
Synthetic data workflows have traditionally required a mix of engineering effort, platform knowledge, and careful coordination across tools. You upload a dataset, write code to explore it, adjust preprocessing steps, configure a generator, train it, generate data, build a model, and eventually compare results. It is powerful, but rarely simple.
This time, I tried something different.
I uploaded the Census Income dataset into the MOSTLY AI Assistant and let the Assistant guide the entire process. What normally takes multiple steps and manual effort unfolded through a single conversational interface. From exploratory analysis to a full Train Synthetic, Test Real (TSTR) evaluation, the workflow was handled end to end.
The result was not just a good synthetic data experiment. It was a different way of working with data altogether.
1. Starting with a Simple Request
I began by asking:
“Analyze this data.”
The Assistant immediately:
- inspected the schema
- profiled numeric and categorical variables
- calculated distributions
- generated visualizations
- highlighted which features most influenced income
- produced summary statistics
- saved shareable files and reports
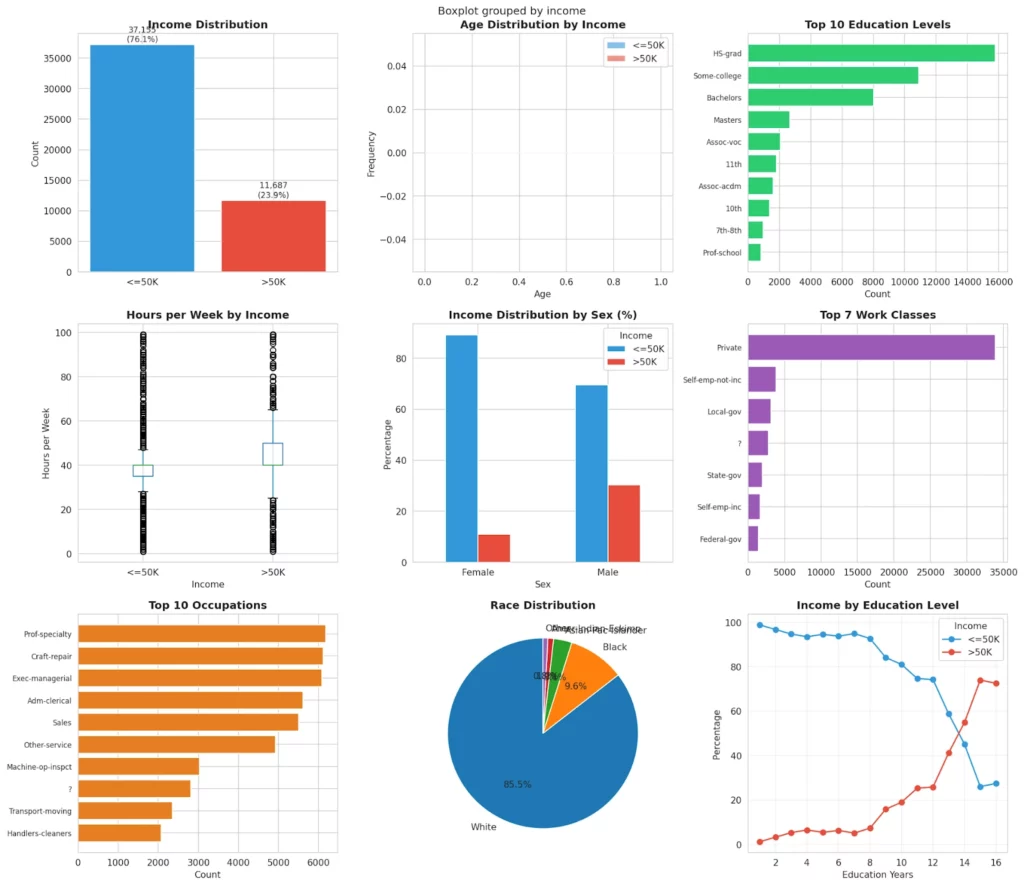
It delivered the type of analysis that usually requires a notebook session and a fair amount of Python. Here, it arrived instantly and in an organized, readable format that set the foundation for the rest of the workflow.
2. Automatically Configuring a Synthetic Data Generator
Next, I asked:
“Can you configure an optimal synthetic data generator for this dataset?”
Using what it learned during the analysis, the Assistant:
- selected an appropriate model size
- enabled value protection
- activated flexible generation
- created a full configuration document
- and then created the generator itself
This is typically a manual configuration step, but in this case the Assistant handled it with a single sentence.
3. Launching a Complete TSTR Experiment Through One Prompt
To validate predictive utility, I asked:
“Create an 80/20 split, train a generator on the 80 percent, generate synthetic data, train a model on both datasets, and compare the model performance on the real test set.”
The Assistant took over and sequentially handled every step:
- created a stratified train test split
- trained the generator only on the training data
- generated a synthetic dataset
- trained an XGBoost model on the real training split
- trained an XGBoost model on the synthetic data
- evaluated both models against the same real 20 percent holdout
Along the way, the Assistant automatically managed the preprocessing required to prepare both datasets for modeling, including aligning column order and data types.
No notebook or custom code was needed; the Assistant handled everything.
4. Comparing Real and Synthetic Model Performance
The results were strong and in line with what you expect from high-fidelity synthetic data.

The synthetic-trained model performed within roughly one percentage point of the real baseline. This confirms that the generator learned the underlying relationships needed for predictive modeling.
5. What Stood Out Most
TSTR itself is not new. It has long been a standard way to assess synthetic data quality.
What is new is how the experiment ran.
The Assistant did not just generate data. It coordinated the entire workflow:
- analysis
- generator configuration
- generator training
- synthetic data production
- ML training
- evaluation
- reporting
All through natural language.
This eliminates the friction that usually exists between wanting to evaluate synthetic data and having the time, tooling, and expertise to run a full experiment. Anyone on a team can now run a validated synthetic workflow without switching tools or writing code.
6. Why This Matters for Data Teams
This approach changes how teams interact with data:
- Experimentation becomes faster because setup work disappears
- Analysis is available instantly without notebook overhead
- Synthetic data can be validated early in a project rather than late
- Privacy-safe data becomes easier to share and collaborate on
- Non-technical users can participate directly in the process
Instead of building and maintaining pipeline steps by hand, teams can focus on evaluating outcomes and exploring new ideas.
7. Final Thoughts
Running a TSTR experiment on its own is straightforward. Running the entire process — analysis, generator configuration, training, synthetic data generation, modeling, evaluation, and reporting — through conversational interaction is something different.
It shows what happens when synthetic data capabilities, machine learning workflows, and a natural-language interface are all connected in one environment.
This demonstrates how the MOSTLY AI Assistant turns a complex workflow into a simple dialogue while still producing rigorous, meaningful results.


