
MOSTLY AI now offers users the choice to train synthetic data generators with or without differential privacy (DP) guarantees! By toggling DP on in the model configuration, training becomes differentially private, and the platform tracks the privacy budget (Epsilon) throughout. Users can also set an upper Epsilon limit, stopping training automatically when the budget is reached. It’s as simple as that. Best of all, this feature works for both our tabular as well as our newly launched language models. Generating differentially private synthetic data has never been easier!
This capability is powered by the Opacus library (kudos to Meta Research), which ensures robust DP training. It handles gradient clipping, adds noise to gradients, randomizes the data loader, and monitors Epsilon through a privacy accountant. Users have full control over noise levels and gradient clipping to fine-tune DP settings for their specific dataset and use case. Importantly, these measures complement MOSTLY AI's existing privacy safeguards, ensuring that all synthetic data is privacy-safe.
While the non-DP training remains the default, providing best-in-class efficiency, quality and safety, this added flexibility serves users that demand strict mathematical privacy guarantees, and that are willing to trade off computational efficiency, and model accuracy for it.
Empirical Demonstration
Let’s use the US Census Income dataset to demonstrate the impact of generating synthetic data with and without differential privacy. This dataset is a canonical choice for studying synthetic data. It comprises 48,842 rows and 15 mixed-type attributes, including fields such as education level, marital status, working hours per week, and income level.
Using the MOSTLY AI platform to synthesize this dataset with default configurations, training takes about 3 minutes and delivers best-in-class empirical scores for accuracy, similarity, and privacy. The synthetic data faithfully represents the general patterns of the original dataset without disclosing any subject-specific information.
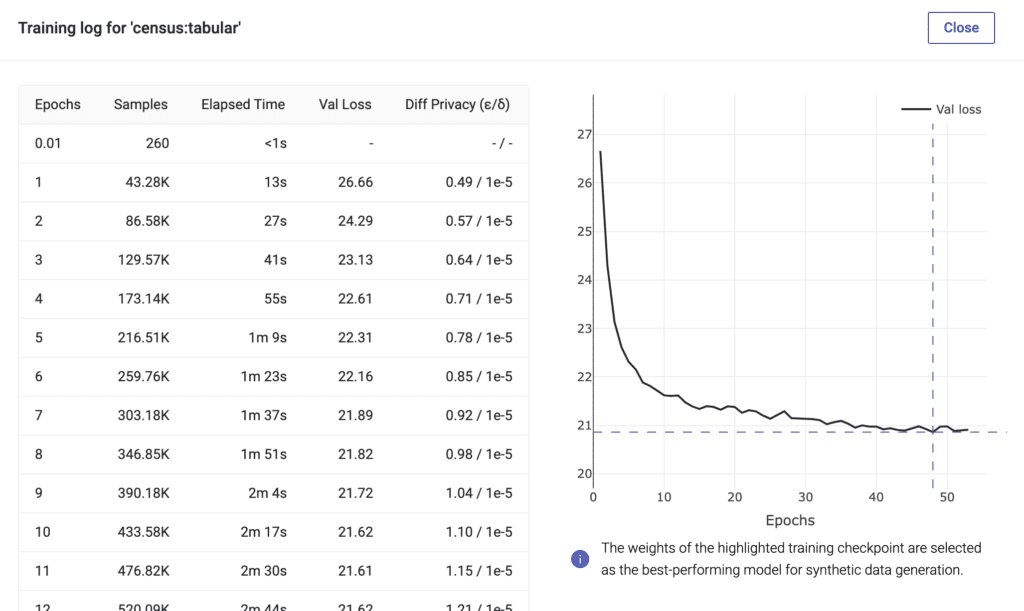
To now train a generative model with mathematical privacy guarantees, we can simply enable differential privacy, while leaving its DP configurations at their defaults. With these settings, training time for the Census dataset increases to 12 minutes and yields a final Epsilon of 2.51 (with a Delta of 1e-5). Inspecting the provided model report reveals hardly any noticeable loss in quality. However, our synthetic data quality metrics help to precisely quantify the impact: the DP guarantee introduced a slight loss in statistical representativeness, with an overall accuracy of 96.2% at DP Epsilon = 2.51, compared to 98.1% without DP.
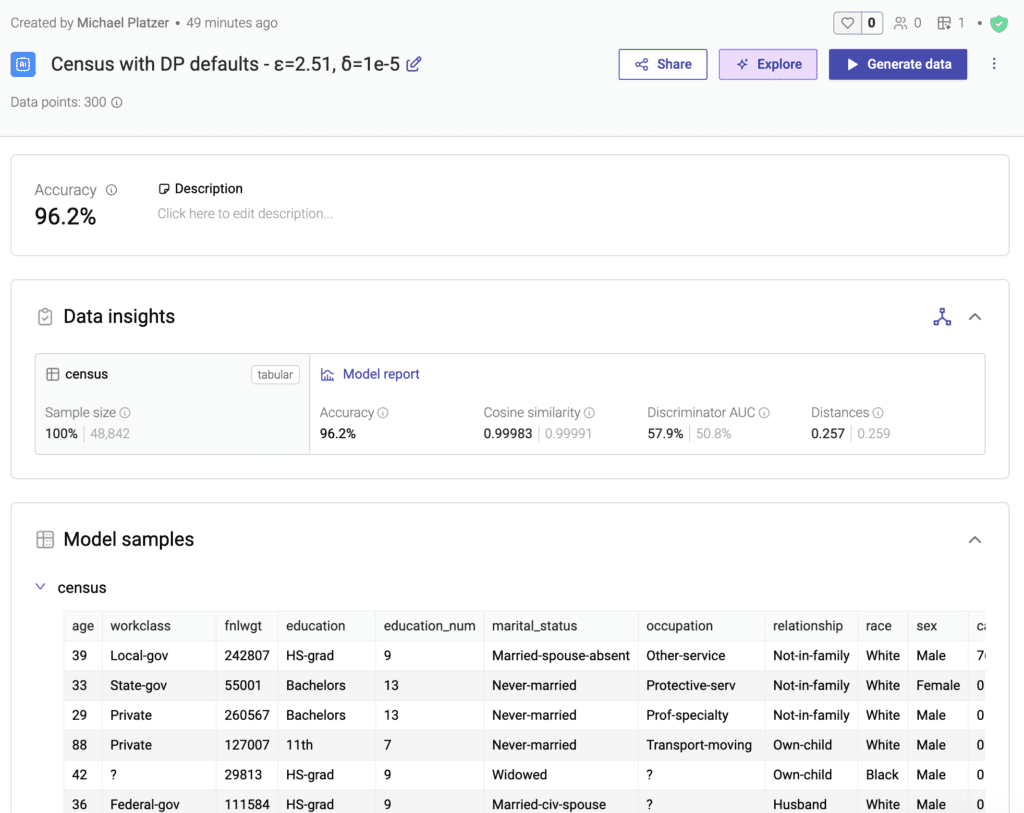
Important: An Epsilon of 2.51 does not imply that this upper limit of privacy disclosure, which only applies to theoretical worst-case scenarios, is actually ever reached in practice. Empirical privacy loss is often orders of magnitude smaller than this1. Similarly, training without DP does not mean that the generated synthetic data is not private. It simply indicates that a theoretical Epsilon value cannot be quantified. Nonetheless, the safety of synthetic data can be assessed empirically, as is done automatically via the model report.
Let’s now dive into the effects of the two key DP settings:
- noiseMultiplier: Adjusts the amount of noise added to the aggregated gradients.
- maxGradientNorm: Controls gradient clipping to limit the influence of individual data points on model weights.
We conducted a total of 3 × 10 experiments using the mostlyai Python client, varying the values for each parameter. See here for the source code and here for the results of these experiments. The noiseMultiplier varied across 0.25, 0.5, 0.75, 1, 1.5, 2, 4, 8, 16, and 32, and maxGradientNorm varied across 0.5, 1, and 2. The resulting relationship between finally consumed privacy budget Epsilon and the achieved overall accuracy is then visualized as a scatter plot below. Each green dot represents a DP-trained generator with specific DP configuration settings, while the single blue dot corresponds to the experiment using the platform's default DP settings (noiseMultiplier=1.5, maxGradNorm=1).
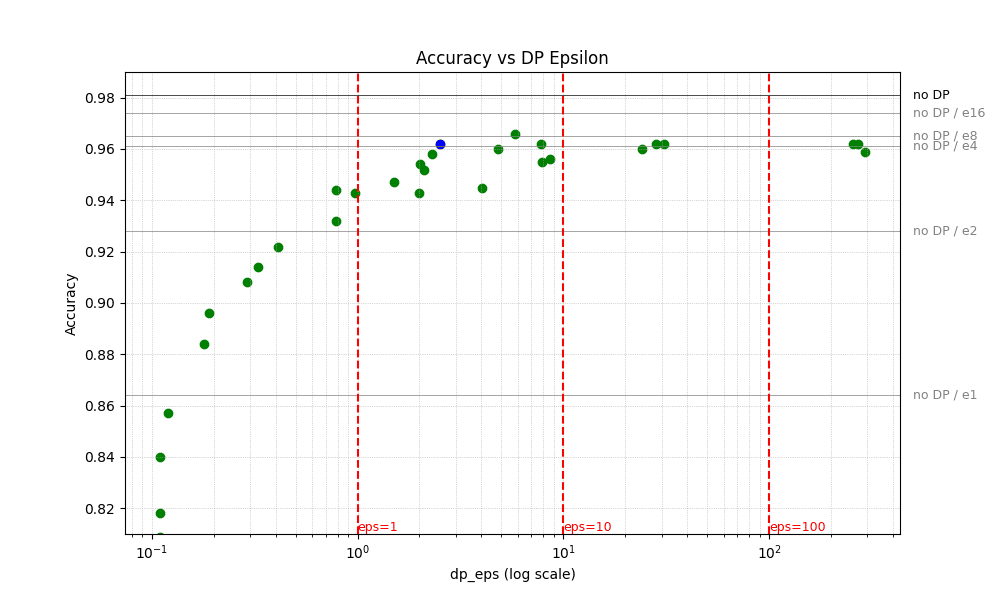
The chart clearly reveals the privacy-utility trade-off. On the left-hand side, we observe training jobs with a small consumed privacy budget, with an Epsilon of less than 1, resulting in reduced overall accuracy. And on the right hand side, we see that accuracy with DP will plateau at a certain level, while it still remains below the non-DP accuracy.
Additionally, experiments without DP that stop early based on the maxEpochs criterion are depicted as horizontal gray lines for reference. For example, using the default DP settings yields empirical accuracy and privacy metrics comparable to that of a generator trained without DP for just 4 epochs. However, the latter takes only 18 seconds of compute, thus ends up being ~40x more compute-efficient than the DP variant.
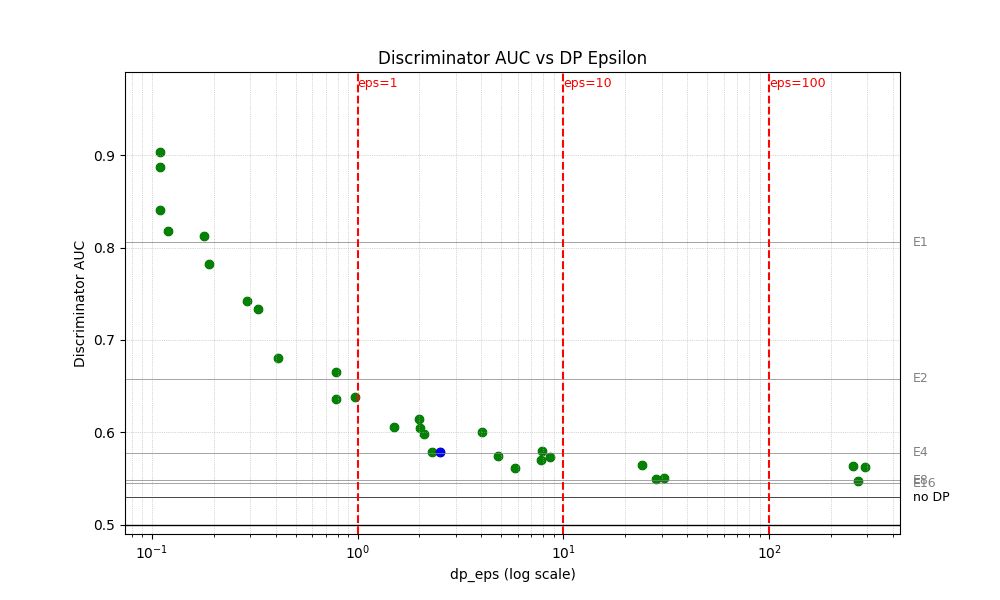
Next up, we evaluate the realism of the various generated synthetic samples using the Discriminator AUC metric. Developed by MOSTLY AI, this metric assesses whether a discriminative model can distinguish between real original samples and generated ones, after mapping them into a meaningful embedding space2.
An AUC value close to 50% implies that the synthetic data is indistinguishable from real samples. Again, the results show that the more relaxed we are with our privacy budget, the higher the data quality and realism achieved. For synthetic data trained without DP we achieve an Discriminator AUC of ~53%. For synthetic data trained with DP defaults, we get a still excellent AUC value of ~58%. I.e. even a purpose-trained ML model has a hard time telling real and synthetic samples apart.
Use Differential Privacy as you see fit
Broadly speaking, there are two camps within the privacy engineering field:
- The Empirical Camp: This group considers self-proclaimed theoretical privacy guarantees pointless, as they cannot be validated - there’s no way to prove a specific algorithm was used at a given time. They argue that the case for private synthetic data must ultimately be made through empirical validation and adversarial stress tests. And if done right, AI-generated synthetic data even without a mathematical privacy guarantee like DP can indeed be shown to be truly anonymous.
- The Theoretical Camp: This group asserts that there is one and only one valid mathematical definition of privacy: differential privacy. DP is valued for its mathematical rigor and desirable properties. One key property is composability, which enables multiple processing steps to be combined under a single, overall privacy budget. For some in the field, even high epsilon values seem acceptable, as the sheer presence of a mathematical upper limit is considered to indicate a presumably much lower empirical information disclosure risk.
At times, this debate becomes surprisingly fierce and dogmatic, feeling detached from real-world practices and risks. In reality, outdated masking or obfuscation methods are still widely used for "anonymization," posing severe privacy risks to customers3.
It’s important to note that DP is neither required nor sufficient to satisfy privacy laws. While DP is an elegant mathematical concept, it has been at times misused to convey a false sense of safety.
- Epsilon Levels Matter: Epsilon must be reasonably low to ensure privacy. For instance, an epsilon of 10 allows the inclusion of a single subject in a dataset to change probabilities by a factor of e^10 = 22,026x. An epsilon of 20 translates to a staggering factor of 485,165,195x. Clearly, such high values are far removed from what is commonly understood as privacy.
- User-Level Privacy is Key: DP must operate at the user level rather than the event or data point level to be meaningful. Unfortunately, some vendors misuse the DP label, ignoring this fundamental principle. Unlike others, the MOSTLY AI platform consistently advocates and reminds users to explicitly specify their privacy-protected subjects, ensuring robust privacy measures.
Ultimately, any privacy claim - whether based on DP or not - must be validated empirically. People don’t care how safe a car is in theory; they care about its safety in practice. Over many years, MOSTLY AI has earned its reputation as the safest and best-performing “car” in the industry, now offering practitioners more choices than ever before.
Conclusion
MOSTLY AI empowers everyone to train differentially private synthetic data generators. The platform now caters to users who are willing to trade off some utility and compute efficiency for the assurance of a theoretical mathematical privacy guarantee for their synthetic data.
But don’t just take our word for it - try it out for yourself! As always, we are eager to hear your feedback and learn from your experiences.
Privacy and innovation go hand in hand, and with MOSTLY AI, you’re equipped to strike the perfect balance for your unique use case.
- One way to study empirical Epsilon is by conducting shadow attribute inference or shadow membership inference attacks. See, e.g. our blog post on attribute disclosure attacks. ↩︎
- This utilizes the Sentence Transformer model all-MiniLM-L6-v2. ↩︎
- "[..] enforcement actions against the use of weak de-identification techniques have been limited so far". See Gadotti et al on "Anonymization: The imperfect science of using data while preserving privacy." Science Advances 10.29 (2024). ↩︎


