
At MOSTLY AI we take pride in offering the world’s most accurate synthetic data platform and that our AI-generated synthetic data is “as good as real”. It seems we might have been wrong on that one, and that it can be very well considered “better than real . The performance of machine learning models can be in fact improved by training on synthetic data in place of the real data. This is possible as the synthetic data helps these models to learn and understand patterns by 1) providing significantly more samples than otherwise available in the original data, and by 2) providing specifically more samples of any minority classes that would otherwise remain under-represented. Sounds too good to be true? Then read on!
So far, most of our customer use cases have focused on generating synthetic data to enable privacy-compliant data collaboration - whether that is across departments, across organizations, or across borders with internal and external partners. The generated synthetic data resembles the original data in shape and size, is statistically representative thereof, and yet fully anonymous. In other words, a dataset twin that can be freely utilized for any development, analytics, and machine learning tasks - without the otherwise privacy-related restrictions and risks attached.
But the benefits of synthetic data don’t stop there, and various other opportunities arise that we are genuinely excited about to explore further together with our most forward-thinking customers. While classic anonymization techniques are inherently destructive and seek to destroy information in an attempt to prevent re-identification, synthetic data generators are constructive by design. They are capable of creating new synthetic worlds from scratch, one data point at a time. These worlds can help to see and understand not only what is already happening, but also what could be possible, and thus can make analytics as well as any statistical models more robust and resilient.

While we’ve covered the aspects of privacy as well as fairness in previous blog posts, we will herewith focus on the benefits of amplifying as well as a rebalancing data to boost the predictive accuracy of downstream machine learning algorithms.
Generating More Training Data for Machine Learning
We start with a dataset of online shopping behavior, sourced from the UCI Machine Learning Repository. It consists of 12,330 sessions, each recorded with 17 features, and a binary target variable representing whether a purchase event took place or not. In total, only 1’908 (=15.5%) of the 12,330 sessions resulted in a transaction, and thus in revenues. The stated goal is to train a predictive model based on the available data that accurately estimates the purchase probability of a new customer session, based on the given 17 attributes.
To reliably assess the accuracy of the calculated purchase propensity scores, it is good practice to set a (randomly sampled) subset of the original data aside for the evaluation phase. This so-called holdout dataset must not be made available to the model’s training phase, as it is only used in a final step to calculate performance measures. These metrics then indicate how the models are likely to perform on new data going forward. The better the performance on the holdout dataset, the better the expected performance when deployed in production.
For predicting a single binary target variable based on a fixed set of features, a whole range of model classes is available nowadays. Logistic regression and decision trees remain popular, given their broad availability, fast computation, and easy interpretability. However, these models have a low and fixed model capacity and saturate quickly. In other words, they can’t get any smarter by feeding further training samples to them.
Modern ensemble models, on the other hand, like Random Forest, LightGBM, or XGBoost, have a flexible model capacity. They thus saturate at a much later point and do benefit from more training data becoming available. This is the reason for their state-of-the-art performance in numerous predictive tasks, as can be seen from open machine learning competitions like hosted on Kaggle. And thanks to open-source software implementations, these types of models are easily accessible and quickly gained in popularity over the last couple of years.
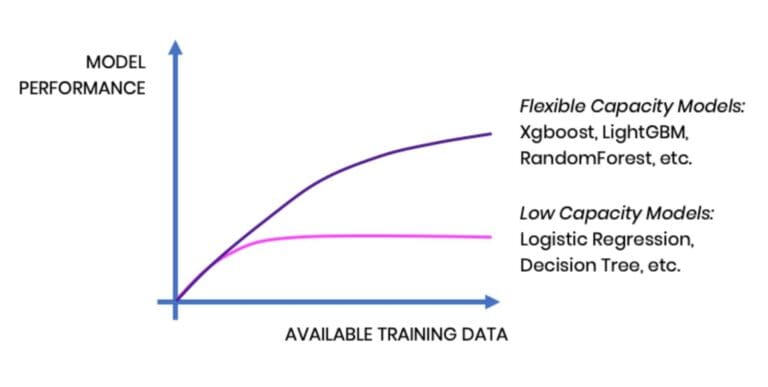
The idea is thus simple: By leveraging MOSTLY AI's synthetic data platform, we will create significantly more training data, and then benchmark downstream ML models that are trained on the synthetic data against the very same models trained on the original data. In both cases, the performance is evaluated on a true holdout dataset that was neither available for the training nor the synthesis.
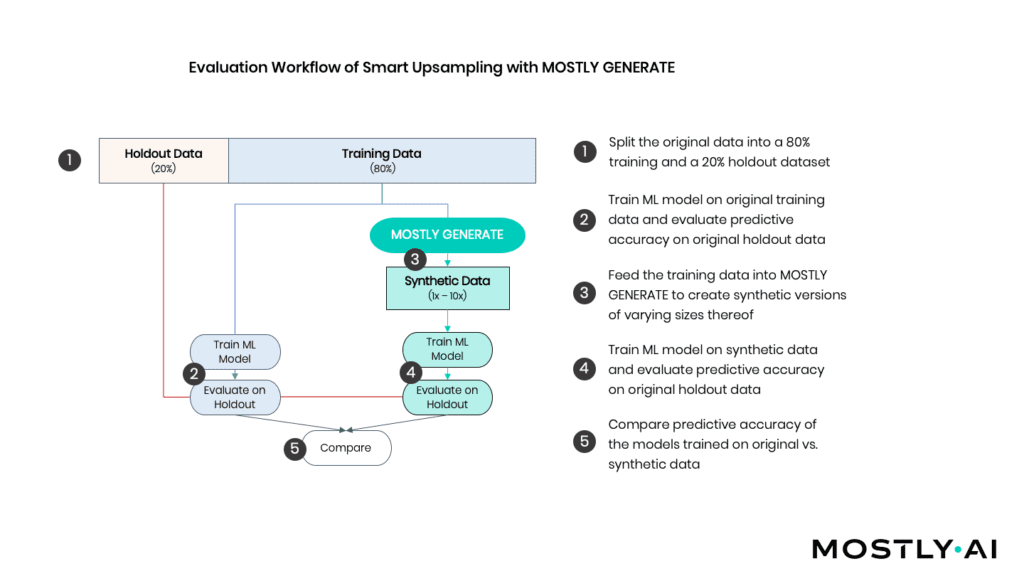
As depicted in Figure 2, we (1) start by randomly splitting the available sessions into an 80% training dataset (=9’864 records) and a 20% holdout dataset (=2’466 records). Various ML models are fitted to the training records that are then evaluated on the holdout (2). In addition, we use the training records to generate a synthetic dataset of 100’000 artificial records consisting of all 17 features and the target variable (3). Based on this amplified dataset, we train the same ML models and again evaluate against the holdout (4). Ultimately, we then compare the accuracy of the holdout of these distinct approaches (5).
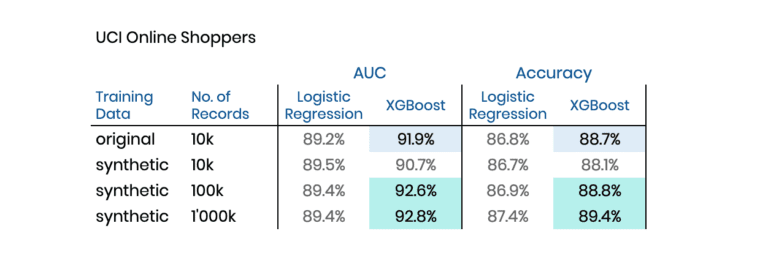
Table 1 reports the performance for two distinct and commonly used evaluation metrics, whereas higher values reflect better performance. And there you have it: Both models do perform better when trained on the (amplified) synthetic data than when trained on the original data! I.e., we are able to boost model performance by feeding it with synthetic data in place of the actual one.
Generating Balanced Training Data for Machine Learning
Next, we turn towards the demanding task of modeling heavily imbalanced datasets, which typically occurs whenever rare yet critical events, such as fraud, incidents, or diseases, need to be predicted. Even the aforementioned state-of-the-art algorithms can struggle in the presence of substantial class imbalances, as the crucial signals for the rare events can easily get drowned in a sea of other available data points.
Common simple heuristic approaches to handle class imbalances are to either downsample or the upsample the training data. The former simply discards samples from the so-called majority class, which effectively throws away available information to achieve class balance. And the latter would repeatedly add the same samples of the minority class multiple times, i.e., the same information is added redundantly. While, as we will see, this can be beneficial, it also increases the chances of memorizing the specific training subjects that are part of the minority class, which bears a significant privacy risk.
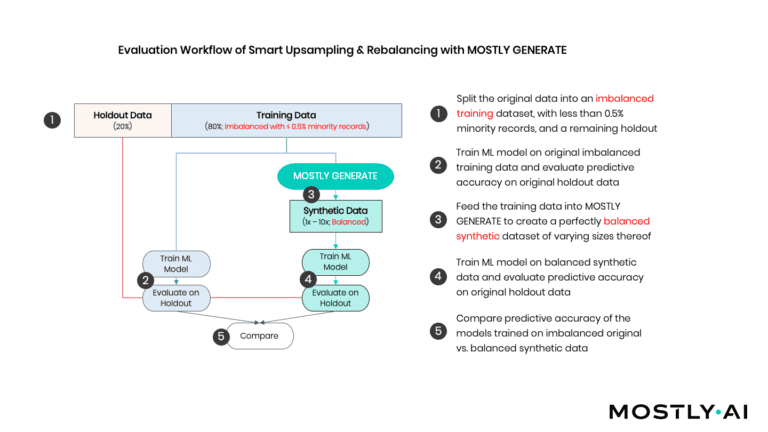
Again, the idea is simple. Instead of training on the original data, we will train our ML models on a synthetic, yet perfectly balanced dataset of significantly bigger volume. We will refer to this approach as “synthetic upsampling" (see Figure 3).
We start our empirical exploration with a dataset on Credit Card Fraud from a 2016 Kaggle competition, that is particularly challenging, as 1) only 0.17% of observations are fraud, and 2) nearly all of the 30 predictor features consist of non-interpretable, uncorrelated PCA (Principal Component Analysis) components. So, while there are 284’807 records in total, there are only 492 fraud cases to learn from. And since we are using 20% for holdout, that number gets even lower, making it even harder to detect patterns that help identify these few fraud cases reliably.
MOSTLY AI's synthetic data platform has the capability to conditionally create synthetic data, which allows us to control explicitly for how many fraud and non-fraud cases are to be generated. This makes it possible to create a perfectly balanced synthetic dataset of any size that we then use to train our downstream ML model on. Table 2 has the results of our experiments, which again show the boost in model performance by training on synthetic instead of the original data.
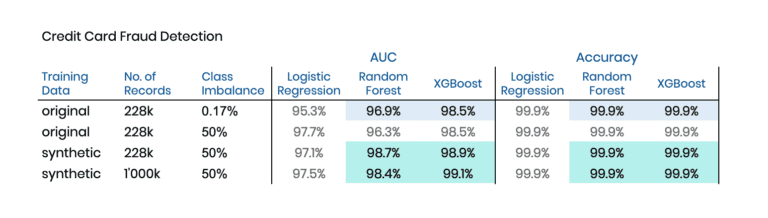
While these are encouraging results, we have to note that 1) the holdout dataset only had 115 fraud cases that could be used for evaluating the performance, and 2) that the overall predictive accuracy was already nearly perfect, and little was to be gained. Let’s, therefore, turn towards two further publicly available datasets, and let’s intentionally bias the training data so that we end up with an artificially imbalanced training data that has only 0.5% of minority cases. The advantage of this experimental setup is that there remain a significant number of “minority” cases within the holdout, making the evaluation measures more robust.
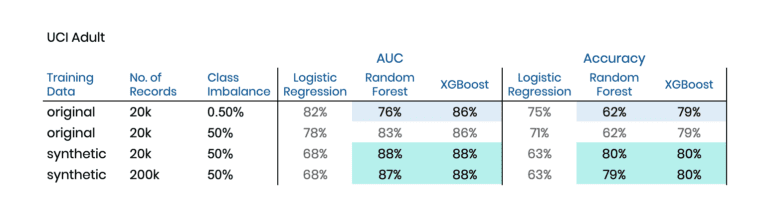
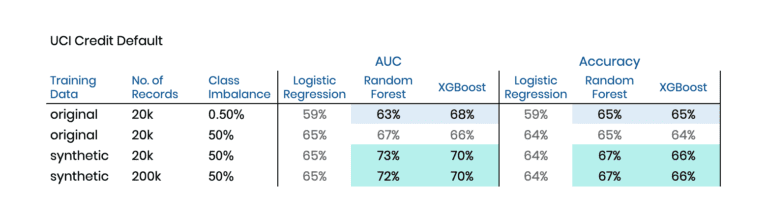
The two chosen datasets are the Adult dataset and the Credit Default dataset, both publicly available via the UCI Machine Learning Repository. Again we have binary prediction tasks at hand. In the former case, we will be predicting high-income citizens, based on 13 mixed-type features recorded for 48’842 subjects. And in the latter, the target is to predict a credit default event based on 23 features logged for 30’000 cases. In both cases, the biased training sample will be intentionally imbalanced, consisting of 19’900 majority cases and only 100 minority cases to learn and to synthesize from.
Table 3 and Table 4 contain the corresponding results of these explorations. And once again, we can see a significant lift by switching towards training on our AI-generated synthetic data. This lift occurs not only in comparison to the original data but also compared to an upsampled variant of the original data. For both datasets, the XGBoost model can be improved in terms of the area under the ROC curve (AUC) by two percentage points, and in terms of Accuracy by one percentage point. Further, it is interesting to note that the Random Forest model manages to get on par and even exceeds the performance of XGBoost when being trained on our balanced synthetic dataset.
Summary
The availability of a sufficient amount of training data is critical for the success of any machine learning initiative. Yet sometimes it’s hard to get started, as initially, too little data might be available. Sometimes, it’s the most relevant cases that are missing in the historic data. Sometimes, it’s just too expensive or time-consuming to gather additional data points. As the explorations in this blog post have demonstrated, AI-generated synthetic data shows promise to support in all of these cases, which is why we are excited to explore these avenues further with our customers to help them succeed with their ML/AI initiatives, at a fraction of the time and at a fraction of the costs.
If you are currently involved in a ML/AI initiative within your organization, reach out to us to learn more - and embark on the exciting synthetic data journey today!


