Best practices
Welcome to the MOSTLY AI Synthetic Data Platform’s best practice guide, your essential roadmap for creating top-tier synthetic data. The ability to craft high-quality synthetic datasets is a invaluable asset across numerous fields. From powering machine learning innovations to bolstering software testing and safeguarding data privacy, synthetic data stands as a robust and secure alternative to traditional data sets.
This guide is designed to unlock the full capabilities of MOSTLY AI for you, ensuring you not only master the platform’s configuration for your unique requirements but also discover valuable insights, helpful tips, and common pitfalls to steer clear of. We’re here to equip you with the expertise and tools necessary to excel with our product.
Let’s dive into the essential concepts of the MOSTLY AI Synthetic Data Platform to set the foundation for your success.
Crawl, walk, run
In this guide, you can learn how to master generative AI tabular synthesis. We start by addressing easy concepts first, iterate on data structure and configuration, and master the data quality at the end. We call this the crawl, walk, run approach. In all the different sections we will learn how to make the first steps, be steady, and finally run.
Crawl
Starting small is the goal. We begin by scaling down various dimensions - from dataset size to training duration and table count to column numbers. This initial phase is about getting comfortable with the platform’s capabilities and gradually expanding your expertise into more intricate scenarios.
- Start with manageable data: Dive into the MOSTLY AI world with compact datasets. This first step is crucial for grasping the fundamentals - from how you input data to tweaking the settings. A single subject table with a handful of columns is your playground here, allowing you to grasp the core concepts without being overwhelmed.
- Quick training for rapid insights: Use swift training cycles to adapt and fine-tune your strategies. Even brief training sessions can yield synthetic data that closely mirrors the statistical properties of your original dataset, providing you with immediate, actionable insights. Set the max training time to one minute to iterate fast and check the results without wasting time and resources. The Turbo option in the model configuration is there to quickly set a generator to train fast.
- Focus on configuration and validation: Meticulous attention to your generator’s setup and the thorough validation of results is key. Establishing the reliability of your synthetic data now lays a strong foundation for tackling more complex challenges ahead.
By starting small and focusing on the essentials, you’ll become adept at using MOSTLY AI and start to see the potential and trustworthiness of synthetic data right from the start. This approach ensures a smooth transition to more sophisticated applications as your confidence and understanding grow.
Walk
With a solid grasp of the basics, we gradually increase the complexity of our datasets and extend the depth of our analyses. This phase is about refining skills and pushing the boundaries of what we’ve learned, preparing us for more advanced synthetic dataset.
- Expand dataset complexity: In the crawl phase, we used a simple dataset. Now we can start adding a multi-sequence time-series table - like a table containing event data of our subject - and venture into more complex datasets incorporating a greater variety of columns. Each step forward allows you to explore new facets of synthetic data generation and how it can be tailored to meet specific needs.
- Increase training time: If in crawl phase, setting a max training time to one minute helped us to iterate fast, we can now increase the training time but still not wait for hours! Increase the max training time to ten minutes and set the max sequence window model parameter to ten. The longer training time enable the generative model to capture deeper patterns and relationships on the more complex dataset, leading to synthetic datasets with enhanced fidelity and usefulness.
- Sharpen focus on data quality: Use the generated synthetic dataset for your downstream use case. Either training a machine learning model (see Evaluate synthetic data quality using downstream ML) or creating dashboards and analyses.
Run
Finally, we are ready to take off. It’s time to fully unleash the potential of synthetic data generation with MOSTLY AI. The “Run” phase is where you confidently integrate and apply everything learned, tackling large-scale, complex projects and sharing your generators with others!
- Collaborate and share: A generator is a trained generative AI model on your tabular data. You can learn from it by conditionally generating data with new distributions, pushing the synthetic dataset into the new environment without any privacy concerns, and, most importantly, you can share this knowledge with other people! Generative AI tabular synthetic data unleashes innovation and collaboration. Be sure to share your generator with your organization.
- Deliver: You can push the data into a new environment while configuring a new synthetic dataset. You can always download synthetic data directly from the synthetic dataset page and push the synthetic data on a destination connector.
- Explore advanced configurations: Now that you have mastered the generative tabular data synthesis, you can try new advanced options, like different encoding types, multi-table generation, seed generation, and many more. Check the Training & Generation section to learn more!
Now that you mastered the “Run” phase, you’re not just producing synthetic data. You become an architect of sophisticated, privacy-conscious data ecosystems that not only fuel innovation but also pave the way for informed, strategic decision-making across the board.
Subject and Linked Tables
In the realm of synthetic data generation with MOSTLY AI, understanding the architecture of subject and linked tables is pivotal. These elements serve as the cornerstone for maintaining data integrity and privacy while ensuring the utility of the synthetic dataset.
Subject table
Imagine consolidating diverse personal details into a secure, organized format. Each individual or entity in your dataset is a ‘subject,’ encapsulated within a subject table. This table acts as a confidential repository, where each row is akin to a personal dossier detailing key attributes such as name, demographics, and other sensitive information, all while guaranteeing privacy in its synthetic counterpart.
A row in this table represents the profile of one customer. It’s like having a separate card for each customer, where you jot down their name, gender, height, address, and income. Each piece of information you write on these cards is a field.
Best practices
- Optimal subject table size: For enriched data quality, we advocate for subject tables to encompass a minimum of 5,000 subjects. This volume fosters a robust dataset, conducive to generating high-quality synthetic data. Nevertheless, MOSTLY AI is designed with flexibility in mind, adeptly handling smaller datasets down to 100 subjects. While smaller datasets may present challenges in data quality, they offer a valuable opportunity to explore the platform’s capabilities and ascertain the feasibility of your specific use case.
- Uniqueness: Each subject in your table should be a mirror to a unique, real-world individual or entity, ensuring a one-to-one correspondence that enhances data clarity and utility.
- Data integrity: Uphold the principle of singularity by avoiding duplicate records for the same subject. A singular row should encapsulate the entirety of a subject’s information. If your table contains multiple rows referring to the same subject, most likely it is not a subject table.
- Row independence: Maintain the independence of each data row; the arrangement of rows is inconsequential, preserving the standalone value of each data point without interdependencies.
- Privacy-conscious naming: Select column names with privacy in mind, a practice that extends to all table types within your dataset. Column names do not contain privacy-sensitive information. This is recommended for all kinds of tables (incl. linked tables).
Tips and tricks
- Crawl: At the beginning, you can select a subset of the columns of your subject and be sure to train with the Turbo option. A fast iteration on the training can help you master the right configuration in a couple of minutes.
Linked table
Think of a linked table as a map that links events to the people they belong to. For example, imagine you are tracking orders in an online store. Each order is an event, and it is connected to a specific customer. This connection is like a thread that ties the event (order) to the customer (subject). Each customer might have more than one order. MOSTLY AI can manage multi-sequence time-series table. It meas that the table contain a time-series (a sequence of events) for multiple subjects.
Best practices
- Each record in the linked table must include the unique ID of the subject record it is linked to (foreign key).
Example
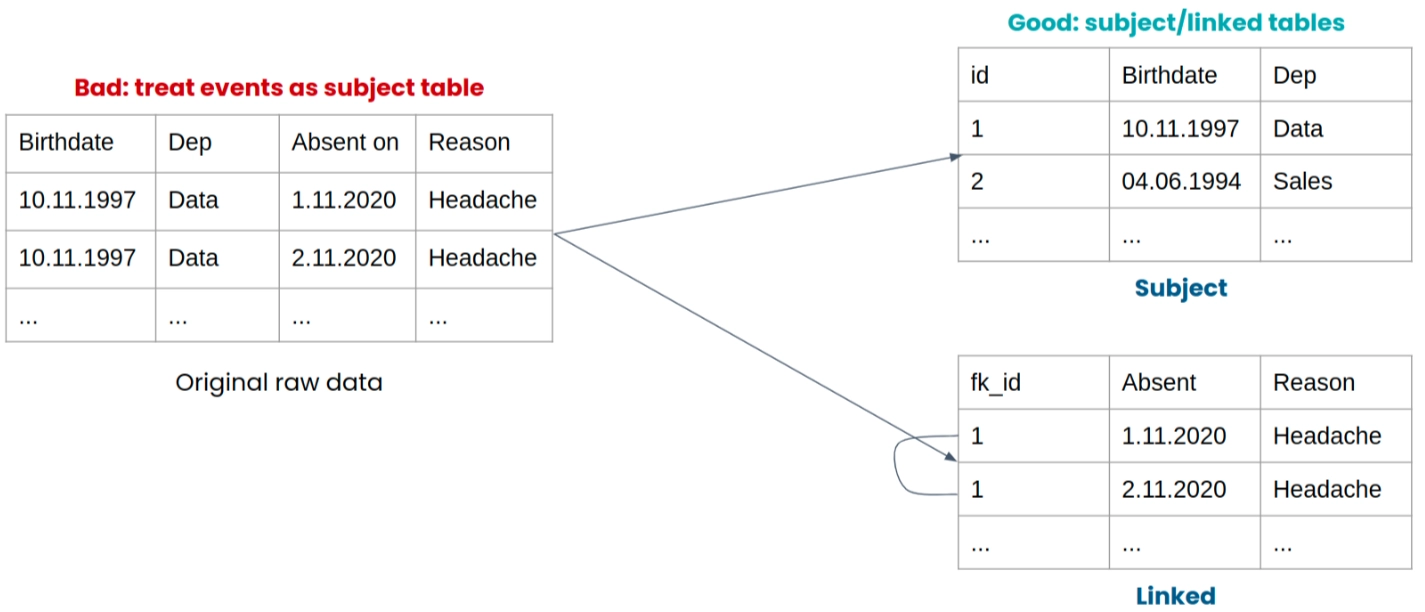
When splitting a table into subject and linked tables, careful data pre-processing is essential to maintain data integrity and privacy. Follow these steps to effectively separate your data and create organized subject and linked tables:
- Identify Unique Subjects: Identify the unique individuals or entities in your dataset. Each distinct individual or entity should have its own row. Remove any duplicate records that might describe the same individual or entity multiple times.
- Extract Subject Information: Create a subject table by extracting all the attributes that relate to the individuals or entities. These attributes should include privacy-sensitive information such as names, genders, addresses, and any other relevant details that define each subject.
- Create linked table: Identify events or actions associated with each subject. Create a linked table that connects each event to the respective subject. In the example below, if you’re tracking employees’ absences, each absence will be linked to a specific employee.
- Privacy-Conscious Column Names: Ensure that column names in both the subject and linked tables do not contain privacy-sensitive information. Column names should be non-identifiable and not compromise privacy.
- Minimum Subject Table Size: Aim for a subject table with at least 5,000 subjects to achieve good data quality. However, the platform can work with smaller subject tables, but the synthetic data quality might vary based on the dataset.
- Validation and Quality Assurance: Before proceeding with model training and data synthesis, thoroughly validate your subject and linked tables. Check for any inconsistencies, duplicate records, or missing information.
Tips and tricks
- Crawl: Start with just the subject table to ensure the synthetic data’s privacy and quality with MOSTLY AI. Once confident, incorporate the linked table for a more comprehensive dataset, easing into the platform’s full capabilities.
- Walk: Begin with smaller data sets and incrementally add more data when using linked tables. This strategy improves model training efficiency. Remember, larger datasets don’t always mean better results; beyond a point, more data doesn’t add much value and can waste resources. Use ten rows as max sequence window. You can set this quickly by selecting the Speed preset.
Encoding types
Selecting the right encoding type for each column can be important when setting up your data for MOSTLY AI’s generative model. MOSTLY AI smartly recognizes Numeric, Categorical, and Datetime types, but others might require your input. This guide highlights various encoding options tailored to diverse data types like text, numbers, categories, or geolocation. Mastering these encoding techniques is key to training a top-notch synthetic data generator with MOSTLY AI.
Geolocation
To generate geolocation coordinates, use the Latitude, Longitude encoding type.
MOSTLY AI needs geolocation coordinates to be represented in a single field with comma-separated latitude and longitude values. You can find the details on the required format here.
Helper Code
Assume you have a geolocation dataset with the following structure, where Latitude and Longitude are stored in a separate column:
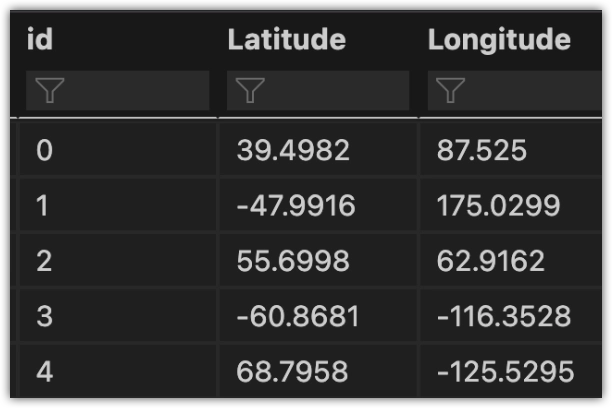
You would need to perform some pre-processing to bring the dataset to MOSTLY AI’s required structure. Below you can find the Python code to do so:
df["LatLong"] = df["Latitude"].astype(str) + ',' + df["Longitude"].astype(str)Now the structure of the dataset should look like this:
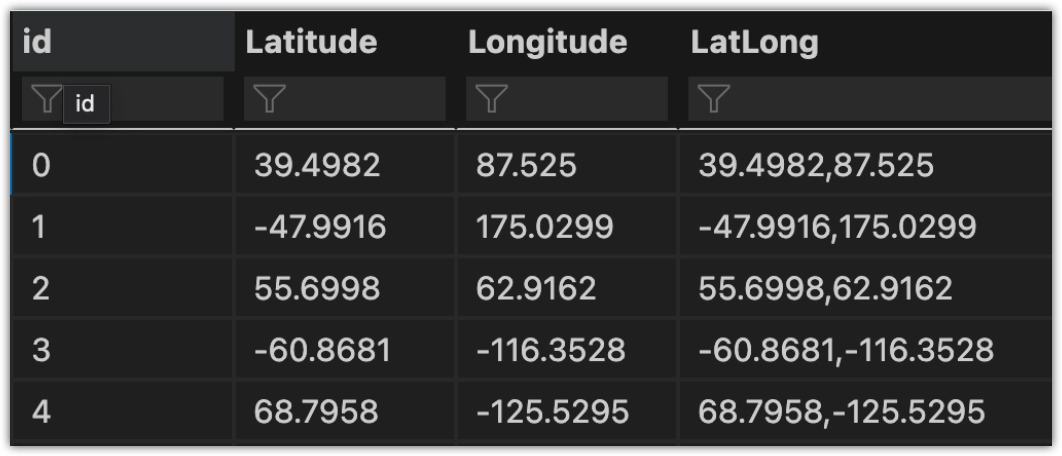
You may opt to remove the ‘Latitude’ and ‘Longitude’ columns from the dataset or not include them through the UI at the Data Settings tab.
Text
Best practices
To be able to generate high-quality text data MOSTLY AI requires getting input from as many as possible data points. We recommend having at least 5,000 number of records containing text of up to 1,000 characters long. The better the quality of the text in the original data the higher the quality of the synthetic text MOSTLY AI can generate.
Bear in mind that when configuring a generator having text columns the training time will be significantly increased. MOSTLY AI utilizes a separate generative AI model dedicated to text columns hence the increase in the training times.
Note
Short Text Sequences: For very short text, character sequence encoding, can be advantageous. Character-level encoding is computationally less intense compared to word-level or subword-level encoding methods.
Numeric
High-precision numeric variables will require more training time to complete.
For example:
- Large integers:
19281276121217623232
- High precision float number:
23.8792328356.91013261
If possible and not needed for the specific use case in mind, we first recommend reducing the precision of such variables, e.g.
- Large integers in millions:
1928.11217.6
- Float number with decreased precision:
23.8856.91
If this is not possible, our default numerical type will sort this issue for you.
Numeric - Auto will heuristically select the most appropriate encoding type for each numeric variable. This selection is based on a simple heuristic that considers the following conditions:
- If a numeric variable has less than 100 distinct values and more than 99.9% of values are non-rare, it will be encoded using ‘Numeric Discrete.’
- If a numeric variable has equal to or fewer than three-digit positions, it will be encoded using ‘Numeric - Digit.’
- For all other cases, ‘Numeric - Binned’ encoding will be applied.
In more detail, the three encoding types for numerical variables are:
- Numeric - Digit: The numerical variables will be recognized as numbers
- Numeric - Discrete: In many cases and depending on the use case, numerical variables might be considered categorical variables. Choose this encoding type, if a numeric variable is actually better represented as categorical. Note: With this encoding type our Rare Category Protection feature will not be in use. Instead, we will create all the discrete numerical values.
Examples:- A binary column with 0 and 1 values. This will be a digit but it should be categorical
- Postcode column with values 1234, 4563, 7635, 9836, etc. A postcode doesn’t make sense to be considered a numeric variable. Instead, it should be a category as it reflects a specific area of a city.
- Numeric - Binned: For large integers, MOSTLY AI will bin your numerical column into quantiles and consider these as categories during training. Then from each bin, a number will be sampled to generate the final numerical column in the synthetic dataset.
Example:
Consider you’re working with a dataset containing a numerical column that consists of large integer values, such as “Number of Products Sold.”- Initial Data: Your original dataset includes the “Number of Products Sold” column, which contains a wide range of integer values, from 1,000 to 1,000,000.
- Binning: During preprocessing, MOSTLY AI employs binning. It divides the range of integer values into quantiles, creating several bins that group similar values together. For instance, the bins might be defined as
- “Low Sales”: 1,000 - 10,000
- “Moderate Sales: 10,001 - 100,000 and
- “High Sales”: 100,001 - 1,000,000
- Categorization and Sampling: These bins effectively transform the numerical data into categorical information. The model then treats these categories as distinct during training. For synthetic data generation, the model samples a value from each bin. For instance, it might sample 1,500 from “Low Sales”, 50,000 from “Moderate Sales”, and 900,000 from “High Sales”.
- Synthetic Data: The generated synthetic dataset reflects the same pattern of distribution as the original data but ensures privacy and data protection. The “Number of Products Sold” column in the synthetic dataset now comprises sampled values from each bin, maintaining the overall distribution.
Categorical
High cardinality columns contribute to an increase in training time.
Best Practices
Often low-quality data such as typos in the categories can increase the cardinality of a categorical variable. We recommend solving such issues prior to creating a generator as part of your data preparation step. By doing so, you increase the quality of your synthetic dataset as well.
Example
Imagine that we have a column that holds information about ‘Types of Diabetes’. The correct categories in this case would be:
- Type 1
- Type 2
Instead due to typos in the column’s content, we might see additional categories, such as:
- Type A
- Type B
- Diabetes 1
- 1
- 2
For the above example instead of having two categories, the cardinality of the column is seven.
Synthetic data with different data dimensions
When deploying MOSTLY AI on different virtual machine (VM) sizes and working with different data dimensions, it is essential to understand how these factors can impact accuracy, training times, and overall performance. This section provides insights what to expect from specific VM sizes and manipulating data dimensions, including wide tables, the number of columns, and the number of rows.
Virtual machine size
The performance of MOSTLY AI can vary based on the VM size you deploy to. Different VM sizes offer varying computational resources when it comes to CPU and memory.
- Training times: Larger VM sizes can significantly reduce training times. More resources allow for faster model training, resulting in quicker training iterations. However, balancing the VM size with your budget and the urgency of results is important.
- Generation times: Although data generation does not require as many resources as AI model training, a VM with more compute resources will also result in faster generation times.
Note: The decision what VM size to use depends on your data dimensions. For more information, see the sections below.
Data dimensions
When working with data, particularly wide tables with a varying number of columns and rows, the following considerations apply:
- Wide Tables
Wide tables, with a high number of features or columns, can pose challenges for training. While they offer more information, they can lead to increased model complexity. Reducing your dataset to include only necessary features based on your use case might enhance training efficiency. - Number of columns
The number of columns in your dataset directly impacts the time required for processing and training. More columns lead to longer training times and increased memory usage. We recommend you only include essential features for your use case and avoid unnecessary complexity.- Below 100 Columns: Working within this range is manageable and you will most likely have a smooth processing and training experiences.
- Between 100 and 500 Columns: Within this bracket you might encounter challenges, particularly contingent on encoding types. Some encoding types (such as Text) increase processing times and memory usage.
- Above 500 Columns: We typically do not recommend to synthesize more than 500 columns at once. Instead consider preprocessing steps, such as feature selection, that can help to streamline training efficiency and mitigate potential issues from data complexity.
- Number of Rows
The number of rows in your dataset affects the model’s generalization ability. Larger datasets often lead to better model performance by providing more diverse examples. However, larger datasets also require more data preprocessing and training time.- Subject tables
- Subject tables below 1 million rows are suitable.
- Within the 1-10 million range, encoding types can impact performance. Consider using the sampling feature to only work with a subset of the data.
- Beyond 10 million, sampling becomes a viable strategy to ensure manageable processing and training.
- Linked tables
- Linked tables typically contain time-series data where every row describes a unique event.
- One or more rows from a linked table can refer to a subject row in a subject table. (From now on, we call this a sequence). Because of this, linked tables take longer to train and generate.
- No limitations exist on the length of sequences. The longer the average sequence is, the longer it will require to generate the sequence, while the training time is independent of it.
- Subject tables
- Number of tables
- The number of tables within your dataset influences the synthetic data generation. As the number of tables increases, factors like processing time, model complexity, and training duration come into play. Balancing dataset richness and the potential challenges associated with multiple tables is essential.
- Processing Time Impact: More tables extend the time required to generate synthetic data. The complexity of managing inter-table relationships and correlations contributes to this effect.
- Inter-Table Correlations: When tables are related, the model aims to capture and maintain these correlations between the tables. Consequently, model complexity increases, leading to prolonged training times.
- To avoid such a scenario, we suggest evaluating the necessity of each table. Consider whether merging certain tables can streamline data processing and training without sacrificing critical insights.
Note:
Remember that every dataset is unique and context matters. Prioritizing essential features ensures your model’s efficacy without being hindered by unnecessary complexity. By adhering to such considerations, you can navigate the training process more effectively, optimizing resources and maximizing insights.
Optimization
Here is how you can achieve best results when working with different VM sizes and data dimensions.
- Experimentation: It is recommended to experiment with various VM sizes, especially during the model training phase. Assess how accuracy and training times evolve with different resources, then decide what VM size you want to employ. Always balance the VM size with your budget and the urgency for results.
- Data Sampling: Consider data sampling techniques for large datasets to create manageable subsets for initial experimentation. This can help to test different configurations without spending excessive time on training or resources.
Note:
- Adding more computational resources will not necessarily reduce training times or increase the accuracy or quality of the synthetic dataset.
- Data sampling and reducing the size might also work against privacy. More data will work better with our privacy protection mechanisms.
- You may calculate the estimated cost of a machine in the cloud using the different cost calculators provided by the main cloud providers:
- Azure
- GCP
- AWS
Examples
Example 1:
- VM Size: 64 CPUs, 256 GB RAM, 4 worker nodes
- Data:
- Number of tables: 2
- Subject table:
- Number of rows: 5,000
- Number of columns: 16
- Linked table:
- Number of rows: 1,037,854
- Number of columns: 15
- Average sequence length: 207.5
- Training time:
- Subject table: 1min
- Linked table: 15 hrs
- Estimated cost using AWS calculator
- EC2 Instance: m5a.16xlarge
- On-Demand Hourly Cost: 2.752 USD
- Total on-demand cost of the job: 41 USD
Example 2:
- VM Size: 12 CPUs, 128 GB RAM, 4 worker nodes
- Data:
- Number of tables: 2
- Subject table:
- Number of rows: 5,000
- Number of columns: 16
- Linked table:
- Number of rows: 1,037,854
- Number of columns: 15
- Average sequence length: 207.5
- Training time:
- Subject table: 1min
- Linked table: 90 hrs
- Estimated cost using AWS calculator
- EC2 Instance: r6g.4xlarge
- On-Demand Hourly Cost: 0.8064 USD
- Total on-demand cost of the job: 72 USD
QA Report
Remediating privacy and accuracy issues
Identifying the source of data quality or privacy issues can be very difficult. Below is a list of common issues.
Accuracy
| | | | — | — | | Bad univariate fit | High number of N/As | | High amount of rare category labels | Incorrect encoding type | | High number of business rules violations | Training goal is set to Speed or Turbo instead of Accuracy |Privacy
- High amount of
NaNcan make the Identical match share fail. - Privacy tests can contain false positives because of sampling and stochastic tests.
- In case of good accuracy, repeating a synthesization and testing privacy again makes sense.
Spotting potential issues
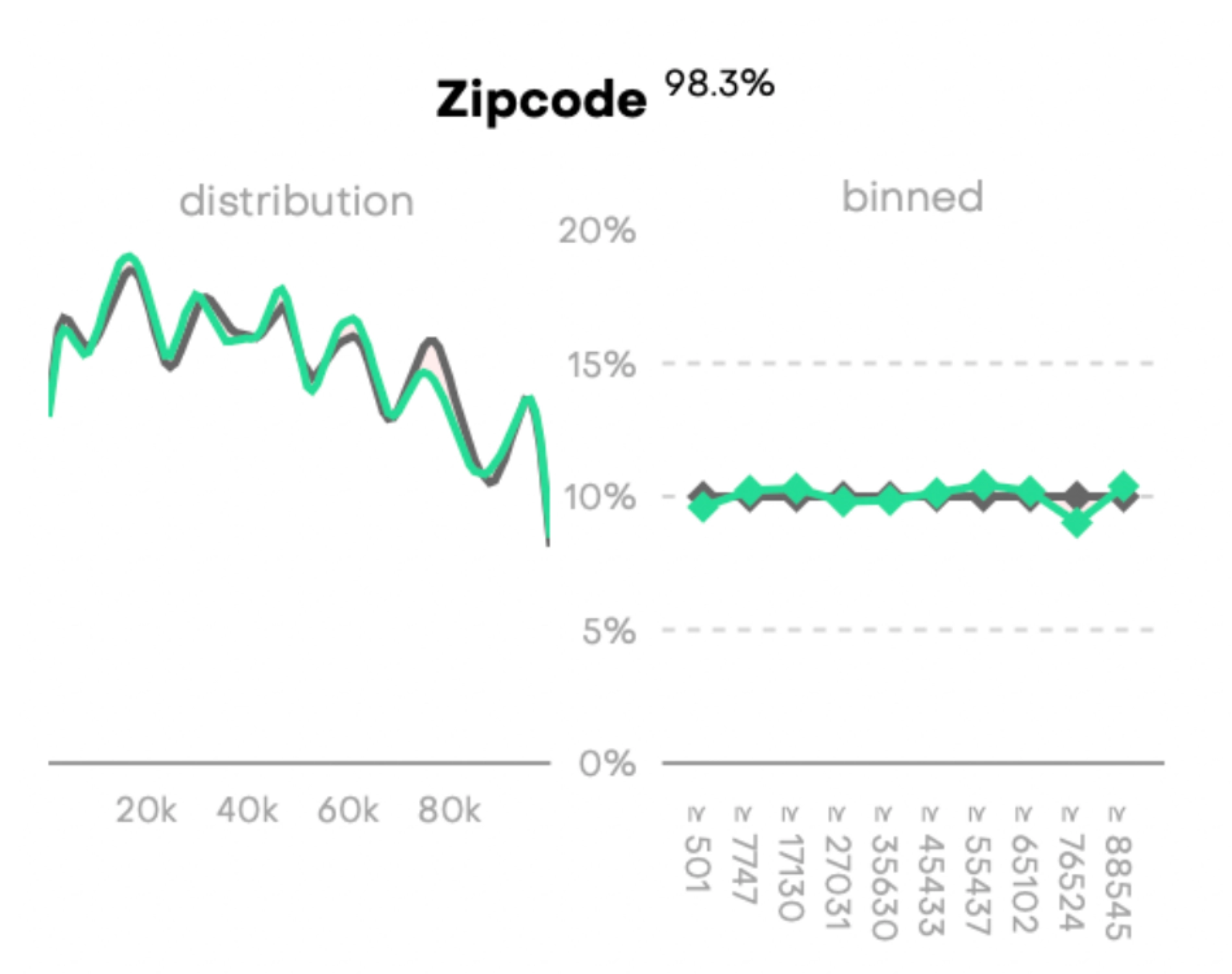
Numerical encoding of categorical values
Values, such as ZIP codes, can be indistinguishable from continuous values. This results in the generation of invalid ZIP codes and difficult-to-learn business rules.
The solution is to change the encoding type to Categorical.
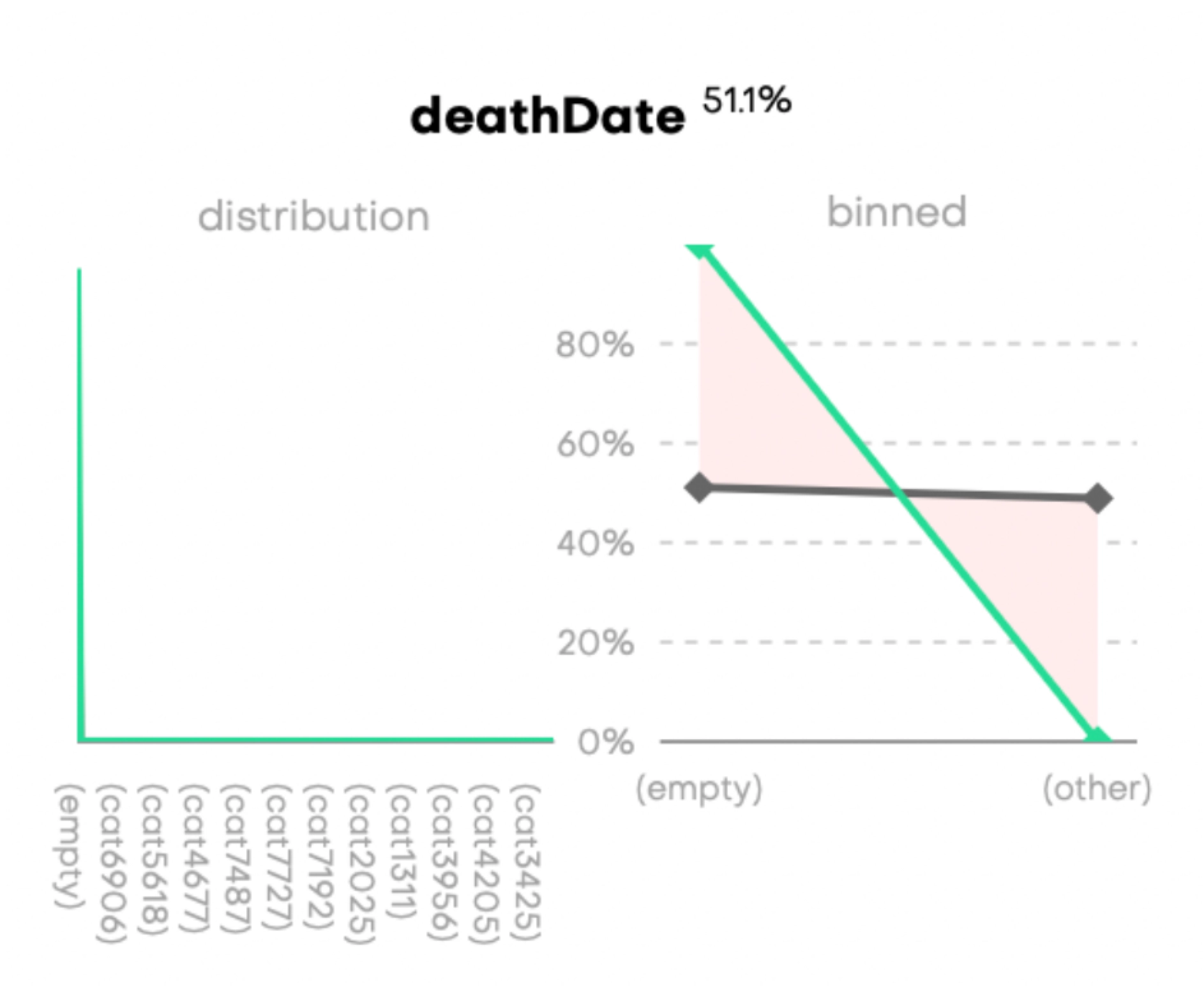
Incorrect datetime format
Incorrect formatting of a date column results in it being encoded as a categorical column. Below is an example of an incorrectly formatted, and thus incorrectly encoded, deathDate column.
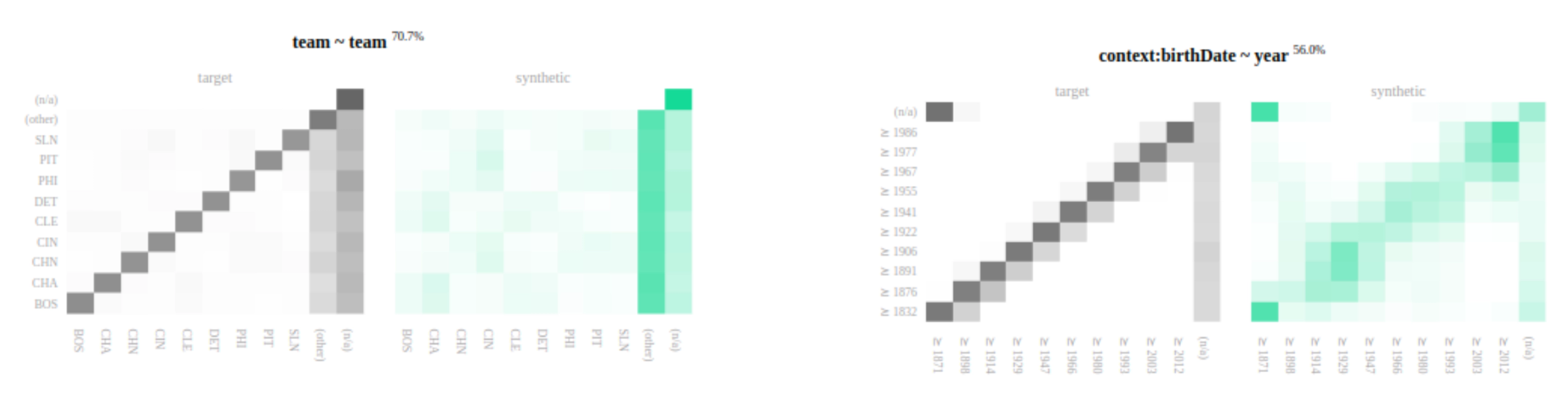
Bivariate relationships are lost
If the bivariate relation between two columns is lost (left example) or weakened (right example) in the synthetic data, MOSTLY AI recommends that you increase the number of training samples, and ensure that the training goal is set to Accuracy.