
The world is changing, and anonymous data is not anonymous anymore
In recent years, data breaches have become more frequent. A sign of changing times: data anonymization techniques sufficient 10 years ago fail in today's modern world. Nowadays, more people have access to sensitive information, who can inadvertently leak data in a myriad of ways. This ongoing trend is here to stay and will be exposing vulnerabilities faster and harder than ever before. The disclosure of not fully anonymous data can lead to international scandals and damaged reputation.
Most importantly, customers are more conscious of their data privacy needs. According to Cisco's research, 84% of respondents indicated that they care about privacy. Among privacy-active respondents, 48% indicated they already switched companies or providers because of their data policies or data sharing practices. And it's not only customers who are increasingly suspicious. Authorities are also aware of the urgency of data protection and privacy, so the regulations are getting stricter: it is no longer possible to easily use raw data even within companies.
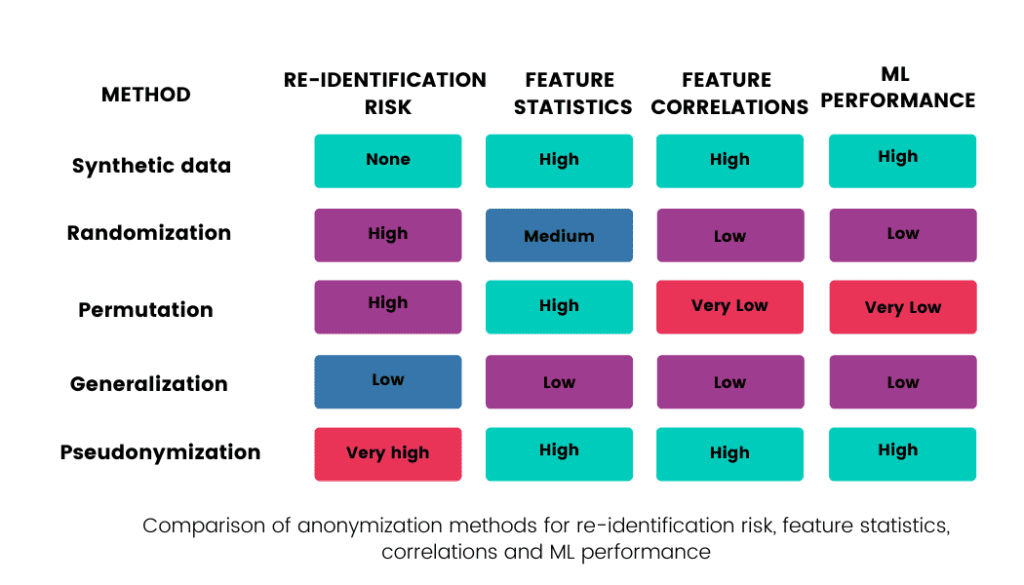
This blogpost will discuss various techniques used to anonymize data. The following table summarizes their re-identification risks and how each method affects the value of raw data: how the statistics of each feature (column in the dataset) and the correlations between features are retained, and what the usability of such data in ML models is.
#1 Pseudonymization is not anonymization
The EU launched the GDPR (General Data Protection Regulation) in 2018, putting long-planned data protection reforms into action. GDPR's significance cannot be overstated. It was the first move towards an unified definition of privacy rights across national borders, and the trend it started has been followed worldwide since. So what does it say about privacy-respecting data usage?
First, it defines pseudonymization (also called de-identification by regulators in other countries, including the US). Based on GDPR Article 4, Recital 26: "Personal data which have undergone pseudonymisation, which could be attributed to a natural person by the use of additional information should be considered to be information on an identifiable natural person." Article 4 states very explicitly that the resulting data from pseudonymization is not anonymous but personal data. Thus, pseudonymized data must fulfill all of the same GDPR requirements that personal data has to.
Why is pseudonymization dangerous?
Imagine the following sample of four specific hospital visits, where the social security number (SSN), a typical example of Personally Identifiable Information (PII), is used as a unique personal identifier.

The pseudonymized version of this dataset still includes direct identifiers, such as the name and the social security number, but in a tokenized form:

Replacing PII with an artificial number or code and creating another table that matches this artificial number to the real social security number is an example of pseudonymization. Once both tables are accessible, sensitive personal information is easy to reverse engineer. That's why pseudonymized personal data is an easy target for a privacy attack.
How about simply removing sensitive information?
For data analysis and the development of machine learning models, the social security number is not statistically important information in the dataset, and it can be removed completely. Therefore, a typical approach to ensure individuals’ privacy is to remove all PII from the data set. But would it indeed guarantee privacy? Is this true data anonymization?
Unfortunately, the answer is a hard no. The problem comes from delineating PII from non-PII. For instance, 63% of the US population is uniquely identifiable by combining their gender, date of birth, and zip code alone. In our example, it is not difficult to identify the specific Alice Smith, age 25, who visited the hospital on 20.3.2019 and to find out that she suffered a heart attack.
These so-called indirect identifiers cannot be easily removed like the social security number as they could be important for later analysis or medical research.
So what next? Should we forget pseudonymization once and for all? No, but we must always remember that pseudonymized data is still personal data, and as such, it has to meet all data regulation requirements.
#2 Legacy data anonymization techniques destroy data
How can we share data without violating privacy? We can choose from various well-known techniques such as:
- Permutation (random permutation of data)
- Randomization (random modification of data)
- Generalization
Permutation - high risk of re-identification, low statistical performance
We could permute data and change Alice Smith for Jane Brown, waiter, age 25, who came to the hospital on that same day. However, with some additional knowledge (additional records collected by the ambulance or information from Alice's mother, who knows that her daughter Alice, age 25, was hospitalized that day), the data can be reversibly permuted back.
We can go further than this and permute data in other columns, such as the age column. Column-wise permutation's main disadvantage is the loss of all correlations, insights, and relations between columns. In our example, we can tell how many people suffer heart attacks, but it is impossible to determine those people's average age after the permutation.

Randomization - high risk of re-identification, low statistical performance
Randomization is another old data anonymization approach, where the characteristics are modified according to predefined randomized patterns. One example is perturbation, which works by adding systematic noise to data. In this case, the values can be randomly adjusted (in our example, by systematically adding or subtracting the same number of days to the date of the visit).
However, in contrast to the permutation method, some connections between the characteristics are preserved. In reality, perturbation is just a complementary measure that makes it harder for an attacker to retrieve personal data but doesn’t make it impossible. Never assume that adding noise is enough to guarantee privacy!

Generalization - low risk of re-identification, low statistical performance
Generalization is another well-known data anonymization technique that reduces the granularity of the data representation to preserve privacy. The main goal of generalization is to replace overly specific values with generic but semantically consistent values. One of the most frequently used techniques is k-anonymity.
K-anonymity prevents the singling out of individuals by coarsening potential indirect identifiers so that it is impossible to drill down to any group with fewer than (k-1) other individuals. In other words, k-anonymity preserves privacy by creating groups consisting of k records that are indistinguishable from each other, so that the probability that the person is identified based on the quasi-identifiers is not more than 1/k. In our example, k-anonymity could modify the sample in the following way:

By applying k-anonymity, we must choose a k parameter to define a balance between privacy and utility. However, even if we choose a high k value, privacy problems occur as soon as the sensitive information becomes homogeneous, i.e., groups have no diversity.
Suppose the sensitive information is the same throughout the whole group - in our example, every woman has a heart attack. In such cases, the data then becomes susceptible to so-called homogeneity attacks described in this paper. The authors also proposed a new solution, l-diversity, to protect data from these types of attacks.
Nevertheless, even l-diversity isn’t sufficient for preventing attribute disclosure. Another article introduced t-closeness - yet another anonymity criterion refining the basic idea of k-anonymity to deal with attribute disclose risk. Most importantly, all research points to the same pattern: new applications uncover new privacy drawbacks in data anonymization methods, leading to new techniques and, ultimately, new drawbacks.
The privacy-utility trade-off
No matter what criteria we end up using to prevent individuals’ re-identification, there will always be a trade-off between privacy and data value. Data that is fully anonymized so that an attacker cannot re-identify individuals is not of great value for statistical analysis.
On the other hand, if data anonymization is insufficient, the data will be vulnerable to various attacks, including linkage. Although an attacker cannot identify individuals in that particular dataset directly, data may contain quasi-identifiers that could link records to another dataset that the attacker has access to. In combination with other sources or publicly available information, it is possible to determine which individual the records in the main table belong to.
The re-identification process is much more difficult with legacy data anonymization than in the case of pseudonymization because there is no direct connection between the tables. Re-identification, in this case, involves a lot of manual searching and the evaluation of possibilities. Still, it is possible, and attackers use it with alarming regularity. As more connected data becomes available, enabled by semantic web technologies, the number of linkage attacks can increase further.
There are many publicly known linkage attacks. In 2001 anonymized records of hospital visits in Washington state were linked to individuals using state voting records. In one of the most famous works, two researchers from the University of Texas re-identified part of the anonymized Netflix movie-ranking data by linking it to non-anonymous IMDb (Internet Movie Database) users’ movie ratings. Others de-anonymized the same dataset by combining it with publicly available Amazon reviews.
We have already discussed data-sharing in the era of privacy in the context of the Netflix challenge in a previous blog post. The topic is still hot: sharing insufficiently anonymized data is getting more and more companies into trouble. Linkage attacks can have a huge impact on a company’s entire business and reputation. At the center of the data privacy scandal, a British cybersecurity company closed its analytics business putting hundreds of jobs at risk and triggering a share price slide.
The final conclusion regarding anonymization: 'anonymized' data can never be totally anonymous. We can trace back all the issues described in this blogpost to the same underlying cause. All anonymized datasets maintain a 1:1 link between each record in the data to one specific person, and these links are the very reason behind the possibility of re-identification. Moreover, the size of the dataset modified by legacy data anonymization is the same as the size of the original data.
#3 Synthetic data provides an easy way out of the dilemma
Synthetic data doesn't suffer from this limitation. Synthetic data contains completely made up but realistic information, without any link to real individuals. In contrast to other approaches, synthetic data doesn't attempt to protect privacy by merely masking or obfuscating those parts of the original dataset deemed privacy-sensitive while leaving the rest of the original dataset intact. Data synthesis is a fundamentally different approach where the source data only serves as training material for an AI algorithm, which learns its patterns and structures.
Once the AI model was trained, new statistically representative synthetic data can be generated at any time, but without the individual synthetic data records resembling any individual records of the original dataset too closely. Therefore, the size of the synthetic population is independent of the size of the source dataset. In other words, the flexibility of generating different dataset sizes implies that such a 1:1 link cannot be found.
MOSTLY AI's synthetic data platform makes this process easily accessible for anyone. The algorithm automatically builds a mathematical model based on state-of-the-art generative deep neural networks with built-in privacy mechanisms. Our synthetic data platform fits the statistical distributions of the real data and generates synthetic data by drawing randomly from the fitted model. No matter if you generate 1,000, 10,000, or 1 million records, the synthetic population will always preserve all the patterns of the real data.
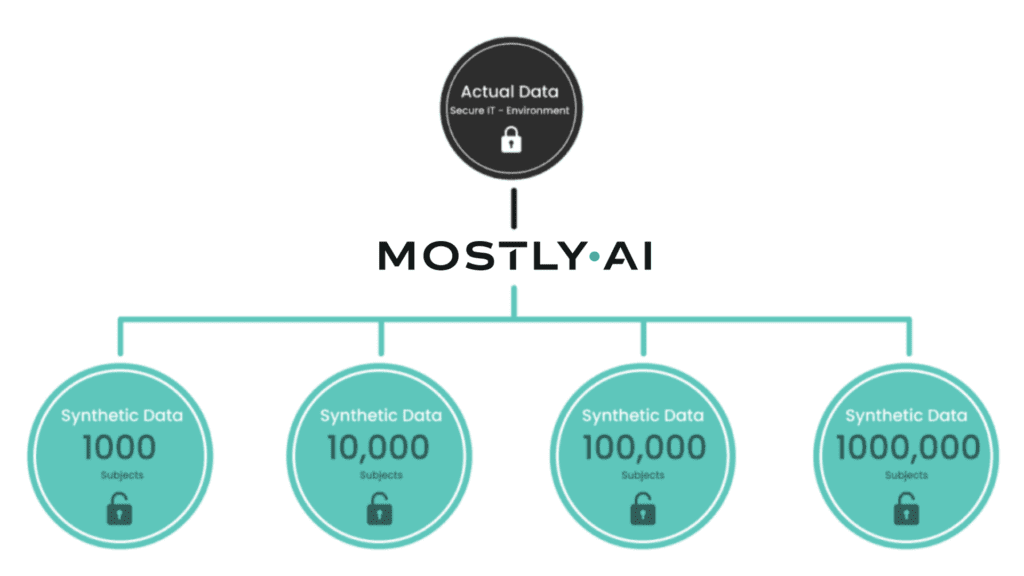
An example of AI-generated synthetic data
Let’s look at an example of the resulting statistics of MOSTLY AI’s synthetic data of the Berka dataset. This public financial dataset, released by a Czech bank in 1999, provides information on clients, accounts, and transactions. The figures below illustrate how closely synthetic data (labeled “synth” in the figures) follows the distributions of the original variables keeping the same data structure as in the target data (labeled “tgt” in the figures).
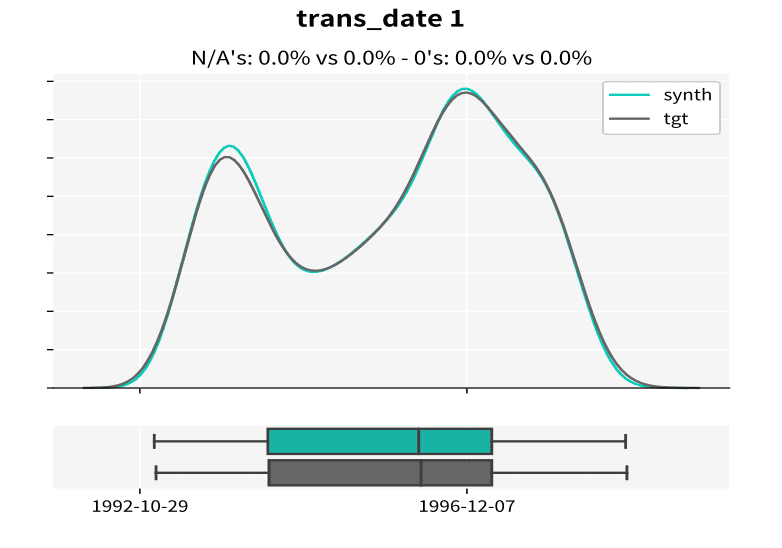
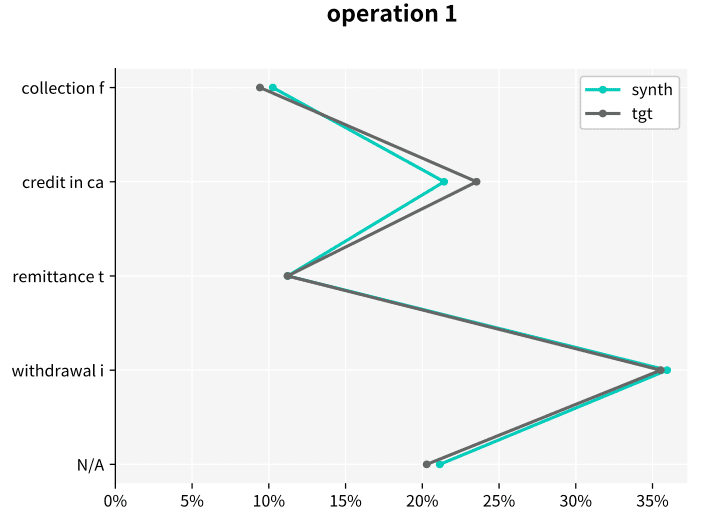
Synthetic data keeps all the variable statistics such as mean, variance or quantiles. Due to built-in privacy mechanisms, synthetic populations generated by MOSTLY AI's synthetic data platform can differ in the minimum and maximum values if they only rely on a few individuals. Keeping these values intact is incompatible with privacy, because a maximum or minimum value is a direct identifier in itself.
For example, in a payroll dataset, guaranteeing to keep the true minimum and maximum in the salary field automatically entails disclosing the salary of the highest-paid person on the payroll, who is uniquely identifiable by the mere fact that they have the highest salary in the company. In other words, the systematically occurring outliers will also be present in the synthetic population because they are of statistical significance. However, the algorithm will discard distinctive information associated only with specific users in order to ensure the privacy of individuals.
Synthetic data is as-good-as-real
The power of big data and its insights come with great responsibility. Merely employing old data anonymization techniques doesn’t ensure the privacy of an original dataset. Synthetic data is private, highly realistic, and retains all the original dataset’s statistical information.
We have illustrated the retained distribution in synthetic data using the Berka dataset, an excellent example of behavioral data in the financial domain with over 1 million transactions. Such high-dimensional personal data is extremely susceptible to privacy attacks, so proper data anonymization is of utmost importance.
Synthetic data has the power to safely and securely utilize big data assets empowering businesses to make better strategic decisions and unlock customer insights confidently. To learn more about the value of behavioral data, read our blog post series describing how MOSTLY AI's synthetic data platform can unlock behavioral data while preserving all its valuable information.


