
Co-Authors: Alexandra Ebert & Daniel Soukup
In the age of digitalization and the rise of artificial intelligence, more and more tasks in public and private organizations are managed or supported by computers and machine learning algorithms.
These include tasks such as data analysis, automated decision making, customer interaction services such as automated emails or chatbots, and recommendation systems. In general, we believe this is a good thing, as machine learning algorithms are fast, scalable, and can analyze way more complex data structures than humans. For example, there are studies showing that the adoption of automated underwriting in mortgage lending contributed to the increase of approval rates for minority and low-income applicants by 30% while improving the overall accuracy of default predictions.
However, machine learning algorithms typically require lots of training data and when this data contains sensitive information about real people, the stakes become extremely high. Two risks involve the violation of privacy and fairness: disclosing sensitive personal information and treating people unjustly during the decision-making process.
There are many well-documented cases of biased decision making that triggered an ongoing discussion about algorithmic fairness. A famous example is Google’s hate speech-detection algorithm that discriminated against African Americans. Researchers at the University of Washington found, that the algorithm was more likely to label their tweets as “hateful” or “offensive”. Not only was it biased against people of color, but also, as another study demonstrated, against well-known drag queens. Another case of bias in Artificial Intelligence was Amazon’s HR algorithm. The system was fed with 10 years worth of records of previous – and predominantly male – Amazon employees and thereby learned that being female poorly correlated with being a suitable candidate for a job at the tech company.
Now, in the cases above, algorithms systematically discriminate against a group based on its gender, race, or sexual orientation. If not addressed, these systemic biases end up in data sets that decision-making algorithms are trained on. Subsequently, the biased algorithms make unfair decisions, perpetuating, and actually amplifying the biases in our society.
We at MOSTLY AI believe in the positive powers of artificial intelligence to foster research and innovation. We will demonstrate that bias-corrected synthetic data can address both privacy and fairness concerns to allow for utilizing and democratizing big data assets while keeping the risks at a minimum. The current post will give a high-level overview of our work and in post 5 of our Fairness Series, we will discuss more technical aspects of our results as well as make our fair synthetic data sets available.
Read the other parts of the series:
- Part 1 - Why Bias in AI is a Problem & Why Business Leaders Should Care
- Part 2 - 10 Reasons For Bias In AI And What To Do About It
- Part 3 - We Want Fair AI Algorithms – But How To Define Fairness?
- Part 5 - Diving Deep Into Fair Synthetic Data Generation
From Privacy Protection To Promoting Fairness in AI
Our synthetic data platform, enables organizations to generate highly accurate, statistically representative synthetic data at scale such as synthetic customer records along with purchase histories. The software functions as an unlimited source of artificial individuals who have interacted with your business the same way as real people did historically. The synthetic data, however, can be shared safely without privacy concerns since these artificial people do not really exist and the privacy of your actual customers, the real data subjects, remains protected.
Synthetic data generation doesn’t need to stop at privacy protection though. As we generate the data from scratch, we can model and shape it to fit different needs. A beautiful example of this is NVIDIA’s styleGAN, where a conditional generation of synthetic images allows for adding smiles or sunglasses to faces, or changing hair and skin color.
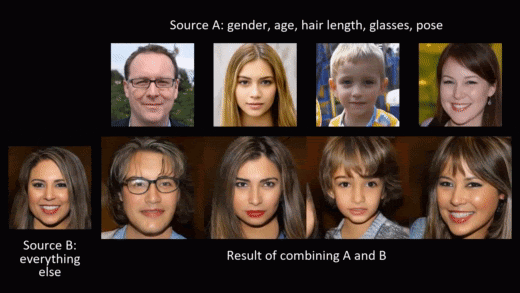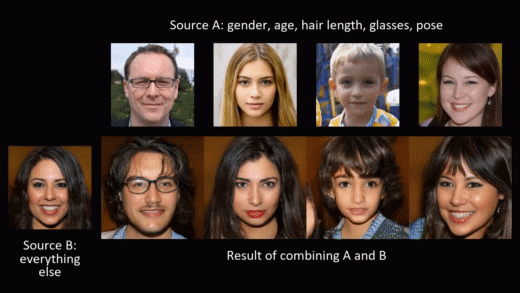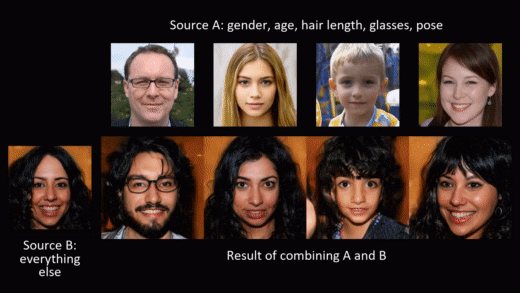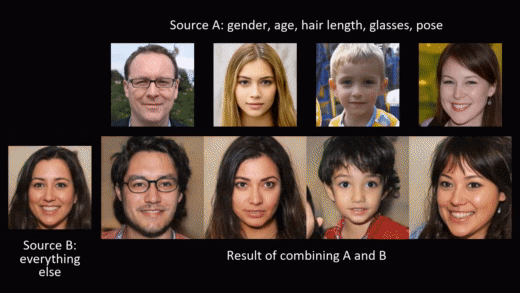
In this blog post, we want to leverage the possibility of modeling and shaping synthetic data to mitigate the second risk mentioned in the introduction: violation of fairness. The result is fair synthetic data that is fully anonymous and de-biased (in accordance with a specific fairness definition).
To Get Fair Synthetic Data You Need To Start With A Fairness Definition
Imagine a perfect world without any biases and discriminations, where attributes such as skin color or sex do not influence people’s lives either in a good nor a bad way. In such a world, the fraction of women among top management positions would equal those of men. Similarly, the fraction of women earning more than $50,000 per year would equal that of men and the fraction of African-Americans in US prisons would be the same as the fraction among Caucasians. This property comes under the name of statistical or demographic parity. The plot below shows how demographic parity is violated in the Adult US census data set with respect to gender and income.
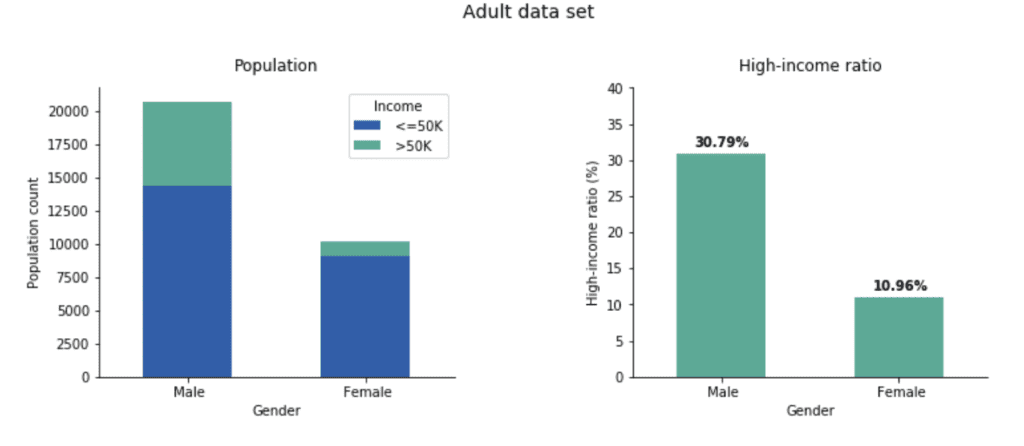
Statistical parity is a very intuitive fairness measure and, in a perfect world with equal opportunities for everybody, it would be satisfied. There are many other, equally viable metrics but keep in mind that there is no single equation or approach that will perfectly fit vastly different scenarios. To truly address and derive actionable insight against bias, one needs a deep understanding of the underlying issues in each use-case. What we developed here is a flexible framework to generate synthetic data that satisfies fairness with respect to a given metric, focusing on parity for now and exploring other measures in a subsequent study.
How To Create A Fair Synthetic Dataset?
There are three points in the machine learning life cycle where you can mitigate bias: at the source, by changing your input data; during the modeling phase by using additional fairness constraints; and as a post-processing step, by revising the algorithm’s decisions in favor of a sensitive group. Naive data-level techniques, such as oversampling methods, have the risk of skewing important data distributions when mitigating imbalances. Our approach is a sort of hybrid, using fairness constraints on a generative model to produce fair synthetic data.
Now, the main objective of our Synthetic Data Platform is to generate new, synthetic data that is as accurate and as representative as the original data set. Under the hood, the software leverages deep neural networks that are trained to optimize an accuracy loss: this simply measures how well our model is reproducing the statistical distributions of the real data. Now, in order to get fair data, we can add a fairness constraint to this optimization step. To stick with the income example, for every mini-batch of data that enters during training, we penalize the violation of statistical parity by a number that is proportional to the difference between the fraction of women and the fraction of men in the high-income segment. We then adapt the model parameters with the objective to minimize both the accuracy loss and fairness constraint.
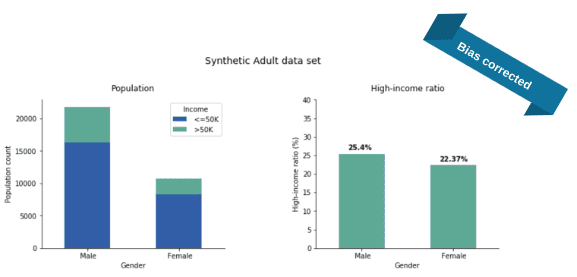
Using this approach, we successfully removed the income inequality with respect to gender from the synthetic version of the Adult data set. We did this with very little compromise on other aspects of data accuracy: for example, you can see we preserved the original Male/Female ratio perfectly.
How Organizations Can Benefit From Private And Fair Synthetic Data
One of our main motivations in working on fair synthetic data generation is the following scenario: imagine Got Big Data Company, a conscientious organization that aims to develop a new predictive model. To do so, they ask the help of a 3rd party vendor, SmartUp AI, and until recently, such collaborations involved allowing access to their sensitive database. Moreover, if Got Big Data Company wanted to address data bias then it required rather special know-how on the developer’s side. Here enters fair synthetic data: Got Big Data Company first generates a synthetic and hence private version of their original data set which is also fair with respect to the modeling task at hand. Next, the vendor, SmartUp AI, develops the predictive model on the synthetic data, just as they would for any task without having to be concerned about bias correction on their end. Then, these models are handed back to Got Big Data Company for use on actual customer data.
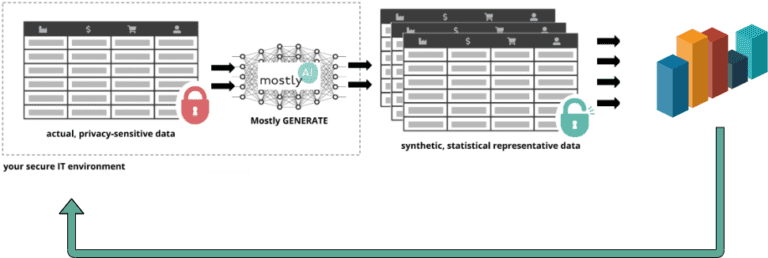
using the synthetic data ⇒ evaluate and deploy on real data.
We find that out-of-the-box predictive models trained on fair synthetic data treat the classes of the sensitive attribute near equally (e.g., female and male). This fair outcome is solely due to using parity-corrected synthetic data, there are no fairness constraints of the predictive models. In the next article, we will release our parity-corrected synthetic data and dive into the technical details of our approach and analysis of the generated data.
Conclusions
There are many inherent risks in automated decision making and in the use of data sets that do not reflect the world we strive to live in. Historical and measurement biases skew predictive models which in turn affect millions of people who are applying for loans or submitting job applications. As data scientists, engineers, and business leaders, we are responsible to address these issues as best as we can. At Mostly AI, we offer a two-in-one tool to utilize data sets that are often sensitive and biased at the same time. First, our fair synthetic data can be safely shared without leaking personal information. Second, having addressed bias-mitigation at the synthetic data generation phase, it enables organizations to utilize existing analytics and modeling pipelines without the need for costly anti-discrimination modifications. To learn more about how fair synthetic data is generated, continue with part 5 of our Fairness Series.


