In partnership with the U.S. Department of Homeland Security (DHS), MOSTLY AI completed a multi-month proof of concept (PoC) focused on one of the most pressing challenges in cybersecurity: enabling advanced analytics and machine learning while maintaining strict data privacy and regulatory compliance.
The core objective was to determine whether synthetic data could replace sensitive telemetry, specifically NetFlow and Sysmon logs, without compromising analytical utility. From the outset, the project defined two key success criteria:
- Synthetic data must achieve at least 90% fidelity compared to the original dataset (as measured by MOSTLY AI’s QA report)
- Machine learning models trained on synthetic data must perform within 5% of the same models trained on original data
This wasn’t a theoretical exercise. Using publicly available data, we worked to replicate realistic conditions and prove that privacy-preserving synthetic data can meet operational needs.
Over six structured milestones, our teams worked closely to explore, iterate, and validate that vision.
Phase One: Separate Synthesis of NetFlow and Sysmon
We began with publicly available data sources for both NetFlow and Sysmon:
- NetFlow V9-format data from Kaggle with over 2 million rows and labeled anomaly flags
- Sysmon event logs from Splunk’s public GitHub repository
Given early constraints, we synthesized these datasets separately:
- On the NetFlow side, we tested three scenarios using IP source, destination, and combined IP pairs as subjects. QA scores exceeded 90% in all cases, with the highest reaching 94.8%.
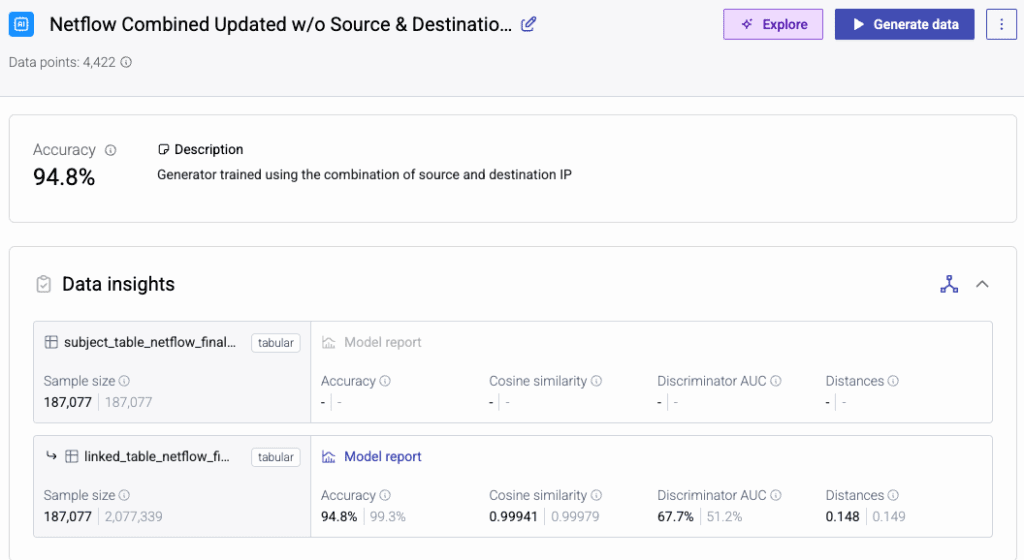
- On the Sysmon side, we structured a two-table setup for process and event-level data. Event data performed well (94.5% accuracy using a language model), while the smaller sample size of the process table limited accuracy.
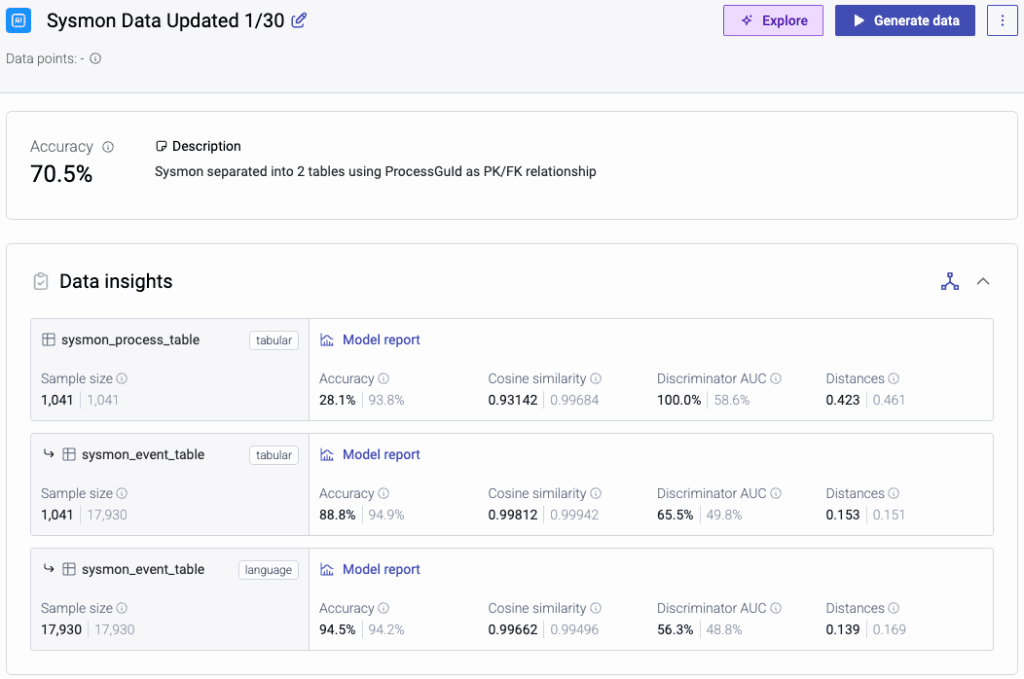
This work formed the foundation of our midpoint demo. At that stage, we had met early fidelity targets and validated that the approach was sound.
From Feedback to Integration: Building a Linked System
Following the midpoint, the DHS team provided focused technical feedback - particularly around our event-linking logic. Originally, we relied on timestamp proximity to associate Sysmon and NetFlow events. Based on suggestions from their leads, we introduced FQDN-based filtering to more accurately link system and network activity.
This iteration led to a more robust structure: a three-table setup consisting of Sysmon events, NetFlow flows, and a Link Table to explicitly associate the two. This was more than a format update: it created the contextual linkage needed to support real-world detection logic.
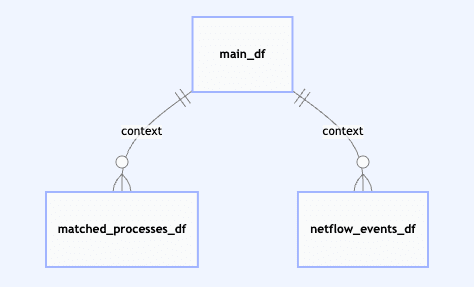
Final Results: Fidelity and Functional Accuracy
In the final evaluation, the combined dataset met both success criteria:
- 90.7% QA accuracy across the full three-table setup
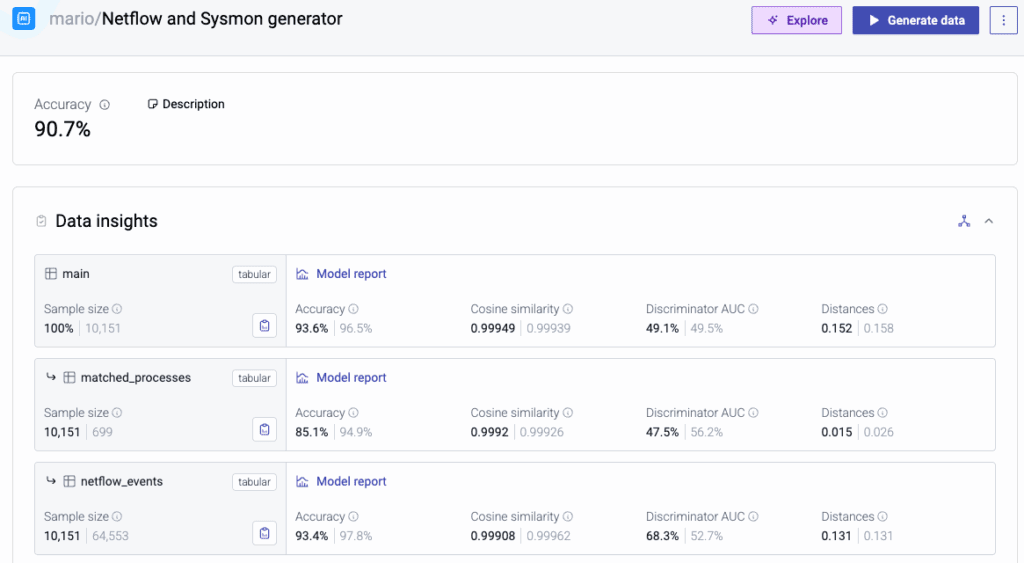
- A Random Forest model trained on synthetic NetFlow data achieved a ROC AUC of 0.993, compared to 0.996 on the original
- The performance delta was just 0.3%, well within the <5% threshold
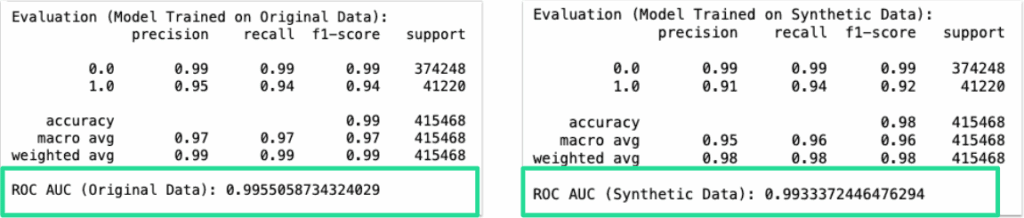
These results confirmed that synthetic data can preserve not only structure and statistical fidelity, but also real downstream model utility, supporting tasks like anomaly detection without exposing sensitive information.
What Comes Next
While this phase of the project is complete, there’s already interest in exploring a potential Phase 2. The foundation is now in place to expand into more advanced use cases, higher volumes, and more nuanced cross-source linkage. Privacy and collaboration challenges remain core issues for federal cyber teams and synthetic data may offer a path forward.
For MOSTLY AI, this PoC reinforces that synthetic data isn’t just a sandbox tool - it’s ready for operational relevance in some of the most constrained and high-stakes environments.
Closing Thoughts
This was a chance to work on something meaningful with a team that was collaborative, curious, and focused on impact. We’re proud of the outcomes and excited about what’s ahead.


