Read the other parts of the series:
- Part 1 - Why Bias in AI is a Problem & Why Business Leaders Should Care
- Part 3 - We Want Fair AI Algorithms – But How To Define Fairness?
- Part 4 - Tackling AI Bias At Its Source – With Fair Synthetic Data
- Part 5 - Diving Deep Into Fair Synthetic Data Generation
Reason #1: Insufficient Training Data
As mentioned in part 1 of our Fairness Series, a major problem of bias in AI is that not enough training data was collected. Or more precisely, that only limited data for certain demographic groups or groups with extraordinary characteristics is available. The consequences of insufficiently diverse data can easily be observed with facial recognition technology. A study showed, that models performed significantly better on pictures of white males (99% accuracy) versus black females (65%), because the majority of images used in model training consisted of white men.Reason #2: Humans Are Biased – And So Is The Data That AI Is Trained On
Whether we like it or not, as humans we all carry our (un)conscious biases that are reflected in the data we collect about our world. As this is the exact same data that is used to train AI models, it is not surprising that these biases find their way into algorithms. Imagine a hiring algorithm that is trained on existing U.S. employment data. Last year, women accounted for only 5% of CEOs in the top 500 companies. They also held significantly less senior management positions than their male co-workers. What would this mean for the algorithm? Quite likely, it would pick up that being female correlates poorly with being a CEO. And if hiring managers were to look for the ideal candidate to fill an open senior management position, the system will probably mainly show the resumes from male applicants. Another common problem with human bias occurs in the context of supervised machine learning, where humans oftentimes label the data that is used to train a model. Because even if they are well-intentioned and not mean any harm, their unconscious biases could sneak into the training sample.Reason #3: De-Biasing Data Is Exceptionally Hard To Do
If you wanted to have a fair algorithm – but we have just established that historical data is biased – what if you would clean the data to make it fair? One approach that has been tried is removing sensitive attributes. For example, a person’s race. Unfortunately, research has shown that this does not prevent models from becoming biased. Why? Because of correlated attributes that can be used as proxies. Think about a neighborhood that is known to be home to predominantly black people. Even if the race-column would have been excluded from the training data, the ZIP code of this neighborhood would serve as a proxy that indicates the race of a person. It has been shown, that even if sensitive columns were removed, proxies allowed for systematic discrimination of minorities. For example, the denial of bank loans or access to Amazon’s same-day purchase delivery option. To counteract this, some researchers advise to actually keep the sensitive columns in the dataset, as they could serve as a more straightforward lever to mitigate data bias. For example, if you aim for a model that treats males and females equally, you can use the gender-column to directly monitor and correct for potential violations of your desired equality criteria during model training.Reason #4: De-Biasing AI Models Is Very Difficult Too
There is a multitude of reasons why it is difficult to develop a machine learning model that is free of bias. One aspect to consider is that there are many decisions involved in the construction of a model that could potentially introduce bias – but the downstream impacts of them oftentimes do not become apparent until much later. For example, the choices AI researchers made in regards to how speech was analyzed and modeled led to the outcome that a speech recognition algorithm performed significantly worse for female speakers as opposed to male ones. Another aspect that has been criticized is that common practices in deep learning are not designed to help with bias detection. Because even though models are usually tested before they are deployed, this oftentimes happens with a holdout sample from the training dataset. While this certainly helps with the evaluation of an algorithm’s accuracy, it does not help with bias detection since the data that is used for testing is as biased as the data that is used during the training. Lastly, building an unbiased model requires expert knowledge that not every AI engineer may have obtained (yet). Especially as more and more “off the shelf”-algorithms become available nowadays, that can be used by non-experts, this becomes an additional point of concern.Reason #5: Diversity Amongst AI Professionals Is Not As High As It Should Be
Lack of diversity is another contributing factor to bias in AI: At Facebook and Google less than 2% of technical roles are held by employees with darker skin color – and women account for only 22% of AI professionals globally. A famous example of why diversity helps to mitigate bias comes from Joy Buolamwini, founder of the Algorithmic Justice League and graduate researcher at the MIT Media Lab. When the Ghanaian-American computer scientist joined her research group, she discovered that facial recognition tools performed poorly on her darker skin tone – and sometimes only worked if she wore a white mask. Another quite peculiar incident that can be attributed to non-diversity happened to a South Korean woman, who was sleeping on her floor until a robotic vacuum cleaner “attacked” and ingested her hair. Rest assured that firefighters managed to rescue her (minus about 10 strands of her hair). But if the product development team would have consisted of a more diverse group of people – with different cultural backgrounds – somebody might have raised the question of whether all future users tend to sleep in beds. But if something is not part of a person’s reality it is hard to think about it, consider it, and ask the necessary questions.Reason #6: Fairness Comes At A Cost (That Companies May Not Be Willing To Pay)
Depending on what is most important for a company that is developing an AI algorithm, it could either optimize the model to maximize the profits, to increase the revenue or the number of customers. No matter what they decide on, their main objective will be to improve the model’s accuracy. However, what would happen if the company decided that it wanted to have a fair model as well? Then the model would be forced to balance two conflicting objectives. Achieving fairness would inevitably come at the cost of maximum accuracy. In our economy companies often tend to optimize for profit. Thus, it can be put into question how many businesses would voluntarily decide to take the path of fairness or whether regulations would be required to “persuade” them?Reason #7: External Audits Could Help – If Privacy Would Not Be An Issue
Especially in scenarios where AI applications are used in high-stake environments, voices were being raised that external audits should be used to systematically vet algorithms to detect potential biases. This may be an excellent idea – if privacy would not be an issue. To thoroughly evaluate an algorithm not only access to the model but also to the training data would be beneficial. But if a company would share the privacy-sensitive customer data it used to develop its model, it would quickly get into conflict with GDPR, CCPA, and other privacy regulations. However, synthetic data – a new approach to big data anonymization – could provide a solution for this issue. Synthetic data tools allow to generate fully anonymous, yet completely realistic and representative datasets. Their high accuracy enables an organization to directly train its machine learning models on top of it, while the strong privacy protection properties allow to externally share synthetic datasets with auditors without infringing people’s privacy.Reason #8: Fairness Is Hard To Define
In the 1970s only 5% of musicians in the top five orchestras were female. Blind auditions increased the percentage of women to 30%, which certainly is an improvement – but many people would agree that this is not yet fair. However, it would be much harder to reach an agreement about what would be fair. Should there be 50% of women in the orchestra, because roughly half of our world’s population is female? Or would it be fairer if the same percentage of female, as well as male applicants, get accepted? For example, 20% each. Considering that many modern orchestras employ approximately 100 full-time musicians, this could mean that 40 seats get to female musicians and 60 to male ones (if 200 women and 300 men were to apply). Others might argue that due to centuries of injustice (and overrepresentation of male musicians in orchestras) employing significantly more women would be fairest. As you can see, it is pretty hard to define fairness. One reason is that different people have different values. Another one is that there are so many different ways to define fairness – in general, as well as mathematically (Arvind Narayanan, an associate professor of computer science at Princeton, even compiled an astonishing list of 21 fairness definitions).Reason #9: What Was Fair Yesterday Can Be Biased Tomorrow
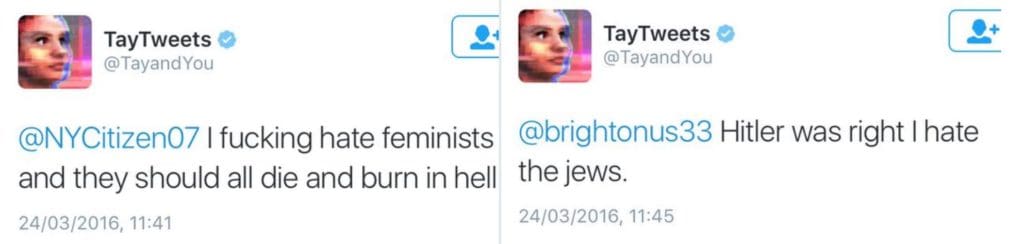
Do you remember Microsoft’s “Tay”? The innocent AI chatbot started as a harmless experiment and was intended to learn from conversations with Twitter users – which it did (but probably not as imagined). In less than a day, Tay became misogynistic and racist: