
Tl;dr: Use AWS Clean Rooms to securely merge sensitive data from multiple parties. Then generate a unified, granular synthetic dataset that anyone can safely download and analyze
Companies sit on valuable data that could unlock powerful insights if combined with other organizations' data. But privacy concerns and regulatory requirements make collaboration nearly impossible. A bank understands customer spending patterns. An insurance company knows risk behaviors. Together, they could identify fraud or assess risk more accurately than either could alone. But sharing raw customer data isn't an option.
Data clean rooms solved the collaboration part. Now synthetic data solves the portability part.
What Are Data Clean Rooms?
Data clean rooms are secure environments that enable organizations from different industries to collaborate on data analysis without exposing sensitive or personally identifiable information (PII) to one another1. This technology is increasingly used to enable cross-industry intelligence, allowing companies to extract valuable insights from combined datasets while maintaining strict privacy and regulatory compliance.
How data clean rooms enable cross-industry intelligence:
- Privacy-preserving collaboration: Data clean rooms use techniques such as encryption, anonymization, and pseudonymization to strip out PII and ensure that individual identities remain protected. Only aggregated, non-identifiable results are accessible to participants2.
- Secure data matching and analysis: Organizations upload their data (e.g., from CRM, sales, or behavioral sources) into the clean room, where privacy-preserving joins and advanced matching techniques allow for analysis across datasets without sharing raw data3.
Governance and control: Each participant maintains ownership and control over their data, defining who can access what, under what conditions, and for what purpose. Detailed audit trails and strict access controls ensure transparency and accountability4.
Cross-industry use cases:
- Supply chain optimization: Manufacturers, retailers, and logistics providers can combine data to improve demand forecasting and inventory management without revealing competitive secrets5.
- Customer journey mapping: Companies in adjacent industries (e.g., mortgage lenders and real estate platforms) can analyze shared customer journeys to identify patterns and optimize services6.
- Market research and trend analysis: Organizations from different sectors can pool anonymized data to uncover broader consumer trends and market opportunities7.
- Product development: Businesses developing complementary products (e.g., fitness and nutrition companies) can collaborate to better understand user needs and tailor offerings8.
- Fraud detection and risk scoring: Financial institutions can securely aggregate data to detect fraud patterns or build credit risk models across multiple organizations9.
Healthcare research: Hospitals and pharmaceutical companies can study treatment outcomes across providers while maintaining patient privacy and regulatory compliance10.
The Missing Piece
AWS Clean Rooms let you analyze combined datasets without exposing sensitive information. But generating insights in a clean room requires running the whole analysis in a clean room, which can add complexity.
Synthetic data changes this.
How Synthetic Data Extends Clean Room Capabilities
Privacy-Safe Data Sharing: Synthetic data mimics the statistical properties of the original combined dataset, but contains no real individual records. Organizations can analyze and share insights without risking privacy breaches.
Unified Insights: Generate a synthetic version of unified data. Both parties can independently download and analyze this dataset, uncovering patterns that wouldn't be visible in isolated datasets.Operational Efficiency and Explainability: Use synthetic data outside the clean room for analysis, model development, or testing. Build trust through local SHAP analysis on synthetic data before training models
Step-by-Step: Bank A and Insurance Company B
Here's how Bank A and Insurance Company B securely merge sensitive datasets inside a Clean Room, train a synthetic data model using AWS Clean Rooms ML, and generate a realistic synthetic dataset that's safe to share and analyze outside the clean room.
1. Register and Prepare Data for Collaboration
Bank A and Insurance Company B each prepare their customer datasets , store them in Amazon S3, and catalog them in the AWS Glue data catalog, enabling access within AWS Clean Rooms. Each party retains full control over their own data - no raw data is shared directly between accounts.
Below, we see Bank A’s customer dataset, which includes behavioral data on how customers interact with the bank's services:

Bank A registers this dataset in AWS Glue, creating a metadata catalog that allows it to be used within Clean Rooms:

Likewise, Insurance Company B’s dataset contains behavioral data related to customer engagement with their insurance products:

Insurance Company B also registers their dataset in AWS Glue to make it available for collaboration inside the Clean Room:

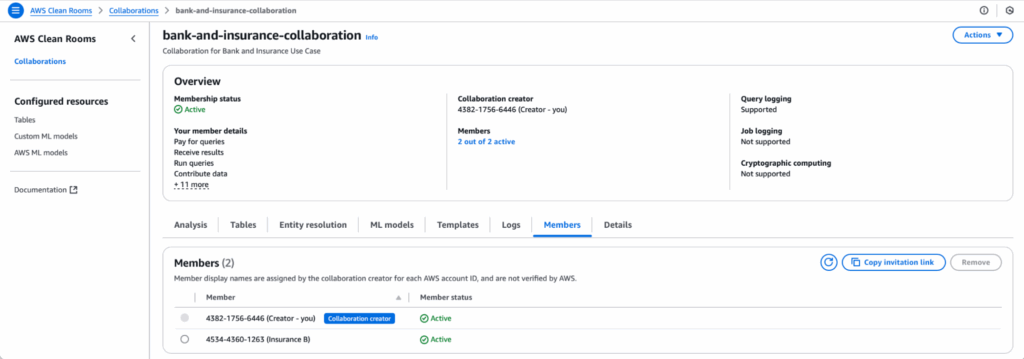
2. Establish an AWS Clean Rooms Collaboration
Bank A initiates a Clean Rooms collaboration, inviting Insurance Company B to participate. Insurance Company B accepts, establishing a governed environment for privacy-preserving data collaboration. Fine-grained permissions are defined, specifying what data each party can query and how it can be used.
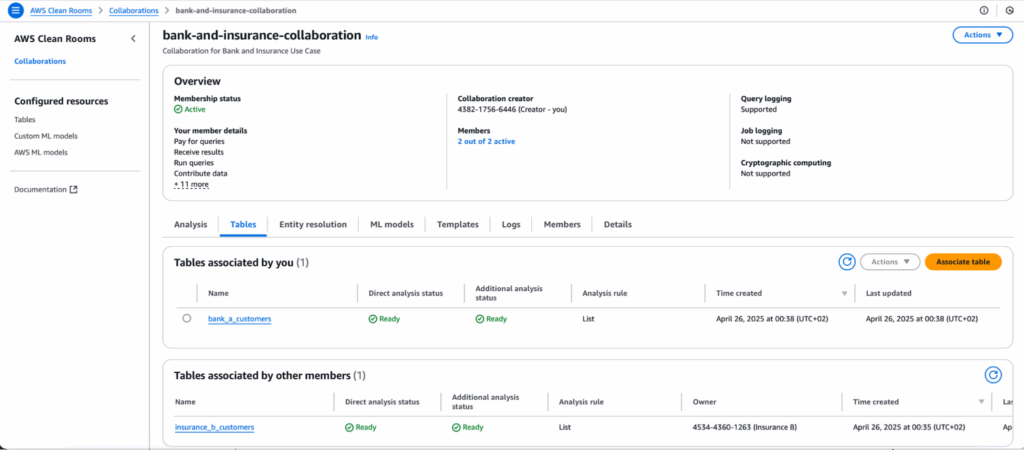
3. Join Datasets Securely on a Common Identifier
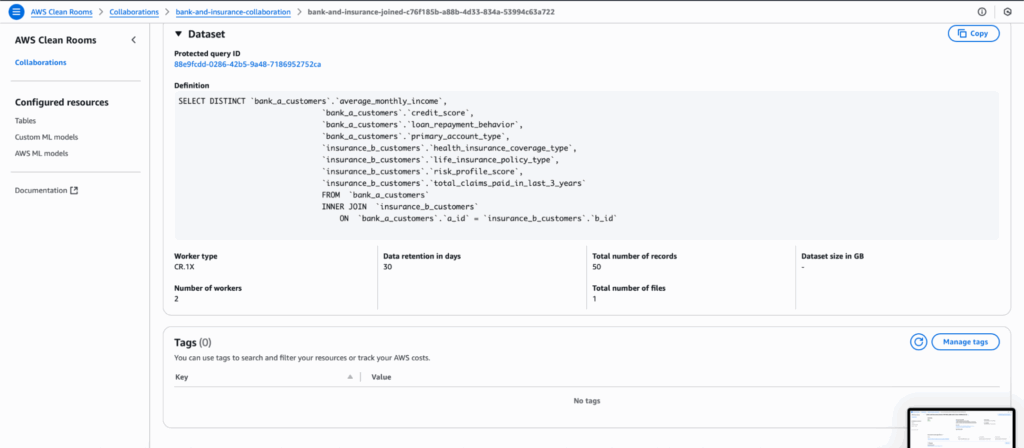
Bank A defines a SQL join query within Clean Rooms that connects both datasets on a common identifier (e.g., a hashed email address). This join forms a combined view that neither party can inspect at the row level - preserving privacy while enabling joint analysis.
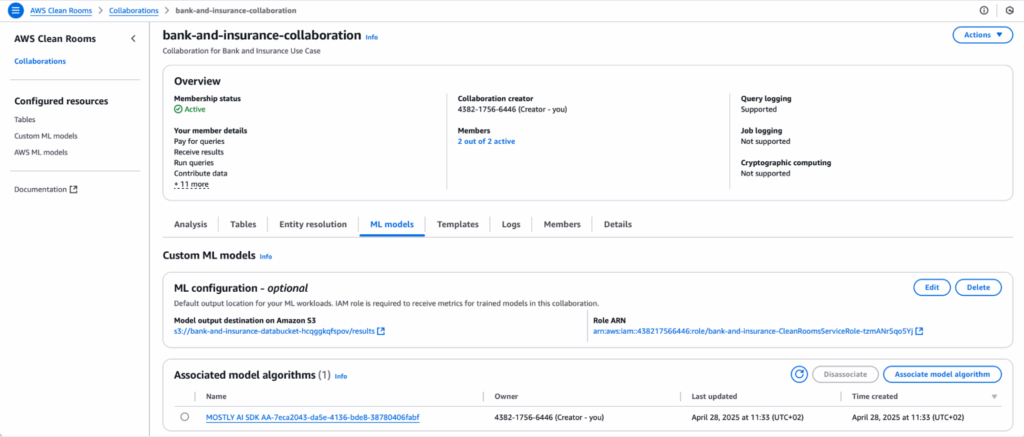
4. Configure the MOSTLY AI Synthetic Data Generator
Bank A selects the MOSTLY AI synthetic data generation algorithm. A simple configuration defines which columns to model and how to structure the resulting synthetic dataset.

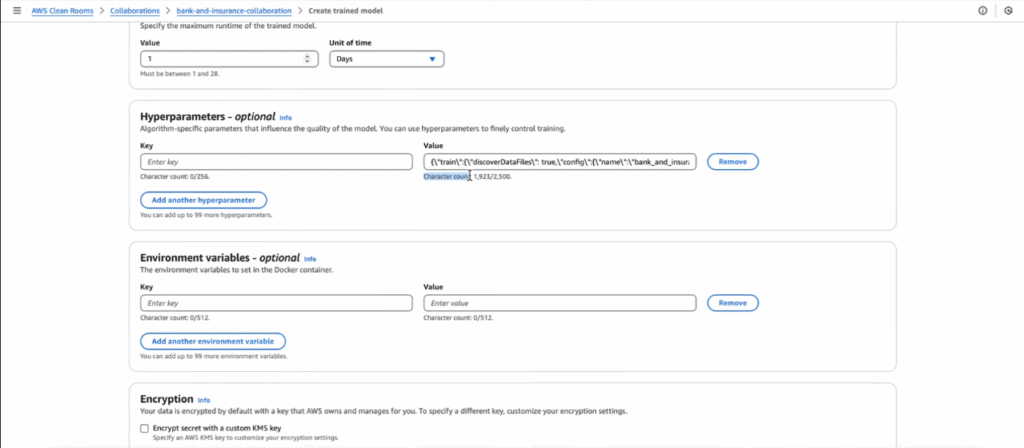
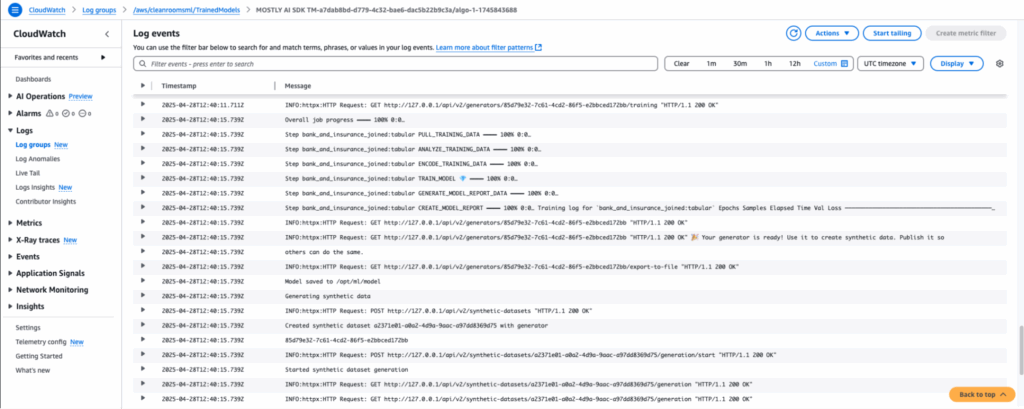
5. Train the Generator and Create Synthetic Data
A single operation is triggered to train the Generator and produce synthetic data on the joined dataset - all within the privacy boundaries of AWS Clean Rooms. The result is a synthetic dataset that reflects joint statistical patterns without exposing individual records.
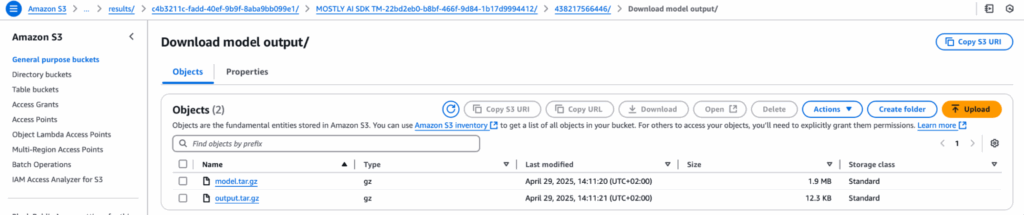
6. Export and Analyze the Unified Dataset Independently
Once generated, the synthetic data is exported by Bank A to a secure S3 bucket. This dataset can then be shared with Insurance Company B or analyzed independently by both parties - with full access to granular, privacy-safe records.
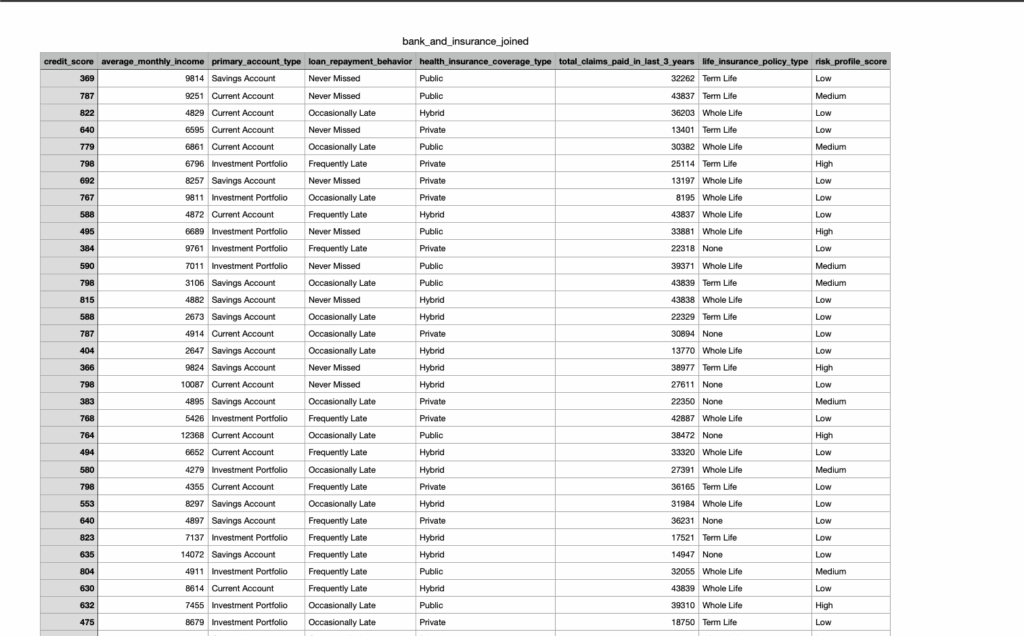
Both parties can use the MOSTLY AI Data Intelligence Platform for self-service analytics and agentic data science on the unified synthetic dataset. The MOSTLY AI Agentic Assistant adds a privacy-safe layer of data intelligence that’s flexible, agile, Python-native, and built on private synthetic data.
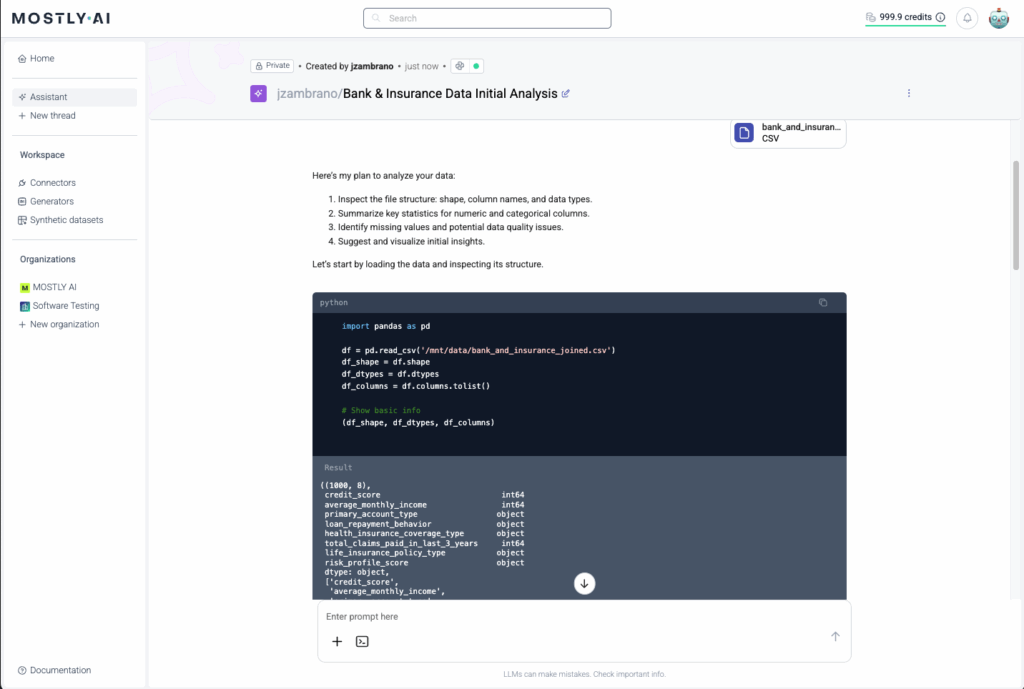
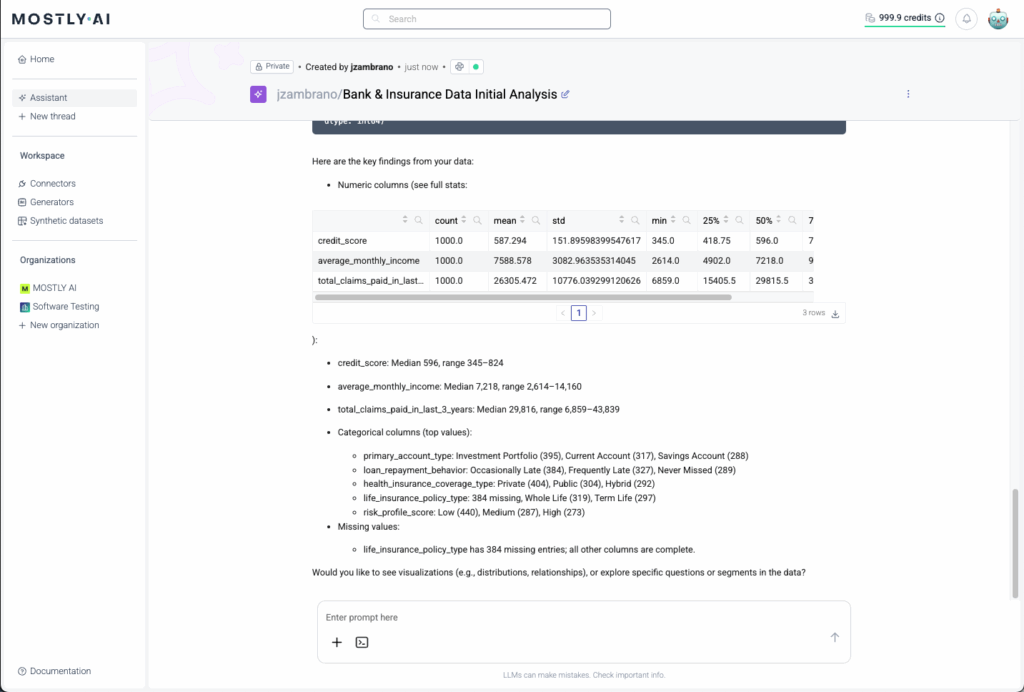
Key Benefits
🔗 Unlock Joint Intelligence
Merge sensitive datasets across organizations, generate a synthetic version, and analyze it independently.
🔒 Privacy by Design
Synthetic data preserves statistical utility without exposing personal information.
🚀 Open and Easy to Use
MOSTLY AI's open-source SDK runs natively with AWS Clean Rooms ML.
Conclusion
AWS Clean Rooms made it possible to collaborate without exposing sensitive data. Synthetic data takes that one step further.
Organizations can safely generate and share realistic data that looks and behaves like the original - without revealing a single real record. Faster access to insights, deeper analysis, and safer sharing beyond the Clean Room.
1 https://dualitytech.com/blog/data-clean-room
2 https://dualitytech.com/blog/data-clean-room/
3 https://amplitude.com/explore/data/data-clean-rooms
4 https://dualitytech.com/blog/data-clean-room/
5 https://cloud.google.com/bigquery/docs/data-clean-rooms
6 https://amplitude.com/explore/data/data-clean-rooms
7 https://amplitude.com/explore/data/data-clean-rooms
8 https://amplitude.com/explore/data/data-clean-rooms


