public API to get synthetic data samples in real-time without the need to create a synthetic dataset.
For more information, see Live probing.
Support for any S3-compatible storage
You can now use the updated S3 cloud storage connector to connect to any S3-compatible storage service.
The new Endpoint URL parameter is required only when you want to connect to a non-AWS S3 storage service.
For more information, see Use S3 for synthetic data.
Contextual search for generators, synthetic datasets, and connectors
You can now find a Search bar for each entity type on their respective pages - Generators, Synthetic datasets, and Connectors. You can use the Search bar to filter the list of available entities by searching in their name and description.
Also, contextual Search bars are now also available when creating generators and synthetic datasets.
- When you create a new generator and select a data source connector, a Search bar is now also available to search the existing data source connectors.
- When you create a new synthetic dataset and need to select a generator for it, you can use the Search bar to filter the list of existing generators.
Improvements
- You can now use the new Back button to go back to the Add data page if you started the creation of a new connector from that context
- Model and Data reports now include links and UUIDs of their originating generator and synthetic dataset respectively so that you can navigate back to each as needed
Resolved issues
- Fixed a cold-start issue and errors no longer appear after you log in to a fresh deployment for the first time
- Fixed an issue with the generation of multi-table setups with non-context relationships
- Improved the error messages for incorrect Azure Service Principal configurations
- Added specific error messages for incorrect access key, secret key, and endpoint URL when creating an S3 connector
v208
May 13th, 2024
REST API and Python client now provide table schema data
With the REST API and Python client, you can now get table schema information for any table that you can access via a connector. The table schema includes the list of table columns, their original vendor-specific data type, and their default model encoding type.
You can use this information to correctly set the table names and table column types when you train a new generator.
Improvements
- Improved the refresh mechanism of the Credits pop-up
- The generator option Max sample size for linked tables is now indicated as
seqsin the UI to indicate that you specify the number of sequences to train on - Improvements in the look and feel of Search results
- Implemented quicker archiving of Parquet files into ZIP format for the data download option
- Updated MOSTLY AI brand image in the login, signup, and password update pages
- The Training log table now gets intra-epoch messages sent every 5 minutes
- In Model and Data reports, the X-axis of binned categorical plots is now sorted by frequency rather than alphabetically
- Improved the error message for incorrect principal credentials when creating a Databricks or Azure connector with a Service principal account
Resolved issues
- After an upgrade of MOSTLY AI, you will now see UI text changes correctly without the need to clear your browser cache
- Resolved a browser cache issue when listing connector locations in the Add data dialog window
- Resolved a text display issue in the Update password screen
v207
May 3rd, 2024
Improvements
- Reduced memory footprint for large data generations
v206
May 3rd, 2024
Range of column values are now available in generator REST API response
For each column of original data, you can now get the privacy-safe range of values found in the column. You can use these values for rebalancing or for seeded generation. In the REST API, this is the SourceColumnValueRange property.
- For columns with encoding types Categorical and Numeric: Discrete, you can get the list of discrete values, sorted by popularity.
- For columns with encoding types Numeric and Datetime, you get a list of min and max values.
Improvements
- Upgraded to PyTorch 2.3.0, and dropped CUDA packages, reducing image file size back to < 2GB
- Dropped outstanding DB2 dependencies from Docker images, slightly reducing image file size
Resolved issues
- Fixed an UI issue with incorrectly displayed permission dropdown
- Fixed an UI issue that allowed Viewers to edit descriptions of entities
- fixed an issue that prevented two subject tables from having the same PK name
- Fixed an issue that prevented the setting of
maxSampleSizefor linked tables with the Python client - Fixed an issue that required a specific sort order of tables when training a multi-table generator with the Python client
- Improved the reliability of page refreshes for running generator training and synthetic data generation status changes
- Fixed an issue with the
Datetime: Relativeencoding type for cases of long, unevenly distributed sequence lengths
v205
Apr 30th, 2024
Resolved issues
Resolved an issue in the validation of the MOSTLY AI sign up form
v204
Apr 24th, 2024
Search
With the new Search bar (in the web application header), you can now search for your favourite generators, synthetic datasets, and connectors.
When you search, you do so within the names and descriptions of each entity. Search results are grouped by entity type.
Search is also available with the API and Python client.
Usage metrics
You can now track the usage of each generator, synthetic dataset, and connector you have in MOSTLY AI.
| Entity | Usage metrics |
|---|---|
| Generators | • synthetic datasets created with the generator • shares* |
| Synthetic datasets | • shares* |
| Connectors | • generators that used this connector • shares* |
* The metric shares shows the number of times you shared an entity with someone. While shares are recorded, the removal of shares is not tracked.
The metrics are available in the new Activity column of each entity in the web application and via the Python client. For more information, see Usage and credits.
Service Principals authentication for Azure and Databricks connectors
You can now create Azure and Databricks connectors that can authenticate with Service Principals.
For details on Service Principal accounts in Azure, see Sign in with a service principal using Azure CLI in the Azure CLI documentation.
For details on Service Principal accounts in Databricks, see Manage service principals in the Databricks documentation.
Improvements
- To aid the generation of large-scale datasets on hardware with limited resources, the generation of Data reports is now also limited with the same heuristic used for Model reports
- Upgraded PyTorch to 2.2.2
- Upgraded Keycloak to 24.0.3
Resolved issues
- Resolved an issue to show the correct Update account information form for users with Google authentication
- Model report is now available even for small datasets used for generator training
- Resolved an issue with synthetic datasets rebalancing which now works as expected when many fixed probabilities that you define as Rebalancing categories add up to 1.0
v203
Apr 18th, 2024
Markdown in entities descriptions
You can now use Markdown to create detailed and stylized descriptions for your generators and synthetic datasets. Use the CommonMark syntax.
- New paragraph - press Enter
- Soft break - double Space
- Italics - wrap in single asterisk of underscore, italic or italic
- Bold - wrap in double asterisks or underscores bold or bold
- Headings - start a line with
#,##, … for heading level 1, 2, … - Unordered lists - start a line with an asterisk
* - Ordered lists - start a line with a number (
1,2, and so on)
Each Description field can have up to 65,000 characters. You can change the descriptions of a generator after it completes training. Similarly, you can change that of a synthetic dataset after it is generated.
Create connectors on the fly
You can now create new connectors when you create a new generator or synthetic dataset.
To do so, use the New connector button from the Connect to source window when you create a new generator and from the Destination dropdown when you configure a destination for a new synthetic dataset.
Support for Kerberos authentication for Apache Hive connectors
Apache Hive connectors now support Kerberos authentication.
For more information, see Use Kerberos for authentication in Apache Hive connectors.
Better performance for large files
- This release includes a number of enhancements that provide significantly improved performance when pulling large data files (CSV, Parquet) from data sources.
Improvements
- You can now create Snowflake connectors to databases without a
publicschema - The Rebalancing column dropdown now includes only Categorical columns and excludes excluded and non-Text columns
- Auto-detection of non-ISO dates in datetime fields in CSV files
- Upgraded Keycloak to 24.0.2
Resolved issues
- When sharing an entity, the Owner label now appears in the dropdown for non-owners
- The
base_urlon the API key page now always reflects the URL of the current MOSTLY AI deployment - Resolved an issue that incorrectly triggered a flexible generation error when updating sample size
- Resolved the Python client error which appeared when you tried to generate a synthetic dataset (
mostly.generate) with a generator that you had already shared (mostly.shared(g, EMAIL))
v202
Mar 28th, 2024
Improvements
- Model and Data reports now download immediately as an HTML file that you can share
- Improved the generation of synthetic data with high cardinality columns
- Improved the generation of primary keys for large datasets
- You can now delete a connector regardless of whether it is currently in use (by a generator or synthetic dataset)
- Security update by upgrading Keycloak
Resolved issues
- When you configure a destination for new synthetic datasets, the Location drop down now refreshes correctly with updated connector locations
- The Rebalancing categories is now always visible on the Synthetic dataset configuration page
v201
Mar 19th, 2024
Use Apache Hive for synthetic data
This release introduces support for Apache Hive and you can now create connectors to use Apache Hive as a data source or destination for synthetic data.
Improvements
- Improved accuracy for sequential models
- Improved resilience for longer sequence models
- Support for viewing synthetic datasets when their generator is no longer available
- Logging for REST API requests
Resolved issues
- Fixed cleanup of storage folders when you delete entities
- UI fixes for the status refresh of generators and synthetic datasets
- Other minor UI resolved issues
v200
Feb 29th, 2024
Decoupling of model training and data generation
- Introduction of the Generator concept
- With generators, workflows are updated in a way that better reflects how the platform is used
- Users with access to production data (Model Creators) can train Generative AI on tabular data
- Users without access to production data (Data Consumers) can use trained Generators to create Synthetic Datasets
- Data Consumers have great flexibility on how to generate synthetic data for their specific needs
- Model Creators can describe their curated synthetic data asset before sharing with the world
- Generators are now a shareable data asset
Improved UI/UX
- Overall improved look & feel of the platform for more intuitive workflows
- Faster and simpler configuration of multi-table setups
- Faster and simpler configuration of advanced features, such as value protection and flexible generation
- More flexible way of configuring and working with data connectors
- More flexible way to control temperature of synthetic data generation
- Convenient way of defining maximum training time for predictable Generator creation duration
Python Client & REST API
- Provides full programmatic control of the platform
- Especially helpful for anyone who wants to work directly with synthetic data out of their code (Data scientists that work with Jupyter Notebooks)
Highly-scalable low-latency engine
- Improved performance and speed across the entire synthesis process
- Optimized performance for very large datasets
Improved data quality
- Excellent sequence length capabilities, catered specifically for large transaction data (0000s events per customer) i.e. multi-sequence multi-variate time-series
Strengthened privacy protection
- Improvements to prevent memorization of the models for small datasets
Flexible rebalancing
- For any number and any kind of attributes
Seed generation for single table
- Conditional generation with seed is now available on single-table generators
Improved & easier deployment
- More flexible options when it comes to required storage classes
- Improved memory management for more robust platform operation
- Simplified Helm Charts
- Centralized logging for easier maintenance and issue remediation
v122
Feb 21st, 2024
Improvements
- MSD-309 - Improved database connection management by maintaining up to 4 simultaneous connections and quickly closing any connections that become idle
- MSD-314 - Improved the logging that original data is deleted immediately after AI training completes
- MSD-279 - Improved AI training memory usage for datasets with high-cardinality categories and long sequences
v113.8
Feb 16th, 2024
Improvements
- MSD-309 - Improved database connection management by maintaining up to 4 simultaneous connections and quickly closing any connections that become idle
- MSD-314 - Improved the logging that original data is deleted immediately after AI training completes
v121
Jan 17th, 2024
Resolved issues
- MSD-209 - Improved the data quality for long sequences.
- MSD-223 - Increased an internal timeout to better handle larger CSV files.
v120
Dec 21st, 2023
New sequence and time-series training strategy
Drastically improved training performance for long sequence lengths, by allowing users to specify a maximum length of records, that is to be considered for each sequence during training of the generator model.
To use the Generate more data option with sequence data, you will need to create a new synthetic dataset.
v119
Dec 18th, 2023
Migration to PyTorch
MOSTLY AI has now migrated to PyTorch! The implementation of PyTorch now provides 2x to 3x faster AI model training times and up to 2x faster synthetic data generation times, reduced memory footprint, and better compute resource utilization.
To use the Generate more data option, you will need to create a new synthetic dataset.
Updated heuristic of Batch size = Auto
We updated the heuristic behind the selection of Batch size = Auto so that it auto-selects batch sizes for more optimal training times based on your subject and linked table data.
Resolved issues
Security and vulnerability fixes
v113.7
Dec 7th, 2023
Resolved issues
- MPD-3807 - Fixed an issue that caused the creation of new synthetic datasets with the
api/v2/jobsendpoint to fail withJob with catalog can't be started, because the catalog is not completed yet. - MCD-2309 - Security fixes by upgrading pyarrow library.
- MCD-2295 - Resolved an issue where primary keys were unexpectedly enforced even when not explicitly configured through the UI. Primary keys are now enforced only when configured through the UI.
v118
Nov 22nd, 2023
Resolved issues
- MCD-2309 - Security fixes by upgrading pyarrow library
- MCD-2295 - Resolved an issue where primary keys were unexpectedly enforced even when not explicitly configured through the UI. Primary keys are now enforced only when configured through the UI.
- MCD-2300 - Reduced the generation batch size to make it even more conservative in resolving out-of-memory issues.
v113.6
Nov 10th, 2023
Improvements
Updated generation batch size logic to take into account the model size
Resolved issues
MPD-3707 - Security fixes by upgrading to JDK 17, Spring Boot 3, and related libraries and components.
v117
Nov 9th, 2023
Improvements
- Added support for taints and tolerations in the MOSTLY AI Helm chart
- Security updates
Resolved issues
- MCD-2292 - Fixed a bug where Smart imputation functioned incorrectly for discrete and binned numeric encoding types.
- MCD-2296 - Reduced generation batch size to resolve out-of-memory issues.
v113.5
Nov 3rd, 2023
Improvements
- Added support for taints and tolerations in the MOSTLY AI Helm chart
- Improved data pull performance for star schemas
Resolved issues
- MPD-3672 - Fixed a bug that triggered the error message
Error while connecting APIincorrectly. - MCD-2272 - Fixed a bug in Model QA report that underreported accuracy for datasets exceeding 10k subjects with more than 10k data points each.
- MCD-2292 - Fixed a bug where Smart imputation functioned incorrectly for discrete and binned numeric encoding types.
v116
Oct 26th, 2023
Improvements
- The relationship diagram now accurately displays table hierarchies from top to bottom and correctly represents 1-n table relationships.
- Improved data pull performance for star schemas.
Resolved issues
- MCD-2246 - Fixed training failures for Text models when using data augmentation features for the non-Text columns.
- MCD-2272 - Fixed a bug in Model QA report that underreported accuracy for datasets exceeding 10k subjects with more than 10k datapoints each.
v115
Oct 12th, 2023
The term “Original” replaces “Training” in the QA report
To better indicate the metrics of your original data in the QA report, we replaced the term “Training” with “Original”.
Logging of peak virtual memory in AI model training logs
You can now find information about the peak virtual memory reached at the end of each training epoch in the training logs of a synthetic dataset.
Improvements
- MCD-2252 - The MOSTLY AI engine now uses the latest version of TensorFlow
- MCD-2245 - Improvements in the synthetic dataset logs for better readability
- MCD-2214 - Improvements in the QA report related to the Rare category protection where rare categories on the X-axis of Univariate and Bivariate charts are now indicated with a combination of
rareand a truncated alphanumeric hash string, such asrare...8fs2
Resolved issues
- MPD-3623 - Fixed the issue that made the View training logs button inactive for the AI model training for columns with the Text encoding type
- MCD-2244 - MOSTLY AI now includes fixes to make the application more resilient in cases when Kubernetes sends a restart command during the training step of a synthetic dataset which caused synthetic datasets to endlessly restart the training step and never finish the synthetic dataset
- MCD-2243 - Fixed the issue that could lead a synthetic dataset to fail with an
OutOfMemoryerror as a result of the original data containing very long sequences - MCD-2239 - Fixed the issue that caused a failure during training for linked tables where the linked tables contain very few samples with very short sequences
v113.4
Oct 12th, 2023
Logging of peak virtual memory in AI model training logs
You can now find information about the peak virtual memory reached at the end of each training epoch in the training logs of a synthetic dataset.
Resolved issues
- MPD-3623 - Fixed the issue that made the View training logs button inactive for the AI model training for columns with the Text encoding type
- MCD-2244 - MOSTLY AI now includes fixes to make the application more resilient in cases when Kubernetes sends a restart command during the training step of a synthetic dataset which caused synthetic datasets to endlessly restart the training step and never finish the synthetic dataset
- MCD-2243 - Fixed the issue that could lead a synthetic dataset to fail with an
OutOfMemoryerror as a result of the original data containing very long sequences - MCD-2239 - Fixed the issue that caused a failure during training for linked tables where the linked tables contain very few samples with very short sequences
- MCD-2193 - Fixed the issue which caused issues when reading a linked table if you excluded columns from the linked table through the UI
v114
Sep 28th, 2023
New table relationships viewer
When you are configuring a synthetic dataset, you can now get an overview of all relationships and foreign key types in the new Relationship diagram.
To open, click the new Relationship diagram button in the Tables page.
Resolved issues
- MCD-2217 - Resolved the error
[-<index>] not found in axiswhich appears during the encoding step of the creation of a synthetic dataset - MCD-2211 - Resolved an issue where columns with names that contain a dot character (
.) were previously dropped from the synthetic dataset - MCD-2210 - Resolved an issue which resulted in failed synthetic datasets when the original data contains a datetime column with a constant value for each row
- MCD-2208 - Resolved an issue for failed synthetic datasets started with the Generate more data > with seed option and failed with the error
unknown EncodingType None for <column_name> - MCD-2175 - Resolved the issue where Parquet files are not delivered to cloud bucket destinations
- MPD-3542 - Fixed the format of the creation date of a synthetic dataset that appears on the Summary page
- MPD-3630 - Fixed the issue that caused the error ‘License is missing’ related to the fetching of user data from Keycloak
v113.3
Sep 28th, 2023
Resolved issues
- MCD-2217 - Resolved the error
[-<index>] not found in axiswhich appears during the encoding step of the creation of a synthetic dataset - MCD-2211 - Resolved an issue where columns with names that contain a dot character (
.) were previously dropped from the synthetic dataset - MCD-2210 - Resolved an issue which resulted in failed synthetic datasets when the original data contains a datetime column with a constant value for each row
- MCD-2208 - Resolved an issue for failed synthetic datasets started with the Generate more data > with seed option and failed with the error
unknown EncodingType None for <column_name> - MCD-2175 - Resolved the issue where we delivered only CSV files and not Parquet files to cloud bucket destinations
v113.2
Sep 21st, 2023
Resolved issues
- MPD-3626 - Fixed the empty downloads of synthetic datasets
v113.1
Sep 19th, 2023
Resolved issues
- MPD-3542 - Fixed the format of the creation date of a synthetic dataset that appears on the Summary page
- MPD-3630 - Fixed the issue that caused the error ‘License is missing’ related to the fetching of user data from Keycloak
v113
Sep 14th, 2023
Auto-adding of child tables
When you add database tables to a synthetic dataset, MOSTLY AI now also automatically adds all related child tables. You no longer need to add related tables manually.
Better guidance for _RARE_ values
You can now find more explanation about _RARE_ values after you hover over each in the preview of synthetic samples in the Summary page.
Improvements in handling nested table relationships
For multi-table setups with a 3-level hierarchy, any correlation between the 3rd level entities and all the 2nd level entities, that link to the same subject, are now retained. For example, for a User > Order > Item setup, all Items now retain correlations to all other Orders that belong to the same User.
Resolved issues
- MCD-2190 - Resolved an issue with the use of the Numeric:Auto encoding type which caused the generation of synthetic datasets to fail for very large or very small datasets.
- MCD-2192 - Resolved an issue that caused some values in a numeric column with the auto-detected encoding type Numeric:Binned to be empty
- MCD-2204 - Resolved an issue where categorical columns were not auto-detected in Parquet files
v112
Aug 31st, 2023
Welcome, Synthetic datasets! (Goodbye, Jobs)
Synthetic datasets is why you use MOSTLY AI! High accuracy, high data quality, privacy-protected synthetic datasets.
We want you to focus on generating synthetic data and we are adding the term to the top-level menu in the MOSTLY AI Synthetic Data Platform!
With that, we also want to say goodbye to Jobs. You served our users well and we are thankful for it!
Source and destination connector types
You can now define each connector as either a data source or a destination. That way, you can only select destination connectors for your synthetic dataset destination and prevent the risk of selecting a data source as the destination.
New design for synthetic datasets summary
When you now open a synthetic dataset from the new Synthetic datasets tab, a new summary page provides easier access to the preview of sample data, the QA report, the tracking of the synthetic dataset progress, and the configuration of the synthetic dataset.
You can use the sidebar on the right to quickly access each section.
- Overview
- Sample data
- QA Report
- Logs
- Configuration
Numeric (Auto) encoding type
The new encoding type Numeric (Auto) is now auto-assigned to columns that contain numeric data. Numeric (Auto) uses heuristics to automatically assign the relevant one of the available Numeric encoding types: Discrete, Digit, or Binned.
You no longer need to worry about which Numeric encoding type you need to use. Just select Numeric (Auto).
v111
Aug 17th, 2023
New Numeric encoding types
You can now select from three different Numeric encoding types: Digit, Discrete, and Binned.
Preview of synthetic data is now available for shared jobs
The Synthetic data tab in a completed job is now available on shared jobs. When you share a link to a completed job with your team, they can now access the Synthetic data tab in the job and preview the generated synthetic data in the job.
Drop tables in the destination
The new option Drop tables in the destination in the Output settings will drop any tables that match the names of the tables in your synthetic data job. MOSTLY AI drops the tables at the start of the job before it completes AI model training and data generation.
You can enable Drop tables in the destination after you start a new job and select a database connector as the destination. The option is not available for cloud storage connectors.
Search database tables when adding them to a catalog
In v110, MOSLTY AI introduced a drop-down to add tables from a database. You can now enter a search term in the drop-down to filter the list of tables and more easily find the table you want to add.
v110
Aug 3rd, 2023
Support for multiple tables in ad hoc and cloud storage jobs
You can now create and configure multi-table jobs not only with databases, but also with file uploads and cloud storage catalog jobs.
New Tables tab in job configuration
For each job configuration, the new Tables tab gives you a list of all tables in the job. The Tables tab is also the new home of all training settings that were previously available in the Training settings tab. Moving forward, the Training settings tab will be no longer available.
In the Tables tab, you can now also add and remove tables from a job.
When you start a job, the Tables tab opens and contains no tables. You can add new tables with the Add table button. This action is supported in all job types: ad hoc, database catalogs, and cloud storage catalogs.
Easier database catalog creation flow
With the new database catalog flow, you no longer need to identify subject tables and rank them.
After you select a database connector, MOSTLY AI shows the new Tables tab where you can now add tables from your cloud buckets or databases and remove any tables that you no longer need.
Easier configuration of table relationships
You can now use the Foreign key option in Generation method to define relationships between tables. This is now available in the Data settings tab during job configuration.
To mark a table as a linked table, specify which of its columns is set as a Context foreign key to another table.
Table relationships configuration is no longer required to start a job
You can now start a job with two or more subject tables. You no longer need to define a relationship and mark any of the tables as a linked table.
Reference tables are now only available in old catalogs
With v110 of MOSTLY AI, the concept of reference tables is no longer available for any newly created jobs or catalogs. All tables in a job are either a subject table (by default) or a linked table (after you set a foreign key to another table). You can only view reference tables in catalogs that you created before v110.
However, you can no longer change the configuration of reference tables, such as set any primary or foreign keys.
Updates in Generate more data
You can now use Generate more data for all job types including database catalog jobs.
With the capability to have ad hoc jobs with multiple uploaded subject tables, for such jobs you will now need to specify the number of new generated subjects or provide a table seed for every subject table in the job.
Resolved issues
- MCD-2071 Implemented better precision when handling primary keys
v109
Jul 19th, 2023
Use different types of data sources and destinations for the same job
Regardless of the type of data source you use for your original data, you can now deliver the generated synthetic data into any type of destination that suits your downstream tasks.
You can now select a different type of connector for the delivery of your synthetic data, so you can mix and match, such as use original data from Databricks but deliver the synthetic data into Snowflake, or use original data from a Microsoft SQL Server database and deliver the synthetic data into a PostgreSQL database.
v108
Jul 6th, 2023
Preview generated synthetic data
When a synthetic data job completes, you can now preview the first up to 100 samples from each generated synthetic table.
Share links to generated synthetic data
With MOSTLY AI, you can now share links to completed synthetic data jobs with anyone. Send the links to colleagues or data-minded friends and they can download the generated synthetic data and review all available QA reports.
Improved star schema support with better handling of correlations between linked tables
We improved the support of star schemas and now provide better handling of the correlations between linked tables. In such cases, synthetic linked tables with correlations now have better quality and accuracy.
SSL support in PostgreSQL connectors
You can now configure your PostgreSQL connectors to use secure SSL connections to the database.
Job progress is now updated every second
As you track the progress of a running job from the Jobs tab or in the View tasks drawer, the progress is now updated every second to provide a more responsive experience.
Resolved issues
- MPD-3220 - In the previous version, when you clicked Stop generation while looking at a job progress in the View tasks drawer, the job would continue generating data and ignore the action. We have now resolved this issue and clicking Stop generation now takes immediate effect.
- MCD-1952 - When a column is set as both a primary key and a foreign key in the original data, MOSTLY AI prioritizes the foreign key relationship and the issue is handled gracefully.
- MCD-1951 - Resolved an issue when MOSTLY AI writes primary keys in UUID format that are longer than the maximum number of characters allowed by the column data type in the destination database
v107
Jun 21st, 2023
Databricks support
You can now create Databricks connectors and use Databricks catalogs as a data source or destination for your generated synthetic data.
Coherence report for linked tables
The Model QA report and Data QA report now contain a Coherence tab for linked tables (event & time-series data). In the Coherence tab, you can find bivariate plots that show how well the sequence and logic of events is preserved in the synthetic data.
Auto-update of training settings based on selected training goal
When you set the Training goal for a synthetic data job, MOSTLY AI now auto-updates the training settings Maximum training epochs and Training samples to values appropriate for the selected training goal.
| | | | --- | :--- | | Accuracy | Maximum training epochs is set to 100| | Speed |- Maximum training epochs is set to 10
- Training samples is set to 100000
- Maximum training epochs is set to 1
- Training samples is set to 10000
Actual and maximum theoretical accuracy in QA report
The Accuracy tab in the Model QA report now shows maximum theoretical accuracy in parenthesis, next to the actual accuracy for each column.
Improvements
- MPD-3182 - Improved the indication of mandatory fields and default values in all database and cloud storage connector configuration screens
- MPD-2985 - The Accuracy tab now orders columns by their univariate accuracy in descending order
- MPD-3080 - The training setting Limit records per subject is now renamed as Limit sequence length
v106
Jun 7th, 2023
BigQuery support
You can now create BigQuery connectors and use BigQuery as a data source or destination for your generated synthetic data.
Use the new Turbo training goal for quick synthetic data jobs
For testing purposes, you might need to run and complete synthetic data jobs rapidly without the need for accuracy. For such cases, you can now use the new Turbo training goal. When you select Turbo, MOSTLY AI automatically sets the Maximum training epochs setting to 1 and reduces the training time to a minimum so that you can get a quickly generated synthetic dataset.
Improvements
- MPD-3105 - The Data settings screen now shows the type of mock data you selected for a column.
- MPD-2476 - You can now set Encoding type: ITT for more than one column in a linked table.
Resolved issues
- MPD-3084 - The metric Context columns no longer appears in the QA report for subject tables.
- MCD-1812 -
_RARE_token values in Categorical columns in the input dataset are now considered as actual categories and no longer result in the crashing of synthetic data jobs. - MCD-1868 - We made optimizations to reduce the number of jobs that fail with
OutOfMemoryerrors. - MCD-1982 - Empty linked tables (that have columns defined but contain no rows) no longer crash synthetic data jobs. MOSTLY AI generates the same empty tables in the synthetic dataset.
v105
May 25th, 2023
Performance improvements
After a number of performance optimizations to our database and queries, the MOSTLY AI Synthetic Data Platform now supports even more simultaneous synthetic data jobs.
Resolved issues
MPD-3147 - Due to some incorrect assignments of foreign keys in specific cases, we disabled the auto-assignment of foreign keys when you upload subject and linked table files.
v104
May 16th, 2023
Snowflake support
You can now create Snowflake connectors, and with that, read original data directly from as well as write synthetic data directly to your Snowflake databases.
Auto-detection of CSV data types
MOSTLY AI now instantly recognizes the correct data types for uploaded CSV files. Previously, this was done as part of the data synthesis.
With this change, the Encoding Type AUTO is now deprecated.
Support for Gzip and Bzip2 files
You can now speed the provisioning of large files by uploading them as Gzip (.gz) or as Bzip2 (.bz2) archive files.
Support for TSV files
You can now upload TSV (tab-separated values) files.
Specify single files from cloud buckets
Previously, you were only able to specify the containing folders as a cloud bucket. With this release, you can now specify the path to individual files on a bucket.
Support for JSON Lines, Feather and ORC format (experimental)
You can now provide your original data as JSON Lines, Feather, or ORC format.
Resolved issues
MCD-1862 - MOSTLY AI now discards rows with duplicate primary keys if you have such in your dataset.
v103
May 8th, 2023
Granular options for Generation mood
Generation mood now includes additional options for finer control over the type of distribution that you want to achieve in the generated synthetic data.
v102
Apr 24th, 2022
Home page
We want to welcome you to the new Home page in the top navigation bar. With the Home page, you have easier and direct access to MOSTLY AI features. You can review them below.
- Upload files In the Upload files tab, you can upload (drag-and-drop or browse to select) a CSV of Parquet file with data to immediately configure and start a synthetic data job.
- Connect to a source On the Connect to a source tab, you can immediately create a connection to a new database or cloud bucket.
- Start a synthetic data job with an existing sample dataset Under Or use sample data, you can immediately start a synthetic data job with any of the datasets that are available. Pick one and start a synthetic data job for it with the Start button.
- Last six completed jobs Under Existing synthetic datasets, you can review the last six completed jobs. The card for each job indicates if the synthetic data passed the Privacy check and what its overall Accuracy is.
Reference tables are no longer copied in the synthetic dataset
To prevent any potential data leaks, MOSTLY AI no longer copies Reference tables in the generated synthetic data.
Resolved issues
- MPD-3064 - Fixed the issue where the Save button remained inactive after you edited a column with a Smart select relationship.
- MPD-3039 - Fixed the issue that kept the Delete button inactive in the Catalogs tab.
v101
Apr 3rd, 2023
Improvements
Easy onboarding with Magiclink
You can now login to MOSTLY AI using Magiclink.
Resolved issues
- MCD-1691 - Fixed the issue that job fails due to too few samples being provided by the User.
- MCD-1740 - Fixed the issue of having Nulls in a Text column.
v3.0
Mar 7th, 2023
Kubernetes and Openshift support
MOSTLY AI 3.0 will use Kubernetes and Openshift as the deployment method.
Smart imputation
Smart imputation allows the user to create a synthetic dataset where specific columns don’t contain null values.
Rebalancing
Rebalancing allows you to specify the distribution of specific values in a column. Using Rebalancing, you can create a large number of relevant business scenarios out of the few that are present in your data. Use it to simulate what-if scenarios based on your historical data, or make minority classes visible for downstream machine learning algorithms.
Generation mood
Generation mood allows you to control the degree to which the synthetic version of the column will adhere to the detected distributions and correlations in the original data. The following generation mood settings are available:
Conservative - Generates synthetic data strictly within the business rules captured in the data. Representative - Generates synthetic data that adheres less strictly to the business rules captured in the data. Creative - Generates synthetic data skewed toward the outliers of the detected distributions.
New QA Report that reflects Programmable synthetic data metrics
With the introduction of the Programmable data, we are now providing quality assurance metrics for the model and data separately.
MariaDB support
You can use MariaDB both as a data source and as a data destination.
New User Interface
The look and feel of the application are updated, along with the below improvements:
- We are now providing consistency throughout the application in terms of flows and page elements, which will allow you to use the application more efficiently.
- The steppers and information boxes will help you through your journey.
- Data, Training, and Output settings are separated in different tabs
- We are giving a visual clue of the configured number using a thousand separator to help you work more efficiently with large numbers.
Rare / Extreme Value Protection updates
Enabling / Disabling the Rare Category Protection
You can enable or disable Rare category protection for categorical type columns.
Extreme Value Protection
You can enable or disable Extreme value protection for numerical, datetime, and ITT-type columns. If enabled, the values of the smallest and largest outliers in these columns will be replaced by the non-outlier values.
Improvements
Improved Quality
The context of all the tables in the hierarchy is now being propagated to the offspring tables. Also, the smart select columns are normalized in the context to improve quality further.
Editing settings of multiple columns at once
You can select and edit multiple columns at once.
Downloading synthetic data as CSV/parquet for all types of jobs
You can now download synthetic data for all types of jobs. If you don’t have access to a destination database/bucket, you can use the Download as CSV/parquet option to download your synthetic data.
Resolved issues
- MPD-2715 - PK and FK relationships are not correctly set for file based jobs.
- MCD-1469 - Fixed the issue that catalogs with multiple context foreign keys may not complete synthetic data generation.
- MCD-1445 - Fixed the issue that batch sizes greater than 4096 crashes synthetic data generation.
- MCD-1438 - Fixed the issue that in database synthesization jobs, tables whose names start with an ___ fail to be read.
- MCD-1432 - Fixed the issue of misalignment of data partitions occurring when the subject table is big and the linked table is small.
- MPD-2576 - For Ad hoc jobs, the default rare category protection method is now Constant instead of Sample.
- MPD-2532 - Fixed the issue that tables with multiple foreign keys may crash when the relationships have been edited in the data catalog.
- MPD-2480 - Fixed the issue that users cannot upload tables that are partitioned over multiple files.
- MPD-2478 - Fixed the issue that free version users see Local Server as a data connector option while unavailable to them.
- MPD-2470 - Fixed this issue that Mock is selectable as an encoding type.
- MPD-2444 - Fixed the issue that the encoding type is not saved when a linked table column is set to ITT.
- MPD-2604 - Fixed the issue that in Ad Hoc jobs, column settings are not persisted after saving when switching tabs.
- MPD-2340 - In Ad hoc jobs and Cloud storage data catalogs, the Edit relationships drawer is automatically shown to the user if the foreign key is not found.
- MPD-2443 - Certain database relationships result in two context foreign keys to the same referenced table, resulting in an error during synthesization.
- MPD-2395 - When creating a data connector, the schema field is marked as mandatory for databases that don’t require it.
- MPD-2381 - For Ad hoc jobs and cloud storage catalogs, the linked table’s first column is automatically selected as the foreign key.
- MPD-2378 - When a table has an unexpected character, the error message doesn’t mention the issue as such, nor does it state where it occurs.
- MPD-2339 - If there is only one referring table, it doesn’t show up in the Primary key and referring tables section.
- MPD-2281 - The column settings drawer shows the incorrect generation method for Smart Select and context foreign keys.
- MPD-2060 - For users of the free version, Local storage is no longer an option when creating data catalogs.
- MCD-1381 - Missing values in the numerical columns of Parquet files are not correctly read.
- MCD-1373 - The Smart Select algorithm throws an error if the referring table is empty.
- MCD-1364 - The database data connector throws an error if there are empty tables.
- MPD-2371 - Tables are not shown in alphabetical order in the ‘Database contents’ section of the database table selection step.
- MPD-2357 - The job settings’ column details of uploaded Parquet files show Auto-detect instead of encoding types.
- MPD-2356 - Parquet files cannot be used as a seed for the Generate more data feature.
- MPD-2351 - When starting an Ad hoc job, users can upload 2 different files as a subject table.
- MPD-2347 - Reference tables’ primary keys are not copied but generated.
- MCD-1325 - QA report generation fails when analyzing database datetime columns that contain values in an unknown format.
- MCD-1327 - Sequence lengths are incorrectly calculated in an edge case scenario.
- MPD-2194 - When creating or modifying a data connector, the Test connection button doesn’t check whether the specified schema can be accessed.
- MPD-2178 - Whitespaces in the header row of CSV files cause issues during synthesization.
- MCD-1275 - QA report generation fails when synthesizing Parquet files.
- MCD-1273 - Incorrect processing of scientific notation in CSV files.
- MCD-1266 - Certain datetime ranges are incorrectly processed as strings.
- MCD-1265 - Restrictive rules causing the QA report to fail in certain edge cases.
- MCD-1261 - Long warning messages within the app’s architecture causes it to crash.
- MCD-1260 - QA report fails when a column is configured as ‘mock data’.
- MCD-1259 - Incremental timestamps in time-series data may generate inconsistent synthetic data when configured as ITT.
- MCD-1258 - QA report fails when a numerical column is completely empty.
- MCD-1257 - Synthesization fails if the linked table’s entries are not linked to the subjects in the subject table.
v2.4.4
Dec 5th, 2022
Improvements
MCD-1217 - When synthesizing databases, the data types of the original schema are now respected, regardless of encoding type.
Resolved issues
- MCD-1469 - Fixed the issue that catalogs with multiple context foreign keys may not complete synthetic data generation.
- MCD-1445 - Fixed the issue that batch sizes greater than 4096 crashes synthetic data generation.
- MCD-1438 - Fixed the issue that in database synthesization jobs, tables whose names start with an ___ fail to be read.
- MCD-1432 - Fixed the issue of misalignment of data partitions occurring when the subject table is big and the linked table is small.
- MPD-2576 - For Ad hoc jobs, the default rare category protection method is now constant instead of sample.
- MPD-2532 - Fixed the issue that tables with multiple foreign keys may crash when the relationships have been edited in the data catalog.
- MPD-2480 - Fixed the issue that users cannot upload tables that are partitioned over multiple files.
- MPD-2478 - Fixed the issue that free version users see Local Server as a data connector option while unavailable to them.
- MPD-2470 - Fixed this issue that Mock is selectable as an encoding type.
- MPD-2444 - Fixed the issue that the encoding type is not saved when a linked table column is set to ITT.
- MPD-2604 - Fixed the issue that in Ad Hoc jobs, column settings are not persisted after saving when switching tabs.
- MPD-2340 - In Ad hoc jobs and Cloud storage data catalogs, the Edit relationships drawer is automatically shown to the user if the foreign key is not found.
v2.4.3
Oct 11th, 2022
Improvements
- MPD-2175 - When running a job, the View training logs is now visible by epoch 1 and shows a spinner to indicate that the training is being canceled.
- MPD-2267 - The QA report for linked tables no longer displays the linked table name along with the context table name.
- MPD-2088 - When adding new foreign keys with the relationships drawer, if there are more than 1 parent tables without primary keys, the error message shows all these tables instead of only the first one.
Resolved issues
- MPD-2443 - Certain database relationships result in two context foreign keys to the same referenced table, resulting in an error during synthesization.
- MPD-2395 - When creating a data connector, the schema field is marked as mandatory for databases that don’t require it.
- MPD-2381 - For Ad hoc jobs and cloud storage catalogs, the linked table’s first column is automatically selected as the foreign key.
- MPD-2378 - When a table has an unexpected character, the error message doesn’t mention the issue as such, nor does it state where it occurs.
- MPD-2339 - If there is only one referring table, it doesn’t show up in the Primary key and referring tables section.
- MPD-2281 - The column settings drawer shows the incorrect generation method for Smart Select and context foreign keys.
- MPD-2060 - For users of the free version, Local storage is no longer an option when creating data catalogs.
- MCD-1381 - Missing values in the numerical columns of Parquet files are not correctly read.
- MCD-1373 - The Smart Select algorithm throws an error if the referring table is empty.
- MCD-1364 - The database data connector throws an error if there are empty tables.
v2.4.2
Sep 28th, 2022
Improvements
- Multiple synthesization jobs started at the same time will now be processed one by one instead of all at once.
Resolved issues
- MPD-2371 - Tables are not shown in alphabetical order in the ‘Database contents’ section of the database table selection step.
- MPD-2357 - The job settings’ column details of uploaded Parquet files show Auto-detect instead of encoding types.
- MPD-2356 - Parquet files cannot be used as a seed for the Generate more data feature.
- MPD-2351 - When starting an Ad hoc job, users can upload 2 different files as a subject table.
- MPD-2347 - Reference tables’ primary keys are not copied but generated.
- MCD-1325 - QA report generation fails when analyzing database datetime columns that contain values in an unknown format.
- MCD-1327 - Sequence lengths are incorrectly calculated in an edge case scenario.
v2.4.1
Sep 12th, 2022
Improvements
- Ad hoc jobs can now synthesize Parquet files.
- CSV files can now have semicolons (;) as well as commas (,) as column separators.
Resolved issues
- MPD-2194 - When creating or modifying a data connector, the Test connection button doesn’t check whether the specified schema can be accessed.
- MPD-2178 - Whitespaces in the header row of CSV files cause issues during synthesization.
- MCD-1275 - QA report generation fails when synthesizing Parquet files.
- MCD-1273 - Incorrect processing of scientific notation in CSV files.
- MCD-1266 - Certain datetime ranges are incorrectly processed as strings.
- MCD-1265 - Restrictive rules causing the QA report to fail in certain edge cases.
- MCD-1261 - Long warning messages within the app’s architecture causes it to crash.
- MCD-1260 - QA report fails when a column is configured as ‘mock data’.
- MCD-1259 - Incremental timestamps in time-series data may generate inconsistent synthetic data when configured as ITT.
- MCD-1258 - QA report fails when a numerical column is completely empty.
- MCD-1257 - Synthesization fails if the linked table’s entries are not linked to the subjects in the subject table.
Security updates
Security updates have been made to the following components:
- Java and Python libraries
- RabbitMQ
- Internal PostgreSQL database
- Keycloak
v2.4
Aug 29th, 2022
Synthesize databases even if they don’t have a schema, and impress your colleagues with its QA report.
-
Relationship manager
Use the relationship manager to add and modify relationships so that you can tailor the synthetic version of your database entirely to your use case. It’s specifically designed to help you synthesize databases without schema or with an incomplete schema. -
A QA report for everyone
You can now download and share the QA report of your synthetic databases with your colleagues. Not only did we make it easy to share, but also easy to read! + We worked on numerous improvements that help you assess synthetic data quality and convey the message that your synthetic data is privacy-secure and an accurate representation of your company’s valuable data assets.
Relationship Manager
Whether your database is small or large, with or without schema, we’ve got you covered. You can now complete the relationships between your database’s tables so that all of its data assets can be properly secured and accurately synthesized, QA report included.
And if you’re dealing with partially defined relationships and don’t know which ones are missing, you can count on us as well. Our handy ‘Tables without relations’ filter gets you going in no time!
Working with the relationship manager is not complicated either. Watch this 6-minute video tutorial to get you up to speed.
QA report
- Improved interactive charts help you easily pinpoint and identify potential accuracy issues in the synthetic data.
- There’s no need to wait for it either! QA report generation now takes seconds per table rather than minutes, so you can immediately assess the quality of your synthetic data.
- Explainer sections in the report help the reader understand what they’re looking at.
- The QA report now comes in a handy, self-contained HTML document that retains all interactive charts when sharing it across your business and partnerships.
Resolved issues
- MPD-2198 - When the ‘number of generated subjects’ is left blank, the number of training subjects is used if defined, instead of the number of subjects in the subject table.
- MPD-2185 - Incorrect number of columns reported in the QA report.
- MPD-2180 - ‘Cancel training’ and ‘Cancel generation’ buttons are not working when synthesizing data.
- MCD-2057 - UI issues when creating an Oracle database data connector.
- MCD-1177 - Incorrect handling of SID and SERVICE_NAME connections to Oracle databases.
- MCD-1169 - The QA report of certain datasets have an Incorrect placement of labels in the correlation matrix.
- MCD-1163 - Numerical columns may generate a casting exception during generation causing a job failure.
v2.3
Jul 7h, 2022
Whether you’re a student, small business, or enterprise, our Synthetic Data Platform is ready to serve your needs
- Effortless onboarding with our new video tutorials
Our new video tutorials help users start synthesizing your company’s valuable data assets right away and help them understand what’s going on in each step. - Audit logs for compliance and security
MOSTLY AI’s audit log keeps track of who accessed the system, what they looked at, and what actions they took. - Improved synthesization of your database’s sequences
The order of your linked tables’ lists, sequences, and time-series data embodies valuable information. MOSTLY AI now allows you to sort your linked tables by column so that all sequential information is optimally preserved.
Free edition
The best AI-driven synthetic data generator is available free of charge forever for generating up to 100K rows daily. If you want to generate high-quality, privacy-safe synthetic versions of your datasets for machine learning, testing or data sharing use cases, MOSTLY AI’s synthetic data generator is at your service. And it’s available straight from your browser after a simple registration.
Effortless user onboarding with video tutorials
Our new video tutorials help users start synthesizing your company’s valuable data assets right away and help them understand what’s going on in each step. There are three video tutorials available:
-
Privacy-secure your customer data
Users will learn to synthesize a table with basic customer profile information, such as their name, address, birth date, etc., and get a glimpse into the type of insights they can obtain from it. -
Privacy-secure behavioral customer data
Users will learn to synthesize a subject table-linked table dataset and understand how to deal with lists, sequences, and time-series data. -
Create a realistic and secure test database
Test engineers will learn to create a subset of a production database that is privacy secure and referentially intact while maintaining all business rules and relevant business scenarios for testing.
Audit logs for compliance and security
System administrators can now retrieve an audit log from the MOSTLY AI Synthetic Data Platform. It keeps track of information regarding who accessed the system, what they looked at, and what actions they took. This temporal information is important to proving compliance and security.
Improved synthesization of your database’s sequences
The order of your linked tables’ lists, sequences, and time-series data embodies valuable information. MOSTLY AI now allows you to sort your linked tables by column so that all sequential information is optimally preserved. For time-series data, you can now also select the ITT (Inter-Transaction-Time) encoding type. It models the time interval between two subsequent events, resulting in a very accurate rendering of the time between events.
Resolved issues
- MPD-2090 - License renewal issues.
- MPD-2033 - QA report generation crashes when a CSV file contains
\nsymbols. - MCD-1131 - Out of memory issues when synthesizing subject table-linked table datasets.
- MCD-1079 - The trained AI model is lost when the training crashes.
- MCD-1070 - In rare cases, numerical values are incorrectly detected as boolean values.
v2.2
May 1st, 2022
- Transform your business with synthetic data that’s effortlessly privacy-secure, efficient, and fast*
- Take advantage of a synthetic data engine that’s mindful of your time and hardware resources.
- Benefit from a much-simplified preparation of your synthesization jobs. The web UI now serves your goals, while MOSTLY AI handles complex configurations in the background.
- Our new user management system lets you create groups, manage group-level access permissions, and lets users share synthetic data assets with these groups.
- MySQL support enables synthetic data in the cloud, integrating MOSTLY AI with cloud databases like AWS Aurora, Google Cloud SQL, and many more.
A smarter, faster & more efficient MOSTLY AI
For the past few months, we have been working to make synthetic data work for your business. Here are some of the highlights:
-
We achieved a more than two-fold increase in synthesization speed, significantly reducing the resource footprint of synthetic data in your company.
-
Preparing synthetic data has become much simpler. The engine now determines the best AI model and outlier protection settings for your dataset and use case.
-
Benefit from better resilience for missing files, rows, columns, and so on. Defects in your data sources will no longer cause issues.
Increased speed
Benefit from a smaller synthetic data footprint and shorter time-to-data
-
MOSTLY AI can not only process datasets virtually limitless in size, it can now ingest and encode them faster than before.
-
Overall AI model training speeds halved, and wide tables now benefit from a faster training time for the first epoch.
-
We achieved a ten-fold increase in synthetic data generation performance. What MOSTLY AI used to generate in minutes can now be done in seconds.
Better synthetic data
Privacy-security is now out-of-the-box and takes zero effort to realize
-
MOSTLY AI protects rare categories by replacing them with non-rare categories. Release 2.2 replaces them in a context-aware manner. For instance, if a female data subject has a rare name, it will be replaced with a female non-rare name.
-
Rare category protection can no longer be adjusted or turned off.
-
Extreme values are now protected in all numerical formats, including datetime and ITT.
-
Lists, sequences, and time-series data now benefit from extreme sequence length protection.
-
Improved accuracy of sequence length distributions in the synthetic data, as minimum sequence lengths are now respected.
Simpler preparation
-
Use the batch size AI model training parameters to balance training speed with memory availability. The appropriate learning rate is now calculated in the background.
-
If your synthesization job doesn’t run as desired, you can choose a smaller or bigger AI model size to mitigate the issue.
-
The job summary now shows a progress bar for each epoch, giving you an indication of how long AI model training will take.
-
The “generate more data” function for synthesization jobs created with release 2.2 will now work with all upcoming versions of MOSTLY AI.
Manage users and groups
Create groups and let users share assets across them
-
As an admin, you can now create groups and manage group-level access permissions. This makes it easier to manage permissions for multiple users or reassign individual users if they change jobs in the organization.
-
As a user, you can now share synthetic data assets with your group or with other groups.
MySQL Data connector
Use the MySQL family of databases for synthetic data
The MySQL data connector enables synthetic data in the cloud and integrates MOSTLY AI with cloud databases like AWS Aurora, Google Cloud SQL, and many more.
Resolved issues
- MPD-1781 - License issues due to restarted VMs.
- MPD-1439 - The data connector details view doesn’t show the database name.
- MCD-952 - The AI server crashes when there’s an issue with assigning foreign keys using Smart Select.
- MCD-939 - Generation crashed if the precision is specified for columns with floating point numbers.
v2.1
Apr 26th, 2021
Equip yourself with the most comprehensive synthetic data platform on the market
MOSTLY AI 2.1 continues our mission to deliver an enterprise-grade synthetic data platform and remain the leader in the tabular synthetic data space.
-
We now support the DB2 family of databases, enabling synthetic data for mainframe applications.
-
Our new Text encoding type allows you to synthesize unstructured natural language. MOSTLY AI 2.1 now covers all tabular data types, from categories to geolocation data and beyond. The world is all yours!
-
Benefit from searchable and interactive charts in the QA report, allowing you to intuitively spot opportunities to further improve synthetic data quality.
Synthetic text
Put unstructured natural language texts to use in your AI/ML applications.
Insurance claim reports, medical diagnoses, and other types of unstructured texts are very rich sources of information, capturing details that aren’t present in numbers or other structured forms of data.
Our new Text encoding type allows you to privacy-protect these texts and put them to use in various AI/ML use cases, for example:
- Named-entity recognition
- Sentiment analysis
- Testing—by generating real descriptions
- E-commerce analytics—by synthesizing customers’ search keywords
DB2 Data connector
Use DB2 databases for synthetic data
You can now connect MOSTLY AI to the DB2 family of databases. + Use them as a data source or as a destination, and enable synthetic data for mainframe applications.
Updated QA Report
All privacy and accuracy charts are now in a hand’s reach
Our privacy and accuracy charts are now available in the web UI, so you can intuitively evaluate the quality of your synthetic data.
Spot opportunities to further improve quality and immediately apply them to the job settings.
- Use the search function to look up specific columns.
- Interactive charts allow you to learn more about specific data points.
- Enlarge them to study them in detail.
Resolved issues
- MPD-1596 - Job cancellation hangs when using AWS ECR.
- MCD-885 - Job won’t start if the String pattern of the Custom string mock data type is not defined.
- MCD-754 - The Generate more data feature crashes with some of the supported datetime formats.
- MCD-806 - Jobs may crash if they process very wide tables.
- MCD-760 - AI model training crashes when consistency correction and GPU acceleration are both active.
v2.0
Nov 2nd, 2021
Synthetize your data wherever it is
Mostly AI 2.0 is now capable of synthesizing entire databases!
It connects to your data sources, recognizes its columns and their relationships, and provides you with a synthetic version of your data wherever you need it.
There are no more limits to what you can synthesize. Connect to your databases, buckets, and files without any hurdles.
Be ready for the synthetic data revolution. It’s already here.
New UI
A new customer centric UI
With Mostly AI 2.0 we introduce a new UI!
The new UI has been redesigned with a customer centric approach.
The task of creating a new synthesization job has never been easier.
And it looks cool too!
Multi-table data catalog
Synthesize complex data structures
With Mostly AI 2.0 it is now possible to define multi-table data catalogs!
The complexity of your data source is now represented in the data catalog:
- Support of primary keys,
- Support of foreign keys,
- and Referential integrity.
The platform understands the relationships between all the tables and create a synthesization plan based on these relationships.
The result is synthetic version of your data in its original form!
Parallel computing
Better performance thanks to parallelization
Thanks to a major architectural redesign, the Mostly AI platform now supports parallel computing.
In case of multi-table synthetic generation, the Mostly AI platform will intelligently divide the tasks that can be calculated in parallel in the available VMs.
Data connectors
Create your data source once and re-use it!
You can now define data connectors in the Mostly AI platform!
Data connector can be used as a source of data or as a data destination.
You can fetch data from your production data lake or database and push them wherever you need!
Mock data
A perfect way to test the extremes
Some of the biggest challenges when testing software can be getting the software into some very specific states. You want to test that the new error message works, but this message is only shown when something breaks. You may have no direct control over and you really need to manipulate this data in order to perform your tests.
You can now define Mock Data in the generation process!
Mock data makes it possible to simulate errors and circumstances that would otherwise be very difficult to create in a real world environment.
New QA report
A new and intuitive QA report
The new QA Report is available directly in the UI. You can explore the results of your generation job and see if there are privacy or accuracy warnings!