Privacy-protection mechanisms
With synthetic data, you can unlock the utility of your original data and at the same time protect the privacy of your subjects. While specific cases in the original data might increase the risk of re-identification, MOSTLY AI employs a number of privacy-protection mechanisms to avoid such risks.
Generated synthetic data does not have 1:1 relation to the original data

In contrast to anonymization techniques, MOSTLY AI uses your original data only as a learning material to train generative AI models. During training, the models learn the patterns, distributions, correlations, and other statistical characteristics of your original data. MOSTLY AI then uses the AI models to generate synthetic data from scratch.
As a result, the synthetic data bears no 1:1 relationship with the original data and no direct surface exists for attacks to re-identify sensitive information.
Probabilistic model with random draws

MOSTLY AI uses an unsupervised machine learning process to train a deep neural network with the original data as input. The resulting AI model contains only the statistical characteristics of the original data without any personal information. To create the synthetic data, MOSTLY AI performs random draws against the AI model.
For an overly simplified example, you can consider how the process of random draws works for a single column from the original data. For example, a single column might contain the categorical variable Gender with distinct values Male, Female, Other and N/A.
One of the many statistical characteristics that the model learns is the distribution of the variables. For example, the original data might have the distribution of 47% females, 45% males, 7% other, and 1% N/As. When MOSTLY AI randomly draws a synthetic data point for this column, the result is Male in about 4-5 times out of 10.
As mentioned, this example is overly simplified as during each random draw, MOSTLY AI takes into account not only the distribution of a single column, but all statistical characteristics and the relationships that exist between each column of the original data.
Due to the probabilistic nature of this process, it is impossible to predict the result of a random draw. In effect, the process naturally introduces some noise which also results in privacy preservation.
Model overfitting prevention

In terms of privacy protection, model overfitting can mean that, during training, the AI model learns not only general patterns but also actual information that includes privacy-sensitive data.
During training, MOSTLY AI applies a mechanism to prevent the generative AI model from memorizing specific individual properties and patterns. The MOSTLY AI loss function and validation criteria are designed to achieve generalization and avoid model overfitting.
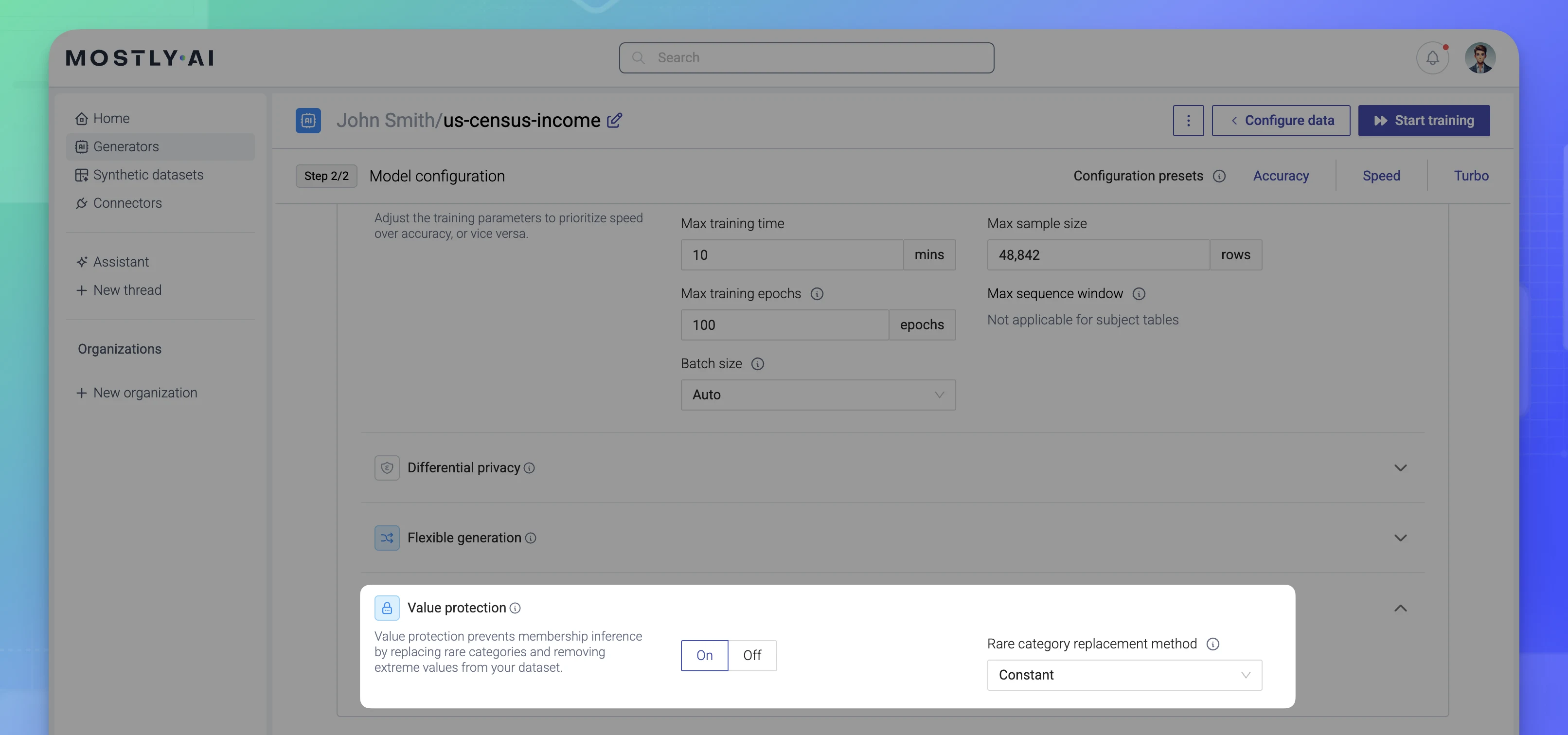
Value protection mechanisms
Value protection includes a number of mechanisms that protect against re-identification in cases such as rare categories, extreme values, and extreme sequence lengths.
Before MOSTLY AI runs the training of the generative AI model with your original data, it applies the value protection mechanisms. This step is crucial to safeguard against membership inference attacks. Although the model cannot learn from a single or small group of subjects, it can still generate a subject with a rare category or extreme numerical value that could be traced back to the original dataset. The mere knowledge that a customer was part of the original dataset constitutes a privacy breach.
Rare category protection

MOSTLY AI applies Rare category protection to categorical columns. This is a safeguard that prevents the training of the AI model with rare values. To maintain the correlation and distribution of the original data, MOSTLY AI substitutes such values with the category value _RARE_.
You can exclude such rare categories from the generated synthetic data. However, this alters the distribution in the synthetic data.
For example, consider a job title such as President of the United States. Although the AI model cannot learn from a single individual, it is trained that a non-zero probability exists of encountering a job title that equals President of the United States.
When MOSTLY AI removes this value before training, it ensures that the value never appears in the generated synthetic data.
Extreme value protection

MOSTLY AI applies Extreme value protection to numerical and date-time columns.
Before training, MOSTLY AI removes extreme values from the data distribtution of such columns. This mechanism ensures that the generated synthetic data does not reveal exceptional cases, such as a 130-year-old person or an entrepreneur with a net worth of 186.5 billion USD.
Extreme sequence length protection

The Extreme sequence length protection algorithm removes excessive numbers of linked records that lead back to a subject in a subject table. As such, long sequence lengths can also jeopardize privacy.
Therefore, we make sure to remove such sequences before the training phase.
Privacy settings by default
When you synthesize data with MOSTLY AI, all privacy settings are on by default.
Value protection is on
MOSTLY AI enables the option Value protection by default for all categorical, numeric, and date-time columns.
Extreme sequence length protection is always on
MOSTLY AI detects extreme sequence length before training and removes them automatically. If you disable Value protection for a Linked table, the Extreme sequence length protection is deactivated.
No tables are copied “as-is”
MOSTLY AI trains a generator on all subject and linked tables from the original dataset. No original data is copied “as-is” into a generator, and as a consequence, no tables from the original dataset are generated “as-is” in the synthetic dataset.
Original data is never retained
While you can upload files, use a database, or access cloud storage buckets to provide your original data, MOSTLY AI uses your original data only for the purposes of training new AI models that can then generate your synthetic dataset.
MOSTLY AI never retains your original data. For example, uploaded files are deleted immediately after your AI models finish training.