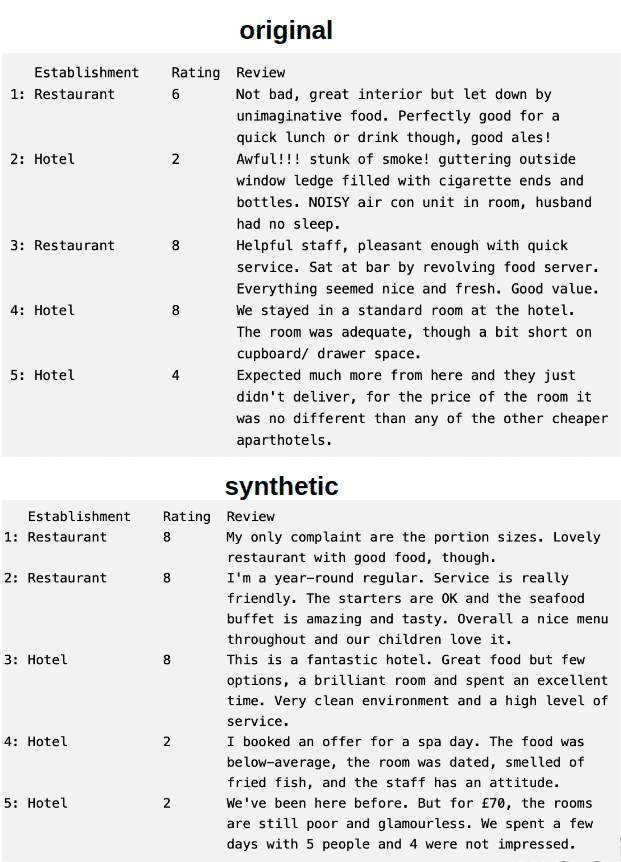
Introduction
Snowflake, a robust cloud-based data warehousing platform, has gained significant popularity for its ability to handle large volumes of structured and semi-structured data while delivering exceptional performance and flexibility.
From startups to enterprise-level organizations, the demand for data-driven insights continues to grow. However, traditional on-premises data warehouses often fall short of meeting the scalability and performance requirements of modern applications. This is where Snowflake shines. By leveraging the power of cloud computing and a unique architecture, Snowflake offers a compelling solution for storing, processing, and analyzing vast amounts of data with unparalleled ease.
Snowflake is a fantastic productivity booster. It decreases the time to value, and ensures that everyone has equitable access to performance. Synthetic Data serves a similar role. As a result, Snowflake is being offered as MOSTLY AI's new DB Connector.
Exploring the key features and benefits of a Snowflake integration
Snowflake has a variety of features that make it an attractive option for enterprises looking for an effective and scalable data warehousing solution. Here are some of the key features and benefits of Snowflake:
Scalability
Snowflake's cloud-based design enables you to scale up or down your data warehouse resources based on your individual requirements. This flexibility guarantees that you have the computational capacity you need to manage rising data volumes and concurrent user requests without sacrificing speed.
Performance
The unique Snowflake design separates computing and storage, enabling massively parallel processing and query optimization. Even when dealing with complicated analytical workloads, this leads to fast and efficient data retrieval.
Flexibility
Snowflake supports both structured and semi-structured data, allowing you to store and analyze a wide range of data formats from relational databases to JSON, XML, and others. This adaptability enables you to gain significant insights from a variety of data sources.
Data sharing
Snowflake's data-sharing features are powerful, allowing you to securely exchange data sets and interact with external partners, clients, or different departments within the organization. This allows data-driven decision-making and encourages a collaborative atmosphere.
Snowflake's architecture and cloud-based approach
Snowflake's architecture is based on a cloud-native foundation, allowing for easy connection with a variety of cloud platforms. The key components of Snowflake's architecture include:
Cloud storage
Snowflake uses cloud object storage for robust and highly accessible data storage, such as Amazon S3, Google Cloud Storage, or Microsoft Azure Blob Storage. This distinction between storage and computation enables effective data storage and retrieval.
Virtual data warehouse (VDW)
The VDW in Snowflake is the computational layer that handles query execution and processing. You may set up numerous virtual warehouses to serve various workloads at the same time, each with its own set of computational resources.
Metadata service
Snowflake's metadata service maintains metadata about your data, including schema information, table structures, and access restrictions. This unified metadata store guarantees uniform data governance while also allowing for efficient query optimization.
Query processing engine
Snowflake's query processing engine is designed to optimize performance and scalability. It scales computing resources dynamically in order to process queries in parallel, resulting in quicker query execution times and more effective resource use.
MOSTLY AI's Snowflake integration
Although Snowflake and MOSTLY AI operate in separate sectors of the data and analytics domain, we have many similarities. MOSTLY AI's Snowflake integration was a logical step on our product journey, looking to increase data consumption downstream.
Data privacy and security
Both Snowflake and MOSTLY AI prioritize data privacy and security. Snowflake provides robust data security features, including encryption, access controls, and compliance certifications. MOSTLY AI's synthetic data generation techniques focus on preserving privacy by generating data that cannot be reverse-engineered to identify individuals. As a result, organizations could leverage Snowflake's secure data infrastructure to store and process synthetic data generated by MOSTLY AI.
Data analytics and AI
Snowflake's data warehousing platform enables organizations to perform advanced analytics and derive insights from their data. Synthetic data generated by MOSTLY AI can be used as a privacy-preserving alternative for sensitive or personally identifiable data during analytics or AI model training. This combination could enhance data analysis and ML model training capabilities while maintaining privacy and compliance.
Productivity booster and breaking data silos
Data silos are often required by law, and certain data assets cannot be connected for compliance reasons. This is where MOSTLY AI’s capabilities come in handy. The synthetic versions of those datasets may work as alternatives and can serve as the sole choice for data collaboration. Combining those with a data warehouse solution like Snowflake is a must. As explained above, Snowflake's cloud-based architecture and data-sharing features contribute to increased productivity for data teams and organizations.
What’s in it for you?
The power of synthetic data: the game-changing Snowflake integration
MOSTLY AI's Snowflake integration is a significant milestone that opens up new opportunities for enterprises. It blends MOSTLY AI's superior AI technology with Snowflake's data warehousing solution's powerful features. This integration enables companies to exploit synthetic data while preserving the statistical features of the original data and ensuring data privacy.
Seamless integration for easy adoption
The ease of adoption of any technological solution is critical, and a Snowflake integration provides a smooth experience. Businesses may produce synthetic data straight from their Snowflake databases, avoiding complicated data transfers and duplicating critical information. This interface improves productivity, saves time, and allows enterprises to make the most of their Snowflake information while maintaining privacy.
Embracing the future of data-driven innovation
In a data-driven world, the capacity to successfully exploit data while protecting privacy drives innovation. MOSTLY AI's Snowflake integration offers a huge step forward in attaining this balance. Organizations can now use the power of synthetic data created straight from Snowflake databases to unleash new levels of creativity while adhering to the strictest data protection rules.
How to connect to your Snowflake account through MOSTLY AI
Step 1
From within the MOSTLY AI app, direct to the Connectors tab and click on the ‘Create connector’ button.
Step 2
Select the Snowflake icon and click proceed.

Step 3
Fill out the form that appeared in the drawer with your account details and the database you would like to connect. Copy and paste the Account URL from your Snowflake account into the ‘Account’ field.
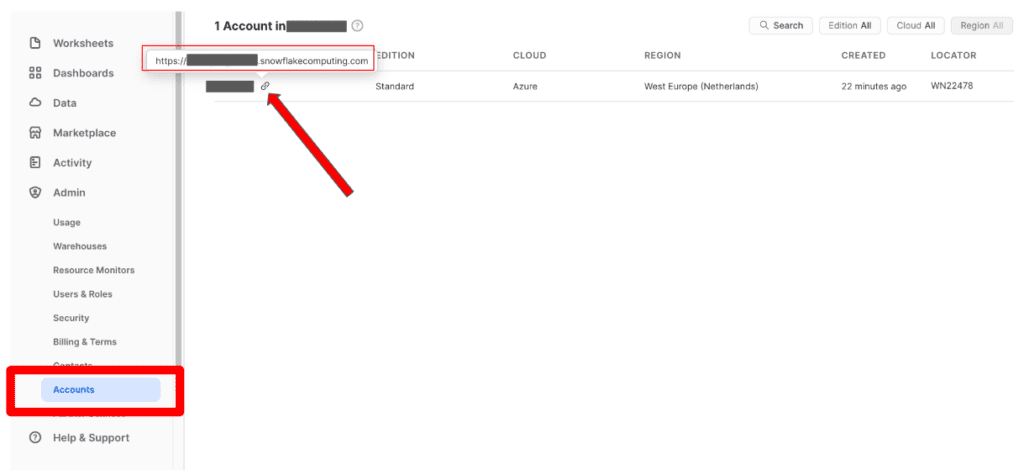
Step 4
Click on ‘Test connection’ to check whether we are able to connect with your Snowflake database and then ‘Save’ to save your Snowflake data connector.
Step 5
Create a new data catalog using your newly created Snowflake data connector and enjoy MOSTLY AI’s features.
For more in-depth documentation, please view our guide on connecting to Snowflake.
Snowflake integration for smooth data consumption
Snowflake is a great productivity booster. If combined for storing MOSTLY AI’s synthetic datasets it unlocks a vast amount of benefits and potential collaboration between departments within and outside an organization. It will also assist data owners who wish to increase collaboration and data-sharing by lowering time-to-data and governance costs, allowing innovation, democratizing data, and promoting data literacy.
We at MOSTLY AI are excited about the potential that Snowflake as our new database connector has to offer to our customers. We are eager to explore this path further with our customers to assist their journey towards data innovation, at a fraction of the time and expense, since the explorations in this blog post have shown the potential to support such a scenario.
As always we are more than happy to introduce you to our platform. If you are as excited as we are to use our new features do not hesitate to contact us and make the change for your organization and start working on your Snowflake integration today.
According to Gartner, "data and analytics leaders who share data externally generate three times more measurable economic benefit than those who do not." Yet, organizations even struggle to collaborate on data within their own walls. No matter the architecture, somehow, everyone ends up with rigid silos and uncooperative departments. Why? Because data collaboration is a lot of work.
The data mesh approach to collaboration
Treating data as a product and assigning ownership to people closest to the origins of the particular data stream makes perfect sense. The data mesh architecture attempts to reassign data ownership from a central focal point to decentralized data owners with domain knowledge embedded into teams across the entire organization. But the data mesh is yet to solve the cultural issues. What we see time and time again at large organizations is people becoming overly protective of the data they were entrusted to govern. Understandably so. The zero trust approach is easy to adopt in the world of data, where erring on the side of caution is justified. Data breaches are multimillion-dollar events, damaging reputations on all levels, from organizational to personal. Without trusted tools to automatically embed governance policies into data product development, data owners will always remain reluctant to share and collaborate, no matter the gains interconnecting data products offer.
The synthetic data mesh for data collaboration
Data ecosystems are already built with synthetic data, accelerating AI adoption in the most data-critical industries, such as finance. When talking about accelerating data science in finance, Jochen Papenbrock, Head of Financial Technology at NVIDIA said:
"Synthetic data is a key component for evaluating AI models, and it's also a key component of collaboration in the ecosystem. My personal belief is that as we see a strong growth of AI adoption, and we'll see a strong growth in the adoption of synthetic data at the same speed."
So making synthetic data generation tools readily available for data owners should be considered a critical component of the data mesh. Proactively synthesizing and serving data products across domains is the next step on your journey of weaving the data mesh and scaling data collaborations. Readily available synthetic data repositories create new, unexpected value for data consumers and the business.
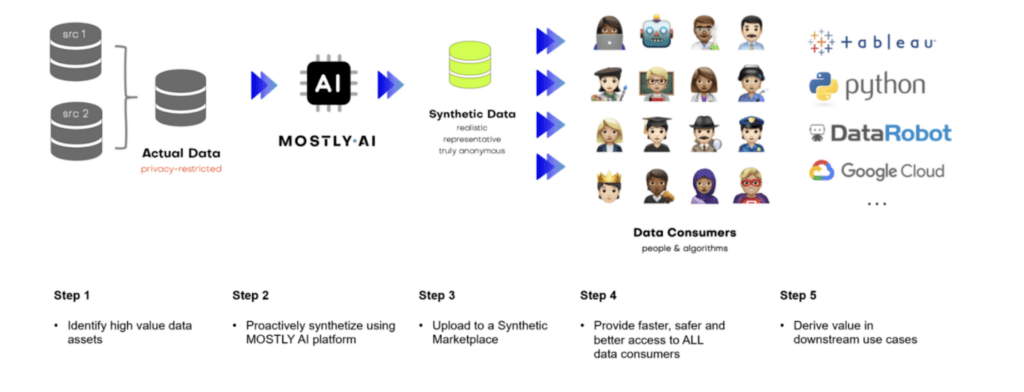
Examples of synthetic data products
Accelerating AI innovation is already happening at companies setting the standards for data collaborations. Humana, one of the largest North American health insurance providers, launched a synthetic data exchange to accelerate data-driven collaborations with third-party vendors and developers. Healthcare data platforms populated with realistic, granular and privacy safe synthetic patient data are mission-critical for accelerating research and product development.
Sometimes data silos are legal requirements, and certain data assets cannot be joined for compliance reasons. Synthetic data versions of these datasets serve as drop-in placements and can interconnect the domain knowledge contained in otherwise separated data silos. In these cases, synthetic data products are the only option for data collaboration.
In other cases, we've seen organizations with a global presence use synthetic data generation for massive HR analytics projects, connecting employee datasets from all over the world in a way that is compliant with the strictest regulations, including GDPR.
The wide adoption of AI-enabled data democratization represents breakthrough moments in how data consumers access data and create value. The intelligence data contains should no longer be locked away in carefully guarded vaults but flowing freely between teams and organizations.
The benefits of data collaborations powered by synthetic data
Shareable synthetic data helps data owners who want to collaborate and share data in and out of organizations by reducing time-to-data and governance costs, enabling innovation, democratizing data, and increasing data literacy. Unlike legacy data anonymization, which reduces data utility. The reduction in time-to-data in itself is significant.
"According to our estimates, creating synthetic data products results in a 90%+ reduction in time-to-consumption in downstream use cases. Less new ideas are left on the cutting room floor, and more data is making an impact in the business.” says John Sullivan, Head of Customer Experience at MOSTLY AI.
MOSTLY AI's synthetic data platform was created with synthetic data products in mind - synthetic data can be shared directly from the platform together with the automatically generated quality assurance report.
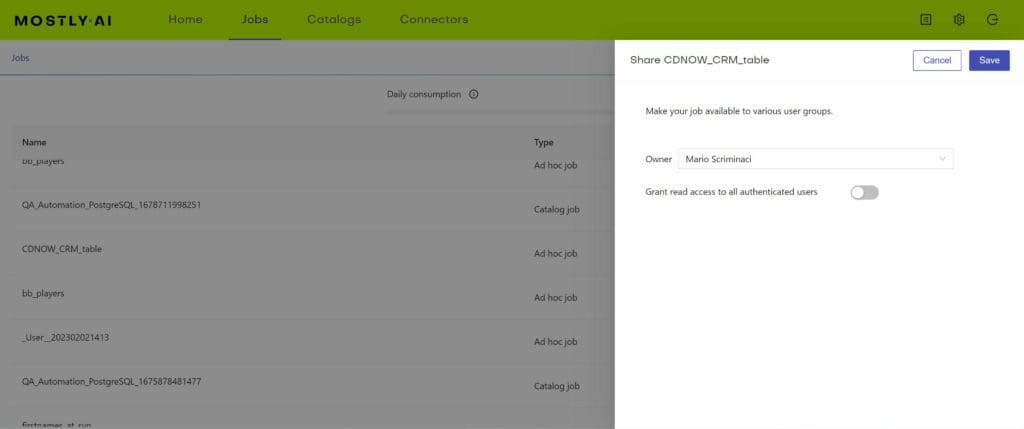
Data mesh vs. data fabric with synthetic data in mind
Mario Scriminaci, MOSTLY AI’s Chief Product Officer thinks, that the concept of the data mesh and data fabric is often perceived as antithetical.
“The difference between the two architectures is that the data mesh pushes for de-centralization, while the data fabric tries to aggregate all of the knowledge about metadata. In reality, they are not mutually exclusive. The concepts of the data mesh and the data fabric can be applied simultaneously in big organizations, where the complexity of data architecture calls for a harmonized view of data products. With the data consumption and data discovery initiatives, synthetic data generation will help centralize the knowledge of data and datasets (aka. the data fabric) and, at the same time, will also help customize datasets to domain-specific needs (aka. data mesh).”
In a data mesh architecture, data ownership and privacy are crucial considerations. Synthetic data generation techniques allow organizations to create realistic data that maintains privacy. It enables data collaboration between teams across organizations to produce and share synthetic data products with high utility.
Data mesh architectures promote the idea of domain-oriented, self-serve data teams. Synthetic data allows teams to experiment, develop, and test data pipelines and applications independently, fostering agility and making data democratization an everyday reality.
Synthetic data products also eliminate the need to replicate or move vast volumes of real data across systems, making it easier to scale and optimize data processing pipelines and enabling data collaboration at scale.
Smart data imputation with AI-generated synthetic data is superior to all other methods out there. Synthetic data generated with MOSTLY AI is highly representative, highly realistic, granular-level data that can be considered ‘as good as real’. While maintaining complete protection of each data subject's privacy, it can be openly processed, used, and shared among your peers. MOSTLY AI’s synthetic data serves various use cases and the initiatives that our customers have so far achieved, prove and demonstrate the value that our synthetic data platform has to offer.
To date, most of our customers' use cases centered around generating synthetic data for data sharing while maintaining privacy standards. However, we believe that there is more on offer for data consumers around the world. Poor-quality data is a problem for data scientists across all industries.
Real-world datasets have missing information for various reasons. This is one of the most common issues data professionals have to deal with. The latest version of MOSTLY AI's synthetic data generator introduces features that can be utilized by users to interact with their original dataset - the so-called 'data augmentation' features. Among those is our ‘Smart Imputation’ technique which can accurately recreate the original distribution while filling the gaps for the missing values. This is gold for analytical purposes and data exploration!
What is smart data imputation?
Data imputation is the process of replacing missing values in a dataset with non-missing values. This is of particular interest, if the analysis or the machine learning algorithm cannot handle missing values on its own, and would otherwise need to discard partially incomplete records.
Many real-world datasets have missing values. On the one hand, some of the missing values may exist as they may hold important information depending on the business. For instance, a missing value in the ‘Death Date’ column means that the customer is still alive or a missing value in the ‘Income’ column means that the customer is unemployed or under-aged. On the other hand, oftentimes the missing values are caused by an organization's inability to capture this information.
Thus, organizations look for methods to impute missing values for the latter case because these gaps in the data can result in several problems:
- Missing data occasionally causes results to be biased. This means that because your data came from a non-representative sample, your findings could not be directly applicable to situations outside of your study.
- Dataset distortion occurs when there is a great deal of missing data, which can change the distributions that people could see in real-world situations. Consequently, the numbers do not accurately reflect reality.
As a result, data scientists may employ rather simplistic methods to impute missing values which are likely to distort the overall value distribution of their dataset. These strategies include frequent category imputation, mean/median imputation, and arbitrary value imputation. Thoughtful consideration should be given to the fact that well-known machine learning libraries like scikit-learn have introduced data scientists to several univariate and multivariate imputation algorithms, including, respectively, "SimpleImputer" and "IterativeImputer."
Finally, the scikit-learn 'KNNImputer' class, which offers imputation for filling in missing data using the k-Nearest Neighbors approach, is a popular technique that has gained considerable attention recently.
MOSTLY AI’s smart imputation technique seeks to produce precise and accurate synthetic data so that it is obvious right away that the final product is of "better" quality than the original dataset. At this point, it is important to note that MOSTLY AI is not yet another tool that merely replaces a dataset's missing values. Instead, we give our customers the ability to create entirely new datasets free of any missing values. Go ahead and continue reading if this piques your curiosity so you may verify the findings for yourself.
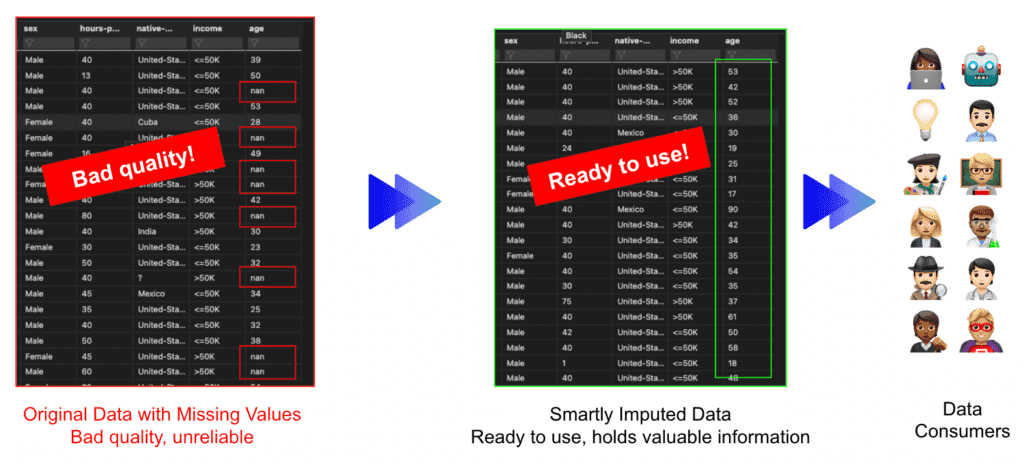
Evaluating smart imputation
We devise the below technique to compare the originally targeted distribution with the synthetic one to evaluate MOSTLY AI's smart imputation feature.
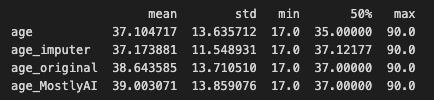
Starting with the well-known US-Census dataset, we use column ‘age’ as our targeted column. The dataset has approximately 50k records and includes 2 numerical variables and 9 categorical variables. The average age of the targeted column is 38.6 years, with a range of 17 to 90 years and a standard deviation of 13.7 years.
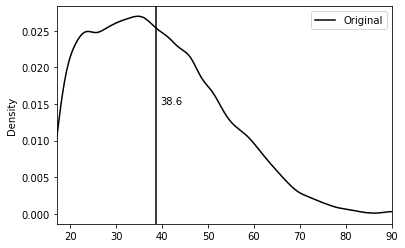
Our research begins by introducing semi-randomly some missing values into the US-Census dataset's "age" column. The goal is to compare the original distribution with the smartly imputed distribution and see whether we can correctly recover the original one.
We applied the following logic to introduce missing values in the original dataset, to artificially bias the non-missing values towards younger age segments. The age attribute was randomly set to missing for:
- 10% of all records
- 60% of records, whose education level was either ‘Doctorate', 'Prof-school' or ‘Masters’
- 60% of records, whose marital status was either ‘Widowed’ or 'Divorced'
- 60% of records, whose occupation level was set to ‘Exec-managerial’
It's important to note that by doing this, the algorithm won't be able to find any patterns or rules on where the missing values are located.
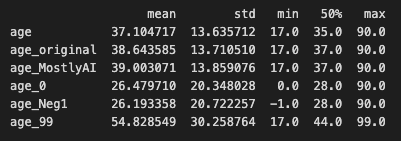
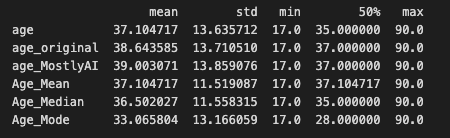
As a result, the 'age' column now has missing numbers that appear to be missing semi-randomly. The column's remaining non-missing values are therefore skewed in favor of younger people:
- Original age mean: 38.6
- Original age mean with missing values: 37.2
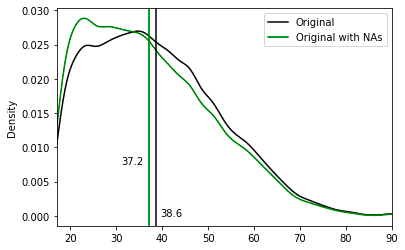
As a next step, we synthesized and smartly imputed the US-Census dataset with the semi-random missing values on the "age" column using the MOSTLY AI synthetic data platform.
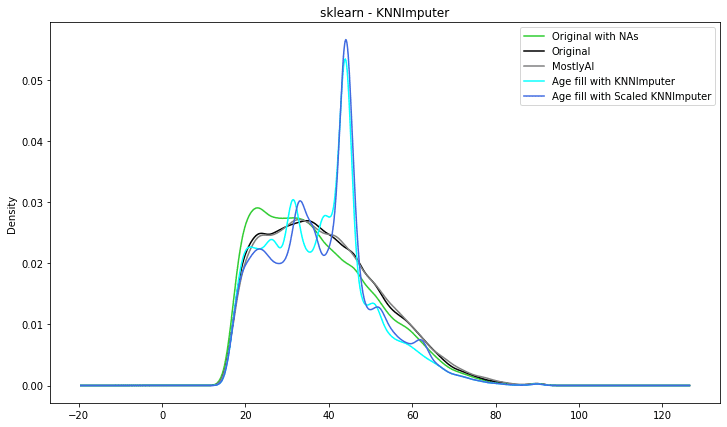
We carried out two generations of synthetic data. The first one is for generating synthetic data without enabling imputation and as expected the synthetic dataset matches the distribution of the data used to train the model (Synthetic with NAs - light green). The second one is for generating synthetic data enabling MOSTLY AI’s Smart imputation feature for the ‘age’ column. As we can see, the smartly imputed synthetic data perfectly recovers the original distribution!
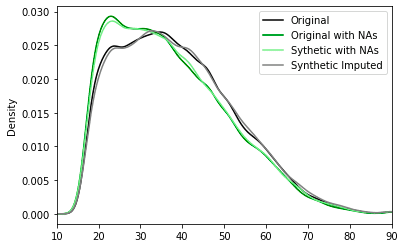
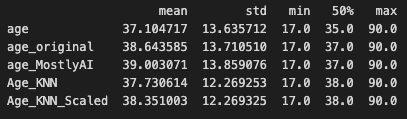
After adding the missing values to the original dataset, we started with an average age of 37.2 and used the "Smart imputation" technique to reconstruct the "age" column. The initial distribution of the US-Census data, which had an average age of 38.6, is accurately recovered in the reconstructed column, which now has an average age of 39.
These results are great for analytical purposes. Data scientists now have access to a dataset that allows them to operate without being hindered by missing values. Now let's see how the synthetic data generation method compares to other data imputation methods.
Data imputation methods: a comparison
Below we are describing 6 of the main imputation techniques for numerical variables and we are going to compare the results with our Smart Imputation algorithm. For each technique below we are presenting a general summary statistics of the ‘age’ distribution as well as a visual representation of the results against MOSTLY AI’s results.
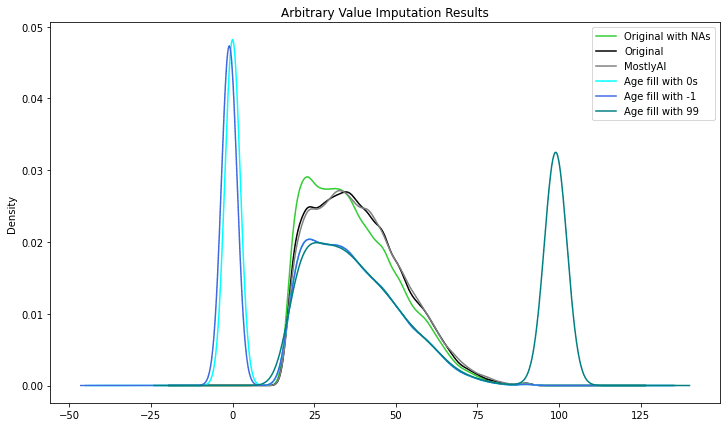
Arbitrary value data imputation
Arbitrary value imputation is a type of data imputation technique used in machine learning to fill in missing values in datasets. It involves replacing missing values with a specified arbitrary value, such as 0, 99, 999, or negative values. Instead of imputing the numbers using statistical averages or other methods, the goal is to flag the values.
This strategy is quite simple to execute, but it has a number of disadvantages. For starters, if the arbitrary number utilized is not indicative of the underlying data, it can inject bias into the dataset. For example, if the mean is used to fill in missing values in a dataset with outliers or extreme values, the imputed values may not accurately reflect the underlying distribution of the data.
Using an arbitrary value can limit dataset variability, making it more difficult for machine learning algorithms to find meaningful patterns in the data. As a result, forecast accuracy and model performance may suffer.
As you can see, the variable was given new peaks, drastically altering the initial distribution.
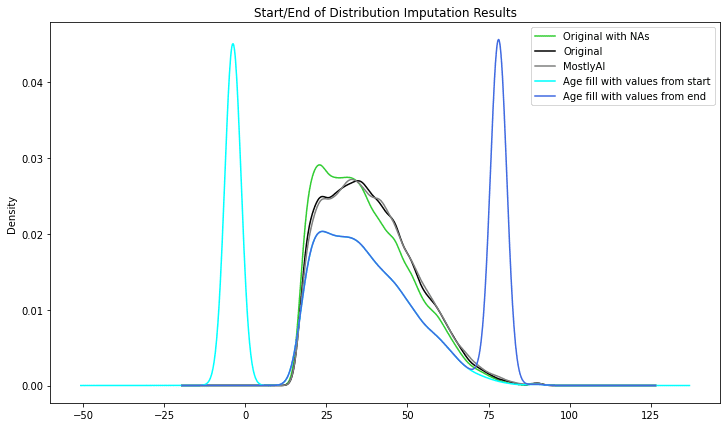
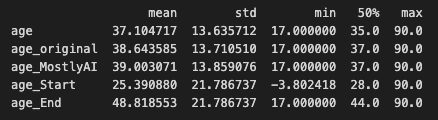
Start/End of Distribution data imputation
Start/End of Distribution data imputation is a form of data imputation technique used to fill in missing values in datasets. It involves replacing missing values with values at the beginning or end of the distribution of non-missing values in the dataset.
If the missing values are numeric, for example, the procedure involves replacing the missing values with the lowest or maximum value of the dataset's non-missing values. If the missing values are categorical, the procedure involves filling in the gaps with the most often occurring category (i.e., the mode).
Similar to the previous technique, as an advantage, is a simple technique to implement and our ML models could capture the significance of any missing values. The main drawback is that we might end up with a distorted dataset as the mean and variance of distribution might change significantly.
Similar to the previous technique, the variable was given new peaks, drastically altering the initial distribution.
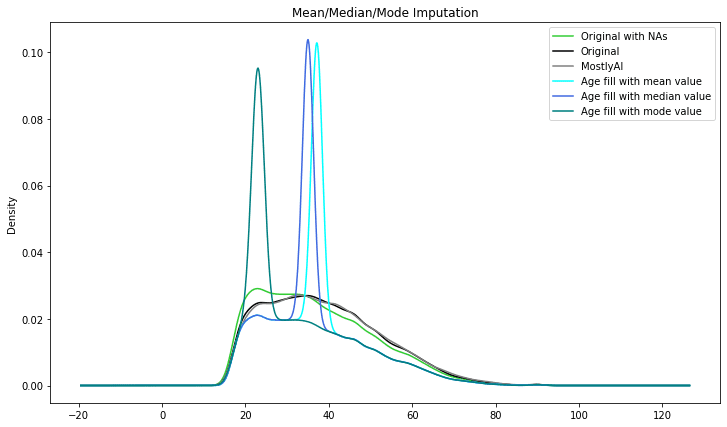
Mean/Median/Mode Imputation
Mean/Median/Mode imputation is probably the most popular data imputation method, at least among beginners. The Mean/Median/Mode data imputation method tries to impute missing numbers using statistical averages.
Mean data imputation involves filling the missing values with the mean of the non-missing values in the dataset. Median imputation involves filling the missing values with the median of the non-missing values in the dataset. Mode imputation involves filling the missing values with the mode (i.e., the most frequently occurring value) of the non-missing values in the dataset.
These techniques are straightforward to implement and beneficial when dealing with missing values in small datasets or datasets with a simple structure. However, if the mean, median, or mode is not indicative of the underlying data, they can add bias into the dataset.
The results start looking better than the previous techniques, however as can be seen the imputed distributions are still distorted.
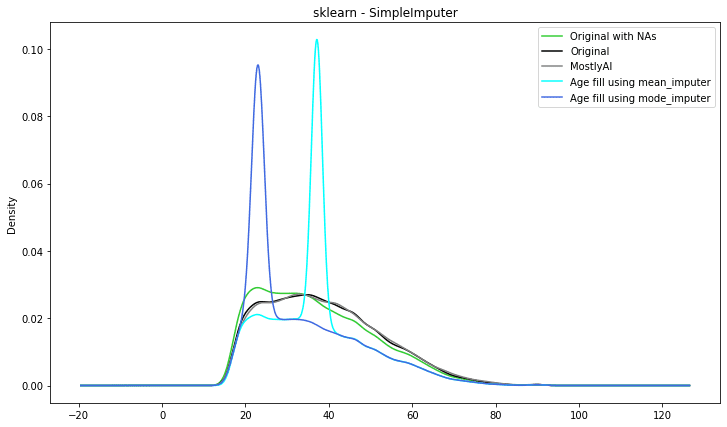
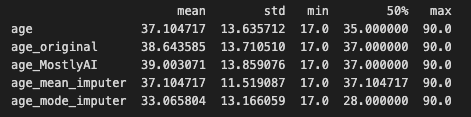
Scikitlearn - SimpleImputer data imputation
Scikit-learn is a well-known Python machine learning library. The SimpleImputer class in one of its modules, sklearn.impute, provides a simple and efficient technique to impute missing values in datasets.
The SimpleImputer class can be used to fill in missing data using several methodologies such as mean, median, mode, or a constant value. It can also be used to fill in missing values by selecting the most common value along each column or row, depending on the axis. SimpleImputer is a univariate imputation algorithm that comes out of the box with the sci-kit learn library.
The results below are similar to the results of the previous technique:
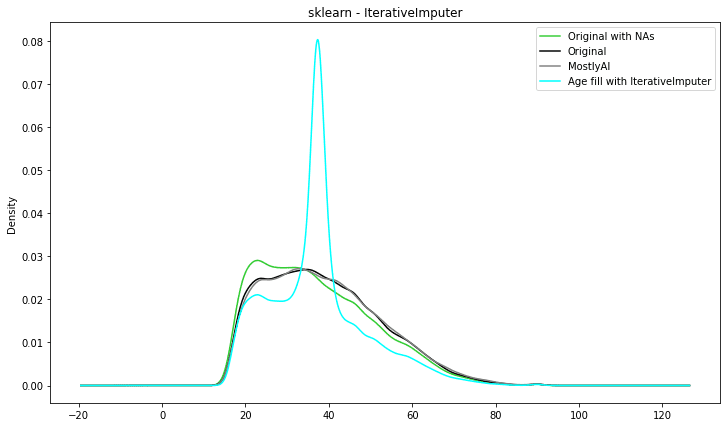
Scikitlearn - IterativeImputer data imputation
Another class in the Scikit-learn's sklearn.impute module that may be used to impute missing values in datasets is IterativeImputer. IterativeImputer, as opposed to SimpleImputer, uses a model-based imputation strategy to impute missing values by modelling the link between variables.
IterativeImputer estimates missing values using a machine learning model. A variety of models are supported by the class, including linear regression, Bayesian Ridge regression, k-nearest neighbours regression, decision trees, and random forests.
Entering the more sophisticated techniques you can see that the imputed distribution is getting closer to the original ‘age’ distribution.
Scikitlearn - KNNImputer data imputation
Let’s look at something a little more complex. K-Nearest Neighbors, or KNN, is a straightforward method that bases predictions on a specified number of nearest neighbours. It determines the separations between each instance in the dataset and the instance you want to classify. Here, classification refers to imputation.
It is simple to implement and optimize. In comparison to the other methods employed so far, it is also a little bit ‘smarter’. Unfortunately, it is prone to outliers. It can be used only on numerical variables hence only those used from the US-census dataset to produce the results below.
The summary statistics look very close to the original distribution. However, the visual representation is not that good. The imputed distribution is getting closer to the original one and visually it seems that KNNImputer produces the best results so far.
Comparison of data imputation methods: conclusion
Six different techniques were used to impute the US-census ‘age’ column. Starting with the simplest ones we have seen that the distributions are distorted and the utility of the new dataset drops significantly. Moving to the more advanced methodologies, the imputed distributions are starting to look like the original ones but are still not perfect.
We have plotted all the imputed distributions against the original as well as the distribution generated by MOSTLY AI’s Smart Imputation feature. We can clearly conclude that AI-powered synthetic data imputation captures the original distribution better.
We at MOSTLY AI are excited about the potential that ‘Smart Imputation’ and the rest of our 'Data Augmentation' and 'Data Diversity' features have to offer to our customers. More specifically, we would like to see more organizations using synthetic data across industries and to reduce the time-consuming task of dealing with missing data - time that data professionals can use to produce valuable insights for their organizations.
We are eager to explore these paths further with our customers to assist their ML/AI endeavours, at a fraction of the time and expense, since the explorations in this blog post have shown the potential to support such a scenario. If you are currently facing the same struggle of dealing with missing values in your data, check out MOSTLY AI's synthetic data generator to try Smart imputation on your own.
TL;DR We present a reproducible case study on synthesizing large-scale population data to gain granular-level insights without compromising on privacy. Accordingly, MOSTLY AI’s unparalleled accuracy combined with its ease-of-use allows any organization to generate highly realistic synthetic replicas of their own customer base. These allow the privacy-safe utilization of data assets - across teams, across borders, across corporate boundaries. See also here for a slideset version of this blog post.
Intro
The UCI Adult dataset is a widely used resource for machine learning and data analysis. It contains detailed information on over 48,000 individuals, including their age, education, income, and other demographic characteristics. The dataset is often used to test and develop algorithms for predicting income levels based on these various factors. Over the past years it has also become the go-to standard to test-drive, showcase and benchmark synthetic data solutions. And any new user of our highly popular free version is guided through the synthetization of that very same dataset as part of their onboarding tutorial. With just a few clicks, and within less than a minute, a highly realistic, statistically representative, and yet truly novel synthetic replica is being generated [Make sure to give it a try!].
But just as AI advances, we also need to advance the datasets it’s being tested on. For years MNIST, a collection of hand-written digits, served as the go-to dataset to test-drive image recognition algorithms, but by now has become “too easy” of a task. Accordingly, it’s also high time to level up the game for structured data synthesis, and publicly showcase its capabilities on bigger, wider and more complex datasets. This shall allow for a more realistic demonstration of capabilities, as any of the real-word datasets of our customers, is orders of magnitudes richer than the commonly demo-ed “toy datasets”. Thus, let’s use the handy Python package folktables to extract a significantly larger and also more recent version of the UCI Adult dataset directly from the US Census Bureau. For this blog post we pulled records from the 2018 American community survey (ACS) on 1,476,217 working individuals of age 17 or older, together with 4 numerical and 28 categorical attributes.
Synthesize data
No matter whether your dataset is small or large in size, using MOSTLY AI to synthesize it, is always the same easy 3-step process. You first upload or connect to your dataset, you then configure and launch the synthetization, and once the job is completed, you then access and freely use your generated synthetic data. Yes, it's that easy!
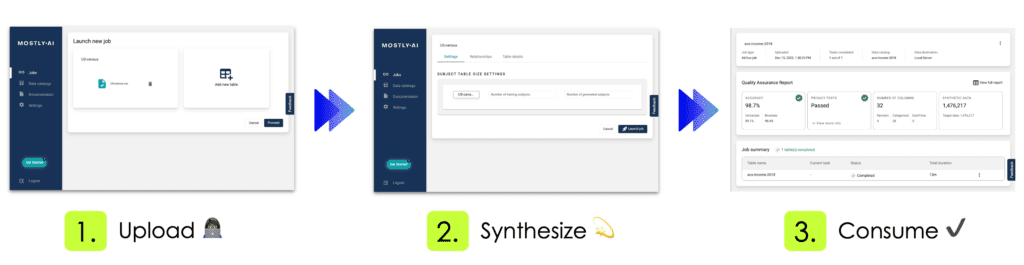
Using our free version, the complete end-to-end process of our introduced dataset takes less than 12 minutes. This includes the fully automated steps of data analysis, data encoding, model training, synthetic data generation as well as the creation of the quality assurance report. The resulting 1,476,217 synthetic records are shown to be statistically representative, highly realistic, truly anonymous, and yet at granular level. These records therefore serve as a safe drop-in alternative to the original data, and allow for any type of data exploration, analysis as well as machine learning task. All without compromising the privacy of any individual.
Explore data
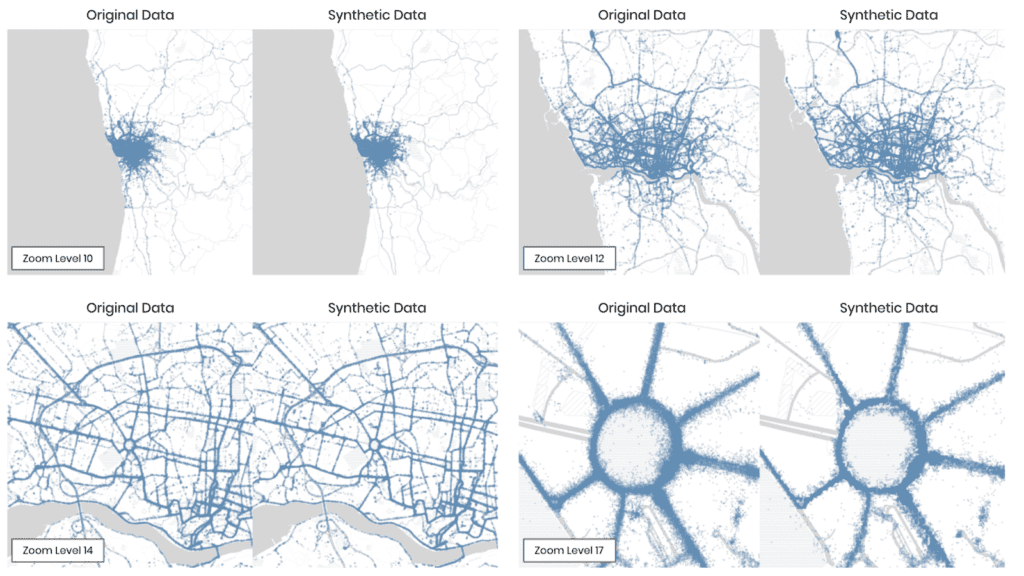
Let’s start out by analyzing MOSTLY AI’s generated synthetic data with Tableau, a popular data visualization platform. Note, that deriving statistical insights should not be understood as an exercise in reporting metrics with excess precision. Deriving statistical insights is much rather the art and science of exploring and spotting relationships and trends within the data, that were previously unknown. And this ability, to explore data in any way needed, is the major benefit of synthetic data when compared to any other privacy-enhancing technology. As a data consumer one is NOT restricted to pre-selected subsets of data attributes, to pre-defined numeric buckets, or to pre-calculated data aggregates, that all severely limit the scope of an analysis. As a data consumer one can freely combine, transform and tabulate any dimension and any measure.
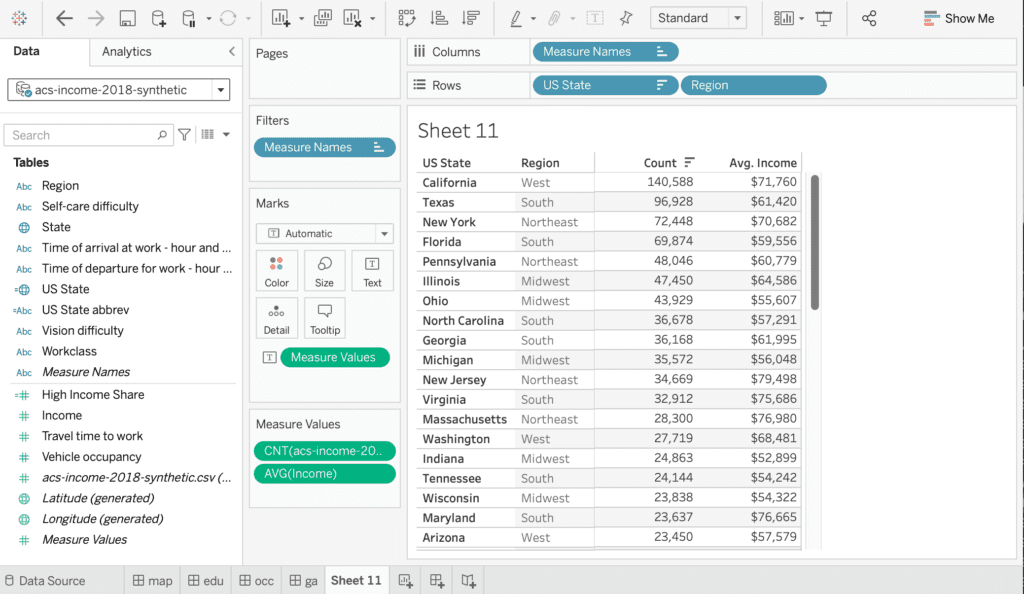
One of the 32 captured attributes within the dataset is information about the surveyed state, representing geographical information, that can be nicely visualized on a map. Figure 3 shows the share of respondents, with an annual income of $50,000 or more, displayed as a choropleth map. The darker the color, the higher the share of high income earners. And one can immediately see, side-by-side, that the very same patterns emerge. States on the west, respectively on the north east coast exhibit significantly higher incomes than other states.
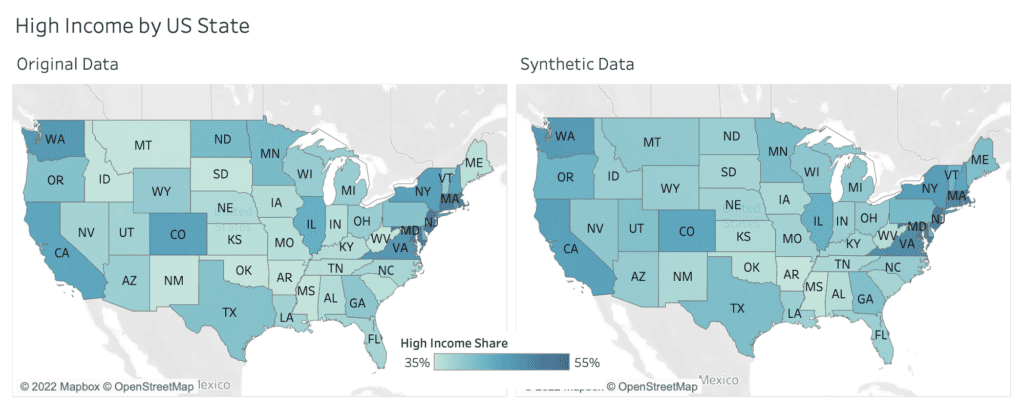
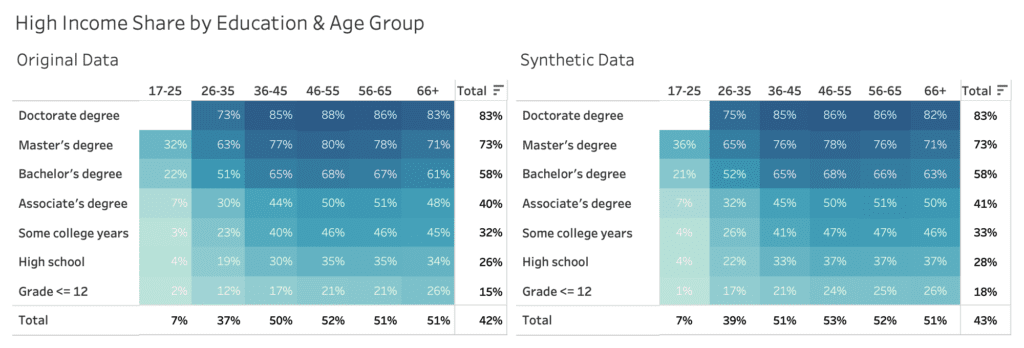
Figure 4 exhibits the share of high income earners across education level and age group, and displays similarly strong, yet consistent patterns. The higher the educational level, the higher the likelihood to earn more than $50k per year. And in addition, there is a significant difference between people below 25 years, people between 26 and 35 years, as well as people of 36 years of age and older.
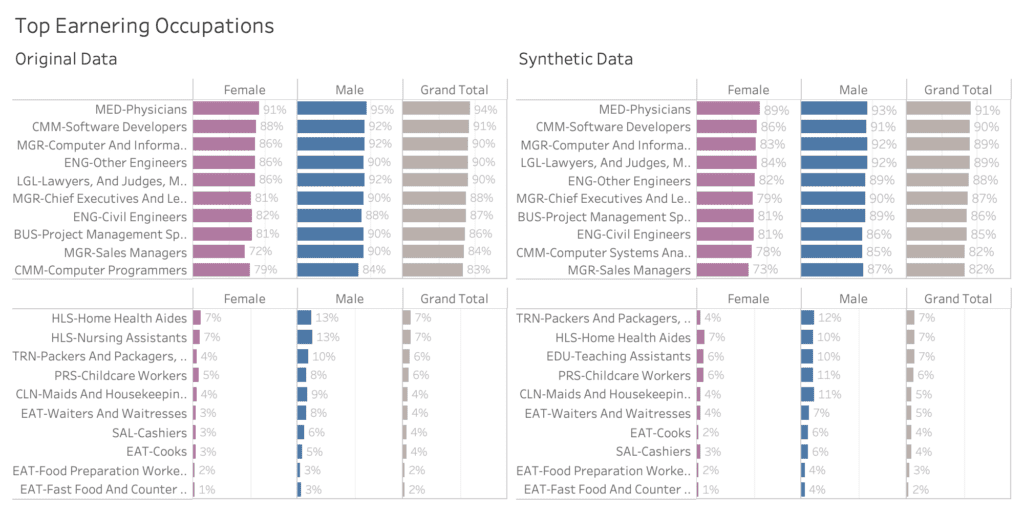
Let’s next explore income across genders, and across occupation, which is an attribute consisting of over 500 (!) distinct values. Most other synthesization solutions struggle with capturing the signals for high cardinality features like these. Figure 5 shows side-by-side the large income gap across occupation, discriminating between high income jobs like physicians and software developers on the one end of the spectrum, and cashiers and fast food workers on the other end. Plus, it also shows a consistent gender pay gap across all occupation. Thus, the analysis shows that men are consistently more likely to earn a high income than women, even when controlling for the type of occupation. Synthetic data can play a pivotal role in uncovering such types of systematic injustices, that are currently locked up due to the private nature of the underlying datasets.
The complete analytical workbook, and each of the presented interactive visualizations, can be accessed through this link hosted on Tableau Public.
Build models
Visual analytics, as shown in the previous section, is an excellent and essential mean to quickly gain a deeper understanding of a dataset and its inherent patterns. However, at the same time it also requires some level of caution, in order to avoid misinterpreting spurious relations by overlooking confounding factors. Machine learning models, that are trained to predict a specific target attribute of interest based on a wide range of other variables, help to mitigate this problem. These models can account for the combined effect of attributes, and with that can report the net impact of individual attributes.
Let’s therefore train a state-of-the-art ML model on top of the synthetic data 1) to benchmark its overall predictive performance with respect to real data, and 2) to identify the key drivers, and their net effect on the attribute of interest, in our case the likelihood of a respondent earning a high income salary. The model of our choice is LightGBM, a gradient boosting machine learning algorithm, that is fast to train and evaluate, even for larger datasets. In our case, training the model on over 1 million records for 31 attributes to predict high income takes less than 1 minute on a commodity laptop.
In order to assess the model’s predictive accuracy on a true holdout dataset, we need to split the original dataset into a training and a holdout set. We randomly assign 80% of the original records to the former, and the remaining 20% to the latter. The synthetic dataset is generated based on the 80% training set. The LightGBM model is then trained on the synthetic data, and finally evaluated on the 20% holdout data, that wasn’t being accessed before. Similarly, the same model is being trained on the original training data, and evaluated on the same holdout as well. This serves us as a very strong benchmark for the ML performance of synthetic data. See figure 6 for a schematic representation of the setup. The holdout, the training as well as a synthetic dataset can be accessed via our Github repository for popular public datasets. There you will also find a corresponding Jupyter notebook that, in combination with our free version, allows anyone to easily reproduce all results from this blog post.
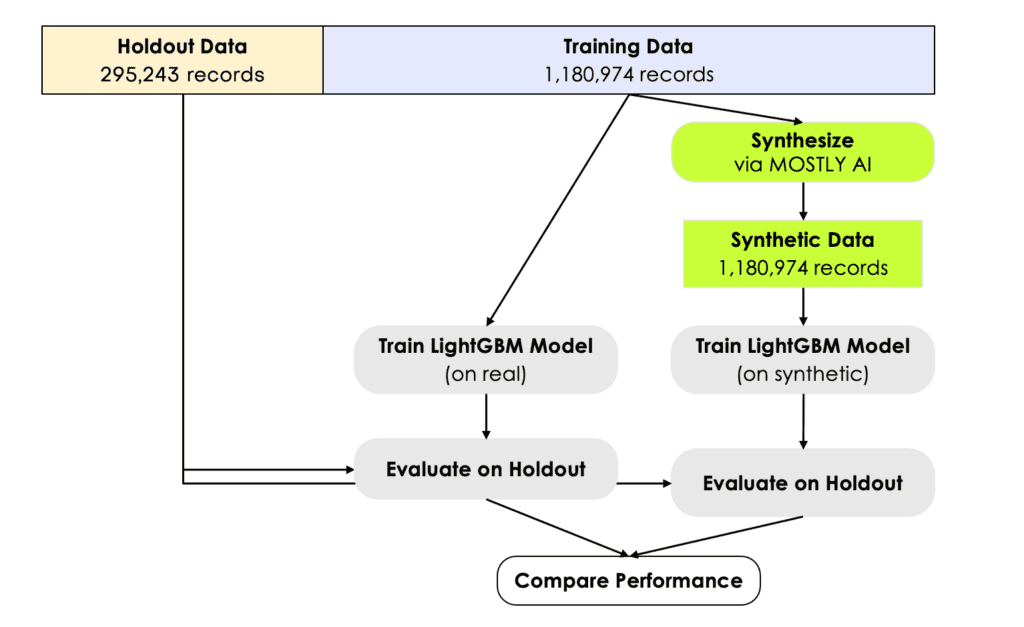
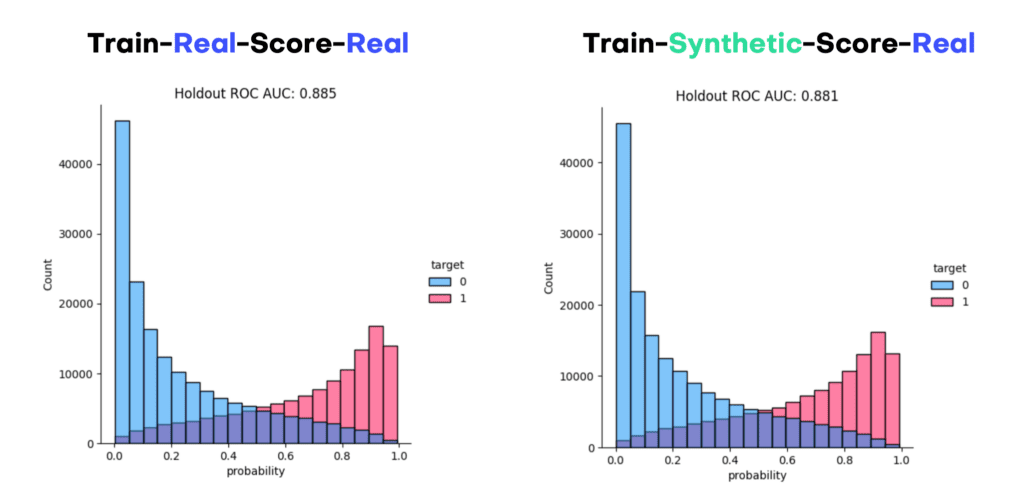
Figure 7 visualizes the distribution of the predicted scores for each of the models, split by income group. We can see that the model can discriminate well between these two groups, and assigns higher probabilities to high income earners, and vice versa. This can be also quantified via the ROC Area-Under-Curve measure, which reflects the probability of the model to correctly recognize the high income earner among a pair of two subjects. We can see that training a state-of-the-art ML model on synthetic data yields identical results, both in terms of scores as well as accuracy. The model trained on synthetic data, with an AUC of 0.881, is on-par with the model trained on real data (AUC: 0.885). This is a particularly strong and robust result, considering that we’ve used nearly 300,000 holdout records for the evaluation.
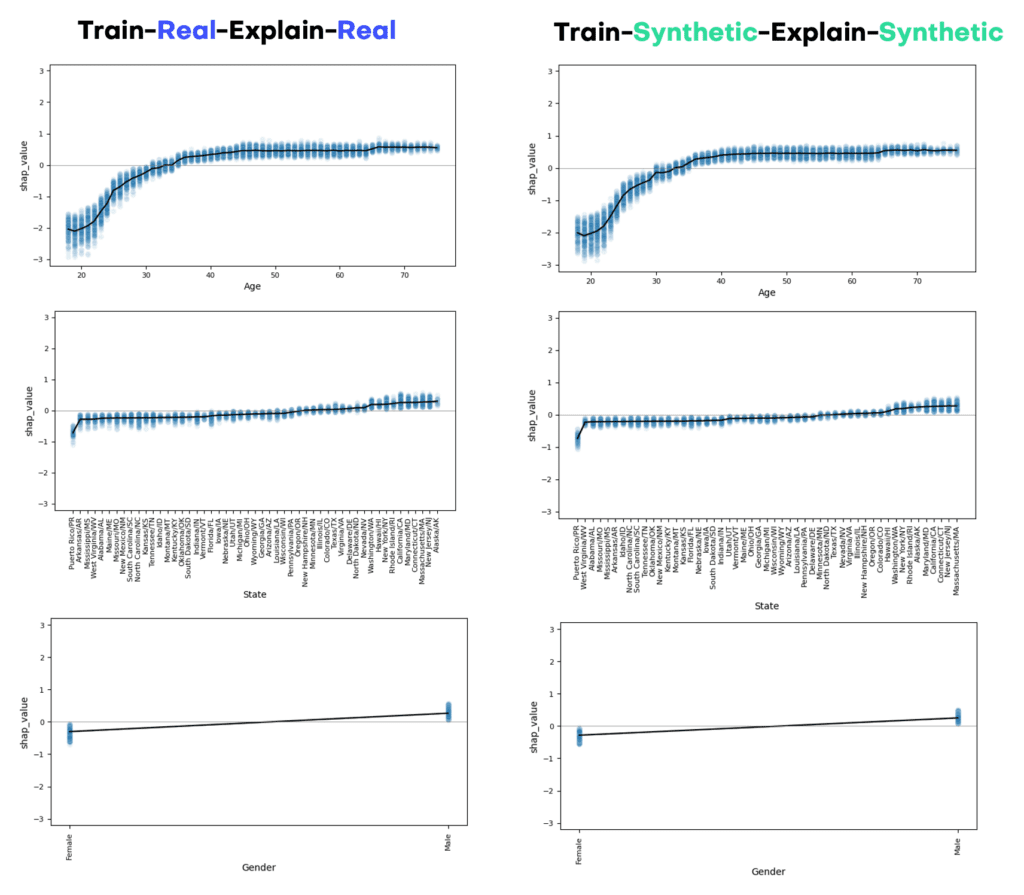
In order to explore the trained models further, we turn towards SHAP, a highly popular framework to explain ML models. Below we show the SHAP summary plot side-by-side, which already reveals the key attributes for predicting income. As one can see, occupation, age, and education are the top 3 drivers that allow to determine whether a person earns a high income or not. After that it is the information on insurance, gender, state and marital status. Further features contribute less to the model predictions. And note again, that these findings are identical for real and for synthetic data, with the key advantage that none of the private information is getting exposed while using the latter.

Aside from the overall impact of an attribute with respect to the predicted target, it is of great interest to study the value-dependent net effect of each of those attributes in details. These can be visualized via SHAP dependency plots, and show for each attribute the shift in predictions given their attribute value. Figure 9 displays the corresponding plots for age, state as well as gender. The x-axes show attribute values, and the y-axes the shift in predicted score. Thus, it is for example very unlikely for a young person below 25 years to be in the high income class, no matter what occupation, education or other features that person has. But once a person has reached 40 years, any further age increase does not change his or her likelihood to earn more. On the other hand, we can also see that, all other things being equal, male respondents are significantly more likely to earn a high income than their female counterparts. I.e., even for the same job, the same location, the same age, the same education, etc., women systematically earn less than men.
The power (and beauty) of synthetic data is the ability to drill down to granular level at any time. So, even though the generated subjects do not exist in real life, but “merely” are statistically representative, they do allow to reason about machine learning models by studying their impact on individual samples. This is a key enabler for involving a broader community of stakeholders (within and across organizations) in a much needed debate on machine learning models. Everyone - engineers, designers, lawyers, managers, customers all alike - is capable to argue a case based on representative samples. Yet, without access to samples, any discussion remains abstract. Figure 10 shows the SHAP values for our predictive income model, that has been trained on synthetic data, then evaluated and explained on synthetic, yet realistic samples. The randomly sampled case is for a 50-year old married woman from New Hampshire, who has a Master’s Degree and works in Education. The model assesses her to have an annual income of more than $50k with 85% likelihood, with her combination of education, occupation and age contribute the most for this assessment. The same type of analysis can be easily done not just for one sample, but for any of the millions of generated synthetic samples, and thus allows to test in detail the behavior as well as the robustness of the developed model, without exposing the privacy of any individuals.

Summary
It’s the dawn of a new era. Generative AI is being recognized for its immense power to inform us all, humans and algorithms alike. And high-quality structured synthetic data, as delivered by MOSTLY AI, is key to overcome the privacy hurdles of data access. It’s key to help us see and understand the world as it is, as well as it could be.
In this blog post we’ve provided a new, publicly reproducible benchmark for state-of-the-art structured synthetic data at scale. We’ve shown how MOSTLY AI allows to easily synthesize large-scale population data, and how the generated data reliably yields identical statistical insights without compromising on privacy. It’s this level of accuracy, its reliability, and last but not least its ease of use, that makes MOSTLY AI stand out on the market. But don’t take our word for it. Go ahead, and start generating synthetic data today!
Learn how to generate high-quality synthetic datasets from real data samples without coding or credit cards in your pocket. Here is everything you need to know to get started.
In this blogpost you will learn:
- What do you need to generate synthetic data?
- What is a data sample?
- What are data subjects?
- What is a subject table?
- How and when to synthesize a single subject table?
- What is not a subject table?
- How to launch your first synthetic data generation?
- How and when to synthesize data in two tables?
- What are linked tables?
- How to create linked tables?
- What is the perfect setup for synthetic data generation?
- How to connect subject and linked tables for synthesization?
- What types of synthetic data can you synthesize?
- How to optimize synthetic data generation for speed or accuracy?
- What are the most common synthetic data use cases?
- How to get expert help with synthetic data generation?
What do you need to generate synthetic data?
If you want to know how to generate synthetic data, the good news is, that you need absolutely no coding knowledge to be able to synthesize datasets on MOSTLY AI’s synthetic data platform. What is even better news is that you can have access to the world’s best quality synthetic data generation for free, generating up to 100K rows daily. Not even a credit card is required, only a suitable sample dataset.
First, you need to register a free synthetic data generation account using your email address. Second, you need a suitable data sample. If you want to know how to generate synthetic data using an AI-powered tool, like MOSTLY AI, you need to know how to prepare your sample dataset, that the AI algorithm will learn from. We'll tell you all about what makes a dataset ready for synthesization in this blogpost.
When do you need a synthetic data generation tool?
Generating synthetic data based on real data makes sense in a number of different use cases and data protection is only one of them. Thanks to how the process of synthetic data generation works, you can use an AI-powered synthetic data generator to create bigger, smaller or more balanced, yet realistic versions of your original data. It’s not rocket science. It’s better than that - it’s data science automated.
When choosing a synthetic data generation tool, you should take two very important benchmarks into consideration: accuracy and privacy. Some synthetic data generators are better than others, but all synthetic data should be quality assured and MOSTLY AI’s platform generates an automatic privacy and accuracy report for each synthetic data set. What’s more, MOSTLY AI’s synthetic data is better quality than open source synthetic data.
If you know what you are doing, it's really easy to generate realistic and privacy-safe synthetic data alternatives for your structured datasets. MOSTLY AI's synthetic data platform offers a user interface that is easy to navigate and requires absolutely no coding. All you need is sample data and a good understanding of the building blocks of synthetic data generation. Here is what you need to understand how to generate synthetic data.
Generate synthetic data straight from your browser
What is a data sample?
Generative tabular data is based on real data samples. In order to create AI-generated synthetic data, you need to provide a data sample of your original data to the synthetic data generator to learn its statistical properties, like correlations, distributions and hidden patterns.
Ideally your sample data set should contain at least 5,000 data subjects (= rows of data). If you don't have that much data that doesn't mean you shouldn’t try - go ahead and see what happens. But don't be too disappointed if the achieved data quality is not satisfactory. Automatic privacy protection mechanisms are in place to protect your data subjects, so you won’t end up with something potentially dangerous in any case.
What are data subjects?
The data subject is the person or entity whose identity you want to protect. Before considering synthetic data generation, always ask yourself whose privacy you want to protect. Do you want to protect the anonymity of the customers in your webshop? Or the employees in your company? Think about whose data is included in the data samples you will be using for synthetic data generation. They or those will be your data subjects.
The first step of privacy protection is to clearly define the protected entity. Before starting the synthetic data generation process, make sure you know who or what the protected entities of a given synthesization are.
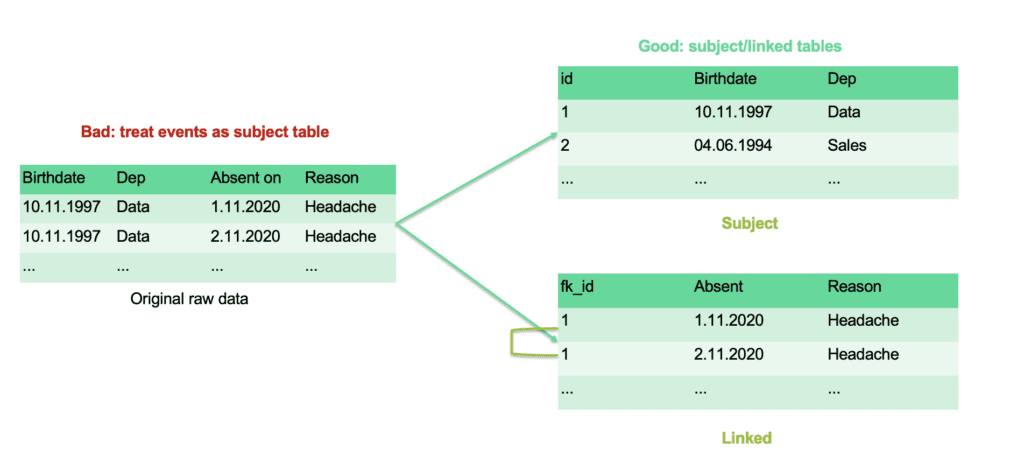
What is a subject table?
The data subjects are defined in the subject table. The subject table has one very crucial requirement: one row is one data subject. All the information which belongs to a single subject - e.g. a customer, or an employee - needs to be contained in the row that belongs to the specific data subject. In the most basic data synthesization process, there is only one table, the subject table.
This is called a single-table synthesization and is commonly used to quickly and efficiently anonymize datasets describing certain populations or entities. In contrast with old data anonymization techniques like data masking, aggregation or randomization, the utility of your data will not be affected by the synthesization.
How and when to synthesize a single subject table?
Synthesizing a single subject table is the easiest and fastest way to generate highly realistic and privacy safe synthetic datasets. If you are new to synthetic data generation, a single table should be the first thing you try.
If you want to synthesize a single subject table, your original or sample table needs to meet the following criteria:
- Each subject is a distinct, real-world entity. A customer, a patient, an employee, or any other real entity.
- Each row describes only one subject.
- Each row can be treated independently - the content of one row does not affect the content of other rows. In other words, there are no dependencies between the rows.
- When synthesizing single tables, the order of the rows will not be preserved throughout the synthesization process. For example, alphabetical order will not be maintained. However, you can re-introduce such ordering in post-processing.
Information entered into the subject table should not be time-dependent. Time-series data should be handled in two or more tables, called linked tables, which we will talk about later.
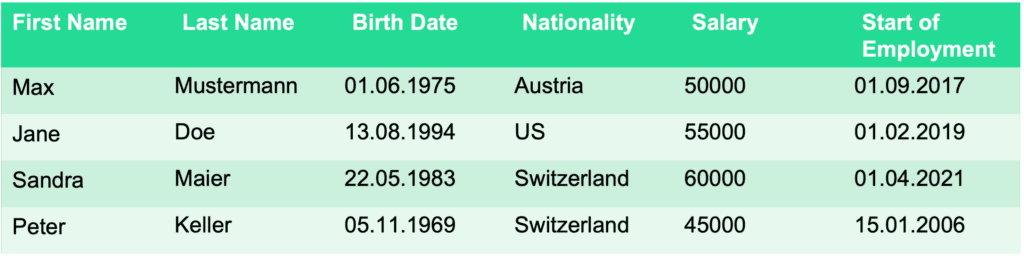
What is not a subject table?
So, how do you spot it if your table that you would like to synthesize is not a subject table? If you see the same data subjects in the table twice, in different rows, it’s fair to say that the table you have cannot be a subject table as it is. In the example below, you can see a company’s records of sick leaves. Since more than one row belongs to the same person, this table would not work as a subject table.
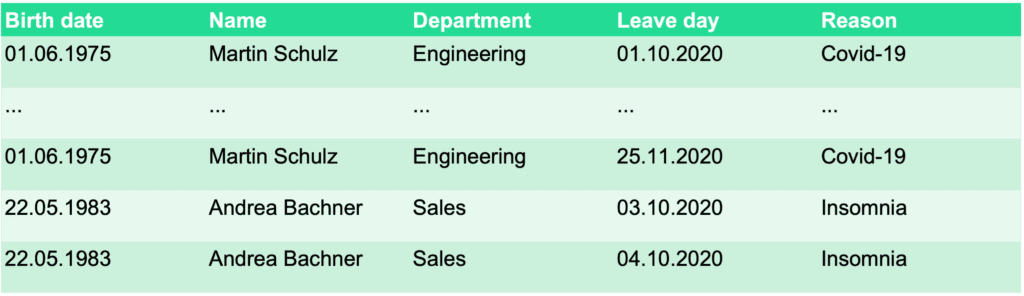
There are some other examples when a table cannot be considered a subject table. For example, when the rows contain overlapping groups, the table cannot be used as a subject table, because the requirement of independent rows is not met.
Another example of datasets not suitable for single-table synthesization are datasets that contain behavioral or time-series data. Here the different rows come with time dependencies. Tables containing data about events need to be synthesized in a two-table set up.
If your dataset is not suitable as a subject table "out of the box" you will need to perform some pre-processing of the data to make it suitable for data synthesization.
It’s time to launch your first synthetic data generation job!
How to generate synthetic data step by step
The good news is, that you need absolutely no coding knowledge to be able to synthesize datasets on MOSTLY AI’s synthetic data platform. What is even better news is that you can have access to the world’s best quality synthetic data generation for free, generating up to 100K rows daily. Not even a credit card is required, only a suitable subject table. First, you need to register a free synthetic data generation account using your email address.
Step 1 - Upload your subject table
Once you are inside MOSTLY AI’s synthetic data platform, you can upload your subject table. Click on Jobs, then on Launch a new job. Your subject table needs to be in CSV or Parquet format. We recommend using Parquet files.
Feel free to upload your own dataset - it will be automatically deleted once the synthetic data generation has taken place. MOSTLY AI’s synthetic data platform runs in a secure cloud environment and your data is kept safe by the strictest data protection laws and policies on the globe, since we are a company with roots in the EU.
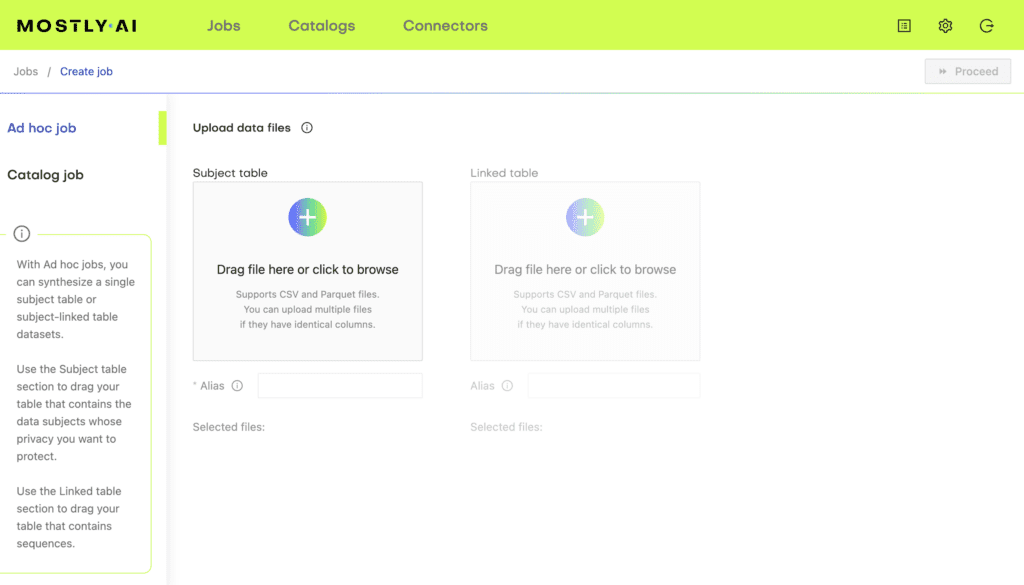
Step 2 - Check column types
Once you upload your subject table, it’s time to check your table’s columns under the Table details tab. MOSTLY AI’s synthetic data platform automatically identifies supported column types. However, you might want to change these from what was automatically detected. Your columns can be:
- Numerical - any number with up to eight digits after the decimal point
- Datetime - with hours, minutes, seconds or milliseconds if available, but a simple date format with YYYY-MM-DD also works
- Categorical - with defined categories, such as gender, marital status, language or educational level
There are other column types you can use too, for example, text or location coordinates, but these are the main column types automatically detected by the synthetic data generator.
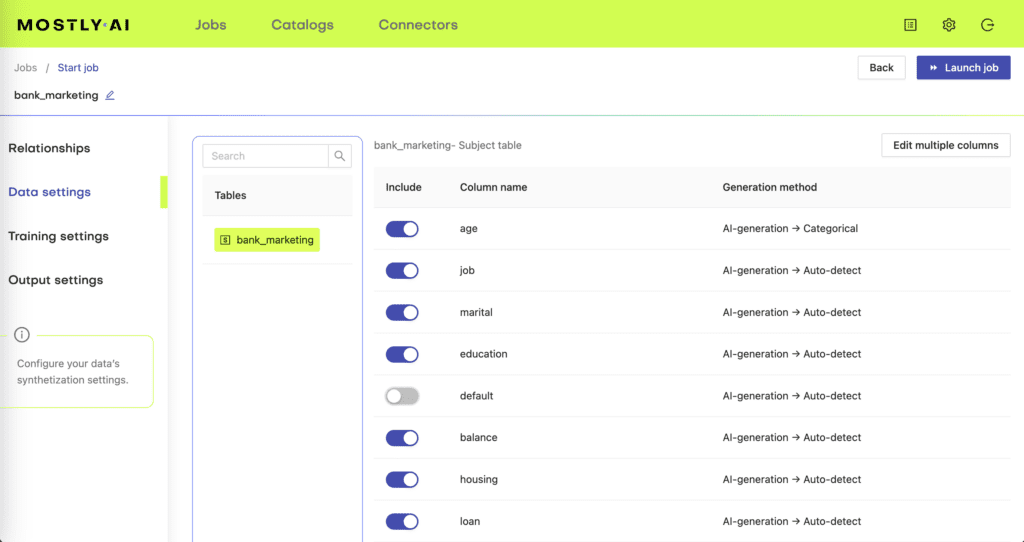
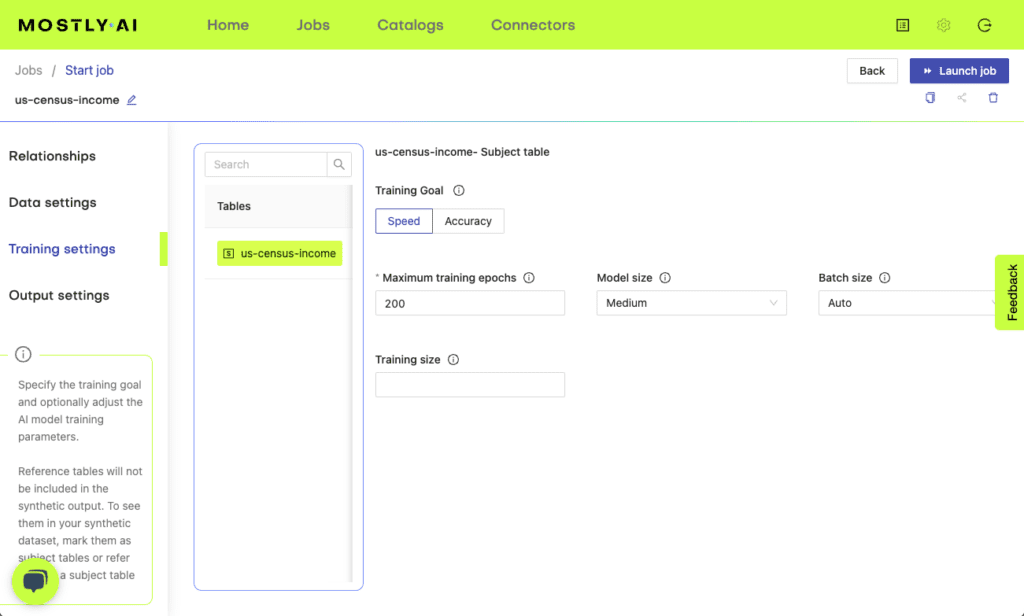
Step 3 - Train and generate
Under the Settings tabs you have the option to change how the synthesization is done. You can specify how many data subjects you want the synthetic data generator to learn from and how many you want to generate. Changing these would make sense for different use cases.
For example, if you want to generate synthetic data for software testing, you might choose to downsample your original dataset into smaller, more manageable chunks. You can do this by entering a smaller number of generated subjects under Output settings than what is in your original subject tables.
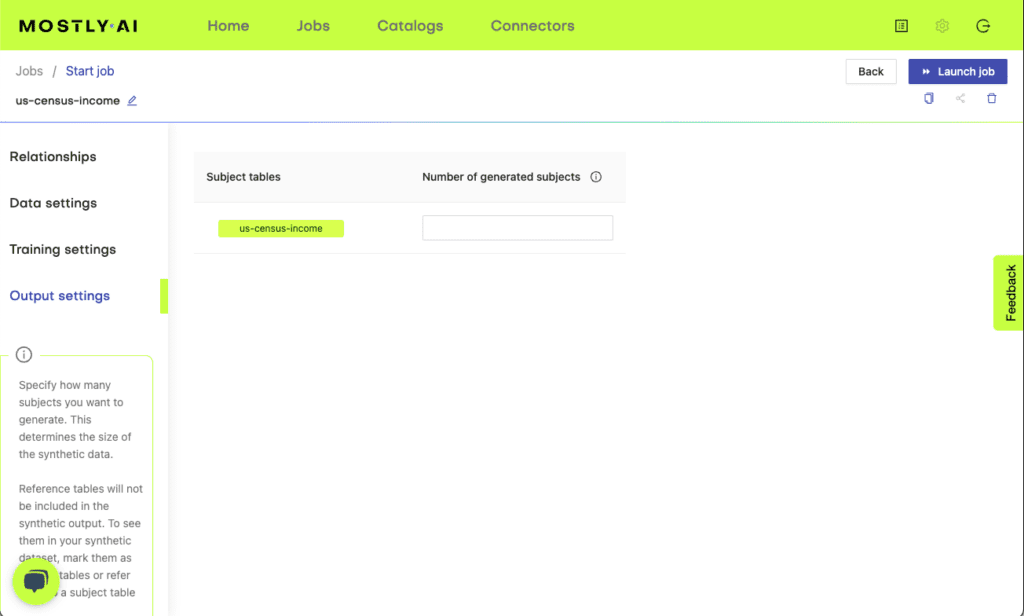
Pro tip from our data scientists: enter a smaller number of training subjects than what your original dataset has to launch a trial synthesization. Let’s say you have 1M rows of data. Use only 10K of the entire data set for a test run. This way you can check for any issues quickly. Once you complete a successful test run, you can use all of your data for training. If you leave the Number of training subjects field empty, the synthetic data generator will use all of the subjects of your original dataset for the synthesization.
Generating more data samples than what was in the original dataset can be useful too. Using synthetic data for machine learning model training can significantly improve model performance. You can simply boost your model with more synthetic samples than what you have in production or upsample minority records with synthetic examples.
You can also optimize for a quicker synthesization by changing the Training goal to Speed from Accuracy.
Once the process of synthesization is complete, you can download your very own synthetic data! Your trained model is saved for future synthetic data generation jobs, so you can always go back and generate more synthetic records based on the same original data. You can also choose to generate more data or to download the Quality Assurance report.
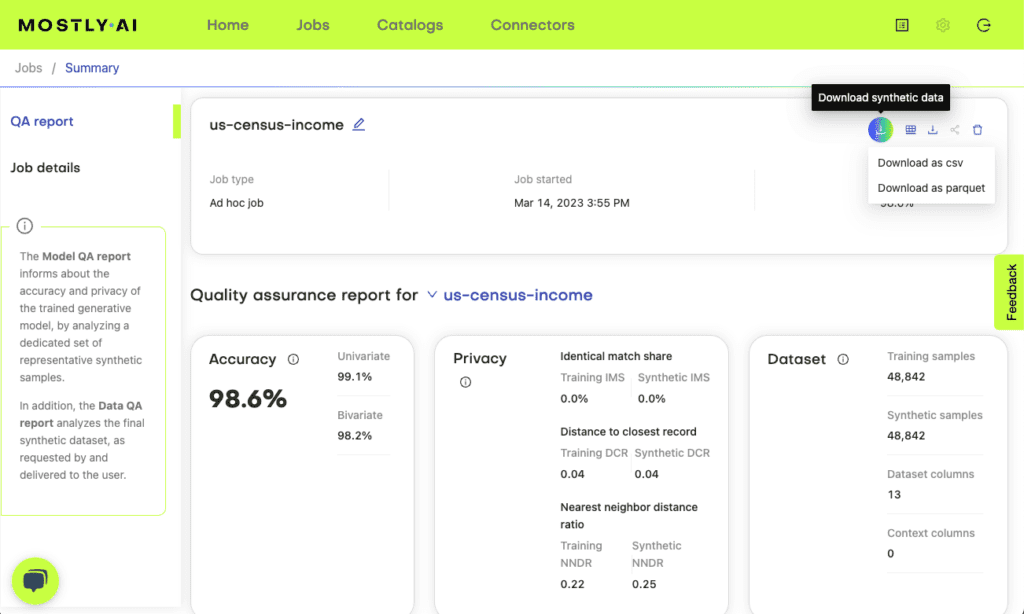
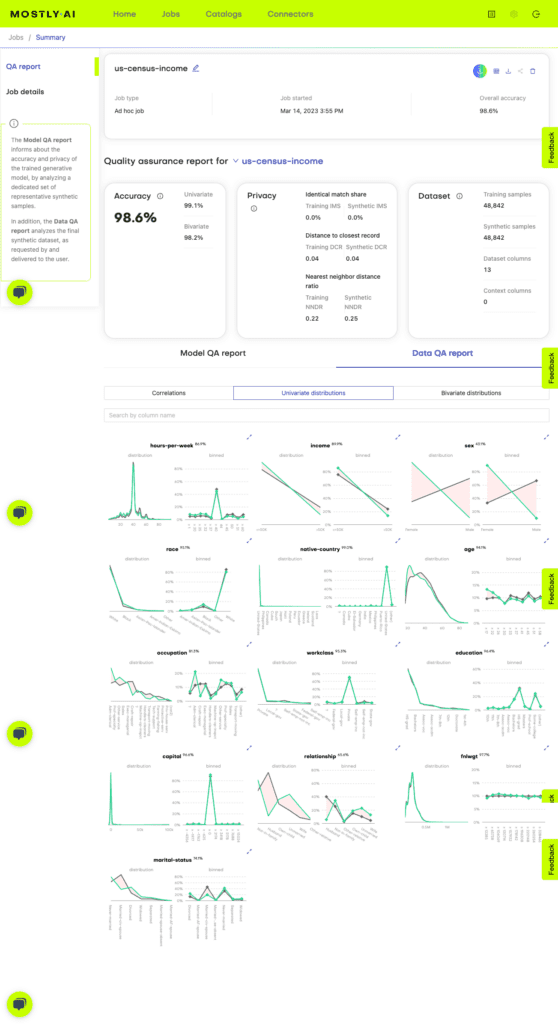
Step 4 - Check the quality of your synthetic data
Each synthetic data set generated on MOSTLY AI’s synthetic data platform comes with an interactive quality assurance report. If you are new to synthetic data generation or less interested in the data science behind generative AI, simply check if the synthetic data set passed your accuracy expectations. If you would like to dive deeper into the specific distributions and correlations, take a closer look at the interactive dashboards of the QA report.
How and when to synthesize data in two tables?
Synthesizing data in two separate tables is necessary when your data set contains temporal information. In more simple terms, to synthesize events, you need to separate your data subjects - the people or entities to whom the events or behavior belong to - and the events themselves. For example, credit card transaction data or patient journeys are events that need to be handled differently than descriptive subject tables. This so-called time-series or behavioral data needs to be included in linked tables.
What are linked tables?
Now we are getting to the exciting part of synthetic data generation, that is able to unlock the most valuable behavioral datasets, like transaction data, CRM data or patient journeys. Linked tables containing rich behavioral data is where AI-powered synthetic data generators really shine. This is due to their ability to pick up on patterns in massive data sets that would otherwise be invisible to the naked eyes of data scientists and BI experts.
These are also among the most sensitive data types, full of extremely valuable (think customer behavior), yet off-limits, personally identifiable, juicy details. Behavioral data is hard to anonymize without destroying the utility of the data. Synthetic behavioral data generation is a great tool for overcoming this so-called privacy-utility trade off.
How to create linked tables?
The structure of your sample needs to follow the subject table - linked table framework. We already discussed subject tables - here the trick is to make sure that information about one data subject must be contained in one row only. You should move columns that are static to the subject table and model the rest as a linked table.
MOSTLY AI’s algorithm learns statistical patterns distributed in rows, so if you have information that belongs to a single individual across multiple rows, you’ll be creating phantom data subjects. The resulting synthetic data might include phantom behavioral patterns not present in the original data.
The perfect set up for synthetic data generation
Your ideal synthetic data generation set up is where the subject table’s IDs refer to the events contained in the linked table. The linked table contains several rows that refer to the same subject ID - these are events that belong to the same individual.
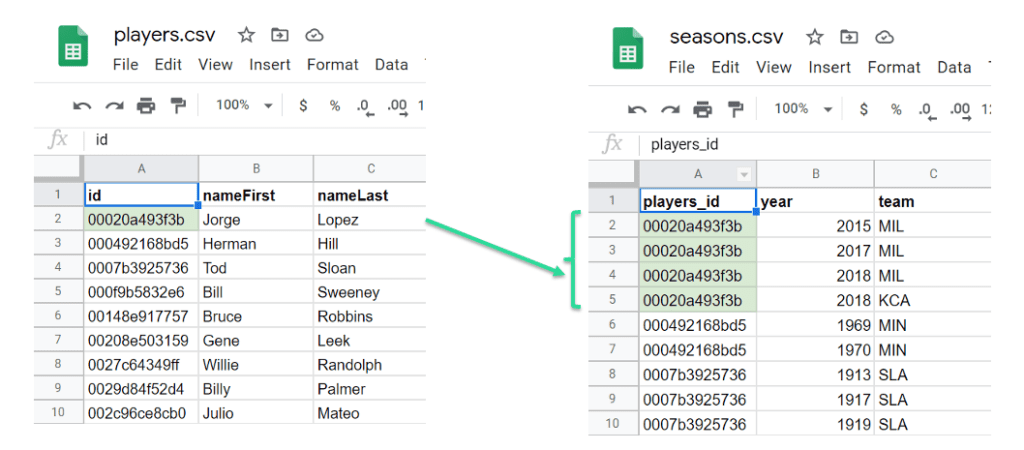
Keeping your subject table and linked table aligned is the most important part of a successful synthetic data generation. Include the ID columns in both tables as primary and foreign keys for establishing the referential relationship.
How to connect subject and linked tables for synthesization?
MOSTLY AI’s synthetic data generation platform offers an easy-to-use, no-code interface where tables can be linked and synthesized. Simply upload your subject table and linked tables.
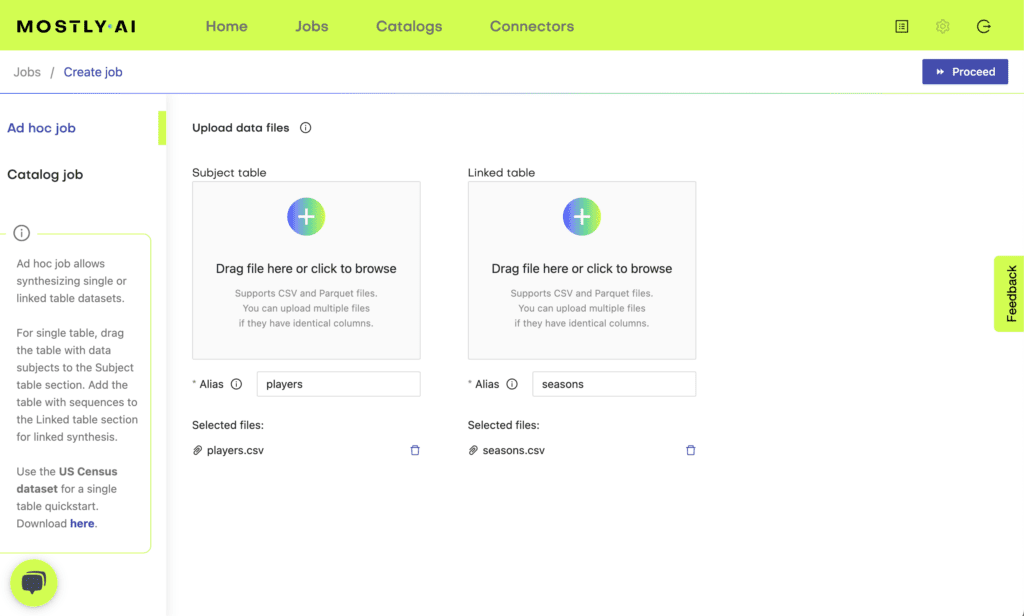
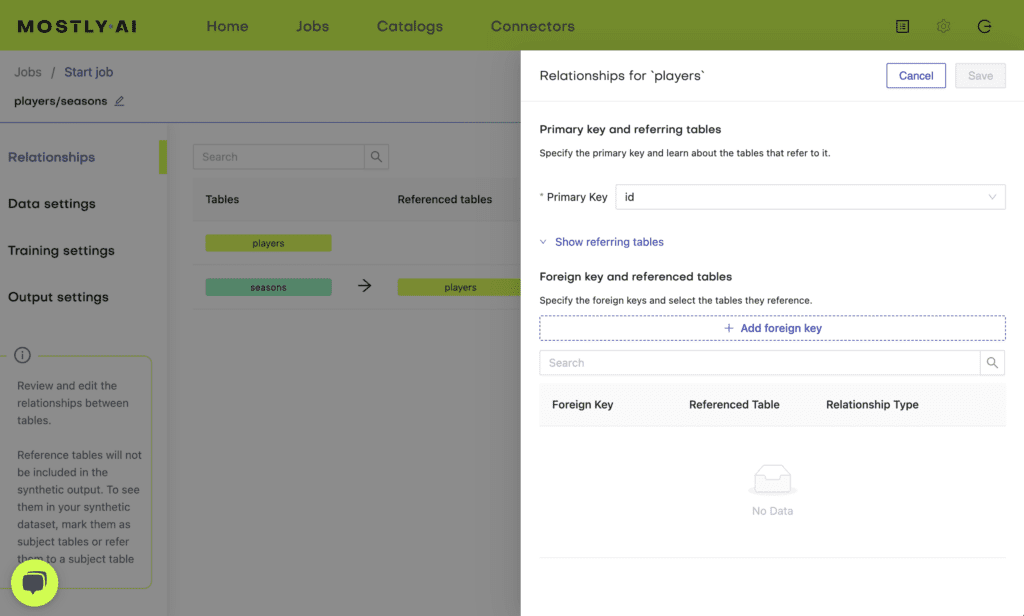
The platform automatically detects primary keys (the id column) and foreign keys (the <subject_table_name> _id column) once the subject table and the linked tables are specified. You can also select these manually. Once you defined the relationship between your tables, you are ready to launch your synthesization for two tables.
Synthetic data types and what you should know about them
The most common data types - numerical, categorical and datetime - are recognized by MOSTLY AI and handled accordingly. Here is what you should know when generating synthetic data from different types of input data.
Synthetic numeric data
Numeric data contains only numbers and are automatically treated as numeric columns. Synthetic numeric data keeps all the variable statistics such as mean, variance and quantiles. N/A values are handled separately and the proportion of that is retained in the synthetic data. MOSTLY AI automatically detects missing values and reproduces it in the synthetic data, for example, if the likelihood of N/A changes depending on other variables. N/A needs to be encoded as empty strings.
Extreme values in numeric data have a high risk of disclosing sensitive information, for example, by exposing the CEO in a payroll database as the highest earner. MOSTLY AI’s built-in privacy mechanism replaces the smallest and largest outliers with the smallest and largest non-outliers to protect the subjects’ privacy.
If the synthetic data generation relies on only a few individuals for minimum and maximum values, the synthetic data can differ in these. One more reason to give the CEO’s salary to as many people in your company as possible is to protect his or her privacy - remember this argument next time equal payment comes up. 🙂 Kidding aside, removing these extreme outliers is a necessary step to protect from membership inference attacks. MOSTLY AI’s synthetic data platform does this automatically, so you don’t have to worry about outliers.
Synthetic datetime data type
Columns in datetime format are treated automatically as datetime columns. Just like in the case of synthetic numeric data, extreme datetime values are also protected and the distribution of N/As is preserved. In linked tables, using the ITT encoding for inter-transaction time improves the accuracy of your synthetic data on time between events, for example when synthesizing ecommerce data with order statuses of order time, dispatch time, arrival time.
Synthetic categorical data type
Categorical data comes with a fixed number of possible values. For example, marital status, qualifications or gender in a database describing a population of people. Synthetic data retains the probability distribution of the categories, containing only those categories present in the original data. Rare categories are protected independently for each categorical column.
Synthetic location data type
MOSTLY AI’s synthetic data generator can synthesize geolocation coordinates with high accuracy. You need to make sure that latitude and longitude coordinates are in a single field, separated by a comma, like this: 37.311, 173.8998
Synthetic text data type
MOSTLY AI’s synthetic data generator can synthesize up to 1000 character long unstructured texts. The resulting synthetic text is representative of the terms, tokens, their co-occurrence and sentiment of the original. Synthetic text is especially useful for machine learning use cases, such as sentiment analysis and named-entity recognition. You can use it to generate synthetic financial transactions, user feedback or even medical assessments. MOSTLY AI is language agnostic, so you won’t experience biases in synthetic text.
You can improve the quality of your text columns that include specific patterns, like email addresses, phone numbers, transaction IDs, social security numbers, if you change these to character sequence data type.
Configure synthetic data generation model training
You can optimize the synthetic data generation process for accuracy or speed, depending on what you need the most. Since the main statistical patterns are learned by the synthetic data generator in the first epochs, you can choose to stop the training by selecting the Speed option if you don’t need to include minority classes and detailed relationships in your synthetic data.
When you optimize for accuracy, the training continues until no further model improvement can be achieved. Optimizing for accuracy is a good idea when you are generating synthetic data for data analytics use cases or outlier detection. If you want to generate synthetic data for software testing, you can optimize for speed, since high statistical accuracy is not an important feature of synthetic test data.
Synthetic data use cases from no-brainer to genius
The most common synthetic data use cases range from simple, like data sharing to complex, like explainable AI, which is part data sharing and part data simulation.
Another entry level synthetic data generation project can be generating realistic synthetic test data, for example for stress testing and for the delight of your off-shore QA teams. As we all know, production data should never, ever see the inside of test environments (right?). However, mock data generators cannot mimic the complexity of production data. Synthetic test data is the perfect solution combining realism and safety in one.
Synthetic data is also one of the most mature privacy-enhancing technologies. If you want to share your data with third parties safely, it’s a good idea to run it through a synthetic data generator first. And the genius part? Synthetic data is set to become a fundamental part of explainable and fair AI, ready to fix human biases embedded in datasets and to provide a data window into the souls of algorithms.
Expert synthetic data help every step of the way
No matter which use case you decide to tackle first, we are here for you from the first steps to the last and beyond! If you would like to dive deeper into synthetic data generation, please feel free to browse and search through MOSTLY AI’s Documentation. But most importantly, practice makes best, so register your free forever account and launch your first synthetic data generation job now.
✅ Data prep checklist for synthetic data generation
1. SPLIT SINGLE SEQUENTIAL DATASETS INTO SUBJECT AND LINKED TABLES
If your raw data includes events and is contained in a single table, you need to split it into a subject table and a linked table. If your single table contains event data, move these sequential data points into another table. Make sure that the new table is linked by the foreign key to the primary key in the subject table. That is, each individual or entity in the subject table is referred to by the linked table with the relevant ID.
How sequential data is structured also matters. If your events are contained in columns, make sure you model them into rows. Each row should describe a separate event.
Some examples of typical dataset synthesized for a wide variety of use cases include different types of time series data, like patient journeys where a list of medical events are linked to individual patients. Synthetic data in banking is often created from transaction datasets where subject tables contain accounts and the linked table contains the transactions that belong to certain accounts, referenced in the subject table. These are all time-dependent, sequential datasets where chronological order is an important part of the data’s intelligence.
When preparing your datasets for synthesization, always consider the following list of requirements:
| Subject Table | Linked table |
| Each row belongs to a different individual | Several rows belong to the same individual |
| The subject ID (primary key in SQL) must be unique | Each row needs to be linked to one of the unique IDs in the subject table (foreign key in SQL) |
| Rows should be treated independently | Several rows can be interrelated |
| Includes only static information | Includes only dynamic information where sequences must be time-ordered if available |
| The focus is on columns | The focus is on rows and columns |
2. MOVE ALL STATIC DATA TO THE SUBJECT TABLE
Check your linked table containing events. If you have static information in the linked table, that is describing the subject, you should move that column to the subject table. A good example would be a list of page visits, where each page visit is an event that belongs to certain users. The IP address of users is the same across different events. It’s static and describes the user, not the event. In this case, the IP_address column needs to be moved over to the subject table.

3. CHECK AND CONFIGURE DATA TYPES
The most common data types, numerical, categorical and datetime are automatically detected by MOSTLY AI’s synthetic data platform. Check if the data types were detected correctly and change the encoding where you have to. If the automatically detected data types don’t match your expectations, double check the input data. Chances are, that a formatting error is leading detection astray and you might want to fix that before synthesization. Here are the cases when you should check and manually adjust data types:
- If your categories are defined by numbers, those will be automatically detected as digit
- If your column format is not correct or if empty data is encoded as non-empty string/token, your digit/datetime column might be treated as a categorical column
TL;DR
- Synthetic data generation methods changed significantly with the advance of AI
- AI-generated, sample-based synthetic data is an entirely different beast than random or mock data
- Stochastic processes are still useful if you care about data structure but not content or meaning
- Rule-based synthetic data generation methods can be used for simple use cases with low, fixed requirements toward complexity
- Use deep generative models to automatically retain structure as well as information of data at scale to unlock private data and reduce model-to-market time
An overview of synthetic data generation methods
Not all synthetic data is created equal and in particular, synthetic data generation methods today are very different from what they were 5 years ago. Let’s take a look at different methods of synthetic data generation from the most rudimental forms to the state-of-the-art methods to see how far the technology has advanced! In this post we will distinguish between three major methods:
- The stochastic process: random data is generated, only mimicking the structure of real data.
- Rule-based data generation: mock data is generated following specific rules defined by humans.
- Deep generative models: rich and realistic synthetic data is generated by a machine learning model trained on real data, replicating its structure and the information it contains.

Which synthetic data generation method should you choose? Evaluation metrics 101
The choice of method depends on the use case and should be evaluated - if possible - both by an expert on the data synthesis and by a domain expert, who is familiar with the data and its downstream usage.
In addition to use-case-specific criteria, several general aspects can be used to evaluate and compare the different synthetic data generation methods available.
- Computation: how much compute is needed to generate data or to build a model.
- Human labor: how much human expertise and labor goes into the generation process.
- System complexity: how difficult it is to build such a data generation system.
- Information content: how much information is present in the synthetic data.
The stochastic process: when form matters more than content
If the structure of the desired synthetic data is known, and the data distribution is irrelevant - when random noise is all you need - the stochastic process is a perfect synthetic data generation method.
An example would be where the synthetic dataset should take the form of a CSV file with a specific number of columns and rows. A random number generator can be used to fill the fields following a defined distribution.
The applicability of such a process is limited to cases where the content of the synthetic data is irrelevant and random noise is good enough in place of real data. Examples of such applications would be stress testing systems, where a huge amount of random data is generated on the fly to evaluate how systems behave under heavy use.
- Computation: generating random data has very small computational needs and can be performed on the fly whenever random data is needed.
- Human labor: the data structure of the synthetic data can be defined easily, or inferred from an existing dataset, reducing the human expertise and labor to a minimum.
- System complexity: these systems are the easiest to build and challenges during implementation often concern computational efficiency to maximize the amount of data that can be generated with given resources.
- Information content: the generated synthetic data contains no relevant information.
Rule-based synthetic data generation: the human-powered machine
The obvious downside to synthetic data generation methods using stochastic processes is their limited use-cases since the resulting data is random and contains no real information.
Rule-based synthetic data generation methods improve on that by using hand-generated data following specific rules defined by humans.
The complexity of those rules can vary from very simple, taking only the desired data type of a column into account (i.e. if a column contains numeric, categorical, or text data), to more sophisticated rules, that define relationships between various columns and events. The amount of human labor and expertise needed, as well as the information contained in the generated data, are therefore completely dependent on the defined rules.
Thus, rule-based synthetic data generation methods come with three additional challenges:
- Scalability: datasets containing many different interdependent columns in a multi-table configuration easily need hundreds of complex and intertwined rules. Adding additional rules gets more and more difficult, practically limiting the maximum complexity of the data that can be modelled.
- Bias: since the rules are defined by human experts, the bias of those experts is reflected in the rules and is therefore present in the generated data. Some table columns might reflect a clearly defined business logic, where bias is part of the agreed policy, but others (e.g. customer behavior, or patient history) might be more susceptible to unconscious human bias.
- Drift: real world data is continuously changing, so rules need to be altered to reflect that change. Complex rule-based systems need effective change management governing the conditions and deciding which rules have to be adapted to reflect changes in the context of their application.
Coping with these challenges can be very difficult, and in many cases, they prove to be deal-breakers. Specifically, Scalability and Drift prevent rule-based systems to be used in applications that require flexibility and support for changing data requirements, effectively limiting its applicability to use cases where the scope and the data requirements are exactly known and will not change. But if these challenges are successfully met, a rule-based system can be a good enough choice for testing in applications, ranging from the generation of tabular data to multimedia content.
However, in any case, no additional information can be extracted from the rule-based synthetic data, than what was already known beforehand and manually encoded into the rules. Thus, these datasets offer no value for analytics, nor for decision support, nor for training machine learning models.
Several web-based tools exist where one can manually define the structure and simple rules to generate tabular data. These kinds of synthetic data generation methods can then be used for testing purposes in software development, or integration tests, ranging from the most typical to the testing of specific edge cases.
- Computation: the computational resources needed to run such a system are completely governed by the number and the complexity of the rules, but in general, the method’s computation needs can be classified as minor to moderate.
- Human labor: the amount of human labor and expertise needed to use such a system is extensive and much higher than any of the other methods described.
- System complexity: the system grows with the number and complexity of the rules supported. In addition, the format/language and interface used to describe rules can be a major contributor to system complexity. In general, the method’s system complexity is high.
- Information content: the information contained in the generated data is limited only by the applied rules.
AI-generated synthetic data: learning by example
Generative AI has revolutionized many things, synthetic data generation methods being one of the prime examples. Synthetic data generation methods using generative algorithms replace code with data. The rules of rule-based synthetic data generation are inherently contained in data samples, upon which AI-powered synthetic data generators are trained. Generative AI models are a class of statistical models that learn the distribution of training data and can be used to generate new data following that distribution.
Applying generative models from machine learning, it is possible to train a machine learning model (e.g. an artificial neural network) with real data so that it learns the structure and the information contained and is able to generate new synthetic data.
Synthetic data generators can be open source, like MIT's synthetic data vault or proprietary, like MOSTLY AI's synthetic data platform. When comparing synthetic data quality, MOSTLY AI's robust commercial solution outperformed SDV in a research conducted by the Joint Reserach Centre of the European Commission.
The human guidance needed by such a system can be minimal. In the best case, no human interaction is needed and the machine learning model is trained automatically.
The complexity of the data that can be learned by such a model is, primarily, limited by the data available and the model capacity (i.e. model architecture and hyperparameters). If the data requirements change, no significant adjustments are needed, simply a new model needs to be trained on the actual data.
Due to the power of machine learning models mimicking the training data, three new challenges unique to this synthetic data generation method have to be addressed:
- Data similarity: The success of replicating the information contained within the original data depends on data complexity and the capacity of the model one chooses to use. For best results, special attention must be paid to testing and documenting the similarity of the synthetic data compared to the original data used to train the model. The metric of similarity is application-specific, but methods from descriptive statistics can be used to analyze the univariate and multivariate distribution, as well as the correlation between features for the synthetic and training data.
- Privacy: with great power comes great responsibility. With many machine learning models being prone to overfitting, one needs to take particular caution to prevent the memorization of training examples. This is particularly important, if the training data is privacy-sensitive, and must be protected.
- Business rules: generative models learn the distribution of features in the training data, and don't yet have a human-like understanding of what a feature means, or what relational qualities exist between features. However, a well-trained generative model will be able to learn most of the rules and retains relationships contained within the training data. Those rules, which are not yet adhered to, can be enforced by simply filtering out the few invalid records as part of the post-processing.
Once these challenges have been met, the applications of AI-powered synthetic data generation methods are almost limitless, and even go beyond what is possible with real data.
Two unique opportunities arise with the use of generative models. One is the use of synthetic data in place of the original data that cannot be accessed because of legal and privacy reasons, and the second is the use of synthetic data within a company to reduce the development time of machine learning models.
One such example, where synthetic data is playing a key role in unlocking original data protected for privacy reasons, is in finance. Here, synthetic data is used for example to improve fraud detection, since it contains the statistical properties necessary for improving fraud detection systems, without exposing the privacy of individuals.
Sharing data across departments and even country borders becomes a seamless process when using a high quality, accurate and privacy compliant deep generative tool, like our very own MOSTLY AI synthetic data platform. As shown in our benchmarking study, MOSTLY AI is the world’s most accurate deep generative tool, which makes the most of all deep generative model advantages, such as the highest levels of statistical utility.
Another example is the use of synthetic data by data science, machine learning and business intelligence units. In most working environments, data access is strictly regulated resulting in time-consuming processes. Working with synthetic data instead of the original makes it possible to build models much faster and to reduce model-to-market time.
We have shown in a recent study that models trained on synthetic data achieve comparable results, and in some cases even outperform models trained on original data. AI model development is increasingly relying on synthetic training data due to the possibilities of data augmentation during the synthesization process, turning data into modelling clay for data scientists and machine learning engineers.
Test data generation can also massively benefit from the power of AI. Synthetic test data generators can pick up on business rules encoded in the production data and automatically recreate them. The resulting synthetic test data is highly realistic and covers many more business cases than manual data generation ever could.
- Computation: the training of machine learning models is in general very compute-intensive, but the problem can be mitigated by the use of special hardware (e.g. GPU, TPU, ASIC as well as others) and by the use of cloud computing.
- Human labor: an optimal machine learning system can be application-agnostic, limiting user interaction to the selection of the training data used to create the models and to some post-processing - depending on the qualities of the dataset and its application.
- System complexity: Machine learning-enabled data synthesis is by far the most complex of the described systems, as it contains multiple complex sub-components (e.g. machine learning model, training infrastructure, and user applications to interact with the system). The architecture of generative models for tabular data and its power to solve previously untouched problems, such as human bias and imbalances is an open research topic full of future potentials.
- Information content: a model capable of generating synthetic data with high similarity to the training data maximizes information content, surpassing rule-based systems by a huge margin and in some cases is even better than raw data.
For a more in-depth introduction to generative models, take a look at this blog post by OpenAI or Stanford’s free course on the subject.
Rundown
Here is a summary of the synthetic data generation methods compared and their performance on the metrics used to evaluate them.
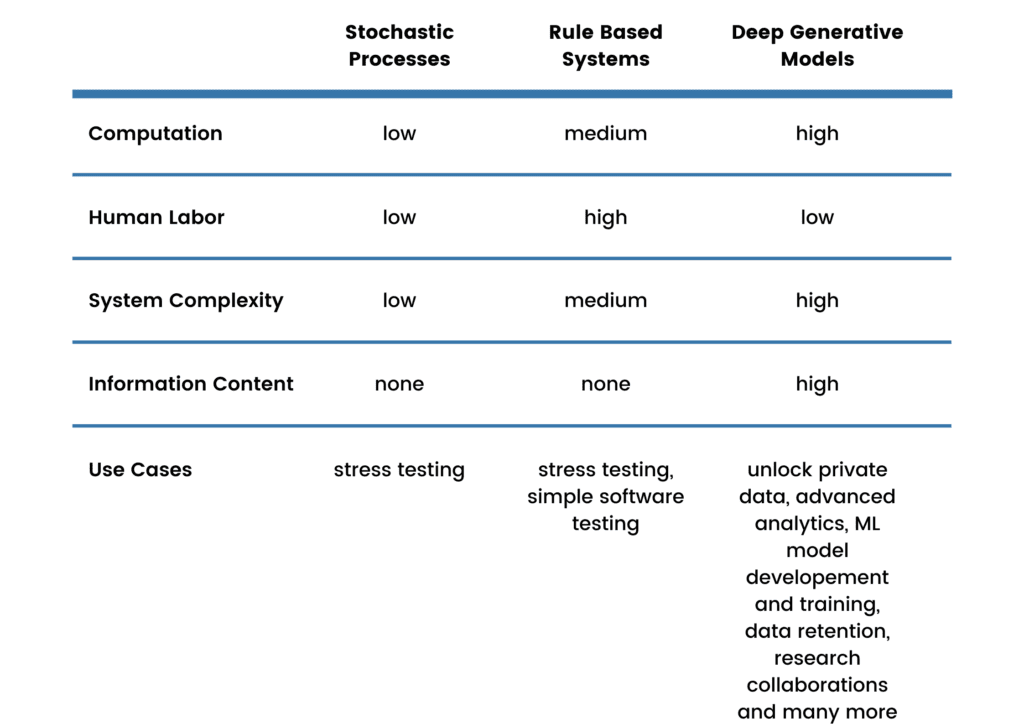
How to choose the right synthetic data generation method?
After having discussed the capabilities and challenges of the various synthetic data generation methods, how do you decide which one matches best the requirements and use cases at hand? Two simple questions shall guide your decision:
- Do you have resources/expertise available to build your own system, and
- Does the synthetic data need to be realistic as well as representative?
Solutions making use of stochastic processes and rule-based systems are highly dependent on their use case, and almost always require the development of new property software. Libraries like cayenne or PyRATA can support such efforts, but require expertise, resources, and will to be maintained.
If the synthesized data has to be realistic, stochastic processes are out of the question and rule-based systems only make sense if it is clear what the data should look like and that description can be written in code.
If in-house development is not an option and the synthetic data has to be as realistic and representative as possible, the use of ML-enabled systems as a service is the best course of action.
How is MOSTLY AI making the most out of generative models?
With MOSTLY AI's synthetic data platform we are addressing the unique challenges coming with generative models. Our synthetic data generation platform comes with built-in privacy safeguards, preventing overfitting, and eliminating the risk of re-identification. Synthetic data is exempt from data privacy regulations, freeing up your previously untouched data assets for sharing and utilization. What’s more, generated synthetic datasets come with automated quality assurance reports which make the assessment of the quality quick and painless.
We at MOSTLY AI are proud to serve customers worldwide. Our clients use synthetic data for finance, insurance and telecommunications use cases. Curious? Head over to the browser version of our product and generate synthetic data yourself for free forever, up to 100K rows a day! Hopefully, this post has been useful to you and provided you with a better understanding of how synthetic data generation has evolved from simple stochastic processes to sophisticated deep generative models. Feel free to reach out and contact us, either with feedback, questions, or any other concerns.
Here at MOSTLY AI, we are big fans of open-source software. We are leveraging more than 90 open-source software packages for our synthetic data generator. It is safe to say that without open-source software libraries, it would have been impossible to get where we are today so quickly. We sometimes get asked by prospects why they should choose MOSTLY AI’s Synthetic Data Platform over freely available open-source solutions, like MIT’s Synthetic Data Vault, to synthesize data. This blog post provides an answer.
Update: SDV changed their license model in 2023, and is NOT open-source anymore.
SDV vs MOSTLY AI: Synthetic data quality
The answer is multifaceted, but the main point is the quality of the synthetic data you can generate. We pride ourselves on delivering synthetic data that is so close to the real data that it can be used as a drop-in replacement without sacrificing any meaningful quality. And, of course, all while guaranteeing full privacy.
Already two years ago, we looked at the quality of synthetic data generated with two popular open-source models: CTGAN and TVAE. Back then, we showed how MOSTLY AI’s synthetic data had higher accuracy on multiple dimensions. This time we look more broadly at the open-source software library developed by MIT, the Synthetic Data Vault (SDV). It was initially released in 2018 based on research work led by Kalyan Veeramachaneni. SDV is a Python library that supports three types of data: single table data, relational data, and time series data. In addition, SDV provides an evaluation and benchmarking framework, SDGym, and comes with 100+ datasets that can be used to explore the functionality.
For this benchmarking exercise, we picked five of the 19 provided single table datasets to get a good variety of data in terms of size and structure:
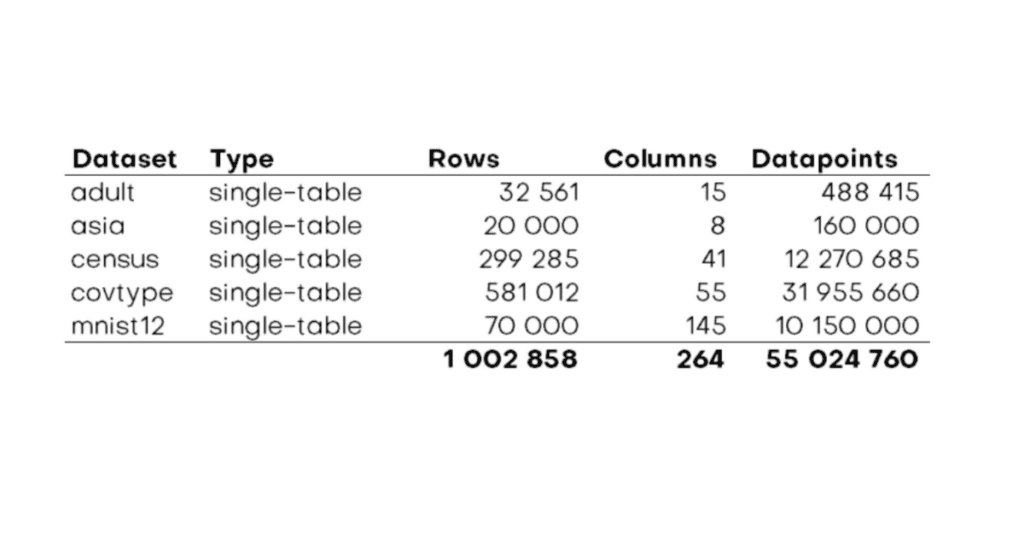
Currently, SDV offers five different models for synthesizing single table data: Tabular Preset (FAST_ML), GaussianCopula, CTGAN, CopulaGAN, and TVAE. To get a proper overview of the state of the art of open-source data synthesis, we spun up some virtual machines and synthesized all five datasets with all available models. And of course, we used the latest release of the MOSTLY AI Synthetic Data Platform to synthesize these datasets to compare. For the record – we used the standard configurations of all models and of our platform. We did not specifically try to tune any dataset. In total, we created more than 5 million rows of synthetic data or 300 million synthetic data points.
The big picture of quality includes the functionality of the synthetic data
Since we wanted to check out SDV more broadly, we also had a look at the functionality to evaluate the quality of generated synthetic data. SDV’s Evaluation Framework takes a real and a synthetic dataset as input and then calculates up to 29 different metrics comparing these two. It returns the average of the scores of the individual metrics, which results in an overall score from 0 to 1, with 0 being the worst and 1 being the best (= the synthetic data is really close to the real data).
For our benchmark, we picked three metrics that worked without any further configuration (LogisticDetection, CSTest, and KSTest) and had SDV report the aggregate score. CSTest (Chi-Squared test) and KSTest (two-sample Kolmogorov–Smirnov test) are statistical metrics that compare the tables by running different statistical tests. LogisticDetection is part of the detection metrics, which evaluate how hard it is to distinguish the synthetic data from the real data by using an ML model (in this case a LogisticRegression classifier).
The results are summarized in the chart below:
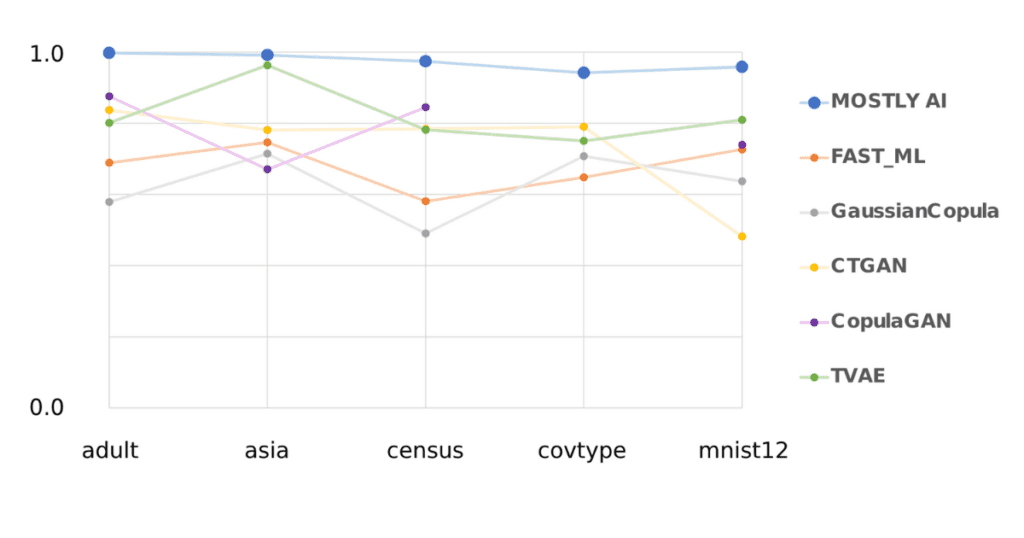
* Please note that no synthetic data for covtype could be created with CopulaGAN due to time-out issues, even on a VM with 224 vCPUs
In short: MOSTLY AI beat every single open-source model for every single dataset. Unsurprisingly the less compute intense FAST_ML, and GaussianCopula models cannot create highly realistic synthetic data with average scores of 0.68 and 0.63, respectively. From the more sophisticated models, TVAE performs best with an average score of 0.82, followed by CopulaGAN (0.78) and CTGAN (0.74). MOSTLY AI’s average score is 0.97.
SDV vs MOSTLY AI: Beyond the hard metrics & further evaluations on synthetic data generation
In practice, you will want to evaluate synthetic data on more dimensions than statistical and detection metrics. High-level metrics give you a first assessment of the quality of the created synthetic data, but the real deal is when synthetic data is actually evaluated by performing the exact same downstream tasks you would have performed using the real data.
Again and again, these analyses confirm what we already know: MOSTLY AI’s Synthetic Data Platform delivers the most accurate synthetic data consistently. But don’t take my word for it: you can find all the created synthetic datasets as a download here to perform whatever kind of analysis you wish.
The heart of our synthetic data platform is where we do not rely on open source but instead have developed our own proprietary IP. The approach and the deep learning architecture used to train a generative model. We have done so because this is what really matters when it comes to achievable synthetic data quality.
There are other reasons to consider when choosing a synthetic data generator. In addition to unmatched synthetic data quality, some of the reasons for choosing MOSTLY AI’s Synthetic Data Platform include:
- Ease of use: Our platform is so simple to use, practically anyone can synthesize data. You do not have to write a single line of code. You do not have to worry about choosing the generative model or about hyperparameter tuning. Just provide the data you want to synthesize, and the platform takes care of the rest – making sure to deliver the highest quality synthetic data.
- Speed: Training sophisticated generative models is compute-intense, and takes time and money. We waited several hours for some CTAN and TVAE models to train on strong VMs. With our platform on a lightweight VM, the synthesizations never took longer than an hour. In production, this can lead to significant cost savings.
- Flexible data ingestion: Instead of being limited to ingesting CSV files, you can connect directly to various data sources, including cloud buckets (e.g., AWS S3) or relational databases like Oracle, MySQL, and PostgreSQL. This saves time and pre- and post-processing steps that are otherwise necessary.
- Privacy guarantees: Synthetic data is not, per default, fully anonymous. For example, you need to make sure to handle outliers and extreme values properly. MOSTLY AI’s synthetic data generator takes care of all that automatically.
- Dedicated support: We have been working in this space for more than five years and know synthetic data inside out. If you encounter any issues, we are there to provide support – for our enterprise clients with guaranteed SLAs.
SDV vs MOSTLY AI: In conclusion
In conclusion, at MOSTLY AI, we are enthusiastic supporters of open-source software and recognize its significant contribution to our synthetic data generator. Our rapid progress and success can be attributed to leveraging over 90 open-source software packages. However, when prospects inquire about why they should choose our Synthetic Data Platform over freely available open-source solutions like Synthetic Data Vault (SDV), we have compelling reasons to offer.
The key factor that sets us apart is the exceptional quality of the synthetic data we generate. We take great pride in delivering synthetic data that closely resembles real data, allowing for seamless integration without compromising privacy or sacrificing quality. In a previous analysis, we compared the accuracy of synthetic data generated using two popular open-source models, CTGAN and TVAE, and demonstrated that MOSTLY AI's synthetic data exhibited superior accuracy across multiple dimensions. This time, we conducted a broader evaluation by examining SDV, an open-source software library developed by MIT.
To assess the quality of the generated synthetic data, we utilized SDV's evaluation framework, which employs various metrics to compare real and synthetic datasets. The results were consistently in our favor, highlighting the superiority of MOSTLY AI's Synthetic Data Platform.
Beyond statistical and detection metrics, we firmly believe in evaluating synthetic data through practical applications. Repeated analyses have validated that our platform consistently delivers the most accurate synthetic data. However, we don't expect you to take our word for it. We invite you to explore and analyze the synthetic datasets we have created, which are available for download.
While open-source software plays a crucial role in our work, we have developed our proprietary intellectual property to ensure the highest possible synthetic data quality. The heart of our Synthetic Data Platform lies in our unique approach and deep learning architecture for training generative models.
In addition to exceptional data quality, there are other reasons to consider our Synthetic Data Platform. We prioritize user experience, offering a straightforward and code-free platform that eliminates the need for choosing generative models or fine-tuning hyperparameters. Moreover, our platform ensures speed and efficiency, leading to significant cost savings compared to training sophisticated generative models using open-source solutions. We also provide flexible data ingestion capabilities, enabling direct connections to various data sources, saving time and effort on pre- and post-processing steps.
Privacy is of utmost importance, and our synthetic data generator automatically handles outliers and extreme values, ensuring privacy. Lastly, we offer dedicated support, leveraging our extensive experience in the synthetic data domain to provide assistance to our enterprise clients with guaranteed service level agreements (SLAs).
If you would like to experience the power of the MOSTLY AI Synthetic Data Platform, we encourage you to sign up and generate synthetic data for free. We are confident that our platform's capabilities and the quality of synthetic data it produces will exceed your expectations.
Experience the power of the MOSTLY AI Synthetic Data Platform for yourself and sign up to generate synthetic data for free.
The agile and DevOps transformation of software testing has been accelerating since the pandemic and there is no slowing down. Applications need to be tested faster and earlier in the software development lifecycle, while customer experience is a rising priority. However, good quality, production-like test data is still hard to come by. Up to 50% of the average tester‘s time is spent waiting for test data, looking for it, or creating it by hand. Test data challenges plague companies of all sizes from the smaller organizations to enterprises. What is true in most fields, also applies in software testing: AI will revolutionize testing. AI-powered testing tools will improve quality, velocity, productivity and security. In a 2021 report, 75% of QA experts said that they plan to use AI to generate test environments and test data. Saving time and money is already possible with readily available tools like synthetic test data generators. According to Gartner, 20% of all test data will be synthetically generated by 2025. And the tools are already here. But let's start at the beginning.
What is test data?
The definition of test data depends on the type of test. Application testing is made up of lots of different parts, many of which require test data. Unit tests are the first to take place in the software development process. Test data for unit tests consist of simple, typically small samples of test data. However, realism might already be an important test data quality. Performance testing or load testing requires large batches of test data. Whichever stage we talk about, one thing is for sure. Production data is not test data. Production data should never be in test environments. Data masking, randomization, and other common techniques do not anonymize data adequately. Mock data and AI-generated synthetic data are privacy-safe options. The type of test should decide which test data generation should be used.
What is a synthetic test data generator?
Synthetic test data is an essential part of the software testing process. Mobile banking apps, insurance software, retail and service providers all need meaningful, production-like test data for high quality QA. There is a confusion around the synthetic data term with many still thinking of synthetic data as mock or fake data. While mock data generators are still useful in unit tests, their usefulness is limited elsewhere. Similar to mock data generators, AI-powered synthetic test data generators are available online, in the cloud or on premise, depending on the use case. However, the quality of the resulting synthetic data varies widely. Use a synthetic test data generator that is truly AI-powered, retains the data structures, the referential integrity of the sample database and has additional, built-in privacy checks when generating synthetic data.
Accelerate your testing with synthetic test data
Get hands-on with MOSTLY AI's AI-powered platform and generate your first synthetic data set!
What is synthetic test data? The definition of AI-generated synthetic test data (TL;DR: it's NOT mock data)
Synthetic test data is generated by AI, that is trained on real data. It is structurally representative, referential integer data with support for relational structures. AI-generated synthetic data is not mock data or fake data. It is as much a representation of the behavior of your customers as production data. It’s not generated manually, but by a powerful AI engine that is capable of learning all the qualities of the dataset it is trained on, providing 100% test coverage. A good quality synthetic data generator can automate test data generation with high efficiency and without privacy concerns. Customer data should always be used in its synthetic form to protect privacy and to retain business rules embedded in the data. For example, mobile banking apps should be tested with synthetic transaction data, that is based on real customer transactions.
Test data types, challenges and their synthetic test data solutions
Synthetic data generation can be useful in all kinds of tests and provide a wide variety of test data. Here is an overview of different test data types, their applications, main challenges of data generation and how synthetic data generation can help create test data with the desired qualities.
| Test Data Types | Application | Challenge | Solution |
|---|---|---|---|
| Valid test data The combination of all possible inputs. | Integration, interface, system and regression testing | It’s challenging to cover all scenarios with manual data generation. Maintaining test data is also extremely hard. | Generate synthetic data based on production data. |
| Invalid (erroneous) test data Data that cannot and should not be processed by the software. | Unit, integration, interface, system testing, security testing | It is not always easy to identify error conditions to test because you don't know them a priori. Access to production errors is necessary but will also not yield previously unknown error scenarios. | Create more diverse test cases with synthetic data based on production data. |
| Huge test data Large volume test data for load and stress testing. | Performance testing, stress testing | Lack of sufficiently large and varied batches of data. Simply multiplying production data does not simulate all the components of the architecture correctly. Recreating real user scenarios with the right timing and general temporal distribution with manual scripts is hard. | Upsample production data via synthesization. |
| Boundary test data Data that is at the upper or lower limits of expectations. | Reliability testing | Lack of sufficiently extreme data. It’s impossible to know the difference between unlikely and impossible for values not defined within lower and upper limits, such as prices or transaction amounts. | Generate synthetic data in creative mode or use contextual generation. |
How to generate synthetic test data using AI
Generate synthetic data for testing using a purpose-built, AI-powered synthetic data platform. Some teams opt to build their own synthetic data generators in-house, only to realize that the complexity of the job is way bigger than what they signed up for. MOSTLY AI’s synthetic test data generator offers a free forever option for those teams looking to introduce synthetic data into their test data strategy.
This online test data generator is extremely simple to use:
- Connect your source database
- Define the tables where you want to protect privacy
- Start the synthesization
- Save the synthetic data to your target database
The result is structurally representative, referential integer data with support for relational structures. Knowing how to generate synthetic data starts with some basic data preparation. Fear not, it's easy and straightforward, once you understand the principles, it will be a breeze.
Do you need a synthetic test data generator?
If you are a company building a modern data stack to work with data that contains PII (personally identifiable information), you need a high quality synthetic data generator. Why? Because AI-generated synthetic test data is a different level of beast where generating a few tables won’t cut it. To keep referential integrity, MOSTLY AI can directly connect to the most popular databases and synthesize directly from your database. If you are operating in the cloud, it makes even more sense to test with synthetic data for security purposes.
Synthetic test data advantages
Synthetic data is smarter
Thanks to the powerful learning capabilities of the AI, synthetic data offers better test coverage, resulting in fewer bugs and higher reliability. You’ll be able to test with real customer stories and improve customer experience with unprecedented accuracy. High-quality synthetic test data is mission-critical for the development of cutting edge digital products.
Synthetic data is faster
Accelerated data provisioning is a must-have for agile software development. Instead of tediously building a dataset manually, you can let AI do the heavy lifting for you in a fraction of the time.
Synthetic data is safer
Built-in privacy mechanisms prevent privacy leaks and protect your customers in the most vulnerable phases of development. Radioactive production data should never be in test environments in the first place, no matter how secure you think it is. Legacy anonymization techniques fail to provide privacy, so staying away from data masking and other simple technuiques is a must.
Synthetic data is flexible
Synthesization is a process that can change the size of the data to match your needs. Upscale for performance testing or subset for a smaller, but referentially correct dataset.
Synthetic data is low-touch
Data provisioning can be easily automated by using MOSTLY AI’s Data Catalog function. You can save your settings and reuse them, allowing your team to generate data on-demand.
What’s wrong with how test data has been generated so far?
A lot of things. Test data management is riddled with costly bad habits. Quality, speed and productivity suffer unnecessarily if your team does any or all of the following:
1.) Using production data in testing
Just take a copy of production and pray that the unsecure test environment won’t leak any. It’s more common than you’d think, but that doesn’t make it ok. It’s only a matter of time before something goes wrong and your company finds itself punished by customers and regulators for mishandling data. What’s more, actual data doesn’t cover all possible test cases and it’s difficult to test new features with data that doesn’t yet exist.
2.) Using legacy anonymization techniques
Contrary to popular belief, adding noise to the data, masking data or scrambling it doesn’t make it anonymous. These legacy anonymization techniques have been shown time and again to endanger privacy and destroy data utility at the same time. Anonymizing time-series, behavioral datasets, like transaction data, is notoriously difficult. Pro-tip: don’t even try, synthesize your data instead. Devs often have unrestricted access to production data in smaller companies, which is extremely dangerous. According to Gartner, 59% of privacy incidents originate with an organization’s own employees. It may not be malicious, but the result is just as bad.
3.) Generate fake data
Another very common approach is to use fake data generators like Mockito or Mockaroo. While there are some test cases, like in the case of a brand new feature, when fake data is the only solution, it comes with serious limitations. Building datasets out of thin air costs companies a lot of time and money. Using scripts built in-house or mock data generation tools takes a lot of manual work and the result is far from sophisticated. It’s cumbersome to recreate all the business rules of production data by hand, while AI-powered synthetic data generators learn and retain them automatically. What’s more, individual data points might be semantically correct, but there is no real "information" coming with fake data. It's just random data after all. The biggest problem with generating fake data is the maintenance cost. You can start testing a new application with fake data, but updating it will be a challenge. Real data changes and evolves while your mock test data will become legacy quickly.
4.) Using fake customers or users to generate test data
If you have an army of testers, you could make them behave like end users and create production like data through those interactions. It takes time and a lot of effort, but it could work if you are willing to throw enough resources in. Similarly, your employees could become these testers, however, test coverage will be limited and outside your control. If you need a quick solution for a small app, it could be worth a try, but protecting your employees’ privacy is still important.
5.) Canary releases for performance and regression tests
Some app developers push a release to a small subset of their users first and consider performance and regression testing done. While canary testing can save you time and money in the short run, long term your user base might not appreciate the bugs they encounter on your live app. What’s more, there is no guarantee that all issues will be detected.
It’s time to develop healthy test data habits! AI-generated synthetic test data is based on production data. As a result, the data structure is 100% correct and it’s really easy to generate on-demand. What’s more, you can create even more varied data than with production data covering unseen test cases. If you choose a mature synthetic data platform, like MOSTLY AI’s, built-in privacy mechanisms will guarantee safety. The only downside you have to keep in mind is that for new features you’ll still have to create mock data, since AI-generated synthetic data needs to be based on already existing data.
Test data management in different types of testing
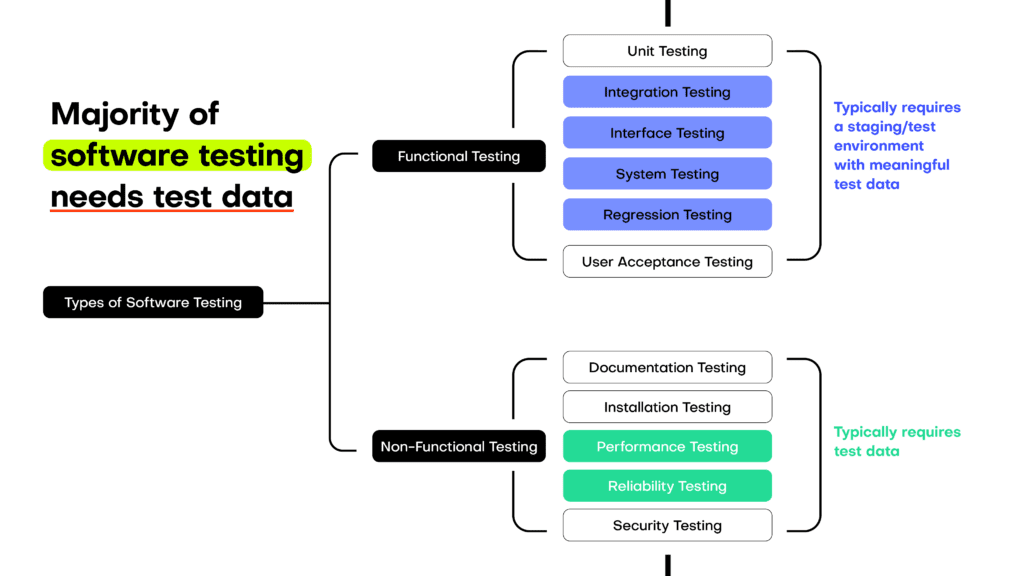
FUNCTIONAL TESTING
Unit testing
The smallest units of code tested with a single function. Mock data generators are often used for unit tests. However, AI-generated synthetic data can also work if you take a small subset of big original production datasets.
Integration testing
The next step in development is integrating the smallest units. The goal is to expose defects. Integration testing typically takes place in environments populated with meaningful, production-like test data. AI-generated synthetic data is the best choice, since relationships of the original data are kept without privacy sensitive information.
Interface testing
The application’s UI needs to be tested through all possible customer interactions and customer data variations. Synthetic customers can provide the necessary realism for UI testing and expose issues dummy data couldn’t.
System testing
System testing examines the entire application with different sets of inputs. Connected systems are also tested in this phase. As a result, realistic data can be mission-critical to success. Since data leaks are the most likely to occur in this phase, synthetic data is highly recommended for system testing.
Regression testing
Adding a new component could break old ones. Automated regression tests are the way forward for those wanting to stay on top of issues. Maximum test data coverage is desirable and AI-generated synthetic data offers just that.
User acceptance testing
In this phase, end-users test the software in alpha and beta tests. Contract and regulatory testing also falls under this category. Here, suppliers and vendors or regulators test applications. Demo data is frequently used at this stage. Populating the app with hyper-realistic synthetic data can make the product come to life, increasing the likelihood of acceptance.
NON-FUNCTIONAL TESTING
Documentation testing
The documentation detailing how to use the product needs to match how the app works in reality. The documentation of data-intensive applications often contain dataset examples for which synthetic data is a great choice.
Installation testing
The last phase of testing, before the end-user takes over, testing the installation process itself to see if it works as expected.
Performance testing
Tests how a product behaves in terms of speed and reliability. The data used in performance testing must be very close to the original. That’s why a lot of test engineers use production data treated with legacy anonymization techniques. However, these old-school technologies, like data masking and generalization, destroy both insights and come with very weak privacy.
Security testing
Security testing’s goal is to find risks and vulnerabilities. The test data used in security testing needs to cover authentication, like usernames and passwords as well as databases and file structures. High-quality AI-generated synthetic data is especially important to use for security testing.
Test data checklist
- Adopt an engineering mindset to test data across your team.
- Automate test data generation as much as you can.
- Develop a test data as a service mindset and provide on-demand access to privacy safe synthetic data sandboxes.
- Use meaningful, AI-generated smart synthetic test data whenever you can.
- Get management buy-in for modern privacy enhancing technologies (PETs) like synthetic data.
2021 has passed in the blink of an eye, yet MOSTLY AI can be proud as this was a revolutionary year of many extraordinary achievements. While we are already excited for what 2022 holds for us, we are taking a step back to look at the highlights and major milestones we have accomplished in 2021.
Synthetic data revolution
Our developers had a busy start to the year with the new upgrade of our category-leading synthetic data generator, MOSTLY AI 1.5. Alongside many shiny new features, the big buzz was about our synthetic data generator now supporting the synthesis of geolocation data with latitude and longitude encoding types. Say goodbye to harmful digital footprints and hello to privacy-safe synthetic geodata!
This was not enough for our very ambitious team; so in the second half of the year, they pushed the boundaries even further by truly revolutionizing software testing. With this new version of our platform, MOSTLY AI 2.0 became the first synthetic data platform that can automatically synthesize complex data structures, making it ideal for software testing. By expanding the capabilities to multi-table data structures, MOSTLY AI now enables anyone – not just data scientists – to create synthetic data from databases, automatically. This improves security and compliance and accelerates time to data. Our team truly deserves a toast for this!
The Data Democratization Podcast
We’ll be soon celebrating the first birthday of “The Data Democratization Podcast”, which we started back in January 2021. With over 2000 downloads in 2021, the podcast was an absolute hit! Our listeners had the opportunity to get so many insights from knowledgeable AI and privacy experts working in top-notch companies who shared their experiences, advice, and real-life case studies. We are entering the new year with even more enthusiasm and are preparing some special surprise guests for you. Stay tuned!
Synthetic data training for superusers
In 2021 we also launched our professional services and training program intended to help create the next generation of synthetic data superusers within enterprises. Several clients have already leveraged this first-of-its-kind program to kickstart their synthetic data journeys, with very positive results. As synthetic data pioneers, we have the most experienced team in the world. Our top engineers, architects, consultants, and data scientists have seen it all. They know what makes or breaks a company's synthetic data adoption, no matter the use case. From scaling ethical and explainable AI to providing on-demand, privacy-safe test data, the know-how is here.
Synthetic data talks
Despite COVID-19 we have managed to attend multiple conferences. While most of them happened virtually, we participated in Slush 2021 in person! Our Co-Founder & Chief Strategy Officer Michael Platzer rocked the stage presenting at this year's event in Helsinki, Finland. We are proud to have been invited to present our synthetic data solution to the world and - while staying safe - connect and exchange ideas with some of the most brilliant minds.
The only synthetic data provider to achieve SOC2 and ISO certifications
With data privacy and information security at the heart of everything we do, our efforts to ensure the privacy and integrity of our customer’s sensitive data by following strict security policies and procedures have been officially recognized this year. In March, we received the SOC 2 Type 2 certification, which is an audit report capturing how a company safeguards customer data and how well internal controls are operating and later in November, we got awarded the ISO 27001 certification which is a globally recognized information security standard.
Thanks to both SOC2 and ISO certifications, our customers and partners can now speed up vetting processes and immediately get a clear picture of the advanced level of information security standards we hold.
Growing the Order of Mostlies
All this wouldn’t be possible without MOSTLY AI’s most important asset – our team (or Mostlies as we like to call them). In 2021, we welcomed quite a few new Mostlies to the team - amongst them new executives to strengthen our product, marketing and sales activities.
The first one to join the team this year was Andreas Ponikiewicz as our Vice President of Global Sales, who took the lead for MOSTLY AI's international sales team across Europe, North America and Asia and has brought our communication with the clients to the next level. Shortly afterward, we welcomed our new CTO, Kerem Erdem, onboard. As a true captain, he is leading us on the way to accelerate our tech performance and enable organizations to thrive in an ethical, responsible way with smart and safe synthetic data. To help get the word out, in early May, Sabine Klisch joined the team as VP Global Marketing and is now leading our creative marketing team on our journey to position MOSTLY AI as the global leader for smart synthetic data. And to spice up the story even more, we have added a special Italian ingredient – Mario Scriminaci, our new CPO who is making sure our synthetic data platform is the number one solution and provides our customers with better-than-real data.
The Best Employer Award
As already mentioned, Mostlies are the most important part of MOSTLY AI and it seems we are doing something right since we made it to the top 3 of Great Place to Work and received Austria's Best Employers 2021 award.
The MOSTLY AI team is truly diverse, with more than 15 different nationalities represented. Almost 40 members strong, we are organized in several teams, including data science, engineering, product, marketing, sales, and operations. The majority of us are based at our headquarter in Vienna, but an increasing number are working remotely spread across the entire world. What has started as a necessity because of COVID-19 has now become an integral part of our company culture.
Looking back, we can say this year has exceeded our expectations by far. One team of devoted professionals all united with the same vision – to empower people with data and build a smarter and fairer future together.
What’s next? 2022 is said to be the year of synthetic data. According to Gartner, by 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated. 2022 will also be the year of MOSTLY AI and we will have exciting news to share with you very soon.
Stay up to date with all things synthetic data!
If you want to stay in the loop with the latest developments in the world of synthetic data, join our newsletter group for monthly updates.