In the first part of this series, we’ve noted that only the most data-savvy organizations turn up on the winning side by knowing how to leverage their rapidly growing behavioral data assets. We further went on and identified two key obstacles for organizations to seize the arising opportunity:
Behavioral data is sequential, and thus complex to model and analyze.
Behavioral data is privacy-sensitive and particularly difficult to anonymize. Thus it tends to be locked up.
As it turns out, these two obstacles are reinforcing each other. Without safe data sharing, you can’t champion data literacy. Without data literacy, you won’t see a growing demand for behavioral data. Synthetic data to the rescue!
However, not all synthetic data is created equal: There are solutions for hand-crafted, rule-based, and model-based synthetic data on the market. All come with a relatively similar value proposition, but all are rather simplistic and by far not as rich and diverse as actual behavioral datasets. But it's the deep learning revolution that now also leads to breakthrough advances in the field of synthetic data. In particular, generative deep neural networks. The kind of networks that we've built into MOSTLY AI's synthetic data platform and that allow us to bring the world’s most advanced synthetic data platform for structured, behavioral data assets to our customers in finance, insurance, and other industries. With AI-generated synthetic data, they are able to serve use cases that go far beyond mere testing and development. Its accuracy and reliability make it the sought-after fuel for their next-generation AI initiatives in our era of privacy.
So, let's turn towards a first case study with behavioral data, that provides an initial glimpse into the power of our synthetic data platform for sequential data.
Introducing the Dataset: CDNOW
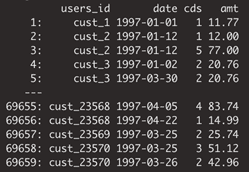
In this blog post, we will work with the so-called CDNOW dataset, which represents purchase records of a former e-commerce site, that sold CDs online. The dataset contains the 18-month purchase history of a cohort of 23,570 customers, that the company acquired in the first quarter of 1997. As it’s one of the few publicly available, real-world transactional datasets, it has been extensively studied within the marketing literature and served as a canonical case study for developing behavioral models in non-contractual settings ([1], [2], [3], [4]). If you are interested, you can easily obtain the dataset as well via Bruce Hardie’s website.
Fig 1. The original CDNOW dataset.
Despite being still a rather simple example, with only a bit over 23’000 customers, and only three attributes for the around 70’000 recorded events, it already offers a vast number of ways to explore the data. For example, every customer has on average 3 transactions recorded, with an average of 2.4 CDs purchased at an average price of $15.5. However, neither an average customer, nor an average transaction, nor an average CD exists. While CD prices range from a couple of bucks for the cheapest ones to over a hundred dollars for collector's editions, the number of purchased CDs is as well anywhere between 1 and 99 per transaction. Additionally, the number of purchases per customer during that 18-month period ranges anywhere from 1 up to 217 (!), where 10% of the most valuable customers are contributing over half of all sales. At the other end of the spectrum, we find the majority of customers (50.5%) to have actually only a single purchase recorded, and thus they apparently decided to never return back to cdnow.com again.
Poor Consumer Understanding Will Lead to Poor Business Decisions
These basic statistics already show that looking at the “Average Customer” does not reveal the looming problems of the e-commerce site, and don't reflect the full breadth of observable behavior in any customer base. Organizations that are truly interested in understanding their customers and their behaviors, and that wish to effectively address these, would rather ask questions like the following:
Which customers will come back?
When will they come back?
How often will they return?
How much will they likely spend?
Thus, what is their customer lifetime value going to be?
(don't miss out on Pete Fader’s TEDx talk on customer-centricity)
And further:
Does the very first purchase provide any indication of later actions?
Are the most frequent customers the most valuable ones?
At which particular dates are customers more active?
Are weekend shoppers different from weekday shoppers?
At which price points do specific customer groups like to act?
How much time typically elapses between two purchases?
Do customers come regularly or rather sporadically?
And can we build predictive models based on these insights?
The answers to all these questions, and many more, are contained right there within the granular level, behavioral data itself. However, as said before, this type of data becomes increasingly inaccessible to people within and outside of an organization, as it is locked away due to regulatory and safety reasons to ensure that the privacy of their customers remains protected. This results in organizations sticking to basic reporting metrics (Total Active Users, Overall Churn Rate,...) and crude segmentation methods, such as Recency, Frequency, and Monetary value (RFM). All the sophisticated behavioral models, that can leverage the hidden patterns contained in big data assets to gain a competitive edge by understanding and subsequently predicting customer behavior remain – to this date – vastly underutilized.
Generating a Synthetic Version of CDNOW
Fig 2. Generating a synthetic CDNOW dataset with a few clicks.
MOSTLY AI's unprecedently accurate synthetic data platform for structured data, can mitigate this problem, as it enables anyone to instantly generate and share synthetic data at scale. That being said, let’s turn towards action, and re-create 50’000 synthetic CDNOW customers, together with their made-up but highly representative purchase histories. All it takes to do that is clicking a few buttons.
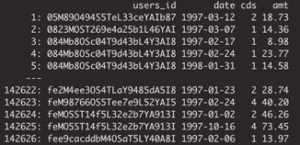
Fig 3. The synthetic CDNOW dataset. All characters and events in this dataset are purely fictitious.
The data for these 50k synthetic customers is shown in Figure 3. Note, that none of these ever existed, yet all of these could have existed! Not only is the resulting dataset structurally identically to the original, but also the purchase behavior of the synthetic customers is highly realistic and, as we will see, statistically representative.
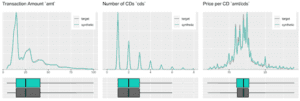
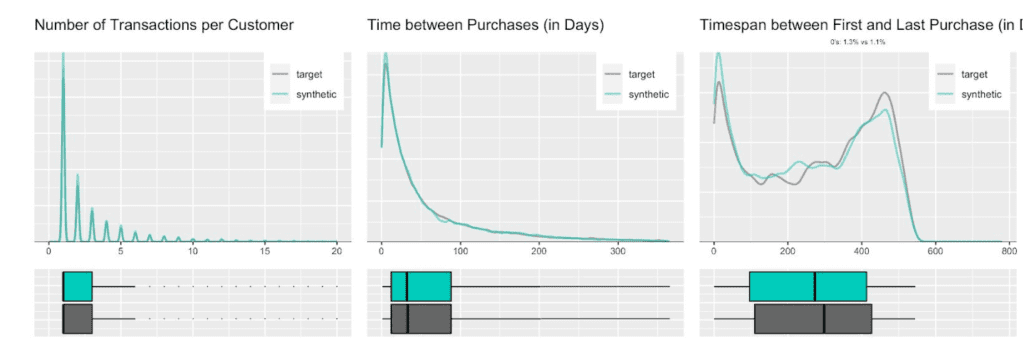
Fig 4. Various distributions at transactional level. The synthetic records (in green) match the original records (in grey) nearly perfectly.
These first plotted distributions already show the high degree of agreement between the original (labeled as target) and the synthetic dataset. Not only in terms of their mean and variance, but also across the whole distribution, together with its deciles, skewness, and multiple modes. Further, the relationship between multiple variables is retained near perfectly as well. This can be seen from the righter most chart, that reports on the ratio between the number of CDs and transaction amount (i.e. on the average price per purchased CD).
Synthetic Sequences Allow You to Draw the Same Conclusions As Real Ones
Fig 5. It’s the sequence that makes the music, that tells the story and that conveys the insight.
While these statistics already show that our technology is capable of generating highly accurate synthetic transactions, the key argument that we are making with this blog post series is, that it’s all about sequential data and its inter-dependencies. Just as a single word tells no story, and a single musical note doesn’t make a tune, a single recorded event of a customer (one transaction, one visit, one click, or really any other action) doesn’t determine a person. It’s the particular sequence of words, the particular sequence of notes, and the particular sequence of events that form the narrative. And only the events and their patterns, taken all together, make up the rich and unique behavioral stories, that are so crucial to understand customers and serve their needs.
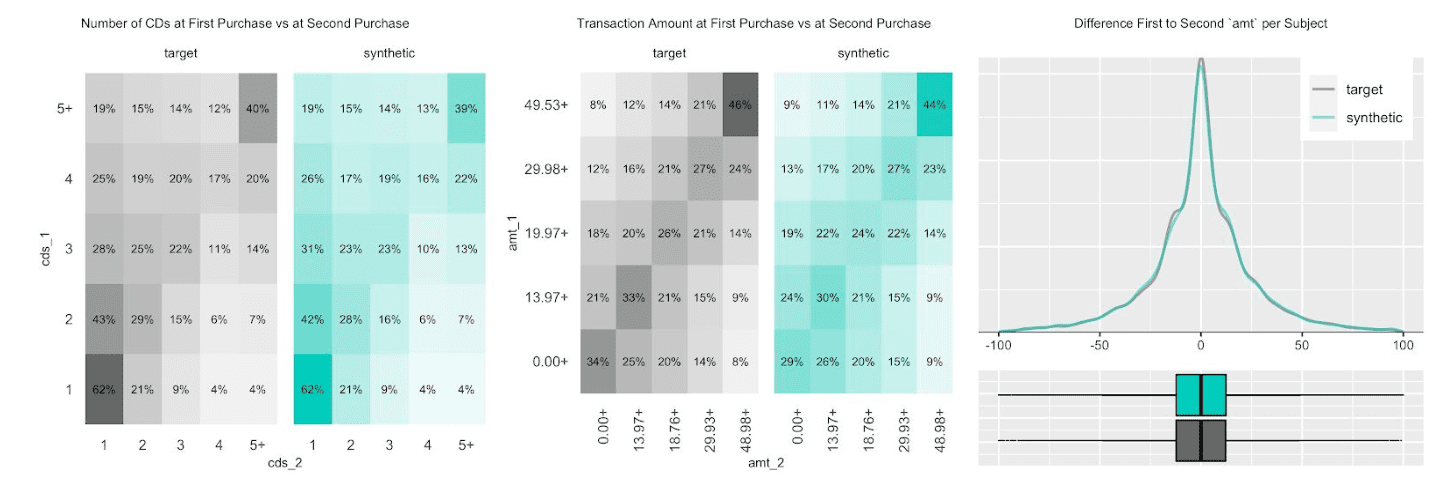
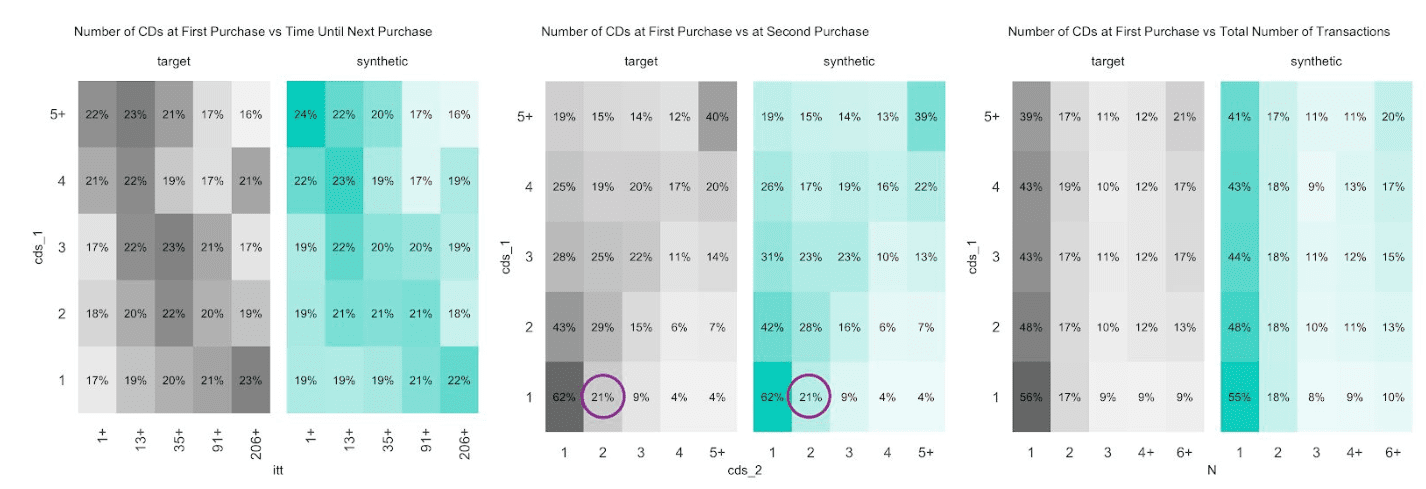
Coming back to the CDNOW dataset, we thus want to investigate how well MOSTLY AI's synthetic data platform was able to retain patterns for customers across their transactions. As a simple starting example, let’s look at the relationship between two succeeding purchases. One would expect to see that a customer that had a high initial purchase amount, would also have an above-average purchase amount for her second purchase. And indeed, they are positively correlated, with a pearson correlation coefficient of 0.39 for the original data. When running the same calculation on the synthetic dataset we do get 0.38, a practically identical result. But just as averages don’t do justice to the full distribution, we shall now continue to visually inspect these temporal relationships in more detail. The plots in figure 6 showcase that, no matter how we decide to slice and dice the data, the discrepancies between the original CDNOW data (target) and the synthetic CDNOW data remain marginal. For example, the probability of ordering five or more CDs at their second purchase is only 4% if they bought a single CD at their first transaction, but goes up to 40% for those that initially bought 5+ CDs as well. It’s the same statistic, and thus the same insight from the actual as from the synthetic data. So, whether it’s the total number of transactions, the number of days between purchases, or the relationship between the initial transaction and the total number of transactions – we are able to come to the same statistical conclusions when analyzing behavioral patterns. But the benefit of synthetic data is, that it allows you to do this analysis without infringing your customers' privacy.
Fig 6. Various Distributions at Customer Level
Synthetic Predictions to Guide Business Decisions While Preserving Privacy
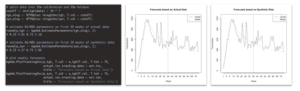
Let’s take this further, and do some predictive modeling on the individual customer level. We can, for example, easily fit the popular BG/NBD model (via the Buy-Till-You-Die R package) to a calibration period of 39 weeks of actual as well as of synthetic data, to see whether this yields comparable results. Note, that our generative model shares none of the intrinsic model assumptions of the BG/NBD model, but purely detects the patterns based on the empirical data. This being considered, it is even more impressive, that the four estimated BG/NBD parameters can be near perfectly recovered from the synthetic data, without ever seeing the actual data. The estimated purchase frequency, the estimated churn process, and their corresponding heterogeneity match closely. Thus, the models trained on synthetic data yield near-identical (and still very accurate) forecasts for the 39 week holdout period of actual consumer data (see figure 7 for further details).
Fig 7. Probabilistic Behavioral Models trained on Actual vs on Synthetic Data - No Difference!
The implications of this are vast, and can’t be stressed enough: The AI-generated synthetic data produced with our groundbreaking technology is not only useful for mere test-driving predictive models. But it can also replace the real data as training data for predictive models – and thereby eliminate the need and the associated risks of working with actual, privacy-sensitive customer data. No other synthetic data solution on the market is capable of providing this level of utility for its generated synthetic data. But don't only take our word for it – go ahead and benchmark them with these publicly-available, real-world behavioral datasets as well!
And this is it for the second part of our mini-series on behavioral data. Next week up, in part 3, we will turn towards bigger, and more complex behavioral datasets, to continue to showcase the power and beauty of synthetic data. Stay tuned!Credits: This work is supported by the "ICT of the Future” funding programme of the Austrian Federal Ministry for Climate Action, Environment, Energy, Mobility, Innovation and Technology.
{"id":290,"post_type":"post","post_image":"https:\/\/mostly-web-mostly-website-assets.s3.eu-central-1.amazonaws.com\/wp-content\/uploads\/2021\/09\/Mostly-AI_Synthetic-Behavioral-Data_CDNOW-300x201.jpg","post_date":"2020-05-28","title":"How To Unlock Your Behavioral Data Assets (Part 2)","excerpt":"Behavioral data is the new gold. Go Synthetic to unleash its potential \u2013 and make sequential behavioral data your ultimate test case for choosing your preferred synthetic data solution!"}