- Part 1 - Why Bias in AI is a Problem & Why Business Leaders Should Care
- Part 2 - 10 Reasons For Bias In AI And What To Do About It
- Part 4 - Tackling AI Bias At Its Source – With Fair Synthetic Data
- Part 5 - Diving Deep Into Fair Synthetic Data Generation
Equal Treatment Versus Equal Access
In the private as well in the business context we oftentimes strive to achieve fairness by treating everybody exactly the same. An equal amount of chocolate. An equal amount of time to finish a test in school and – in an ideal world – also equal pay regardless of gender or race. The concept behind this is called equality. But what it fails to take into account is that not every one of us starts from the same place and that some might need different support than others do. Imagine three people of divergent height trying to get to the beautifully ripe, red apples on an apple tree. If you were to give a small pedestal to everyone, it would not really improve the situation for the smaller individuals:
Fair AI Requires A Mathematical Fairness Definition
In order to build fair machine learning systems, we need to precisely define and quantify what we mean by a fair outcome. There are several mathematical definitions that do just that and on a high level, these notions fall into two categories: group and individual fairness. Group fairness and parity constraints aim to achieve the same outcomes across different demographics, or more generally, a set of protected population classes. In other words, the population that receives a given assessment by the algorithm (let it be positive or negative) should reflect the whole population and its demographics. We can furthermore require that the types of mistakes the model makes and the severity of these errors should be evenly distributed across the population. These requirements are intuitive, easily applied across domains, and hence are the most widely used, and studied. At the same time, being fair with respect to parity can seem highly unfair from a single individual’s viewpoint. So individual fairness advocates treating similar individuals similarly. The ”Fairness through Awareness” approach is built on first defining a task-specific similarity measure between pairs of data subjects and using that to quantify how close predictions a randomized algorithm should give on two individuals. There are ways to combine group and individual fairness, such as learning fair representations (abstract transformations of the data points into high-dimensional numeric vectors) that could be used in downstream modeling tasks. Yet another approach develops individual risk scores and uses a thresholding policy to treat similarly risky individuals the same way. The list of fairness definitions goes on and on, but in all cases, one aims to find the most accurate model that still satisfies a given fairness constraint. But who exactly selects the protected classes and the requirements that should be met? We know that certain parity requirements are impossible to satisfy simultaneously. On the other hand, finding the right metric and risk scores for individual assessments can be very challenging and needs to be done on a case-by-case basis. As Hanna Wallach from Microsoft Research puts it “[…] issues relating to fairness and machine learning are fundamentally socio-technical, and they are not going to be addressed by computer scientists or developers alone”. So it is of utmost importance to include a diverse set of stakeholders in these decisions with an insight into the whole decision-making process.Demographic Parity – A Group-Fairness Measure
For defining and explaining in more detail group-fairness measures, let’s revisit David Weinberger’s tomato factory example. In this hypothetical factory, tomatoes are processed to end up in spaghetti sauce. An integral part of the factory is a machine learning algorithm that automatically analyzes tomatoes on the conveyor belt and classifies them into fresh and bad (or rotten) tomatoes. Fresh tomatoes are transferred into the “Acceptable” bin and ultimately end up in the spaghetti sauce, rotten tomatoes end up in the “Discard” bin and are thrown away. Consider there exist only two kinds of tomatoes worldwide: 80% of all tomatoes are red tomatoes and 20% of them are yellow. Apart from their appearance, there is no difference between red and yellow tomatoes. They taste the same, have the same shape, grow equally fast, and need equal amounts of care. They also have the same storage life which means they start to rot after the same time span. One of the most intuitive definitions of fairness is demographic (or statistical) parity. In case the tomato sorting machine learning algorithm satisfies demographic parity, we expect about 80% of red and 20% of yellow tomatoes within the “Acceptable” bin in the spaghetti factory. In other words, we expect the fractions of red and yellow tomatoes in the global population to be reflected in the “favorable” group of “Acceptable” tomatoes in the factory. An unfair algorithm, that “favors” red tomatoes and discriminates against yellow ones, would put more than 80% of red tomatoes in the “Acceptable” bin. In this example, demographic parity is a perfectly fine measure. However, as Dwork and co-workers pointed out, the notion of demographic parity has shortcomings and needs to be applied with great care. Imagine that our two hypothetical tomato sorts do differ in that yellow tomatoes tend to rot a little faster than red ones on their way to the factory. In that case, the fraction of red tomatoes in the “Acceptable” bin should be larger than 80% as more of the yellow tomatoes need to be discarded. Enforcing demographic parity in this scenario leads to two problems. First, it actually introduces some unfairness. To achieve demographic parity, say for a one-day batch of tomatoes processed in the factory, the algorithm needs to put some rotten yellow tomatoes into the “Acceptable” bin while, at the same time, prevent some of the perfectly fresh red tomatoes from going in there. The second shortcoming is related to the tension between accuracy and fairness. If the tomato sorting algorithm was what is called a perfect classifier (in practice a perfect classifier does not exist but for the sake of the argument let’s consider it does), it would not make any mistakes and place all tomatoes in the correct bin. As such, this algorithm is fair as it treats every single tomato the way the tomato “deserves”. Enforcing demographic parity on this perfect classifier would actually detune it – which clearly shows that there is a misalignment between optimizing a classifier and satisfying demographic parity. Therefore, demographic parity usually leads to larger costs in accuracy and, therefore, costs an organization more money than other fairness measures.Equality of False-negatives And Equalized Odds
The core problem of demographic parity is that it does not take into account the ground truth. It does not care whether or not tomatoes are “Acceptable”, it just requires the fractions of red and yellow tomatoes in the global population being represented in the “Acceptable” bin. There is a group of fairness measures that do take into account the ground truth by, for example, balancing or equalizing the errors the sorting algorithm makes for both sorts of tomatoes. One of the simplest examples in this context is the so-called equality of false-negatives measure that enforces constant false-negative rates across groups. In our tomato example, this means that fresh tomatoes – irrespective of their color – have the same probability of falsely ending up in the “Discard” bin. This measure only amends the errors made in the group of fresh tomatoes as only they can falsely end up in the “Discard” bin. An even stronger fairness notion that also mitigates errors in the group of rotten tomatoes is called equalized odds. It requires constant false-negative as well as true-negative rates across groups. This means that also the chances for rotten tomatoes ending up in the “Discard” bin is equal for red and yellow tomatoes. One big advantage of these types of fairness measures is that they allow for perfect decisions. For a perfect classifier, the false-negative and true-negative rates across all groups are 0% and 100%, respectively. This does not mean that the accuracy of a real-world classifier is not limited by an additional fairness constraint but it shows that, for example, equalized odds is usually better aligned with optimization than demographic parity.The Accuracy Versus Fairness Trade-Off
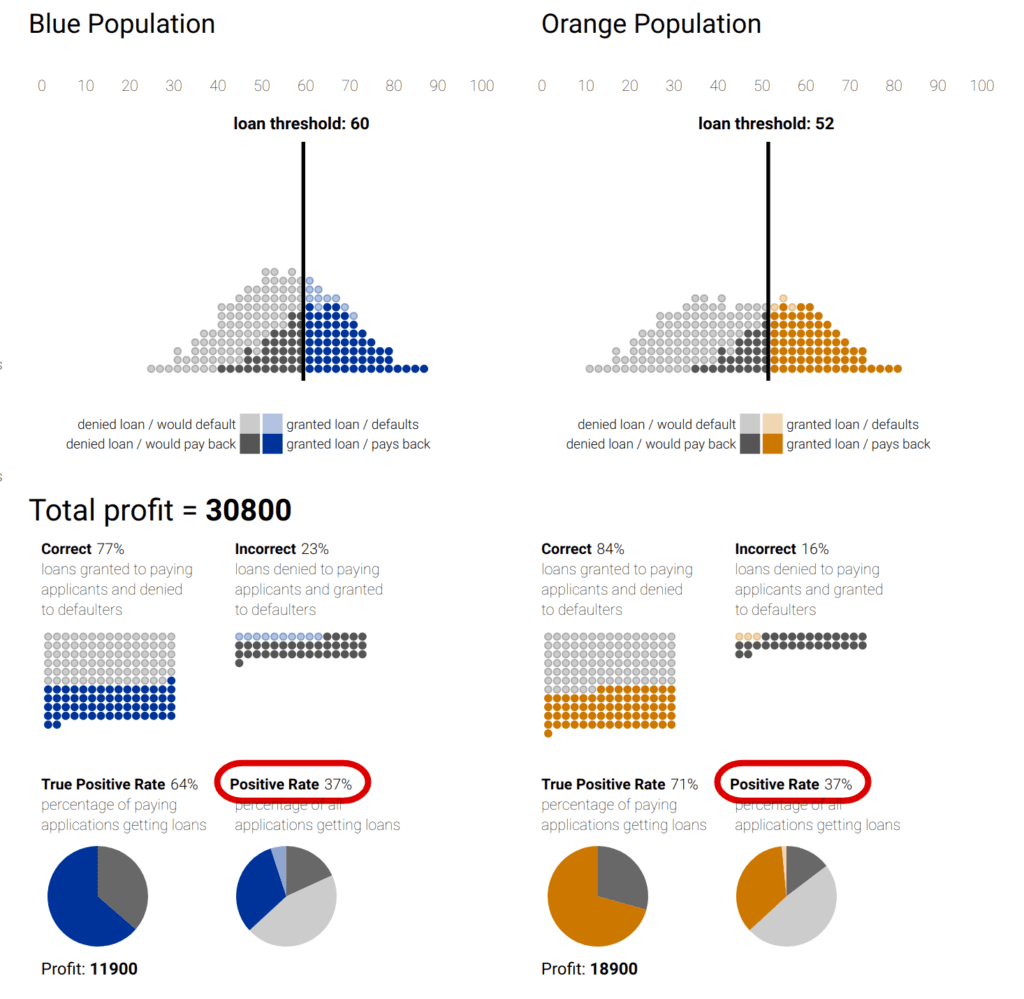
Fairness always comes at a cost: as we put an additional constraint on the model, we introduce a trade-off with accuracy. This is not a new phenomenon and a stark example relates to a fatal Uber accident in Tempe, Arizona. The autonomous vehicle system detected the pedestrian in time to stop but the developers had tweaked the emergency braking system in favor of not braking too much, balancing a trade-off between jerky driving and safety. Going back to bias, when we compare a model that maximizes total revenue, a fairness constrained model will probably promise less profit. You can explore these concepts with an interactive threshold classifier, including demographic parity and equal opportunity (that is, equal true positive rates), in a post from Google Research. By setting various global or group aware thresholds for giving out hypothetical loans, you can see how the bank’s profit and the distributions of loans across the population changes.