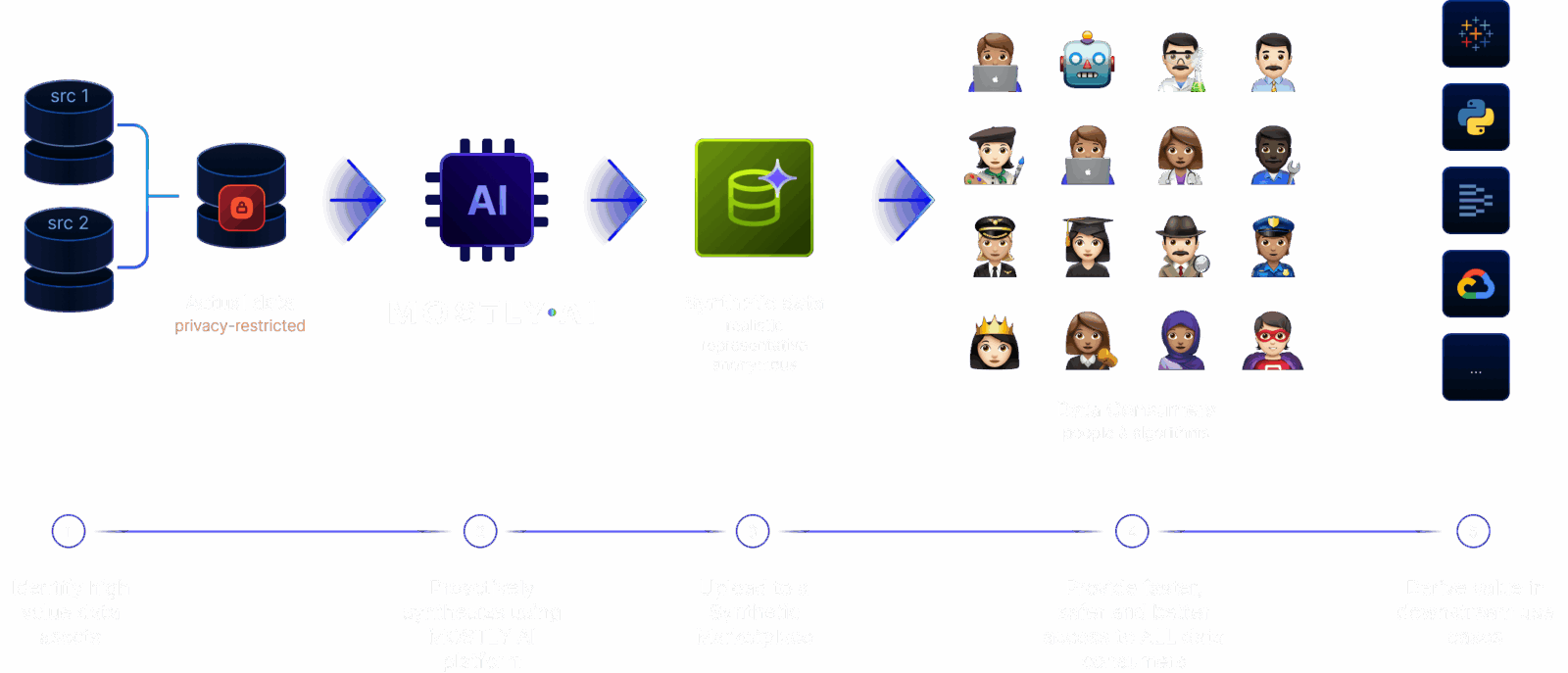
The Data Access Dilemma: Balancing Innovation, Privacy, and Risk
- Internal data access is becoming increasingly restricted.
Rightfully so, as organizations face growing internal risks. According to Gartner, 59% of privacy incidents originate from within an organization. Even more concerning, 45% of those are the result of intentional actions by employees, whether malicious or not. - Minimizing the internal attack surface has become critical.
Financial and reputational damage from data leaks has made perimeter defense insufficient. Reducing the volume of sensitive data accessible inside the organization is now a top priority. - Traditional data governance strategies are falling short.
Most approaches are not only insecure but also deeply inefficient. Data scientists report spending up to 80% of their time on locating, cleaning, and preparing data rather than extracting insights from it. - External demand for data access is rising.
Vendors, start-ups, research collaborators, and offshore development teams all depend on reliable data access to build, test, and innovate. But most are met with roadblocks instead of pipelines. - Compliance and cybersecurity pressures are closing the gates.
New privacy rulings like Schrems II have made cross-border data sharing between the EU and US nearly impossible. At the same time, a growing cyber threat landscape is making organizations more risk-averse than ever when it comes to sharing data externally.

What’s Really Holding Back Data-Driven Innovation
Everyone talks about the importance of data-driven decisions, but the reality inside most organizations is quite different. Only a small group of individuals, usually a few privileged data scientists, actually have access to the data needed to make those decisions. And even for them, the process is rarely smooth. Accessing certain datasets often involves navigating complex permission systems and internal approvals.
The challenge becomes even greater when data scientists or machine learning engineers want to explore new ideas or work on unfamiliar datasets. In many cases, they must request additional permissions, even for running new types of analyses on data they have used before. Depending on the organization, these approval processes can take several weeks or longer, causing significant delays and slowing down innovation.
External data sharing poses an even more difficult problem. Organizations that manage large volumes of sensitive information, such as financial institutions, banks, and insurance companies, are typically left with two poor options. They can either choose not to share data at all, or rely on outdated anonymization techniques. These traditional approaches often fail to protect privacy effectively and result in data with limited utility. In some cases, less mature organizations expose themselves to serious risks by using basic de-identification methods or sharing production data directly.
Better, faster, and compliant ways of accessing data are already possible with the right approach. Yet most organizations are still unaware of one of the most powerful solutions available today: synthetic data.
Enabling Data Democratization Through Synthetic Data
Data is increasingly being treated as a product, especially within large organizations. To unlock its full potential, data should be proactively made available across departments, flowing seamlessly between business units and even across international subsidiaries.
However, in highly regulated industries, achieving this level of data access is extremely difficult without the right privacy-enhancing technologies. One technology that stands out is synthetic data. It is transforming how organizations anonymize and share data, turning the concept of compliant, scalable data access into a practical reality.
Synthetic data makes data democratization significantly easier to implement, particularly in sectors with strict regulatory requirements such as healthcare, banking, and government. Traditional data-sharing processes often involve lengthy approval workflows, legal agreements, and privacy reviews. In contrast, synthetic data removes many of these barriers by preserving the analytical value of the original dataset without including any personal or sensitive information.
As a result, organizations can share data more freely across departments, subsidiaries, or even with external partners. This simplifies compliance, accelerates decision-making, and fosters greater collaboration across teams.
With synthetic data, organizations can create a more open, innovative, and privacy-respecting data culture that supports both agility and compliance.
To see a practical example of synthetic data in use, explore the following video showing how it can be shared within a Databricks environment.
Data democratization best practices
More and more companies pivot to a proactive data approach. These innovators create internal - or in some cases, external data exchange platforms - to facilitate innovation and data-forward thinking across the organization and beyond.
Synthetic data sandboxes are populated with curated and maintained synthetic versions of business-critical datasets. Access to synthetic data assets can be broadly and quickly provided. Citizen data scientists can freely use synthetic data sandboxes, accelerating innovation and compliance. This helps to unlock customer data for a wide variety of further use cases, such as:
McKinsey estimates that privacy-safe data sharing could generate almost $3 trillion annual economic value. And synthetic data generators are the technology to make this a reality.